[论文解读]Learning Relationships for Multi-View 3D Object Recognition.
Yang, Ze and Liwei Wang. “Learning Relationships for Multi-View 3D Object Recognition.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019): 7504-7513.
目录
一. 前言
1.研究背景及目的:
2.文章贡献:
3.基础原理
二. 方法
1.解决问题的关键因素:
2.概述
3.增强块
4.归一化
5.集成块
三. 实验介绍
1.数据集
2.实现细节
四. 结论
一. 前言
1.研究背景及目的:
对于3D对象的特定部分,如果从不同的视点渲染3D形状,它将被投影到2D平面中的不同空间位置。视图汇集操作忽略了来自不同视点的2D外观之间的空间相关性,因此,来自不同视点的对应区域没有对齐,并且来自不同视点的信息不能被有效地组合。此外,视图共享策略平等地对待所有视图,而不考虑不同视图之间的关系以及每个视图的辨别能力。
本文提出了一种关系网络来有效地连接来自不同视点的相应区域,从而增强单个视点图像的信息。此外,关系网络利用一组视图之间的相互关系,并整合这些视图以获得有区别的三维对象表示。
2.文章贡献:
- 与以前的多视图三维对象识别方法不同,我们利用一种新的基于关系的框架来专门建模多视图输入数据上的区域-区域关系和视图-视图关系。
- 我们提出了一种用于三维物体识别和检索的关系网络。该模型包含几个增强和集成模块。增强块通过对其内部区域和其他视图中相应区域之间的关系进行建模来增强单个视图的信息。集成块对视图之间的相互关系进行建模,并集成来自这些视图的信息,以生成最终的3D对象描述符。
- 我们的模型可以进行端到端的训练,并且我们在ModelNet数据集上演示了我们的模型的有效性。我们提出的方法在三维目标识别和检索任务上都优于现有模型。
3.基础原理
采用了两个基本的构建块,即增强块和集成块。强化模块负责探索区域与区域之间的关系,以强化每个单独视图的信息;集成块负责建模视图到视图的关系,以便有效地集成来自单个视图的信息。具体地,对于给定视图图像的特征图,特征图中的每个空间位置是对应于图像中某个区域的特征向量。对于给定视图图像中的每个区域,增强块从其他视图中找到匹配/相关区域,并通过利用来自匹配区域的线索来增强该区域的信息。这样,视图的信息可以得到加强。之后,集成块采用自关注选择机制来为每个视图生成重要性分数,这表示该视图的相对辨别能力。
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第1张图片](http://img.e-com-net.com/image/info8/5ffc12fc047f4c77bdd805c26684a8d1.jpg)
二. 方法
1.解决问题的关键因素:
第一,模拟区域与区域之间的关系。在3D对象的某些部分不能从某个特定视点清晰理解的情况下(例如,部分遮挡、反射、不完整),可以从其他视点找到缺失的信息。对于给定的视图图像,如果存在匹配其内部的区域和其他视图中的对应区域的策略,则可以通过利用匹配区域之间的关系来增强该给定视图的信息。
第二,建模视图到视图的关系。在3D对象的几个部分从某些视点完全不可见的情况下,仅仅建模区域到区域的关系不能进一步帮助那些视图获得关于不可见部分的信息。我们需要对视图到视图的关系进行建模,以确定每个视图的辨别能力,并进一步整合这些视图以获得最终的3D对象描述符。
2.概述
我们的方法基于这样的假设,即连接来自不同视图的对应区域并推理它们之间的关系可以帮助视图更好地表征3D对象。因此,对于给定视图中的每个区域,最初的目标是从其他视图中定位其对应的区域。在形式上,我们将X = {X1,X2,....,XN}定义为描述3D对象X的视图序列,其中N是视图的数量。为了获得区域级特征,我们从卷积层而不是全连通层提取特征。具体而言,对于每个视图Xi,其卷积特征图Ri∈ RL×L×Dr可以被视为L×L特征向量,每个特征向量是对应于视图Xi中的区域的Dr维表示:
![]()
对于来自视图Xi的区域特征rij,增强块枚举视图序列中所有可能的区域,并使用成对匹配函数M来计算rij和每个枚举区域rmn的特征之间的标量Mij,mn,表示这两个区域的关联程度:
![]()
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第2张图片](http://img.e-com-net.com/image/info8/8a869ffc8265493f891eefc50cf44cbb.jpg)
这里rij可以表示蓝色框,rmn表示红色框。
然后,区域特征rij由所有列举的区域根据它们与rij的匹配分数来加强。我们将增强区域特征表示为r*ij,它利用了其他视图中相应区域的信息。我们将视图Xi的增强特征图Rj*∈Rl×l×Dr表示为:

之后,我们通过网络的下一部分发送增强特征图R*i,并获得视图Xi的增强特征向量f*i∈RDf。请注意,单个视图的特征向量f*i不能封装关于3D对象的所有信息,因为3D对象的某些部分可能从其视点完全隐藏,所以我们不能通过区域匹配来获取这些部分的缺失信息。因此,为了获得3D对象的完整表示,我们需要组合来自多个增强特征向量的信息。为了取得这样的进展,我们提出了一个集成块,它利用了增强特征向量之间的相互关系,并为每个特征向量生成一个重要性分数。最后,所有增强的特征向量和它们的重要性分数被联合考虑以生成单个紧凑的3D对象描述符。
3.增强块
对于每个视图图像Xi,增强块旨在开发区域与其他视图之间的区域关系,这进一步有助于增强和精炼Xi的信息。特征提取器为视图Xi生成一组特征向量Ri= {ri1,ri2,···,riL2},其中每个特征向量rij是对应于视图Xi的一个部分区域的Dr维表示。匹配函数M可以计算任意两个区域特征rij与rmn之间的匹配分数Mij, mn。这里我们选择嵌入的点积函数作为匹配函数。在这种情况下,我们首先将输入r1,r2∈RDr线性嵌入到具有可学习嵌入矩阵Wr∈RDe×Dr的隐藏空间中,然后计算它们的点积相似度作为匹配分数:
![]()
在得到不同区域之间的匹配分数后,我们将rij的匹配矩阵表示为:
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第3张图片](http://img.e-com-net.com/image/info8/4a857cca97c74db1ab7aea621d243141.jpg)
由于嵌入隐藏空间的低维De,使用高度优化的矩阵乘法码可以有效地计算匹配矩阵。直观上,与rij匹配得分较高的区域更有可能代表3D物体的相同部分,因此更有可能增加rij的信息。我们首先对匹配矩阵进行归一化,然后计算增强区域特征
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第4张图片](http://img.e-com-net.com/image/info8/0acd2d537e0247209fe740fc5843ebbc.jpg)
其中,我们将g解释为一种投影,它将区域特征映射到具有一些良好性质的空间中(例如,区域特征的信息可以很容易地融合)。通过计算所有枚举区域特征的加权和(在投影空间内)来增强rij信息,每个区域特征的权重是其与rij的归一化匹配得分。函数f是将加权和注入原始区域特征空间的映射。为简单起见,我们考虑f和g为线性映射的情况,即g(x) = Wgx和f(x) = Wfx,其中Wg∈RDg×Dr和 Wf∈RDr×Dg是学习参数,为了简单起见,我们省略了偏置项。增强块是光滑和可微的,使网络端到端可训练。注意,我们在增强块中使用了一个残余连接。残差连接使网络更易于优化,补强块可以从身份映射开始,逐步向任务导向转变。
4.归一化
接下来,我们将描述如何对匹配矩阵进行归一化。
Normalizing across views. 在这个设置中,匹配矩阵使用缩放的softmax函数对所有条目进行归一化:
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第5张图片](http://img.e-com-net.com/image/info8/6fdbb23649994b12abf00085587b6330.jpg)
其中De是Wr的行大小。但是,这种策略可能会导致占优现象,即匹配矩阵被很少的条目占优。在我们的任务中,对于参考视图中的给定区域,我们希望在其他视图中找到足够的与给定区域匹配的区域。
Normalizing inside Views. 在此设置下,将匹配矩阵的每一行单独归一化:
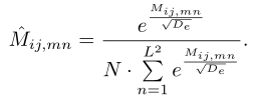 (9)
(9)
在这种情况下,匹配得分是标准化的区域内的每个视图。具体来说,对于参考视图中的一个给定区域,该方法分别从每个视图中选择最优匹配区域,然后将所有匹配区域进行组合,以增强给定区域的信息。我们在增强块中使用这种归一化策略。
5.集成块
给定所有视图的增强特征向量,目标是整合它们并生成3D对象的最终表示。在最简单的设置下,可以通过对所有增强特征向量的视图池操作来表示三维物体特征。然而,在这种情况下,不同观点之间的关系和每个观点的区别权被忽略了。
我们提出了一个通用的集成块来建模不同视图之间的相互关系,并给每个视图分配一个重要评分。基于所有增强特征向量及其重要性评分,得到最终的三维物体描述符。直观地说,为了确定某个视图是否具有歧视性,我们还需要查看其他视图。因此,使用一元函数来计算每个视图的重要性得分是不理想的。换句话说,对于每个增强特征向量f*i∈RDf,应根据f*i与所有其他增强特征向量之间的关系计算其重要性评分。形式上,我们定义重要性函数L,以如下形式计算每个增强特征向量f*i的重要性评分Ii:

我们将重要性函数L设计为成对函数的组合,如下所示:
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第6张图片](http://img.e-com-net.com/image/info8/bab91d3b9d1c4d15add0d3c6a83cafef.jpg)
其中R是一个标量成对函数。在不失一般性的前提下,我们使用嵌入的点积函数R(f*1,f*2)=
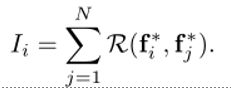
我们使用ReLU归一化对重要性分数进行归一化,如公式所示。注意,在这里使用softmax函数可能会导致梯度饱和的问题,因此使训练不稳定。然后将输出f计算为增强特征向量的凸组合:
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第7张图片](http://img.e-com-net.com/image/info8/989bf5634af74fae84233265d3761f72.jpg)
(13)
然后我们发送f遍历其余全连接层,以获得最终的3D对象表示。
三. 实验介绍
为了与之前的方法进行公平的比较,我们使用VGG-M网络作为基础模型。通过在体系结构中插入加强块和集成块,我们构建了一个关系网络。默认情况下,增强块插入在conv5层之后,积分块插入在fc6层之后。注意,构建块可以放置在网络的不同位置。按照类似的方案,可以构造更多与其他基本架构集成的变体。
与现有的作品相比,我们的增强块和集成块在三维物体识别方面有几个独特的优势:1)非局部块不区分空间和时间关系。与视频不同,对象存在于每个视图中。在我们的解决方案(Eqn. 9)中,对于参考视图中的一个给定区域,reinforce块独立地从每个视图中选择最佳匹配区域,这种策略鼓励给定区域从所有其他视图中获得信息。2)在我们的积分块中,我们使用ReLU函数(Eqn. 13)对重要性分数进行归一化,它可以看作是Softmax函数的一阶近似,具有更好的性能和更稳定的训练。据我们所知,我们是第一个将自注意模型连接到多视点三维物体识别,并解决了三维物体识别中不同视点之间区域不对齐的问题。
1.数据集
我们使用ModelNet数据集来评估关系网络的性能。ModelNet目前包含来自662个类别的127,915个3D CAD模型。这些模型是通过在线搜索引擎收集的,并由工作人员在Amazon Mechanical Turk上注释。ModelNet40是一个子集,包括来自40个类别的12,311个模型,这些模型被分成9,843个训练示例和2,468个测试示例。此外,ModelNet10是由来自10个类别的4,899个模型组成的另一个子集,这些模型被分为3,991个训练示例和908个测试示例。ModelNet40和ModelNet10都有很好的注释,可以在线下载。注意,在不同的类中示例的数量是不相等的,因此我们在前面的工作中报告了平均实例准确性和平均类准确性。平均实例准确率计算所有示例中正确预测示例的百分比,而平均类准确率是每个类每个准确率的平均值(每个类的准确率之和/总类数)。
2.实现细节
在我们所有的实验中,我们使用ImageNet上预先训练的VGG-M作为基础模型。这使得我们能够与大多数基于VGG-M的现有方法进行公平的比较。我们使用学习率0.001、动量0.9的SGD优化器,并使用随机水平视图翻转和重量衰减0.0001来减少过拟合。
多视图输入生成,我们假设形状沿着特定的轴(如z轴)垂直方向,我们设置虚拟摄像机指向网格的质心,从地平面升高30度。视点被圈起来,以给定的角度θ围绕轴放置。我们默认设置θ = 30°,这为每个3D对象生成12个视图。在后面我们研究了θ(视图数)的影响。
表1给出了三维物体识别与检索的实验结果及对比。我们提出的方法在ModelNet40数据集上达到了94.3%/92.3%的平均实例/类准确率,在ModelNet10数据集上达到了95.3%/95.1%的平均实例/类准确率,证明了我们的方法的有效性。注意,关系网络使用单模态输入,而其他一些方法使用多模态输入和更高级的深层网络。MHBN[47]是一个强有力的竞争对手,它在ModelNet40数据集上实现了94.1%的平均实例精度。然而,MHBN对浏览次数很敏感,我们观察到当浏览次数从6增加到12时,性能下降。此外,MHBN需要计算双线性特征和奇异值分解(SVD)在实际应用中是一种繁琐且计算量大的方法。在三维目标检索任务中,我们的关系网络在82.7 mAP下获得了最佳的检索性能。然而,关系网络的特征是直接训练分类,因此没有优化检索。根据原文MVCNN的建议,我们进一步采用低秩马氏度量W,直接将三维物体特征投影到128维空间中,使得投影空间中的类内距离更小,类间距离更大。与之前的工作类似,我们采用[36]的大裕度度量学习算法和实现。通过学习低秩马氏矩阵,我们的关系网络进一步获得了86.7检索mAP的最佳性能。精度查全曲线如图3所示。
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第8张图片](http://img.e-com-net.com/image/info8/065de50e64a442c4b0e1ce840896f63a.jpg)
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第9张图片](http://img.e-com-net.com/image/info8/299168d9f16648628185db6ef840c184.jpg)
视图数量影响. 为了研究视图数量对分类性能的影响,我们改变视图数量进行训练和测试。我们将其与MVCNN[39]、RCPCNN[44]、GVCNN[10]和MHBN[47]进行比较。比较方法的准确性取自Y u et al.[47]和Wang et al.[43]。表2提供了ModelNet40数据集上的平均实例精度。可以看出,我们的关系网络比以前的方法有更好的性能或可与之媲美。表2显示,当视图数量从6增加到12时,前面的方法会受到性能下降的影响。然而,我们的关系网络受益于视图数量的增加,表明关系网络能够稳健地建模视图之间的关系。
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第10张图片](http://img.e-com-net.com/image/info8/5ff8a24814c44b29a8100e6444b810ea.jpg)
构建块的影响. 为了分析关系网络中不同组件的影响,我们在ModelNet40上设计了不同的运行设置,以研究构建块的位置和数量。注意,VGG-M网络是一个相对较浅的网络,只有5个卷积层和2个全连接层。因此,集成块被放置在两个完全连接的层之间。我们研究块的位置和数量。表3比较了添加在VGG-M不同位置的单个补强块,我们发现在conv5之后放置补强块的效果略好
我们假设这是因为卷积有一个更大的接受域,这使得不同观点之间的区域匹配更容易。如表3所示,当我们将integration块替换为view池策略时,性能从94.3下降到93.8。表4显示了在网络中放置多个加强块的结果。我们发现,如果不插入补强块,性能会略有下降,多放补强块并不能提高性能。
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第11张图片](http://img.e-com-net.com/image/info8/530b1298411748f4a31561db5462bc30.jpg)
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第12张图片](http://img.e-com-net.com/image/info8/723abd64859842cd9d8f4d1ea42a6d07.jpg)
关注的可视化. 我们进一步从测试集中选择一些三维模型,并在图5和图4中可视化增强块和集成块的行为。对于给定的参考区域,我们从其他视图的特征图中找到conv5之后的加固块计算出的最对应的面元,并在图5中绘制橙色矩形。我们发现增强块很好地聚焦在来自其他视图的相应区域上。图4显示了由集成块计算的不同视图的重要性分数。我们发现,视图中包含更多辨别部分的3D对象将被赋予更高的重要性分数。那么学习到的注意力是有意义的,并且符合人类的直觉。
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第13张图片](http://img.e-com-net.com/image/info8/4330401f6bd94b3c8136925e180ff361.jpg)
![[论文解读]Learning Relationships for Multi-View 3D Object Recognition._第14张图片](http://img.e-com-net.com/image/info8/7b725c8443b24bb99fcb0f5bddf44680.jpg)
四. 结论
本文提出了一种基于关系网络的三维物体识别与检索方法。区域到区域关系和视图到视图关系都被考虑在内。关系网络是端到端可训练的,并在ModelNet数据集上实现了最先进的性能。为了更好地理解我们的框架,我们进行了系统的实验来研究我们方法中不同成分的影响。我们发现,学习的注意力很好地符合人类的直觉。