篇一:数据挖掘之分析部分
来源:https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl
目录
一.数据的总体了解
1.1 维度:data.shape
1.2 类型等基本信息:data.info()
1.3 统计信息:data.describe()
二.数据的深入了解
2.1 数据类型
2.1.1分类数据
2.1.2数值数据
2.2 数据分布:
2.2.1分类数据的分布
2.2.2离散型数据的分布
2.2.3连续型数据的分布
三.数据的特殊了解
3.1 缺失值
3.2 唯一值
四.数据的关系了解
4.1特征变量与特征变量之间
4.2特征变量与目标变量之间
一.数据的总体了解
数据读取全部采用data = pd.read_csv()格式
1.1 维度:data.shape
data.shape1.2 类型等基本信息:data.info()
给出样本数据的相关信息概览 :行数,列数,列索引,列非空值个数,列类型,内存占用,注意观察是否有连续型数据,离散型数据
data_train.info()

1.3 统计信息:data.describe()
生成描述性统计,总结数据集分布的中心趋势,分散和形状,不包括NaN值。
data.describe()
二.数据的深入了解
2.1 数据类型
- 特征一般由类别型数据和数值型数据构成,而数值型数据又分为离散型数据和连续型数据
-
类别型特征有时具有非数值关系,有时也具有数值关系。比如‘grade’中的等级A,B,C等,是否只是单纯的分类,还是A优于其他要结合业务判断。
2.1.1分类数据
category_fea = [x for x in data_train.columns if data_train[x].dtype == np.object]2.1.2数值数据
numerical_fea = [x for x in data_train.columns if data_train[x].dtype != np.object]数值型变量分析,数值型肯定是包括连续型变量和离散型变量
这里只是假设特征中特征值不重复的个数<10的特征判定为离散数据,具体还要根据字段分析
#过滤数值型类别特征
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)2.2 数据分布:
2.2.1分类数据的分布
- 文字形式
data_train['grade'].value_count()- 图表形式
import matplotlib.pyplot as plt
import seaborn as sns
for i in category_fea:
plt.figure(figsize=(8, 8))
sns.barplot(data_train[i].value_counts(dropna=False)[:20],
data_train[i].value_counts(dropna=False).keys()[:20])
plt.show()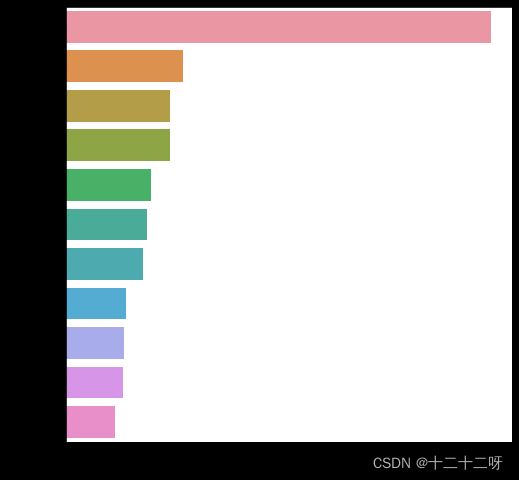
2.2.2数值离散型变量的分布
# 数值类别型变量分析
for i in numerical_noserial_fea:
print(data_train[i].value_counts())
print("\n")输出示例:
- 如果类别个数之间相差悬殊,用不用再分析
- 如果输出只有一个类别,则该变量特征无价值,考虑删除
3 606902 5 193098 Name: term, dtype: int64
2.2.3数值连续型数据的分布
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
- 如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
- 正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
data_train[numerical_serial_fea].hist(bins=50,figsize=(16,12))
三.数据的特殊了解
3.1 缺失值
- 纵向了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于查看某一列nan存在的个数是否真的很大,如果nan存在的过多,说明这一列对label的影响几乎不起作用了,可以考虑删掉。如果缺失值很小一般可以选择填充.
- 另外可以横向比较,如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
- 比赛大杀器lgb模型可以自动处理缺失值
- 有多少列存在缺失值
data_train.isnull().any().sum()- 缺失特征中,缺失率大于50%的特征
have_null_fea_dict = (data_train.isnull().sum()/len(data_train)).to_dict()
fea_null_moreThanHalf = {}
for key,value in have_null_fea_dict.items():
if value>0.5:
fea_null_moreThanHalf[key] = value
fea_null_moreThanHalf- 可视化查看缺失率和缺失特征
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()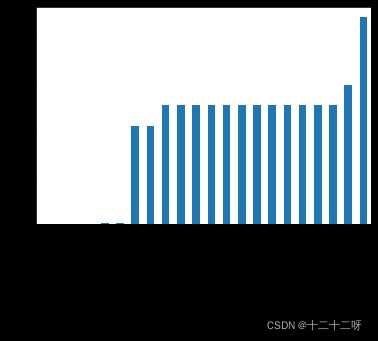
3.2 唯一值
one_value_fea = [col for col in data_train.columns if data_train[col].nunique()<=1]四.数据的关系了解
4.1特征变量与特征变量之间
import seaborn as sns
plt.subplots(figsize=(16,9))
correlation_mat = train[cont_features].corr()
sns.heatmap(correlation_mat,annot=True)
4.2特征变量与目标变量之间
- 数值型特征变量与目标变量之间关系
train_loan_fr = data_train.loc[data_train['isDefault'] == 1]
train_loan_nofr = data_train.loc[data_train['isDefault'] == 0]
for col in data_train[numerical_serial_fea].columns:
if col!='isDefault':
sns.boxplot(x = "isDefault", y=col, saturation=0.5, palette=['g','r'], data=data_train)
plt.title(col)
plt.show()
- 类别型特征变量与目标变量之间关系
for col in data_train[category_fea].columns:
print(col)
fig, ((ax1, ax2)) = plt.subplots(1, 2, figsize=(15, 8))
train_loan_fr.groupby(col)[col].count().plot(kind='barh', ax=ax1, title='Count of {} fraud'.format(col))
train_loan_nofr.groupby(col)[col].count().plot(kind='barh', ax=ax2, title='Count of {} non-fraud'.format(col))
plt.show()