机器学习之集成树模型
机器学习之集成树模型
- 一、集成模型之XGBoost
-
- 1.1 XGBoost算法原理
- 1.2 XGBoost与GBDT区别
- 1.3 XGBoost模型分类实战
-
- 1.3.1 数据读取
- 1.3.2 模型构建
- 1.3.3 参数调节
-
- 1.3.3.1 网格搜索
- 1.3.3.1 随机搜索
- 1.3.3.1 贝叶斯优化
- 二、集成模型之LightGBM
-
- 2.1 XGBoost缺点
- 2.2 LightGBM的优化
- 2.3 LightGBM基本原理
-
- 2.3.1 直方图(Histogram)算法
-
- 2.3.1.1 直方图算法
- 2.3.1.2 直方图作差加速
- 2.3.2 单边梯度采样 Gradient-based One-Side Sampling(GOSS)
- 2.3.3 互斥特征捆绑 Exclusive Feature Bundling(EFB)
- 2.3.4 带深度限制的Leaf-wise的叶子生长策略
- 2.3.5 直接支持类别特征(Categorical Feature)作为输入
- 2.3.6 并行计算
- 2.3.7 内存占用小
- 2.4 LightGBM与XGBoost的联系和区别
- 三、集成模型之CatBoost
本文主要介绍GBDT、XGBoost、LightGBM和CatBoost为代表的Boosting算法原理、使用方法和调参方式进行介绍。
一、集成模型之XGBoost
1.1 XGBoost算法原理
- 目标函数构造:
数据集包含n个样本m个特征,对于提升树模型来说,假设有K个叠加函数(additive functions,即决策树),模型可表示为:
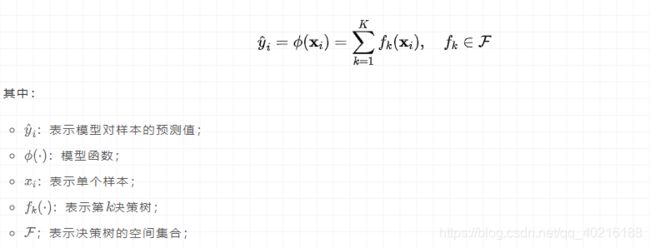
我们要学习上述加性模型,需要最小化正则化后的损失函数:

假设 y ^ i ( t ) \hat{y}_i^{(t)} y^i(t)表示在第 t t t次迭代时对第 i i i个样本的预测值,那么目标函数可表示为:
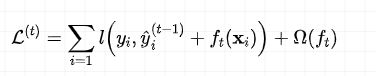
其中 ( y ) ^ i t − 1 \hat{(y)}_i^{t-1} (y)^it−1表示第 t − 1 t-1 t−1次迭代时,集成模型的预测值, f t ( . ) f_t(.) ft(.)表示第 t t t个决策树,在经过前 t − 1 t-1 t−1轮迭代后, y ^ i ( t − 1 ) \hat{y}_i^{(t-1)} y^i(t−1)为常数,所以只需要学习 f t ( x i ) f_t(x_i) ft(xi),同时在前 t − 1 t-1 t−1轮迭代后,集成模型的复杂度也是常数,所以目标函数没有包括。
- 目标函数近似:
泰勒公式的二阶近似:
f ( x + Δ x ) = f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ x + o ( Δ x ) f(x+\Delta x)=f(x)+f'(x)\Delta x+\frac{1}{2}f''(x)\Delta x+o(\Delta x) f(x+Δx)=f(x)+f′(x)Δx+21f′′(x)Δx+o(Δx)
对于损失函数来说,将 y ^ i ( t − 1 ) \hat y_i^{(t-1)} y^i(t−1)对应于 x x x, f t ( x i ) f_t(x_i) ft(xi)对应于 Δ x \Delta x Δx,损失函数可以近似为:
L ( t ) = ∑ i = 1 l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) L^{(t)}=\sum_{i=1}l(y_i, \hat y_i^{(t-1)}+f_t(x_i))+\Omega(f_t) L(t)=i=1∑l(yi,y^i(t−1)+ft(xi))+Ω(ft)
L ( t ) ≅ ∑ i = 1 n [ l ( y i , y ^ ( t − 1 ) ) + ∂ y ^ ( t − 1 ) l ( y i , y ^ ( t − 1 ) ) f t ( x i ) + 1 2 ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ ( t − 1 ) ) f t 2 ( x i ) ] + Ω ( f t ) L^{(t)}\cong\sum_{i=1}^n[l(y_i, \hat y^{(t-1)})+\partial_{\hat y(t-1)}l(y_i, \hat y^{(t-1)})f_t(x_i)+\frac{1}{2}\partial^2_{\hat y(t-1)}l(y_i, \hat y^{(t-1)})f^2_t(x_i)]+\Omega(f_t) L(t)≅i=1∑n[l(yi,y^(t−1))+∂y^(t−1)l(yi,y^(t−1))ft(xi)+21∂y^(t−1)2l(yi,y^(t−1))ft2(xi)]+Ω(ft)
我们令 g i = ∂ y ^ ( t − 1 ) l ( y i , y ^ ( t − 1 ) ) g_i=\partial_{\hat y(t-1)}l(y_i, \hat y^{(t-1)}) gi=∂y^(t−1)l(yi,y^(t−1)), h i = ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ ( t − 1 ) ) h_i=\partial^2_{\hat y(t-1)}l(y_i, \hat y^{(t-1)}) hi=∂y^(t−1)2l(yi,y^(t−1))
因此目标函数可以近似为:
L ( t ) ≅ ∑ i = 1 n [ l ( y i , y ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) L^{(t)}\cong\sum_{i=1}^n[l(y_i, \hat y^{(t-1)})+g_if_t(x_i)+\frac{1}{2}h_if^2_t(x_i)]+\Omega(f_t) L(t)≅i=1∑n[l(yi,y^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)
并且 l ( y i , y ^ ( t − 1 ) ) l(y_i, \hat y^{(t-1)}) l(yi,y^(t−1))为常数,可以去掉:
L ( t ) ≅ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) L^{(t)}\cong\sum_{i=1}^n[g_if_t(x_i)+\frac{1}{2}h_if^2_t(x_i)]+\Omega(f_t) L(t)≅i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
一阶导 g i g_i gi和二阶导 h i h_i hi是已知的,因此需要学习的参数在 f t ( x i ) f_t(x_i) ft(xi)中。
复杂度 Ω ( f t ) \Omega(f_t) Ω(ft)与叶子节点数量和叶子结点的值 w w w(学习参数)(某个样本的预测值对应于某个叶子结点的值,这样就能描述清楚决策树上对应每个样本的预测值)有关。一般表示为:
Ω ( f t ) = γ T + 1 2 λ ∥ w ∥ 2 \Omega(f_t)=\gamma T+\frac{1}{2} \lambda \lVert w \rVert ^2 Ω(ft)=γT+21λ∥w∥2
我们将目标函数表示为:
L ( t ) ≅ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + γ T + 1 2 λ ∑ j T w j 2 = ∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 ] + γ T L^{(t)}\cong\sum_{i=1}^n[g_i f_t(x_i)+\frac{1}{2}h_if^2_t(x_i)]+\gamma T+\frac{1}{2} \lambda \sum_{j}^T w_j^2 \\ =\sum_{j=1}^T[(\sum_{i \in I_j }g_i)w_j+\frac{1}{2}(\sum_{i\in I_j}h_i+\lambda)w_j^2]+\gamma T L(t)≅i=1∑n[gift(xi)+21hift2(xi)]+γT+21λj∑Twj2=j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT
I j = { i ∣ q ( x i ) = j } I_j=\{i|q(x_i)=j\} Ij={i∣q(xi)=j}
式 I j I_j Ij表示决策树中分配到第 j j j个叶子节点中的样本集合,其中 q ( x ) q(x) q(x)表示单个树的结果,即样本对应叶子节点的索引。
可以看到 L ( t ) L^(t) L(t)是关于 w j w_j wj的二次函数,最优解为 w j ∗ = − b 2 a w_j^*=-\frac{b}{2a} wj∗=−2ab,即
w j ∗ = − ∑ i ∈ I j g i ∑ i ∈ I j h i + λ w_j^*=-\frac{\sum_{i \in I_j }g_i}{\sum_{i\in I_j}h_i+\lambda} wj∗=−∑i∈Ijhi+λ∑i∈Ijgi
将 w j ∗ w_j^* wj∗带入 L ( t ) L^{(t)} L(t),可以得到对应的目标函数为:
L ∗ ( t ) = − 1 2 ∑ j = 1 T ( ∑ i ∈ I j g i ) 2 ∑ i ∈ I j h i + λ + γ T L^{(t)}_*=-\frac{1}{2}\sum_{j=1}^T\frac{(\sum_{i\in I_j }g_i)^2}{\sum_{i\in I_j}h_i+\lambda}+\gamma T L∗(t)=−21j=1∑T∑i∈Ijhi+λ(∑i∈Ijgi)2+γT
- 决策树构造,寻找分割点:
简单的方法是将所有决策树的结构全部罗列出来,然后优化,计算他们的目标函数值,进行比较,选择最小目标函数值的决策树。但是如果决策树深度过深,那么所有决策树的数量太多,很难完成上述步骤。
所以,文章采用了一种贪心算法(greedy algorithm)的策略,从单个叶子结点开始,迭代的增加分治进行比较。
当前有样本 1 , 2 , 3 , 4 , 5 , 6 {1, 2, 3, 4, 5, 6} 1,2,3,4,5,6,目前决策树为:

其中目标函数值可以表示为:
o b j o l d ∗ = − 1 2 [ ( g 1 + g 2 ) 2 h 1 + h 2 + λ + ( g 3 + g 4 + g 5 + g 6 ) 2 h 3 + h 4 + h 5 + h 6 + λ ] + 2 γ obj^*_{old}=-\frac{1}{2}[\frac{(g_1+g_2)^2}{h1+h2+\lambda}+\frac{(g_3+g_4+g_5+g_6)^2}{h3+h4+h5+h6+\lambda}]+2\gamma objold∗=−21[h1+h2+λ(g1+g2)2+h3+h4+h5+h6+λ(g3+g4+g5+g6)2]+2γ
我们对右子树进行划分:

此时目标函数为:
o b j n e w ∗ = − 1 2 [ ( g 1 + g 2 ) 2 h 1 + h 2 + λ + ( g 3 + g 4 ) 2 h 3 + h 4 + λ + ( g 5 + g 6 ) 2 h 5 + h 6 + λ ] + 3 γ obj^*_{new}=-\frac{1}{2}[\frac{(g_1+g_2)^2}{h1+h2+\lambda}+\frac{(g_3+g_4)^2}{h3+h4+\lambda}+\frac{(g_5+g_6)^2}{h5+h6+\lambda}]+3\gamma objnew∗=−21[h1+h2+λ(g1+g2)2+h3+h4+λ(g3+g4)2+h5+h6+λ(g5+g6)2]+3γ
将二者相减为:
o b j o l d ∗ − o b j n e w ∗ = 1 2 [ ( g 3 + g 4 ) 2 h 3 + h 4 + λ + ( g 5 + g 6 ) 2 h 5 + h 6 + λ − ( g 3 + g 4 + g 5 + g 6 ) 2 h 3 + h 4 + h 5 + h 6 + λ ] − γ obj^*_{old}-obj^*_{new}=\frac{1}{2}[\frac{(g_3+g_4)^2}{h3+h4+\lambda}+\frac{(g_5+g_6)^2}{h5+h6+\lambda}-\frac{(g_3+g_4+g_5+g_6)^2}{h3+h4+h5+h6+\lambda}]-\gamma objold∗−objnew∗=21[h3+h4+λ(g3+g4)2+h5+h6+λ(g5+g6)2−h3+h4+h5+h6+λ(g3+g4+g5+g6)2]−γ
如果 o b j o l d ∗ − o b j n e w ∗ > 0 obj^*_{old}-obj^*_{new}>0 objold∗−objnew∗>0,则说明可以进行分支。
通过以上分割方法,就可以分步的找到基于贪心的局部最优决策树。
1.2 XGBoost与GBDT区别
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题);
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导;
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合;
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率);
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算;
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向;
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行;
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
1.3 XGBoost模型分类实战
1.3.1 数据读取
以kaggle 2015年航班延误数据为例,进行建模。
数据来源:https://www.kaggle.com/usdot/flight-delays
该数据集完整数据量有500多万条航班记录数据,特征有31个,我们仅采用1%的数据和11个特征,经过预处理后重新构建训练数据集,目标是构建对航班是否延误的二分类模型。
#导入模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xgboost as xgb
import warnings
warnings.filterwarnings('ignore')#忽略warning
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score, accuracy_score, confusion_matrix
#数据读取
flight=pd.read_csv(r'./flights/flights.csv')
print(flight.shape)
#结果
(5819079, 31)
#抽取选取的列
cols=["MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE","FLIGHT_NUMBER",
"DESTINATION_AIRPORT", "ORIGIN_AIRPORT","AIR_TIME","DEPARTURE_TIME",
"DISTANCE", "ARRIVAL_DELAY"]
#月、日,每周的第几天,航空公司,航班号,目的地机场,始发机场,空气流动时间,起飞时间,距离,航班延误。
#数据抽样,获取指定特征
flight_part=flight.sample(frac=0.01, random_state=10)[cols]
print('flight_part.shape=', flight_part.shape)
#训练标签进行二值离散化,延误大于10分钟的转化为1(延误),延误小于10分钟的转化为0(不延误)
flight_part['ARRIVAL_DELAY']=(flight_part['ARRIVAL_DELAY']>10)*1
#类别特征编码,对“航线”、“航班号”、“目的地机场”、“出发地机场”等类别特征进行类别编码处理
cat_cols=["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]
for i in cat_cols:
flight_part[i]=flight_part[i].astype('category').cat.codes+1
#训练集和测试集划分
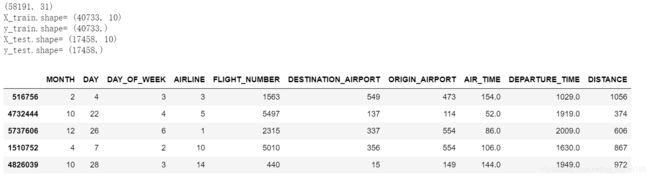
X_train,X_test,y_train,y_test=train_test_split(flight_part.drop('ARRIVAL_DELAY',axis=1),
flight_part['ARRIVAL_DELAY'],
random_state=10,
test_size=0.3)
#打印划分后的数据集大小
print('X_train.shape=',X_train.shape,
'\ny_train.shape=',y_train.shape,
'\nX_test.shape=',X_test.shape,
'\ny_test.shape=',y_test.shape)
X_train.head()
1.3.2 模型构建
sklearn中xgboost模块的XGBClassifier函数参数:
常规参数:
- booster:
gbtree 树模型作为基分类器(默认)
gblinear 线性模型作为基分类器 - slient:
silent=0,不输出中间过程(默认)
silent=1,输出中间过程 - nthread:
nthread=-1, 使用全部CPU进行并行运算(默认)
nthread=1, 使用1个CPU进行运算 - scale_pos_weight:
正样本的权重,在二分类任务中,当正负样本比例失衡时,设置正样本的权重,模型效果更好。例如,当正负样本比例为1:10时,scale_pos_weight=10
模型参数之Tree Booster
:
- n_estimatores:
含义:总共迭代的次数,即决策树的个数。
调参:防止overfitting - early_stopping_round:
含义:在验证集上,当连续迭代n次后,分数没有提高后,提前终止训练。
调参:防止overfitting - max_depth:
含义:决策树的深度,默认值为6,建议值3-10.
调参:值越大,越容易过拟合;值越小,越容易欠拟合。 - max_leaf_nodes:
含义:一颗决策树最大叶子结点数量,如果是二叉树,实际上和树的深度有关。 - min_child_weight:
含义:最小叶子节点样本权重和,如果一个叶子节点的样本权重和小于min_child_weight,则对该节点不进行划分。在线性回归模型中,这个参数指的是指建立每个模型所需要的最小样本数。默认值为1,取值范围是[0,∞]。
调参:调大该值可以防止过拟合。 - subsample:
含义:用于训练模型的子样本占整个样本集合的比例。如果设置为0.5则意味着XGBoost将随机的从整个样本集合中抽取出50%的子样本建立树模型,这能够防止过拟合。默认为1,取值范围是(0,1]。 - colsample_bytree:
含义:控制每棵随机采样的列数的占比(每一列是一个特征)。 默认值为1。取值范围是(0,1]。 - lambda:(别名:reg_lambda)
含义:L2正则化项参数。默认值为1。 - alpha:(别名:reg_alpha)
含义:L1正则化参数。默认值为0。
模型参数之 Linear Booster
:
- lambda:(python sklearn style参数名会有所变化 ,别名:reg_lambda)
含义:L2正则化项参数。默认值为1。 - alpha:(python sklearn style参数名会有所变化 ,别名:reg_alpha)
含义:L1正则化参数。默认值为0。 - lambda_bias:(python sklearn style参数名会有所变化 ,reg_lambda_bias])
含义:偏置上的L2正则化(没有在L1上加偏置,因为并不重要),默认值为0。
学习任务参数:
- learning_rate(python sklearn style参数名会有所变化 ,别名:eta):
含义:学习率,控制每次迭代更新权重时的步长,默认为0.3。建议值为0.01-0.2。
调参:值越小,训练越慢 - objective:
含义:目标函数
1)回归任务:reg:linear(默认)、reg:logistic
2)二分类:binary:logloss概率、binary:logitraw类别
3)多分类:multi:softmax,同时设置参数num_class=n,可以返回类别、multi:softprob,同时设置参数num_class=n,可以返回概率
4)排序任务:rank:pairwise,排序任务中最小化pairwise loss。 - eval_metric:
含义:评估函数
1)回归任务:
rmse–均方根误差(默认);
mae–平均绝对误差。
2)分类任务:
auc
auc-roc曲线下面积;
error@t–错误率(二分类,通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。不同的划分阈值可以通过 ‘t’进行设置);
merror–错误率(多分类,计算公式为(wrong cases)/(all cases));
logloss–负对数似然函数(二分类);
mlogloss–负对数似然函数(多分类log损失函数)
map–平均正确率。 - seed:
含义:随机数种子,默认值为0。
clf = xgb.XGBClassifier(learning_rate=0.1, # 学习率
n_estimators=100, # 树的个数--100棵树建立xgboost
max_depth=8, # 树的深度
gamma=0.1, # 惩罚项中叶子结点个数T前的参数
reg_lambda=2, # L2惩罚参数
random_state=1000, # 随机数
min_child_weight=3, # 最小叶子节点样本权重和
colsample=0.7, # 列采样的比例
eta=0.001, # 学习率
nthread=-1, # 使用全部CPU进行计算
eval_metric='logloss').fit(X_train, y_train) # 损失函数选择对数似然
y_test, y_pred = y_test, clf.predict(X_test) # y_pred输出预测样本的类别
print("Accuracy : %.4f" % accuracy_score(y_test, y_pred))
# predict_proba(X_train)输出预测样本的概率,输出2个值:[0.38, 0.62],其中0.38表示此样本预测为0类别的概率,0.62表示为1类别的概率,所以[:,1]将1类别的概率索引出来。
y_train_proba = clf.predict_proba(X_train)[:, 1]
print("AUC Score (Train): %.4f" % roc_auc_score(y_train, y_train_proba))
y_proba = clf.predict_proba(X_test)[:, 1]
print("AUC Score (Test): %.4f" % roc_auc_score(y_test, y_proba))
confusion_matrix(y_test, y_pred)
# 结果
#结果
Accuracy : 0.7983
AUC Score (Train): 0.8560
AUC Score (Test): 0.7206
array([[13470, 221],
[ 3300, 467]], dtype=int64)
1.3.3 参数调节
机器学习中常用的参数调节方法有:网格搜索(grid search)、随机搜索(random search)和贝叶斯优化(bayesian optimization)。
1.3.3.1 网格搜索
-
网格搜索是一项常用的超参数调优方法,常用于优化三个或者更少数量的超参数,本质是一种穷举法。对于每个超参数,使用者选择一个较小的有限集去探索。然后,这些超参数笛卡尔乘积得到若干个超参数组合。网格搜索使用每组超参数训练模型,挑选验证集误差最小的超参数作为最好的超参数。
-
例如,我们有三个需要优化的超参数a,b,c,候选的取值分别是{1,2},{3,4},{5,6}。则所有可能的参数取值组合组成了一个8个点的3维空间网格如下:{(1,3,5),(1,3,6),(1,4,5),(1,4,6),(2,3,5),(2,3,6),(2,4,5),(2,4,6)},网格搜索就是通过遍历这8个可能的参数取值组合,进行训练和验证,最终得到最优超参数。
-
sklearn中通过model_selection模块下的GridSearchCV来实现网格搜索调参(详见:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html),并且这个调参过程是加了交叉验证的。
from sklearn.model_selection import GridSearchCV
model=xgb.XGBClassifier()
param_dict={'max_depth':range(3,10,1),
'min_child_weight':[1,3,6],
'n_estimators':[100,150,200],
'learning_rate':[0.01,0.05,0.1]}
grid_search=GridSearchCV(estimator=model, param_grid=param_dict,cv=3,scoring='accuracy',verbose=10,n_jobs=-1)
grid_search.fit(X_train, y_train)
#结果
Fitting 3 folds for each of 189 candidates, totalling 567 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 1.3s
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 2.8s
[Parallel(n_jobs=-1)]: Done 16 tasks | elapsed: 4.9s
[Parallel(n_jobs=-1)]: Done 25 tasks | elapsed: 7.6s
[Parallel(n_jobs=-1)]: Done 34 tasks | elapsed: 10.3s
[Parallel(n_jobs=-1)]: Done 45 tasks | elapsed: 14.3s
[Parallel(n_jobs=-1)]: Done 56 tasks | elapsed: 18.5s
[Parallel(n_jobs=-1)]: Done 69 tasks | elapsed: 25.4s
[Parallel(n_jobs=-1)]: Done 82 tasks | elapsed: 33.2s
[Parallel(n_jobs=-1)]: Done 97 tasks | elapsed: 44.8s
[Parallel(n_jobs=-1)]: Done 112 tasks | elapsed: 56.5s
[Parallel(n_jobs=-1)]: Done 129 tasks | elapsed: 1.2min
[Parallel(n_jobs=-1)]: Done 146 tasks | elapsed: 1.5min
[Parallel(n_jobs=-1)]: Done 165 tasks | elapsed: 1.8min
[Parallel(n_jobs=-1)]: Done 184 tasks | elapsed: 2.3min
[Parallel(n_jobs=-1)]: Done 205 tasks | elapsed: 2.4min
[Parallel(n_jobs=-1)]: Done 226 tasks | elapsed: 2.6min
[Parallel(n_jobs=-1)]: Done 249 tasks | elapsed: 2.7min
[Parallel(n_jobs=-1)]: Done 272 tasks | elapsed: 2.9min
[Parallel(n_jobs=-1)]: Done 297 tasks | elapsed: 3.2min
[Parallel(n_jobs=-1)]: Done 322 tasks | elapsed: 3.6min
[Parallel(n_jobs=-1)]: Done 349 tasks | elapsed: 4.0min
[Parallel(n_jobs=-1)]: Done 376 tasks | elapsed: 4.5min
[Parallel(n_jobs=-1)]: Done 405 tasks | elapsed: 4.7min
[Parallel(n_jobs=-1)]: Done 434 tasks | elapsed: 4.9min
[Parallel(n_jobs=-1)]: Done 465 tasks | elapsed: 5.2min
[Parallel(n_jobs=-1)]: Done 496 tasks | elapsed: 5.5min
[Parallel(n_jobs=-1)]: Done 529 tasks | elapsed: 6.0min
[Parallel(n_jobs=-1)]: Done 567 out of 567 | elapsed: 6.6min finished
[11:41:37]
GridSearchCV(cv=3,
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, gamma=None,
gpu_id=None, importance_type='gain',
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=None, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None,
num_parallel_tree=None, random_state=None,
reg_alpha=None, reg_lambda=None,
scale_pos_weight=None, subsample=None,
tree_method=None, validate_parameters=None,
verbosity=None),
n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.05, 0.1],
'max_depth': range(3, 10),
'min_child_weight': [1, 3, 6],
'n_estimators': [100, 150, 200]},
scoring='accuracy', verbose=10)
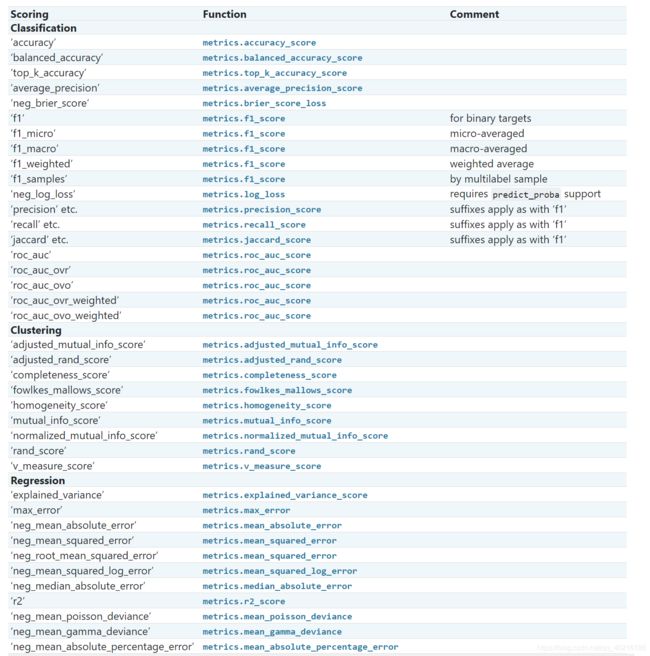
scoring参数可参考网站:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
#参数
#最优的参数
print(grid_search.best_params_)
#最好的模型
print(grid_search.best_estimator_)
#输出最优的精度
print(grid_search.best_score_)
#结果
{'learning_rate': 0.05, 'max_depth': 9, 'min_child_weight': 6, 'n_estimators': 200}
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.05, max_delta_step=0, max_depth=9,
min_child_weight=6, missing=nan, monotone_constraints='()',
n_estimators=200, n_jobs=8, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
0.8007266808733092
1.3.3.1 随机搜索
- 随机搜索,顾名思义,即在指定的超参数范围或者分布上随机搜索和寻找最优超参数。相较于网格搜索方法,给定超参数分布内并不是所有的超参数都会进行尝试,而是会从给定分布中抽样一个固定数量的参数,实际仅对这些抽样到的超参数进行实验。相较于网格搜索,随机搜索有时候会是一种更高效的调参方法。
- Sklearn中通过model_selection模块下RandomizedSearchCV方法进行随机搜索。详见:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
from sklearn.model_selection import RandomizedSearchCV
model=xgb.XGBClassifier()
param_dict={'max_depth':range(3,10,1),
'min_child_weight':[1,3,6],
'n_estimators':[100,150,200],
'learning_rate':[0.01,0.05,0.1]}
grid_search=RandomizedSearchCV(estimator=model, param_distributions=param_dict,cv=3,scoring='accuracy',verbose=10,n_jobs=-1)
grid_search.fit(X_train, y_train)
#结果
Fitting 3 folds for each of 10 candidates, totalling 30 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=-1)]: Done 2 tasks | elapsed: 6.3s
[Parallel(n_jobs=-1)]: Done 9 tasks | elapsed: 13.2s
[Parallel(n_jobs=-1)]: Done 19 out of 30 | elapsed: 19.8s remaining: 11.4s
[Parallel(n_jobs=-1)]: Done 23 out of 30 | elapsed: 20.7s remaining: 6.2s
[Parallel(n_jobs=-1)]: Done 27 out of 30 | elapsed: 21.9s remaining: 2.3s
[Parallel(n_jobs=-1)]: Done 30 out of 30 | elapsed: 22.9s finished
[11:54:03] WARNING: C:/Users/Administrator/workspace/xgboost-win64_release_1.4.0/src/learner.cc:1095: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
RandomizedSearchCV(cv=3,
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, gamma=None,
gpu_id=None, importance_type='gain',
interaction_constraints=None,
learning_rate=None,
max_delta_step=None, max_depth=None,
min_child_weight=None, missing=nan,
monotone_constraints=None,
n_estimators=100,...obs=None,
num_parallel_tree=None,
random_state=None, reg_alpha=None,
reg_lambda=None,
scale_pos_weight=None,
subsample=None, tree_method=None,
validate_parameters=None,
verbosity=None),
n_jobs=-1,
param_distributions={'learning_rate': [0.01, 0.05, 0.1],
'max_depth': range(3, 10),
'min_child_weight': [1, 3, 6],
'n_estimators': [100, 150, 200]},
scoring='accuracy', verbose=10)
#最优的参数
print(grid_search.best_params_)
#最好的模型
print(grid_search.best_estimator_)
#输出最优的精度
print(grid_search.best_score_)
#结果
{'n_estimators': 150, 'min_child_weight': 6, 'max_depth': 7, 'learning_rate': 0.1}
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.1, max_delta_step=0, max_depth=7,
min_child_weight=6, missing=nan, monotone_constraints='()',
n_estimators=150, n_jobs=8, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
0.7999656259758351
1.3.3.1 贝叶斯优化
- 使用场景:
1)函数 f ( x ) f(x) f(x)表达式未知,即黑箱子模型,给定输入x,可以输出y;
2) f ( x ) f(x) f(x)对于x的梯度未知;
3)需要得到 f ( x ) f(x) f(x)在自变量x上的全局最优解。 - 与常规的网格搜索的区别:
1)贝叶斯调参采用高斯过程,考虑之前的参数信息,不断地更新先验;网格搜索未考虑之前的参数信息;
2)贝叶斯调参迭代次数少,速度快;网格搜索速度慢,参数多时易导致维度爆炸;
3)贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部优值。 - 理论:
贝叶斯优化调参,从两个部分讲起:1)高斯过程,用以拟合优化目标函数;2)贝叶斯优化,包括了“开发”和“探索”,用以花最少的代价找到最优值.
1)高斯过程:
高斯过程可用于非线性回归,非线性分类,参数寻优等。以往的建模需要对 p ( y ∣ X ) p(y|X) p(y∣X)建模,当用于预测时,则是
p ( y N + 1 ∣ X N + 1 ) p(y_{N+1}|X_{N+1}) p(yN+1∣XN+1)
而高斯过程,还考虑了 y N y_N yN和 y N + 1 y_{N+1} yN+1之间的关系,即
p ( y N + 1 ∣ X N + 1 , y N ) p(y_{N+1}|X_{N+1}, y_N) p(yN+1∣XN+1,yN)
高斯过程通过假设 y y y值服从联合正态分布,如下所示:
[ y 1 y 2 . . . y n ] ∽ N ( 0 , [ k ( x 1 , x 1 ) , k ( x 1 , x 2 ) , . . . , k ( x 1 , x n ) k ( x 2 , x 1 ) , k ( x 2 , x 2 ) , . . . , k ( x 2 , x n ) . . . k ( x n , x 1 ) , k ( x n , x 2 ) , . . . , k ( x n , x n ) ] ) ∽ N ( 0 , K ) \begin{bmatrix} y_1 \\ y_2 \\ ...\\y_n \end{bmatrix} \backsim N(0, \begin{bmatrix} k(x_1,x_1),k(x_1, x_2), ...,k(x_1, x_n) \\k(x_2,x_1),k(x_2, x_2), ...,k(x_2, x_n) \\ ... \\k(x_n,x_1),k(x_n, x_2), ...,k(x_n, x_n) \end{bmatrix}) \backsim N(0, K) ⎣⎢⎢⎡y1y2...yn⎦⎥⎥⎤∽N(0,⎣⎢⎢⎡k(x1,x1),k(x1,x2),...,k(x1,xn)k(x2,x1),k(x2,x2),...,k(x2,xn)...k(xn,x1),k(xn,x2),...,k(xn,xn)⎦⎥⎥⎤)∽N(0,K)
其中协方差矩阵叫做核矩阵,记为 K K K,仅和特征x有关,和y无关。
高斯过程的思想是: 假设 Y 服从高维正态分布(先验),而根据训练集可以得到最优的核矩阵 ,从而得到后验以估计测试集 y ∗ y_∗ y∗, y ∗ ∽ N ( 0 , k ( x ∗ , x ∗ ) ) y_*\backsim N(0,k(x_*, x_*)) y∗∽N(0,k(x∗,x∗))。有后验如下:
p ( y ∗ ∣ y ∽ N ( K ∗ K − 1 y , K ∗ ∗ − K ∗ K − 1 K ∗ T ) ) p(y_*|y\backsim N(K_*K^{-1}y, K_{**}-K_*K^{-1}K_*^T)) p(y∗∣y∽N(K∗K−1y,K∗∗−K∗K−1K∗T))
其中, K ∗ K_* K∗为训练集的核向量,有如下关系:
[ y 1 y ∗ ] ∽ N ( 0 , [ k ( x 1 , x 1 ) , . . . , k ( x 1 , x ∗ ) . . . k ( x ∗ , x 1 ) , . . . , k ( x ∗ , x ∗ ) ] ) ∽ N ( 0 , [ K , K ∗ T K ∗ , K ∗ ∗ ] ) \begin{bmatrix} y_1 \\ y_* \end{bmatrix} \backsim N(0, \begin{bmatrix} k(x_1,x_1), ...,k(x_1, x_*) \\ ... \\k(x_*,x_1),...,k(x_*, x_*) \end{bmatrix}) \backsim N(0, \begin{bmatrix} K, K_*^T \\K_*,K_{**} \end{bmatrix}) [y1y∗]∽N(0,⎣⎡k(x1,x1),...,k(x1,x∗)...k(x∗,x1),...,k(x∗,x∗)⎦⎤)∽N(0,[K,K∗TK∗,K∗∗])
2)高斯过程的估计方法:
假设使用平方指数核,那么有:
k ( x 1 , x 2 ) = σ f 2 e x p ( ) − ( x 1 − x 2 ) 2 2 l 2 k(x_1,x_2)=\sigma^2_f exp()\frac{-(x_1-x_2)^2}{2l^2} k(x1,x2)=σf2exp()2l2−(x1−x2)2
那么需要的超参数 θ = [ σ f 2 , l ] \theta=[\sigma_f^2, l] θ=[σf2,l],由于 y y y服从多维正态分布,因此似然函数为:
L = log p ( y ∣ x , θ ) = − 1 2 log ∣ K ∣ − 1 2 ( y − μ ) T K − 1 ( y − μ ) − n 2 log ( 2 π ) L=\log p(y|x, \theta)=-\frac{1}{2}\log|K|-\frac{1}{2}(y-\mu)^TK^{-1}(y-\mu)-\frac{n}{2}\log(2\pi) L=logp(y∣x,θ)=−21log∣K∣−21(y−μ)TK−1(y−μ)−2nlog(2π)
3)贝叶斯优化理论:
贝叶斯优化是一种逼近思想,当计算非常复杂、迭代次数较高时能起到很好的效果,多用于超参数确定。
贝叶斯优化的例子:
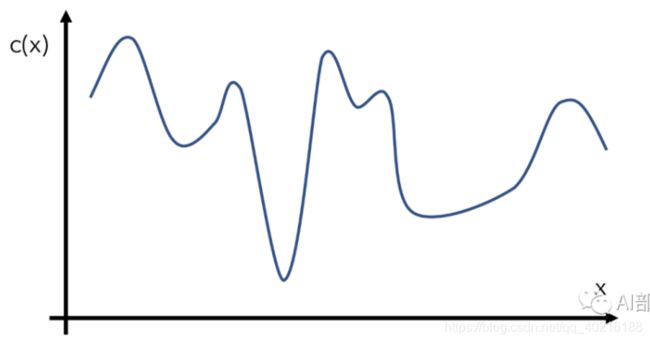
比如我们有一个目标函数c(x),代表输入为x下的代价为c(x)。优化器是无法知道这个c(x)的真实曲线如何的,只能通过部分(有限)的样本x和对应的c(x)值。假设这个c(x)下图所示。
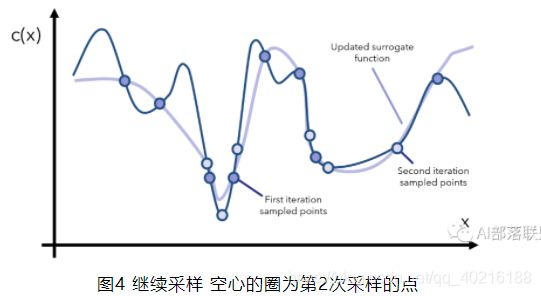
贝叶斯优化器为了得到c(x)的全局最优解,首先要采样一些点x来观察c(x)的形状,这个过程可以叫surrogate optimization(替代优化),由于无法窥见c(x)的全貌,只能通过采样点来找到一个模拟c(x)的替代曲线,如下图所示:

得到这个模拟的/替代的曲线之后,我们就能找到两个还算不错的最小值对应的点了(上图中标注的是promising minima),于是根据当前观察到的这两个最小点,再采样更多的点,用更多的点模拟出一个更逼真的c(x)再找最小点的位置,如下图所示
然后我们重复上面这个过程,每次重复的时候我们干以下几件事情:先找到可拟合当前点的一个替代函数,然后根据替代函数的最小值所在的位置去采样更多的 ,再更新替代函数,如此往复。
基本思想:
基于数据使用贝叶斯定理估计目标函数的后验分布,然后再根据分布选择下一个采样的超参数组合。它充分利用了前一个采样点的信息,其优化的工作方式是通过对目标函数形状的学习,并找到使结果向全局最大提升的参数。
高斯过程用于在贝叶斯优化中对目标函数建模,得到其后验分布。
通过高斯过程建模之后,我们尝试抽样进行样本计算,而贝叶斯优化很容易在局部最优解上不断采样,这就涉及到了开发和探索之间的权衡。
- a)开发 (exploitation): 根据后验分布,在最可能出现全局最优解的区域进行采样, 开发高意味着均值高。
- b)探索 (exploration): 在还未取样的区域获取采样点, 探索高意味着方差高。
而如何高效的采样,即开发和探索,我们需要用到 Acquisition Function, 它是用来寻找下一个 x 的函数。
几种主流的Acquistion Function:
- a)POI(probability of improvement):
P O I ( X ) = P ( f ( X ) ≥ f ( X + ) + ξ ) = Φ ( μ ( x ) − f ( X + ) − ξ σ ( x ) ) POI(X)=P(f(X)\geq f(X^+)+\xi)=\Phi (\frac{\mu(x)-f(X^+)-\xi}{\sigma(x)}) POI(X)=P(f(X)≥f(X+)+ξ)=Φ(σ(x)μ(x)−f(X+)−ξ)
其中, f ( X ) f(X) f(X) 为 X X X的目标函数值, f ( X + ) f(X^+) f(X+) 为到目前为止最优的目标函数值, μ ( x ) , σ ( x ) \mu(x),\sigma(x) μ(x),σ(x)分别是高斯过程所得到的目标函数的均值和方差,即 f ( X ) f(X) f(X)的后验分布。 ξ \xi ξ为trade-off系数,如果没有该系数,POI函数会倾向于取在 X + X^+ X+周围的点,即倾向于exploit而不是explore,因此加入该项进行权衡。POI是一个概率函数,因此只考虑了 f ( X ) f(X) f(X)比 f ( X + ) f(X^+) f(X+)大的概率。
而我们要做的,就是尝试采样新的X,使得 POI(X) 最大,通常我们使用蒙特卡洛模拟的方法进行。 - b)Expected Improvement:
EI则是一个期望函数,因此考虑了$ f(X) $比 $f(X^+) 大 多 少 。 我 们 通 过 下 式 获 取 大多少。我们通过下式获取 大多少。我们通过下式获取X$:
x = a r g m a x x E ( m a x 0 , f t + 1 − f ( X + ) ∣ D t ) x=argmax_x E(max{0, f_{t+1}-f(X^+)}|D_t) x=argmaxxE(max0,ft+1−f(X+)∣Dt)
其中 D t D_t Dt 为前 t t t个样本,在正态分布的假定下,最终得到:
E I ( x ) = { ( μ ( x ) − f ( x + ) ) Φ ( Z ) + σ ( x ) ϕ ( Z ) , i f σ ( x ) > 0 0 , i f σ ( x ) = 0 } EI(x)= \begin{Bmatrix} (\mu(x)-f(x^+))\Phi(Z) +\sigma(x)\phi(Z), if \sigma(x)>0 \\0 , if \sigma(x)=0 \\ \end{Bmatrix} EI(x)={(μ(x)−f(x+))Φ(Z)+σ(x)ϕ(Z),ifσ(x)>00,ifσ(x)=0}
其中 Z = μ ( x ) − f ( x + ) σ ( x ) Z=\frac{\mu(x)-f(x^+)}{\sigma(x)} Z=σ(x)μ(x)−f(x+) - c)Confidence bound criteria:
L C B ( x ) = μ ( x ) − κ σ ( x ) U C B ( x ) = μ ( x ) + κ σ ( x ) LCB(x)=\mu(x)-\kappa\sigma(x) \\UCB(x)=\mu(x)+\kappa\sigma(x) LCB(x)=μ(x)−κσ(x)UCB(x)=μ(x)+κσ(x)
假设我们把acquisition functin简写为aq(x),整个贝叶斯优化可以概括为: - 1)基于Gaussian Process,初始化替代函数的先验分布;
- 2)根据当前替代函数的先验分布和aq(x),采样若干个数据点;
- 3)根据采样的x得到目标函数f(x)的新值;
- 4)根据新的数据,更新替代函数的先验分布,并开始重复迭代2-4步;
- 5)迭代之后,根据当前的Gaussian Process找到全局最优解。
缺点和不足:
- 高斯过程核矩阵不好选
代码实现
我们先定义一个目标函数,里面放入我们希望优化的函数。比如此时,函数输入为XGBoost的所有参数,输出为模型交叉验证5次的AUC均值,作为我们的目标函数。因为bayes_opt库只支持最大值,所以最后的输出如果是越小越好,那么需要在前面加上负号,以转为最小值。由于bayes优化只能优化连续超参数,因此要加上int()转为离散超参数。(参考:https://www.cnblogs.com/yangruiGB2312/p/9374377.html)
(cross_val_score函数参考:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html)
from sklearn.model_selection import cross_val_score
import xgboost as xgb
def xgb_cv(n_estimators, max_depth,learning_rate,min_child_weight):
val = cross_val_score(
xgb.XGBClassifier(max_depth=int(max_depth),
learning_rate=min(learning_rate,0.3),
n_estimators=int(n_estimators),
nthread=-1,
min_child_weight=int(min_child_weight),
seed=0
),
X_train,y_train, scoring='roc_auc', cv=5
).mean()
return val
#然后我们就可以实例化一个bayes优化对象了
#里面的第一个参数是我们的优化目标函数,第二个参数是我们所需要输入的超参数名称,以及其范围。
#超参数名称必须和目标函数的输入名称一一对应。
xgb_bo = BayesianOptimization(
xgb_cv,
{
'max_depth': (5,10),
'learning_rate': (0.1,0.3),
'n_estimators': (50,100),
'min_child_weight': (5,10)
}
)
#开始优化
xgb_bo.maximize(n_iter=20)
#结果
| iter | target | learning_rate | max_depth | min_child_weight| n_estimators |
| 1 | 0.5614 | 0.257 | 8.252 | 6.389 | 90.26 |
| 2 | 0.5624 | 0.2817 | 9.346 | 7.396 | 66.48 |
| 3 | 0.5739 | 0.2782 | 6.772 | 5.166 | 53.22 |
.....
| 25 | 0.5789 | 0.1 | 5.0 | 10.0 | 55.02 |
=========================================================================
#查看最优参数
xgb_bo.max
#结果
{'target': 0.5789135834536424,
'params': {'learning_rate': 0.1,
'max_depth': 5.0,
'min_child_weight': 10.0,
'n_estimators': 55.020884298941965}}
二、集成模型之LightGBM
2.1 XGBoost缺点
-
XGBoost基于预排序方法的决策树算法。基本思想是:首先,对所有特征都按照特征取值进行预排序。其次,在遍历分割点的时,用O(#data)的代价找到一个特征上的最好分割点。最后,按照最好的分割点将数据分裂成左右子树。
-
预排序算法的优点是能精确地找到分割点。缺点是:
-
1)首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。
-
2)其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
-
3)最后,对cache优化不友好。每轮迭代时,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
2.2 LightGBM的优化
为了避免上述XGBoost的缺陷,并且能够在不损害准确率的条件下加快训练速度,lightGBM进行如下优化:
- 1)基于直方图(Histogram)的决策树算法;
- 2)单边梯度采样 Gradient-based One-Side Sampling(GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征值节省了不少时间和空间上的开销;
- 3)互斥特征捆绑 Exclusive Feature Bundling(EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的;
- 4)带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长 (level-wise) 的决策树生长策略,因为它平等对待同一层的叶子节点,带来了很多没必要的开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM使用了带有深度限制的按叶子生长 (leaf-wise) 算法;
- 5)直接支持类别特征(Categorical Feature)作为输入;
- 6)支持高效并行;
- 7)Cache命中率优化。
2.3 LightGBM基本原理
2.3.1 直方图(Histogram)算法
2.3.1.1 直方图算法
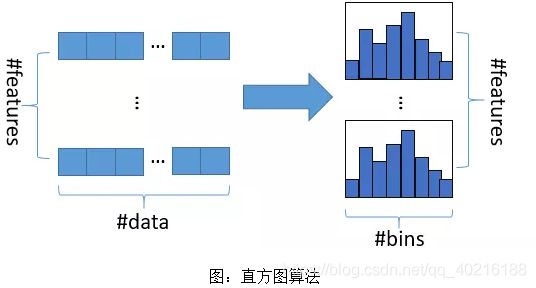
- 基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
- 数值特征进行分桶
1)如果数值特征的不同取值个数小于预先设定的最大分桶数:则每个桶内存放一类取值特征的样本,即使用排序后的前后2个值的均值作为分桶界限;
2)数值特征不同取值个数大于最大分桶数:首先统计每个特征取值对应的样本数,当一个取值的样本数大于桶样本数的均值(总样本数/最大分桶数),对它独立分桶,再对剩下的样本进行排序和统计,由小到大排序累计加和达到单个分桶的最大样本数,完成一次分桶。 - 特征离散化具有很多优点,如存储方便、运算更快、鲁棒性强、模型更加稳定等。对于直方图算法来说最直接的有以下两个优点:
1)内存占用更小: 直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。也就是说XGBoost需要用32位的浮点数去存储特征值,并用32位的整形去存储索引,而 LightGBM只需要用8位去存储直方图,内存相当于减少为1/8;
2)计算代价更小: 预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LightGBM只需要计算k次(k可以认为是常数),直接将时间复杂度从O(#data*#feature)降低到O(k*#feature),而我们知道data>>k。 - Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
2.3.1.2 直方图作差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍。


2.3.2 单边梯度采样 Gradient-based One-Side Sampling(GOSS)
-
GOSS是一个样本的采样算法。在进行数据采样的时只保留了梯度较大的数据,如果样本梯度较小,则该样本的训练误差也比较小(gbdt拟合就是负梯度),但是如果直接将所有梯度较小的数据都丢弃掉势必会影响数据的总体分布。
-
GOSS首先将要进行分裂的特征的所有取值按照绝对值大小降序排序(XGBoost一样也进行了排序,但是LightGBM不用保存排序后的结果),选取绝对值最大的a个数据。然后在剩下的较小梯度数据中随机选择b个数据。接着将这b个数据乘以一个常数 1 − a b \frac{1-a}{b} b1−a ,这样算法就会更关注训练不足的样本,而不会过多改变原数据集的分布。最后使用这(a+b)个数据来计算信息增益。(a, b都是百分比)
-
对于每一步迭代(for循环里面的):
(1)先根据模型进行预测,得到样本预测值preds;
(2)根据preds计算loss,然后进一步计算得到样本梯度,样本权重w初始赋值都等于1;
(3)根据样本梯度的绝对值,降序排序得到sorted,它是样本的索引数组;
(4)大梯度样本数据选取topN=alen(I)个,得到topSet,也是索引数组;
(5)小梯度样本数据,从剩余的样本里随机挑选randN=blen(I)个,得到randSet;
(6)将topSet和randSet进行合并,得到usedSet,大小等于(a+b)*len(I) ;
(7)将小样本的样本权重乘上权重系数因子,得到新的样本权重w;
(8)根据usedSet索引上的样本I, 梯度g, 权重w,得到一个新的弱学习器newModel。
(9)将新弱学习器newModel,加入总模型(lgb是加法模型)。 -
总之,根据算法流程,每步迭代的样本数都减小为上一次样本数的(a+b)*100%,是指数变化的。实验表明,该做法并没有降低模型性能,反而还有一定提升。究其原因,应该是采样也会增加弱学习器的多样性,从而潜在地提升了模型的泛化能力,稍微有点像深度学习的dropout。
2.3.3 互斥特征捆绑 Exclusive Feature Bundling(EFB)
- 前面GOSS可以通过减少样本加速模型训练,而EFB可以通过减少特征个数使数据规模进一步变小。
- 互斥:一些特征很少同时出现非0值,类似于one-hot特征。lgb的思想是将互斥的特征捆绑在一起形成新的特征,以减少特征数量,提高训练速度。
1)首先介绍如何判定哪些特征应该捆绑在一起?
- EFB算法流程:
(1)将特征作为图的顶点,对于不互斥的特征进行相连(存在同时不为0的样本),特征同时不为0的样本个数作为边的权重;
(2)根据顶点的度对特征进行降序排序,度越大表明特征与其他特征的冲突越大(越不太可能与其他特征进行捆绑);
(3)设置最大冲突阈值K,外层循环先对每一个上述排序好的特征,遍历已有的特征捆绑簇,如果发现该特征加入到该特征簇中的冲突数不会超过最大阈值K,则将该特征加入到该簇中。否则新建一个特征簇,将该特征加入到新建的簇中。
2)如何将特征捆绑簇里面的所有特征捆绑(合并)为一个特征?
- EFB采用的是加入一个偏移常量(offset)来解决。举个例子,我们绑定两个特征A和B,A取值范围为[0, 10),B取值范围为[0, 20)。则我们可以加入一个偏移常量10,即将B的取值范围变为[10,30),然后合并后的特征范围就是[0, 30),并且能很好的分离出原始特征~
(参考网址:https://www.zhihu.com/collection/614379258)
2.3.4 带深度限制的Leaf-wise的叶子生长策略
-
Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
-
XGBoost 采用 Level-wise 的增长策略,该策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂,因此带来了很多没必要的计算开销。
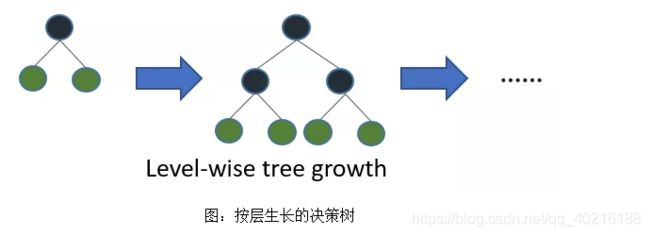
-
LightGBM采用Leaf-wise的增长策略,该策略每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
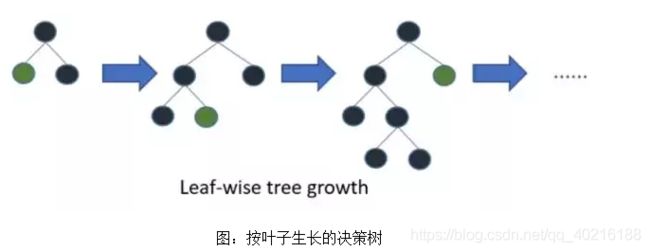
2.3.5 直接支持类别特征(Categorical Feature)作为输入
2.3.6 并行计算
- 特征并行
并行计算训练数据中特征集合上的最优切分点; - 数据并行
- 投票并行
2.3.7 内存占用小
2.4 LightGBM与XGBoost的联系和区别
- (1)LightGBM使用了基于histogram的决策树算法。1)内存上优势:内存消耗小。2)计算上的优势:预排序算法在选择好分裂特征计算分裂收益时需要遍历所有样本的特征值,时间为O(#data*#feature),而直方图算法只需要遍历桶就行了,时间为O(#bin*#feature)。
- (2)XGBoost采用的是level-wise的分裂策略,而LightGBM采用了leaf-wise的策略,区别是XGBoost对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果影响不大,但是XGBoost也进行了分裂,带来了不必要的开销。leaft-wise的做法是在当前所有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显leaf-wise这种做法容易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合。
- (3)LightGBM使用直方图做差加速,一个子节点的直方图可以通过父节点的直方图减去兄弟节点的直方图得到,从而加速计算。
- (4)LightGBM支持类别特征,不需要进行独热编码处理。
- (5)LightGBM优化了特征并行和数据并行算法,除此之外还添加了投票并行方案。
- (6)LightGBM采用基于梯度的单边采样来减少训练样本并保持数据分布不变,减少模型因数据分布发生变化而造成的模型精度下降。
- (7)互斥特征捆绑减少特征数量。
(参考网址:https://mp.weixin.qq.com/s/UWgedc6pdz2Ydh13IAxiUQ)
- 基于Scikit-learn接口的分类
from lightgbm import LGBMClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
# 划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 模型训练
gbm = LGBMClassifier(num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=5)
# 模型存储
joblib.dump(gbm, 'loan_model.pkl')
# 模型加载
gbm = joblib.load('loan_model.pkl')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
# 模型评估
print('The accuracy of prediction is:', accuracy_score(y_test, y_pred))
# 特征重要度
print('Feature importances:', list(gbm.feature_importances_))
# 网格搜索,参数优化
estimator = LGBMClassifier(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
- 基于Scikit-learn接口的回归
import pandas as pd
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import Imputer
# 1.读文件
data = pd.read_csv('./dataset/train.csv')
# 2.切分数据输入:特征 输出:预测目标变量
y = data.SalePrice
X = data.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object'])
# 3.切分训练集、测试集,切分比例7.5 : 2.5
train_X, test_X, train_y, test_y = train_test_split(X.values, y.values, test_size=0.25)
# 4.空值处理,默认方法:使用特征列的平均值进行填充
my_imputer = Imputer()
train_X = my_imputer.fit_transform(train_X)
test_X = my_imputer.transform(test_X)
# 5.调用LightGBM模型,使用训练集数据进行训练(拟合)
# Add verbosity=2 to print messages while running boosting
my_model = lgb.LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20,
verbosity=2)
my_model.fit(train_X, train_y, verbose=False)
# 6.使用模型对测试集数据进行预测
predictions = my_model.predict(test_X)
# 7.对模型的预测结果进行评判(平均绝对误差)
print("Mean Absolute Error : " + str(mean_absolute_error(predictions, test_y)))
三、集成模型之CatBoost
参考网址:https://mp.weixin.qq.com/s/ABR1cDAvKA9pDVNe1a6qYg
-
数据集
这里我使用了 2015 年航班延误的 Kaggle 数据集,其中同时包含类别型变量和数值变量。这个数据集中一共有约 500 万条记录,我使用了 1% 的数据:5 万行记录。数据集官方地址:https://www.kaggle.com/usdot/flight-delays#flights.csv 。以下是建模使用的特征:
月、日、星期: 整型数据
航线或航班号: 整型数据
出发、到达机场: 数值数据
出发时间: 浮点数据
距离和飞行时间: 浮点数据
到达延误情况: 这个特征作为预测目标,并转为二值变量:航班是否延误超过 10 分钟
实验说明: 在对 CatBoost 调参时,很难对类别型特征赋予指标。因此,同时给出了不传递类别型特征时的调参结果,并评估了两个模型:一个包含类别型特征,另一个不包含。如果未在cat_features参数中传递任何内容,CatBoost会将所有列视为数值变量。注意,如果某一列数据中包含字符串值,CatBoost 算法就会抛出错误。另外,带有默认值的 int 型变量也会默认被当成数值数据处理。在 CatBoost 中,必须对变量进行声明,才可以让算法将其作为类别型变量处理。 -
不加Categorical features选项的代码-分类
import pandas as pd, numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn import metrics
import catboost as cb
# 一共有约 500 万条记录,我使用了 1% 的数据:5 万行记录
# data = pd.read_csv("flight-delays/flights.csv")
# data = data.sample(frac=0.1, random_state=10) # 500->50
# data = data.sample(frac=0.1, random_state=10) # 50->5
# data.to_csv("flight-delays/min_flights.csv")
# 读取 5 万行记录
data = pd.read_csv("flight-delays/min_flights.csv")
print(data.shape) # (58191, 31)
data = data[["MONTH", "DAY", "DAY_OF_WEEK", "AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT",
"ORIGIN_AIRPORT", "AIR_TIME", "DEPARTURE_TIME", "DISTANCE", "ARRIVAL_DELAY"]]
data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"] > 10) * 1
cols = ["AIRLINE", "FLIGHT_NUMBER", "DESTINATION_AIRPORT", "ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes + 1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"],
random_state=10, test_size=0.25)
cat_features_index = [0, 1, 2, 3, 4, 5, 6]
def auc(m, train, test):
return (metrics.roc_auc_score(y_train, m.predict_proba(train)[:, 1]),
metrics.roc_auc_score(y_test, m.predict_proba(test)[:, 1]))
# 调参,用网格搜索调出最优参数
params = {'depth': [4, 7, 10],
'learning_rate': [0.03, 0.1, 0.15],
'l2_leaf_reg': [1, 4, 9],
'iterations': [300, 500]}
cb = cb.CatBoostClassifier()
cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv=3)
cb_model.fit(train, y_train)
# 查看最佳分数
print(cb_model.best_score_) # 0.7088001891107445
# 查看最佳参数
print(cb_model.best_params_) # {'depth': 4, 'iterations': 500, 'l2_leaf_reg': 9, 'learning_rate': 0.15}
# With Categorical features,用最优参数拟合数据
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=4, iterations=500, l2_leaf_reg=9,
learning_rate=0.15)
clf.fit(train, y_train)
print(auc(clf, train, test)) # (0.7809684655761157, 0.7104617034553192)
- 有Categorical features选项的代码-分类
from catboost import CatBoostClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
data = pd.read_csv("ctr_train.txt", delimiter="\t")
del data["user_tags"]
data = data.fillna(0)
X_train, X_validation, y_train, y_validation = train_test_split(data.iloc[:,:-1],data.iloc[:,-1],test_size=0.3 , random_state=1234)
categorical_features_indices = np.where(X_train.dtypes != np.float)[0] #找出类别变量
model = CatBoostClassifier(iterations=100, depth=5,cat_features=categorical_features_indices,learning_rate=0.5, loss_function='Logloss',
logging_level='Verbose')
model.fit(X_train,y_train,eval_set=(X_validation, y_validation),plot=True) #开始训练
#将plot = ture 打开后,catboot包还提供了非常炫酷的训练可视化功能,从下图可以看到我的Logloss正在不停的下降。
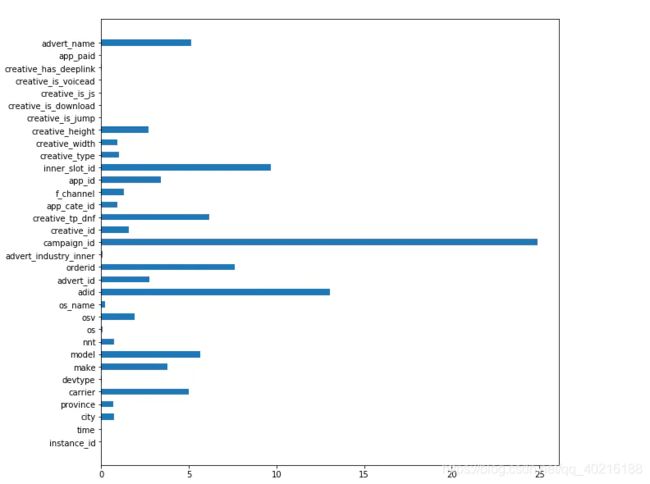
训练结束后,通过model.feature_importances_属性,我们可以拿到这些特征的重要程度数据,特征的重要性程度可以帮助我们分析出一些有用的信息。
import matplotlib.pyplot as plt
fea_ = model.feature_importances_
fea_name = model.feature_names_
plt.figure(figsize=(10, 10))
plt.barh(fea_name,fea_,height =0.5)
- CatBoost回归
rom catboost import CatBoostRegressor
# Initialize data
train_data = [[1, 4, 5, 6],
[4, 5, 6, 7],
[30, 40, 50, 60]]
eval_data = [[2, 4, 6, 8],
[1, 4, 50, 60]]
train_labels = [10, 20, 30]
# Initialize CatBoostRegressor
model = CatBoostRegressor(iterations=2,
learning_rate=1,
depth=2)
# Fit model
model.fit(train_data, train_labels)
# Get predictions
preds = model.predict(eval_data)
print(preds)