Python+OpenCV实用案例应用教程:建立自定义物体检测器
本章将深入探讨物体检测的概念,这是计算机视觉中最常见的挑
战之一。既然在这本教程中已经讲了很多内容了,读到这里,你也许会
想,什么时候才能把计算机视觉应用实践中呢。你是否想过建立一个
系统来检测车辆和人呢?实际上,你离目标已经不远了。
在前面的章节中,我们已经研究了一些物体检测和识别的具体例
子。我们在第5章中关注的是直立、正面的人脸,在第6章中关注的是
具有类似角点或者类似斑点特征的物体。在本章中,我们将探讨具有
良好泛化性能或推广能力的算法,在某种意义上,这些算法可以应对
存在于给定物体类中的真实世界的多样性。例如,不同车辆有不同的
设计,人们所穿的衣服不同,呈现出的形状也不同。
本章将介绍以下主题:
·学习另一种特征描述符:面向梯度直方图(Histogram of
Oriented Gradient,HOG)的描述符。
·理解非极大值抑制(Non-Maximum Suppression,NMS),帮助
我们选择检测窗口集的最佳重叠。
·获得对支持向量机(Support Vector Machine,SVM)的高层次
理解。这些通用分类器是基于监督机器学习的,在某种程度上与线性
回归类似。
·基于HOG描述符用预训练分类器检测人。
·训练词袋(Bag-of-Word,BoW)分类器来检测车辆。对于这个
示例,我们将使用图像金字塔、滑动窗口和NMS的自定义实现,以便
更好地理解这些技术的内部工作原理。
本章的大多数技术并不是相互排斥的,而是作为检测器的组成部
分一起工作的。在本章结束时,你将知道如何训练和使用实际用于街
道的分类器!
7.1 技术需求
本章使用了Python、OpenCV以及NumPy。安装说明请参阅第1章。
本章的完整代码可以在本教程的GitHub库
(https://github.com/PacktPublishing/Learning-OpenCV-4-
Computer-Vision-with-Python-Third-Edition)的chapter07文件夹
中找到。示例图像可以在images文件夹中找到。
7.2 理解HOG描述符
HOG是一种特征描述符,因此它与尺度不变特征变换(Scale
Invariant Feature Transform,SIFT)、加速鲁棒特征(Speeded-Up
Robust Feature,SURF),以及ORB(这些已在第6章中介绍过)都属
于同一算法家族。与其他特征描述符一样,HOG能够提供对特征匹配以
及对物体检测和识别至关重要的信息类型。HOG常用于物体检测。该算
法——尤其是作为人的检测器——是Navneet Dalal和Bill Triggs在
论文“Histograms of Oriented Gradients for Human Detection”
(INRIA,2005)中提出的,该论文可在
https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
上找到。
HOG的内部机制非常智能,能把图像划分为若干单元,并针对每个
单元计算一组梯度。每个梯度描述了在给定方向上像素密度的变化。
这些梯度共同构成了单元的直方图表示。在第5章中使用局部二值模式
直方图研究人脸识别时,我们遇到过类似的方法。
在深入了解HOG工作原理的技术细节之前,先来了解一下HOG是如
何看世界的。
7.2.1 HOG的可视化
Carl Vondrick、Aditya Khosla、Hamed Pirsiavash、Tomasz
Malisiewicz和Antonio Torralba开发了名为HOGgles(HOG护目镜)的
HOG可视化技术。获取HOGgles摘要以及代码和出版物的链接,请参阅
Carl Vondrick在麻省理工学院的网页
http://www.cs.columbia.edu/~vondrick/ihog/index.html。
Vondrick等人使用一辆卡车照片作为其中一幅测试图像,如图7-1所
示。
Vondrick等人基于Dalal和Triggs早期论文中的一种方法,生成了
HOG描述符的可视化结果,如图7-2所示。


然后,Vondrick等人利用HOGgles对特征描述算法进行反演,重构
HOG所看到的卡车图像,如图7-3所示。

在这两个可视化中,你可以看到HOG把图像划分为多个单元,而且
可以很容易地识别出车轮以及车辆的主要结构。在图7-2的可视化中,
每个单元的计算梯度可视化为一组纵横交错的线,有时看起来像一颗
拉长的星星,星星的轴越长,梯度也就越强。在图7-3的可视化中,沿
着单元的不同轴,将梯度可视化为亮度的一种平滑过渡。
现在,我们来进一步考虑HOG的工作方式,以及它对物体检测解决
方案的贡献。
7.2.2 使用HOG描述图像的区域
对于每个HOG单元,直方图包含箱体(bin)的数量与梯度的数量
相等,或者说HOG考虑的是轴方向的数量。计算完所有的单元直方图之
后,HOG会处理一组直方图以产生更高级别的描述符。具体来说就是这
些单元将组合成称为“块”的更大区域。这些块可以由任意数量的单
元组成,但是Dalal和Triggs发现,在进行人员检测时,2×2的单元块
产生的结果最好。创建块大小的矢量,这样就可以对其进行标准化,
补偿局部的光照和阴影变化。(单个单元太小,无法检测到这些变
化。)这种标准化提升了基于HOG的检测器在光照条件变化时的鲁棒
性。
和其他检测器一样,基于HOG的检测器需要处理物体位置和尺度的
变化。在图像上移动一个固定大小的滑动窗口可以解决在不同位置搜
索的需求。将图像缩放到各种大小,形成一个所谓的图像金字塔,可
以解决在各种尺度上进行搜索的需求。在5.2节,我们已学习了这些技
术。但是,我们来详细说明一个难点:如何在重叠窗口中处理多个检
测。
假设我们正在使用滑动窗口在图像上执行人员的检测。我们以小
的步长滑动窗口,每次只滑动几个像素,因此我们期望它能够多次框
入所有给定的人。假设重叠检测到的确实是一个人,我们不希望报告
多个位置,而是只报告我们认为正确的一个位置。或者说,即使在给
定位置的检测结果有很好的置信度,如果重叠检测结果有更好的置信
度,那么我们可能会拒绝它,因此,对于一组重叠检测结果,我们将
选择具有最好置信度的检测结果。
这就是NMS发挥作用的地方。给定一组重叠区域,我们可以抑制
(或拒绝)分类器没有产生最大分数的所有区域。
7.3 理解非极大值抑制
非极大值抑制(NMS)的概念听起来可能很简单,即从一组重叠的
解中选出一个最好的!但是,其实现要比你最初想象的复杂得多。还
记得图像金字塔吗?重叠检测可以发生在不同的尺度上。我们必须收
集所有的正检测,并在检查重叠之前将它们的边界转换到常规尺度。
下面是NMS的一个典型实现方法:
(1)构建图像金字塔。
(2)对于物体检测,用滑动窗口方法扫描金字塔的每一层。对于
每个产生正检测结果(超过某个任意置信度阈值)的窗口,将窗口转
换回原始图像尺度。将窗口及其置信度添加到正检测结果列表中。
(3)将正检测结果列表按照置信度降序排序,这样最佳检测结果
就排在了第一的位置。
(4)对于在正检测结果列表中的每个窗口W,移除与W明显重叠的
后续窗口,就得到一个满足NMS标准的正检测结果列表。
除了NMS,过滤正检测结果的另一种方法是淘汰所有子窗
口。在谈到子窗口(或者子区域)时,我们指的是完全包含在另一个
窗口(或者区域)内的窗口(或者图像中的区域)。要检查子窗口,
只需要比较各种窗口矩形的角点坐标。我们会在7.5节中第一个实际示
例中采用这种简单方法。也可以将NMS和子窗口抑制结合在一起。
这些步骤中有几个步骤是迭代的,因此就有一个有趣的优化问
题。Tomasz Malisiewicz在
http://www.computervisionblog.com/2011/08/blazing-fast-nmsm-
from-exemplar-svm.html上提供了一个基于MATLAB的快速示例实现。
Adrian Rosebrock在
https://www.pyimagesearch.com/2015/02/16/faster-non-maximum-
suppression-python/上提供了该示例实现到Python的一个端口。
7.7.2节中的示例将在该示例实现的基础上进行构建。
那么,如何确定窗口的置信度呢?我们需要一个分类系统来确定
是否存在某个特征,以及分类的置信度。这就是支持向量机发挥作用
的地方。
7.4 理解支持向量机
在不深入研究支持向量机工作细节的情况下,我们来试着理解它
在机器学习和计算机视觉的背景下可以帮助我们完成什么。给定有标
记的训练数据,支持向量机通过寻找最优超平面来学习分类同类数
据。简单地说,该超平面是对不同标记数据进行最大限度划分的平
面。为了帮助我们理解,我们来考虑图7-4,这是扎克·韦恩伯格
(Zach Weinberg)Creative Commons Attribution-Share Alike 3.0
Unported License下的示例。
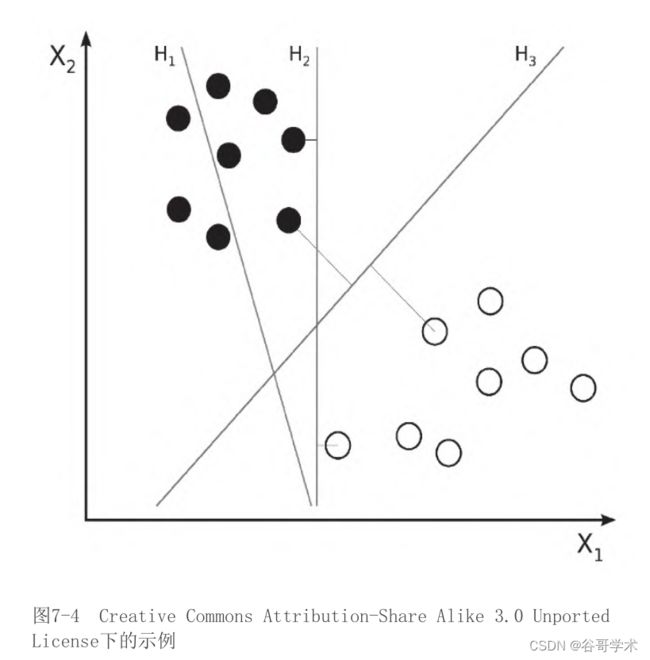
超平面H 1 并没划分这两个类(黑色点和白色点)。超平面H 2 和H 3 都
划分了类,但是只有超平面H 3 以最大限度划分了类。
假设我们正在训练一个支持向量机作为人员检测器。我们有两个
类:人和非人。我们提供包含人或者不包含人的各种窗口的HOG描述符
的向量作为训练样本。这些窗口可能来自不同的图像。支持向量机通
过寻找最优超平面来学习,该超平面最大限度地把多维HOG描述符空间
划分为人(在超平面的一侧)和非人(在超平面的另一侧)两类。之
后,当给训练过的支持向量机提供一个HOG描述符向量(来自任何图像
的任何其他窗口)时,支持向量机可以判断该窗口是否包含人。支持
向量机甚至可以给出与向量到最优超平面的距离有关的置信度值。
支持向量机模型在20世纪60年代初就出现了。然而,从那时起,
它经历了改进,现代支持向量机实现的基础可以在Corinna Cortes和
Vladimir的论文“Support-vector networks”(Machine Learning,
1995)中找到。该论文网址为
http://link.springer.com/article/10.1007/BF00994018。
既然我们已经对实现物体检测器的关键组件有了概念上的理解,
那么就来看几个例子。我们先研究OpenCV的一个现成物体检测器,然
后再继续设计和训练自定义物体检测器。
7.5 基于HOG描述符检测人
OpenCV自带一个能够进行人员检测的名为cv2.HOGDescriptor的
类。该接口与我们在第5章中用过的cv2.CascadeClassifier类有一些
类似之处。但是,与cv2.CascadeClassifier不同,
cv2.HOGDescriptor有时返回嵌套的检测矩形。或者说,
cv2.HOGDescriptor可能告诉我们它检测到某个人的矩形框完全位于另
一个人的矩形框内。这种情况是有可能的,例如,一个孩子可能站在
一个成年人的前面,而且孩子的矩形框可能完全落在成年人矩形框
内。但是,在常规情况下,嵌套检测可能是错误的,因此
cv2.HOGDescriptor经常和过滤所有嵌套检测的代码一起使用。
我们通过测试来确定矩形是否嵌套在另一个矩形中,首先需要编
写测试的实现脚本。为此,我们将编写函数is_inside(i,o),此处,i
是可能的内部矩形,o是可能的外部矩形。如果i在o内,函数将返回
True,否则,函数返回False。下面是脚本的开头部分:
 现在,我们创建一个cv2.HOGDescriptor实例,通过运行下列代码
现在,我们创建一个cv2.HOGDescriptor实例,通过运行下列代码
指定它将使用OpenCV内置的默认人员检测器:

请注意,我们使用setSVMDetector方法指定人员检测器。希望根
据本章前一节的内容,这能讲得通。支持向量机是一个分类器,因此
支持向量机的选择决定了cv2.HOGDescriptor将要检测的物体类型。
现在,加载一幅图像(在本例中,为正在干草地里工作的妇女的
一张旧照片),尝试运行以下代码来检测图像中的人:

请注意,cv2.HOGDescriptor有一个detectMultiScale方法,它返
回两个列表:
(1)检测到的物体(在本例中是检测到的人)的矩形框列表。
(2)检测到的物体的权重或者置信度列表。值越高表示检测结果
正确的置信度也就越大。
detectMultiScale接受几个可选参数,包括:
·winStride:这个元组定义了滑动窗口在连续的检测尝试之间移动
的x和y距离。HOG可以很好地处理重叠窗口,因此相对于窗口大小,
步长可能较小。步长越小,检测次数越多,计算成本也越高。默认步
长是让窗口无重叠,也就是与窗口大小相同,即(64,128),用于默认的
人员检测器。
·scale:该尺度因子应用于图像金字塔的连续层之间。尺度因子越
小,检测次数越多,计算成本也会越高。尺度因子必须大于1.0,默认
值是1.5。
·finalThreshold:这个值决定检测标准的严格程度。值越小,严格
程度越低,检测次数越多。默认值是2.0。
现在,对检测结果进行过滤,去掉嵌套矩形。要确定矩形是否是
嵌套矩形,我们可能需要将其与其他所有矩形进行比较。请注意,下
面的嵌套循环使用了is_inside函数:


最后,绘制其余的矩形和权重,以突出显示检测到的人,并显示
和保存可视化结果:
 如果运行脚本,你会看到图像中的人周围都有矩形,如图7-5所
如果运行脚本,你会看到图像中的人周围都有矩形,如图7-5所
示。 这张照片是谢尔盖·普罗库金–戈尔斯基(Sergey Prokudin-
这张照片是谢尔盖·普罗库金–戈尔斯基(Sergey Prokudin-
Gorsky,彩色摄影的先驱)的另一个作品。这张照片拍摄于1909年,其
中的场景位于俄罗斯西北部的卢辛斯基修道院。
对于离摄像头最近的6名女性,成功地检测到5名。与此同时,背
景中的一个塔被错误地检测为人。在实际应用中,通过分析视频中的
一系列帧可以提升人的检测结果的准确性。例如,想象我们正在看卢
辛斯基修道院干草地的一个监控录像,而不是一张单独的照片。我们
应该能够添加代码来确定这座塔不可能是一个人,因为它没有移动。
此外,我们应该能够在其他帧中检测到其他的人,并跟踪每个人在帧
与帧之间的运动。我们将在第8章讨论人的跟踪问题。
接下来将研究另一种物体检测器,并训练它来检测给定类型的物
体。
7.6 创建并训练物体检测器
使用预训练过的检测器建立快速原型很容易,非常感谢OpenCV的
开发人员,是他们让人脸检测和人员检测等功能变得触手可及。但
是,无论是业余爱好者还是计算机视觉专业人士,都不可能只处理人
和人脸。
此外,如果你和本教程的作者一样,你会想知道最初是如何创建
“人员检测器”的,以及是否可以对其进行改进。此外,你可能还想
知道是否可以应用相同的概念来检测从汽车到精灵的不同物体。
事实上,在工业上,你可能不得不处理检测非常具体的物体(如
注册牌照、教程的封面,或者对雇主或客户来说,所有可能重要的内
容)的问题。
因此,问题是如何产生我们自己的分类器?
有许多流行的方法。在本章的其余部分,我们将看到其中之一依
赖于支持向量机和BoW技术。
我们已经讨论过支持向量机和HOG了。现在,我们来仔细研究一下
BoW。
7.6.1 理解BoW
最初,BoW(词袋)的概念并不是为计算机视觉设计的,而是我们
在计算机视觉的背景下使用了这个概念的进化版本。我们先来讨论BoW
的基本版本,正如你可能已经猜到的那样,BoW最初属于语言分析和信
息检索领域。
有时,在计算机视觉背景下,BoW被称为视觉词袋(Bag of
Visual Word,BoVW)。但是,我们还是使用BoW,因为这是OpenCV
使用的术语。
BoW是一种技术,通过BoW可以给一系列文档中的每个单词指定权
重或计数,然后用这些计数的向量表示这些文档。我们来看一个例
子:
·文档1:I like OpenCV and I like Python。
·文档2:I like C++and Python。
·文档3:I don’t like artichokes。
利用这3个文档,我们可以构建一个字典,也称为码本
(codebook)或词表(vocabulary),其值如下:

它有8个元素。现在我们使用8个元素的向量来表示原始文档。对
于给定的文档,每个向量包含的值表示按字典中的顺序计算所有单词
的数量。上述三个句子的向量表示如下:

可以把这些向量概念化为文档的直方图表示,或者概念化为用来
训练分类器的描述符向量。例如,可以根据这样的表示将文档分类为
垃圾邮件或非垃圾邮件。事实上,垃圾邮件过滤是BoW的众多实际应用
之一。
既然我们已经掌握了BoW的基本概念,那么就来看看如何将BoW应
用于计算机视觉领域吧!
7.6.2 将BoW应用于计算机视觉领域
现在,我们已经熟悉了特征和描述符的概念。我们曾使用SIFT和
SURF等算法从图像的特征中提取描述符,以便在另一幅图像中匹配这
些特征。
目前,我们还掌握了基于码本或字典的另一种描述符。我们学习
了支持向量机,它可以接受标记的描述符向量作为训练数据,可以找
到描述符空间在给定类中的最优划分,并可以预测新数据的类。
有了这些知识,我们可以采用以下方法来构建分类器:
(1)获取图像的一个样本数据集。
(2)对于数据集中的每一幅图像,(用SIFT、SURF、ORB或者类
似的算法)提取描述符。
(3)向BoW训练器添加描述符向量。
(4)将描述符聚成k个聚类,这些聚类的中心(质心)是视觉词
汇。最后一点可能听起来有点晦涩,但是我们将在下一节中进一步对
其进行探讨。
在这个过程的最后,我们将获得一个可供使用的视觉词汇字典。
正如你可以想象的那样,大的数据集将有助于使字典的视觉词汇更加
丰富。在某种程度上,词汇越多越好!
训练了分类器之后,我们应该对其继续进行测试。好消息是,测
试过程在概念上与前面概述的训练过程非常相似。给定测试图像,我
们可以提取描述符并通过计算描述符到质心距离的直方图来量化这些
描述符(或降低描述符的维度)。在此基础上,我们可以尝试识别视
觉词汇,并在图像中定位这些视觉词汇。
这就是本章的重点,至此你已经对建立更深入的实际示例产生了
兴趣,并渴望编写代码。但是,在继续之前,我们来快速了解一下k均
值聚类理论,以充分理解如何创建视觉词汇,从而更好地理解使用BoW
和支持向量机的物体检测过程。
7.6.3 k均值聚类
k均值(k-means)聚类是一种量化方法,借此我们可以通过分析
大量的向量得到少量的聚类。给定一个数据集,k表示该数据集将要划
分的聚类数。“均值”一词是指数学上的平均数,当直观地表示时,
聚类的均值是它的质心或聚类的几何中心点。
聚类是指将数据集中的点分组的过程。
OpenCV提供了名为cv2.BOWKMeansTrainer的类,可以用来帮助我
们训练分类器。正如你所期望的,OpenCV文档给出了这个类的摘要,
如下所述:
基于k均值的类使用词袋方法训练视觉词表。
介绍了这个冗长的理论之后,我们可以看一个例子,并开始训练
我们的自定义分类器。
7.7 检测汽车
要训练任何类型的分类器,我们必须先创建或者获取训练数据
集。我们将训练一个汽车检测器,因此数据集必须包含代表汽车的正
样例,以及代表检测器在搜索汽车时可能遇到的其他物体(非汽车)
的负样例。例如,如果检测器的目标是搜索街道上的汽车,那么路
边、人行横道、行人或者自行车的图片可能是比土星环的图片更具有
代表性的负样例。除了表示预期的主体内容,理想情况下,训练样本
应该代表特定摄像头和算法看到主体的方式。
最终,在本章,我们打算使用一个固定大小的滑动窗口,因此重
要的是训练样本要遵循固定的大小,并且为了框住没有太多背景的汽
车,应紧密裁剪正样例。
在一定程度上,在不断添加好的训练图像时,我们期望分类器的
准确率会提升。另外,大的数据集会使训练变慢,而且有可能会过度
训练分类器,以至于分类器不能推断训练集之外的样本。在本节后
面,我们将以一种允许我们轻松修改训练图像数量的方式来编写代
码,这样就能通过实验找到一个合适的大小。
如果我们要自己组建完成汽车图像的数据集(尽管这是完全可行
的),但会非常耗时。为避免重新发明车轮——或者整个汽车——我
们可以利用现成的数据集,如下所示:
·汽车检测UIUC图像数据集:
https://cogcomp.seas.upenn.edu/Data/Car/。
·斯坦福大学汽车数据集:
http://ai.stanford.edu/~jkrause/cars/car_dataset.html。
我们的示例将使用UIUC数据集。获取该数据集并在脚本中对其进
行使用,涉及几个步骤。下面来介绍每个步骤:
(1)从
http://l2r.cs.uiuc.edu/~cogcomp/Data/Car/CarData.tar.gz下载
UIUC数据集。将其解压到某个文件夹,我们称该文件夹为
(2)同样在
detect_car_bow_svm.py的Python脚本。要开始脚本的实现,编写以下
代码查看是否存在CarData子文件夹:

如果你可以运行这个脚本,并且该脚本不打印任何内容,就表示
一切正常。
(3)接下来,在该脚本中定义以下常量:

请注意,我们的分类器将有两个训练阶段:一个阶段用于BoW词
表,将使用大量图像作为样本;另一个阶段用于支持向量机,将使用
大量BoW描述符向量作为样本。我们可以为每个阶段定义不同数量的训
练样本。在每个阶段,还可以为两个类(汽车和非汽车)定义不同数
量的训练样本,但是,我们将使用相同数量的样本。
(4)我们将使用cv2.SIFT提取描述符,并使用
cv2.FlannBasedMatcher匹配这些描述符。我们用下面的代码初始化这
些算法:

请注意,我们以与第6章中使用的同样方式,初始化了SIFT和
FLANN。可是,这一次,描述符匹配并不是最终目标,相反,它将成为
BoW功能的一部分。
(5)OpenCV提供了名为cv2.BOWKMeansTrainer的类来训练BoW词
表,还提供了名为cv2.BOWImgDescriptorExtractor的类来将某种底层
描述符(在我们的示例中是SIFT描述符)转换为BoW描述符。我们用下
面的代码初始化这些对象:

在初始化cv2.BOWKMeansTrainer时,必须指定聚类数(在本示例
中是40)。在初始化cv2.BOWImgDescriptorExtractor时,必须指定描
述符提取器和描述符匹配器(在本示例中分别是之前创建的cv2.SIFT
对象和cv2.FlannBasedMatcher对象)。
(6)要训练BoW词表,需要根据各种汽车和非汽车图像提供SIFT
描述符的样本。我们将从CarData/TrainImages子文件夹加载图像,其
中包含名为pos-x.pgm的正(汽车)图像,以及名为neg–x.pgm的负
(非汽车)图像,其中x是从1开始的数字。我们编写以下实用函数来
返回到第i个正的和负的训练图像的一对路径,其中i是一个从0开始的
数字:
在本节的后面部分,当需要获取训练样本时,我们将在循环中调
用上面的函数,其值i是变化的。
(7)对于每个训练样本的路径,我们需要加载图像、提取SIFT描
述符并把描述符添加到BoW训练器中。我们编写另一个实用函数来精确
地实现这一任务,如下所示:

如果在图像中没有找到特征,那么keypoints和descriptors变量
将为None。
(8)在这一阶段,我们已经有了训练BoW词表所需的一切。我们
读取每个类(汽车作为正类,非汽车作为负类)的一些图像,并添加
到训练集,如下所示:

(9)既然已经组建好了训练集,我们将调用词表训练器的
cluster方法,执行k均值分类并返回词表。把这个词表分配给BoW描述
符提取器,如下所示:

请记住,我们前面使用SIFT描述符提取器和FLANN匹配器初始化
BoW描述符提取器。现在,我们也给BoW描述符提取器一个词表,这个
词表是我们用SIFT描述符样本训练的。在这一阶段,BoW描述符提取器
拥有了从高斯差分(Difference of Gaussian,DoG)特征提取BoW描
述符所需要的一切。
请记住,正如在6.4节中讨论的那样,cv2.SIFT检测DoG特征并
提取SIFT描述符。
(10)接下来,我们将声明另一个实用函数,接受图像并返回由
BoW描述符提取器计算的描述符向量。这涉及图像的DoG特征提取以及
基于DoG特征的BoW描述符向量的计算,如下所示:

(11)准备组建包含BoW描述符样本的另一个训练集。我们创建两
个数组来容纳训练数据和标签,并用BoW描述符提取器生成的描述符填
充这两个数组。我们将每个描述符向量标记为表示正样本的1或表示负
样本的-1,代码块如下:

如果希望训练分类器来区分多个正类,只需要简单地添加带
有标签的其他描述符。例如,我们可以训练一个分类器,它使用标签1
表示汽车,2表示人,-1表示背景。没有要求必须有负类或背景类,但
是,如果没有负类或背景类,分类器将假定所有内容都属于正类。
(12)OpenCV提供了名为cv2.ml_SVM的类,代表支持向量机。我
们创建一个支持向量机,并用之前组建的数据和标签对其进行训练,
如下所示:

请注意,必须把训练数据和标签从列表转换为NumPy数组,
然后再将它们传递给cv2.ml_SVM的train方法。
(13)最后,我们准备通过对不在训练集中的一些图像进行分类
来测试支持向量机。我们将遍历测试图像的路径列表。对于每个路
径,加载图像、提取BoW描述符,并获得SVM的预测或分类结果,根据
之前使用的训练标签,它将是1.0(汽车)或-1.0(非汽车)。我们将
在图像上绘制文本以显示分类结果,并在窗口中显示图像。显示完所
有图像后,等待用户按下任意键,然后结束脚本。所有这些都可以在
下面的代码块中实现:


保存并运行脚本。你应该看到包含各种分类结果的6个窗口。图7-
6是真正例结果的一个截图,图7-7是真负例结果的一个截图。
 在简单测试的6张图片中,只有图7-8这一张图片分类错误。
在简单测试的6张图片中,只有图7-8这一张图片分类错误。
 尝试调整训练样本的数量,并试着在更多的图像上测试分类器,
尝试调整训练样本的数量,并试着在更多的图像上测试分类器,
看看可以得到什么结果。
我们来总结一下我们到目前为止所做的工作。我们使用SIFT、BoW
和支持向量机训练了一个分类器,以区分两个类:汽车和非汽车。我
们已将该分类器应用于整个图像。下一个逻辑步骤是应用滑动窗口技
术,这样就可以将分类结果缩小到图像的特定区域。
7.7.1 支持向量机和滑动窗口相结合
通过把支持向量机(SVM)分类器与滑动窗口技术和图像金字塔相
结合,我们可以实现下列改进:
·检测图像中同类型的多个物体。
·确定图像中检测到的每个物体的位置和大小。
我们将采用以下方法:
(1)取图像的一个区域,对其进行分类,按照预定义的步长把窗
口移动到右侧。当到达图像最右端时,将x坐标重置为0,向下移动一
步,重复整个过程。
(2)在每一步,使用经BoW训练的SVM执行分类。
(3)根据SVM,持续跟踪正检测的所有窗口。
(4)在对完整图像中每个窗口分类之后,缩小图像,并利用滑动
窗口重复整个过程。因此,我们使用的是图像金字塔。继续缩小并分
类直到到达最小尺度。
在此过程结束时,我们已经收集了有关图像内容的重要信息。但
是,有一个问题:在所有的可能中,我们会发现一些重叠块,每个重
叠块都生成高置信度的正检测结果。也就是说,图像可能包含一个多
次被检测的物体。如果报告了这些多重检测结果,我们的报告很可能
会有误导性,因此我们将使用NMS过滤结果。
作为复习,请参考7.3节。
接下来,我们来看如何修改并扩展之前的脚本,以实现刚介绍的
方法。
7.7.2 检测场景中的汽车
现在,我们已经准备好应用目前为止所学的所有概念,创建一个
汽车检测脚本,扫描图像并在汽车周围绘制矩形。我们通过复制之前
的脚本detect_car_bow_svm.py,创建一个新的Python脚本
detect_car_bow_svm_sliding_window.py。(前面刚介绍了
detect_car_bow_svm.py的实现。)新脚本的大部分实现将保持不变,
因为我们仍然以几乎与之前相同的方式训练BoW描述符提取器和SVM。
但是,在训练完成后,我们会用一种新的方式来处理测试图像。我们
不对每幅图像进行整体分类,而是将每幅图像分解到金字塔层和窗口
中,对每个窗口进行分类,并将NMS应用于产生正检测结果的窗口列
表。
对于NMS,我们将依赖于Malisiewicz和Rosebrock的实现(如7.3
节中所述)。你可以在这本教程的GitHub库中找到一个稍做修改的实现
副本,具体在chapter7/non_max_suppression.py的Python脚本中。该
脚本提供了一个具有以下签名的函数:
![]()
该函数接受包含矩形坐标和得分的NumPy数组作为第1个参数。如
果有N个矩形,数组的形状就是N×5。对于索引i处的给定矩形,数组
中的值有以下含义:
·boxes[i][0]:最左边的x坐标。
·boxes[i][1]:顶端的y坐标。
·boxes[i][2]:最右边的x坐标。
·boxes[i][3]:底部的y坐标。
·boxes[i][4]:得分,分数越高代表矩形是正确检测结果的置信度
越大。
该函数接受一个阈值(代表矩形之间重叠的最大比例)作为第2个
参数。如果两个矩形的重叠比例大于这个参数,将会过滤掉较低的得
分结果。最后,该函数将返回由剩余矩形组成的数组。
现在,我们把注意力转向对
detect_car_bow_svm_sliding_window.py脚本的修改,如下所述:
(1)首先,为NMS函数添加一个新的import语句,如代码中的粗
体所示:
(2)在脚本开始处定义一些额外的参数,如下面的粗体所示:

我们将使用SVM_SCORE_THRESHOLD作为阈值来区分正窗口和负窗
口。稍后,我们将看到如何获得得分。使用NMS_OVERLAP_THRESHOLD作
为NMS步骤中可接受的最大重叠比例。这里,我们随机选择15%,所以
将剔除重叠超过该比例的窗口。在用支持向量机做实验时,可以根据
自己的喜好调整这些参数,直到找到能在应用程序中产生最佳结果的
值。
(3)把k均值聚类数从40个减少到12个(根据实验随机选择的一
个数),如下所述:
 (4)同时调整SVM的参数,如下所示:
(4)同时调整SVM的参数,如下所示:

在对支持向量机进行上述修改后,我们将指定分类器的严格或严
重程度。随着C参数值的增加,假正例风险降低,但是假负例风险增
加。在我们的应用程序中,假正例是指当窗口中实际上并不是汽车
时,检测为汽车,而假负例是指窗口中实际上是一辆汽车时,但却检
测为非汽车。
在完成训练SVM的代码之后,我们想再添加两个辅助函数,其中一
个用于生成图像金字塔层,另一个用于基于滑动窗口技术生成感兴趣
的区域。除了添加这些辅助函数之外,我们还需要以不同的方式处理
测试图像,以便利用滑动窗口和NMS。以下步骤将介绍这些更改:
(1)首先,我们来看处理图像金字塔的辅助函数,如下列代码块
所示:

此函数将获取一幅图像并生成一系列调整大小的图像版本,但有
最大和最小限制。
你可能已经注意到,返回调整后的图像时没有使用return关键
字,而是使用了yield关键字。这是因为该函数是所谓的生成器。它产生
一系列可以在循环中轻松使用的图像。如果你不熟悉生成器,那么可
以参阅https://wiki.python.org/moin/Generators上的官方Python维基百
科。
(2)接下来是基于滑动窗口技术生成感兴趣区域的函数。此函数
如下面的代码块所示:

同样,这也是一个生成器。尽管它嵌套得有点深,但是其机制非
常简单:给定一幅图像,返回左上角坐标和代表下一个窗口的子图
像。连续的窗口通过任意大小的步长从左到右移动,直到到达图像的
最右端,并从上到下移动,直到到达图像的底端。
(3)现在,我们来考虑测试图像的处理。和之前版本的脚本一
样,循环遍历测试图像路径列表,以加载和处理每幅图像。循环的开
始部分没有变化。下面是其内容:

(4)对于每幅测试图像,遍历金字塔层,对于每一金字塔层,遍
历滑动窗口的位置。对于每个窗口或者感兴趣区域(Region Of
Interest,ROI),提取BoW描述符并使用SVM对其进行分类。如果分类
产生的正检测结果超过了某个置信度阈值,就将矩形的角点坐标和置
信度添加到正检测结果列表中。继前面的代码块之后,我们继续处理
给定的测试图像,代码如下:

我们注意到,上述代码中有一些复杂的地方:
·为了获得支持向量机预测的置信度,我们必须使用可选标志
cv2.ml.STAT_MODEL_RAW_OUTPUT来运行predict方法。然后,该方
法返回一个得分作为其输出的一部分,而不是返回一个标签。这个得
分可能为负,而且低的值表示置信度高。为使得分更直观并匹配NMS
函数的假设(得分越高越好),我们对得分取负,这样高的值就代表
了置信度高。
·因为使用的是多层金字塔,窗口坐标没有共同的尺度。在将它
们添加到正检测结果列表之前,需要将其转换到共同的尺度,即原始
图像的尺度。
到目前为止,我们已经在不同的尺度和位置进行了汽车检测,结
果就是可以得到一个检测到的汽车矩形列表(包括矩形坐标和得
分)。预计在矩形列表中会有很多重叠内容。
(5)现在,调用NMS函数,以便在重叠的情况下,选出得分最高
的矩形,如下所示:

注意,我们已经将矩形坐标和得分列表转换为NumPy数组
(该函数所期望的格式)。
在这个阶段,我们有一个检测到的汽车矩形及其得分的数组,已
经确保这些是我们可以选择的最好的非重叠检测(在模型参数内)。
(6)现在,把下列内循环添加到代码中,绘制矩形及其得分:

在该脚本的前一个版本中,外循环的主体以显示当前测试图像
(包括在其上绘制的注释)结束。在循环遍历所有测试图像之后,等
待用户按下任意键,然后,程序结束,代码如下:
运行修改后的脚本,看看它能如何回答这个永恒的问题:老兄,
我的车呢?
图7-9显示了一个成功的检测结果。
另一幅测试图像中有两辆汽车。脚本成功地检测到一辆,没有检
测到另一辆,如图7-10所示。


有时,也会把具有许多特征的背景区域错误地检测为汽车,如图
7-11所示。
 请记住,在这个示例脚本中,我们的训练集很小。训练集越
请记住,在这个示例脚本中,我们的训练集很小。训练集越
大,背景也就越多样化,因此可以提升检测结果的准确性。同时,请
记住,图像金字塔和滑动窗口会产生大量感兴趣区域(ROI)。考虑到
这个问题,我们应该意识到检测器的假正例比率实际上相当低。如果
对视频的帧进行检测,那么可以通过过滤仅发生在单个帧或少数几帧
中的检测结果(而不是过滤任意最小长度的检测序列),进一步降低
假正例比率。
请使用前面脚本的参数和训练集随意进行实验。等你准备好了,
我们对其进行一些总结以结束这一章。
7.7.3 保存并加载经过训练的支持向量机
关于支持向量机(SVM)的最后一条建议:你不需要在每次使用检
测器时都对其进行训练,实际上,你应该避免这样做,因为训练很
慢。使用如下代码可以把训练好的SVM模型保存到XML文件:

随后,可以使用下列代码重新加载训练好的SVM:

通常,你可能需要有一个脚本来训练和保存SVM模型,而其他脚本
加载并使用SVM来解决各种检测问题。
7.8 本章小结
本章,我们介绍了包括HOG、BoW、SVM、图像金字塔、滑动窗口以
及NMS在内的各种概念和技术。我们知道了这些技术在物体检测以及其
他领域都有应用。我们编写了一个脚本,将这些技术中的大多数
(BoW、SVM、图像金字塔、滑动窗口以及NMS)结合在一起,通过对自
定义检测器进行训练和测试的练习,获得了机器学习方面的实际经
验。最后,我们证明了我们可以检测汽车!
本章的知识是第8章的基础,在第8章我们将对视频中的帧序列使
用物体检测和分类技术。我们将学习如何跟踪物体并保留有关跟踪物
体的信息——在许多实际应用程序中,这是一个很重要的目标。