Focal Self-attention for Local-Global Interactions in Vision Transformers论文阅读
Focal Self-attention for Local-Global Interactions in Vision Transformers论文阅读
-
- 介绍
- 方法
-
- Focal self-attention
- Window-wise attention
-
- Sub-window pooling.
- Attention computation.
- Complexity analysis
- Model configuration
- 实验
-
- 图像分类
- 目标检测和实例分割
- 语义分割
- 与SOTA方法比较
- 消融实验
-
- window size
- window shift
- short-range和long-range交互的贡献
- 模型深度和模型能力
paper:https://arxiv.org/pdf/2107.00641v1.pdf

介绍
Transformer成功的关键是其self-attention可以捕获short-range和long-range的视觉依赖,如图1左边所示,但是会带来随着图像分辨率二次方增加的计算量,而许多视觉任务(目标检测,语义分割等)都需要对高分辨率的图像处理。许多工作通过添加粗粒度的全局attention或者是细粒度的局部注意力来减少self-attention的计算量和内存占用,然而这些方法都会损害self-attention的建模能力,导致结果是次优化的;
论文中提出了focal self-attention,同时融合细粒度局部交互和粗粒度全局交互;
考虑到邻近区域之间的视觉依赖性通常强于远处区域,作者只在局部区域进行细粒度的自关注,而在全局范围内进行粗粒度的关注;
每个token将离其最近的tokens来做细粒度,较远的做粗粒度交互,因此有效率的同时捕获了short-range和long-range的视觉依赖;如图1右边所示;
由focal self-attention组成的架构,就是focal transformer;
(标准的self-attention捕捉short-range和long-range的交互,都是通过细粒度的方式);
Focal Transformer较小的分类模型,在224x224的分辨率下,以51.1M、89.8M的参数实现了ImageNet上83.5%、83.8%的top-1准确率;
当作为backbone使用到下游任务中时,Focal Transformer在6个不同的目标检测架构上都实现了比Swin Transformer的结果,并在COCO数据集mini-val/test-dev上实现了58.7/58.9 的box mAP,50.9/51.3 mask AP;
在语义分割ADE20K数据及上,实现了55.4 mIoU,实现了新的SOTA;
方法
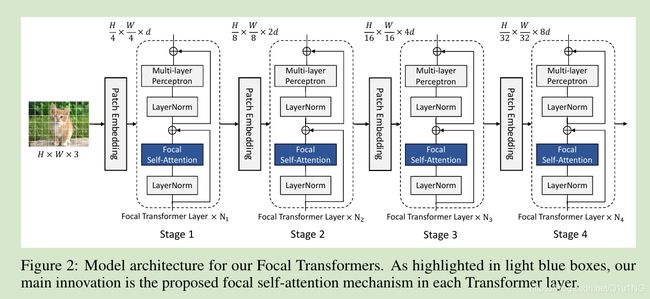
对于一个HxWx3的图像,首先经过一个kernerl size=4, stride=4的conv操作(Patch Embedding层),将分辨率变为H/4 x W/4 x d的特征图,其中d=4x4x3;
然后是4个stage,每个stage之前都有一个patch embedding层,之后的是将特征图空间大小减半,通道数增加一倍;
对于图像分类,将最后一个stage的输出送入一个分类头;
对于目标检测,将最后三个stage或者全部4个stage送入检测头;
模型的能力可以由通道数d和每个stage的堆叠数{N1 , N2 , N3 , N4 }控制;
Focal self-attention
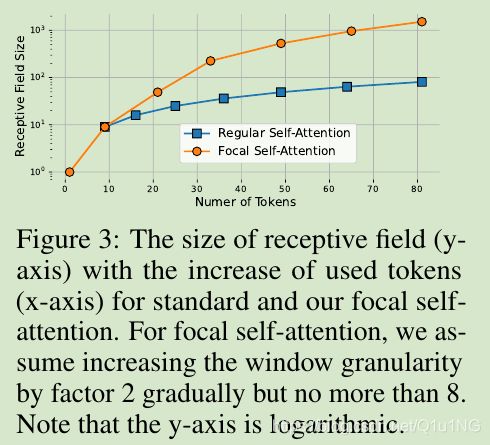
对于一个query位置,只在局部做细粒度交互,全局做粗粒度交互,对于标准的self-attention,不仅可以减少计算量,而且能够提高感受野,如图3所示;
Window-wise attention
整个流程如图4所示
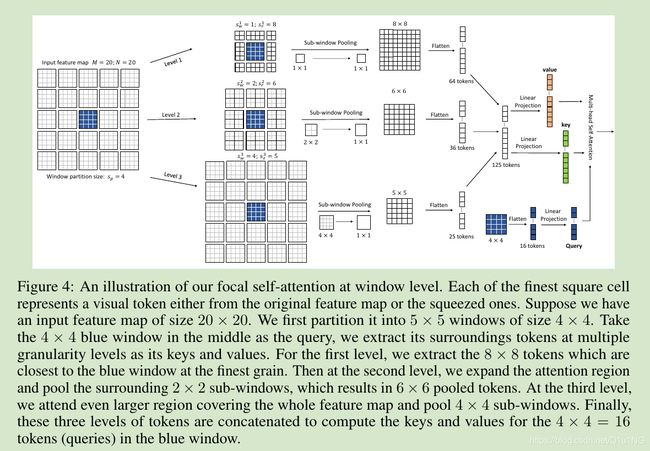
- Focal levels L:Focal self-attention 提取tokens的细粒度等级;
- Focal window size slw:在不同细粒度等级下的子窗口大小,如图1中三个等级分别为1,2,4;
- Focal region size slr:进行sub-window pooling之后的regions窗口大小;
Sub-window pooling.
如图4中间所示;
对于输入特征图x∈M x N x d,对每个L等级进行sub-window pooling,首先切分输入特征图划分为slw x slw的网格,然后使用一个简单的线性层flp来池化每个sub-windows:
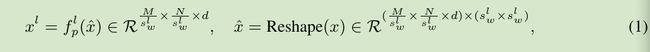
由于sub-windows的大小一本都很小(最大为7),所以这里的参数了很少;
Attention computation.
计算attention如图4右边所示;
计算query仅仅通过中间的token计算,而value,key则是通过所有经过sub-window操作之后的tokens拼接到一起经过线性层计算所得;
![]()
值得注意的是严格的Focal self-attention是按照图1,需要去除掉不同层级重叠的regions,但模型中将其保留了下来,来捕获不同层级的特征金字塔信息,最终和Swin Transformer一样,加上了相对位置偏置:
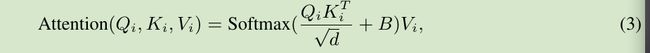
其中B是可学习的相对位置偏置;L层focal level对应L个B的子集;
和Swin Transformer一样,对于第一层,水平和垂直方向的范围在[−sp + 1, sp− 1],B1∈ (2sp-1)x(2sp-1);
对于其他的focal层,考虑到它们对查query的粒度不同,对一个窗口内的所有query都一视同仁,并用Bl ∈slr x slr表示query窗口与每个pooled token之间的相对位置偏置;
每个窗口的focal self-attention是独立的,所以可以并行计算;
Complexity analysis
对于每个输入特征图x∈ M x N x d,有 M s l w \frac{M}{s^lw} slwM x M s l w \frac{M}{s^lw} slwM个子窗口,对于每个子窗口,公式1中的pooling操作的复杂度为O((slw)2d),所有额子窗口复杂度为O((M N )d);
对于所有的focal层,总共复杂度为O(L(M N )d);
至于方程式3中的注意力计算,每个query窗口sp × sp计算复杂度是O((sp)2 ∑l (slr )2 d),整个输入特征图的复杂度是O(∑l (slr )2(M N )d);
总共的计算复杂度为 O((L + ∑l (slr )2)(M N )d);
Model configuration

实验
图像分类
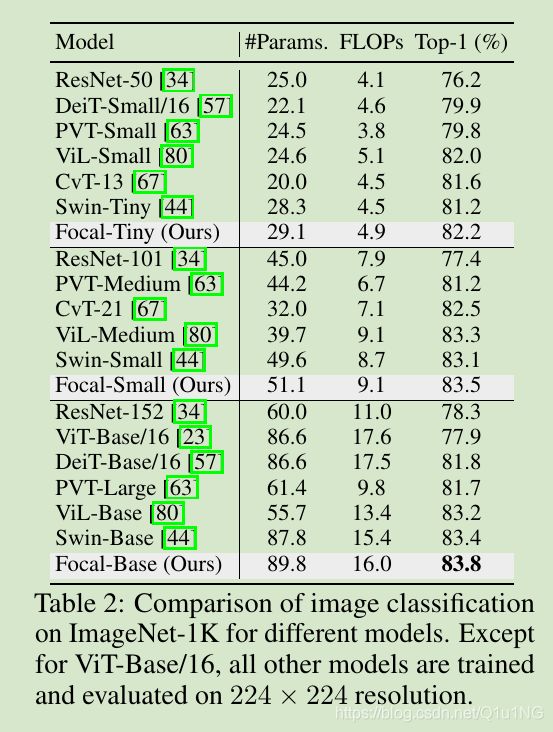
Focal-Tiny比Transformer baseline DeiT-Small/16高2.0%;
在相同模型配置(2-2-6-2)下,Focal-Tiny比Swin-Tiny高了1.0%;
Focal-Small比其他small模型精度高,且参数更少;
Focal-Base有着与其他模型差不多的参数了和FLOPs,精度最高;
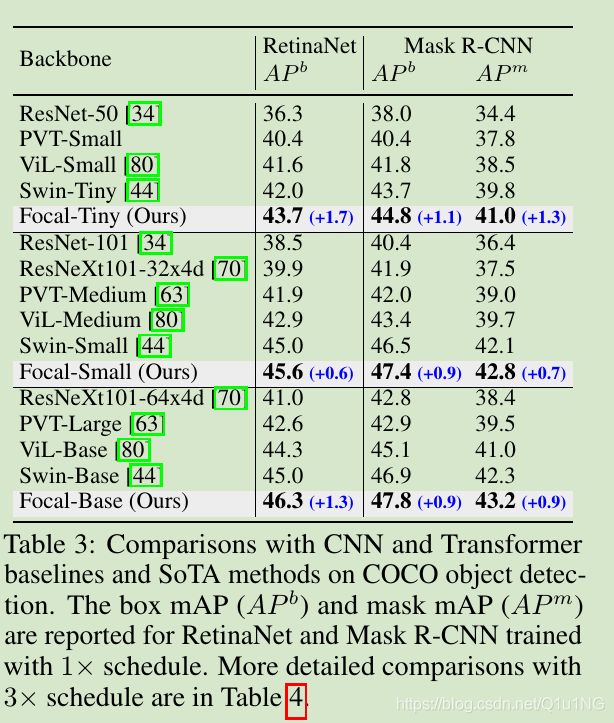
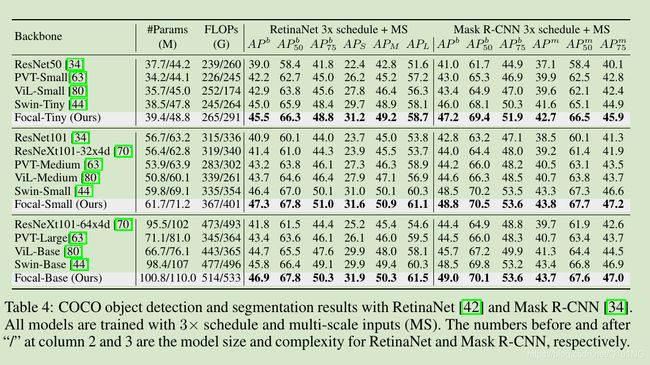
目标检测和实例分割
COCO数据集
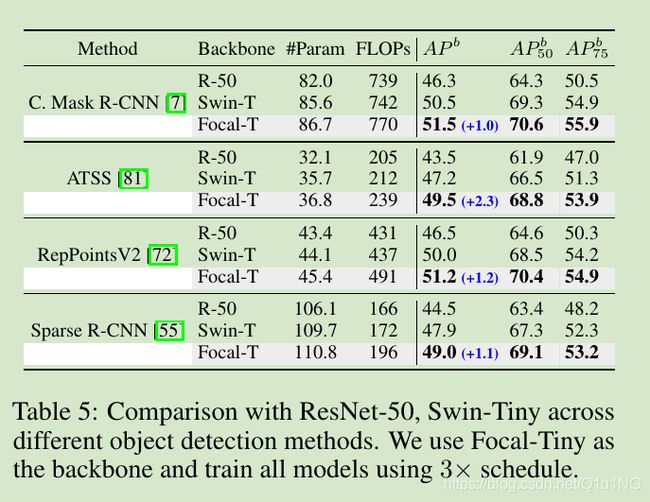
语义分割
UperNet作为baseline,在ADE20K数据集上,与Swin Transformer差不多的模型大小,有着更好的精度;
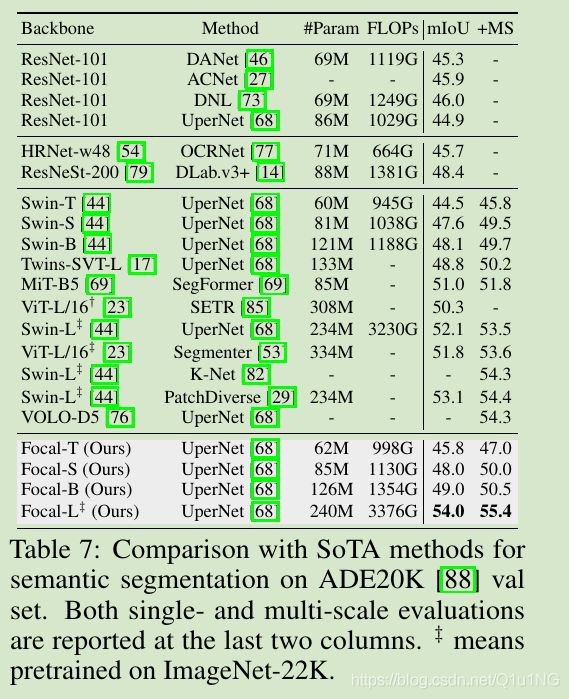
与SOTA方法比较
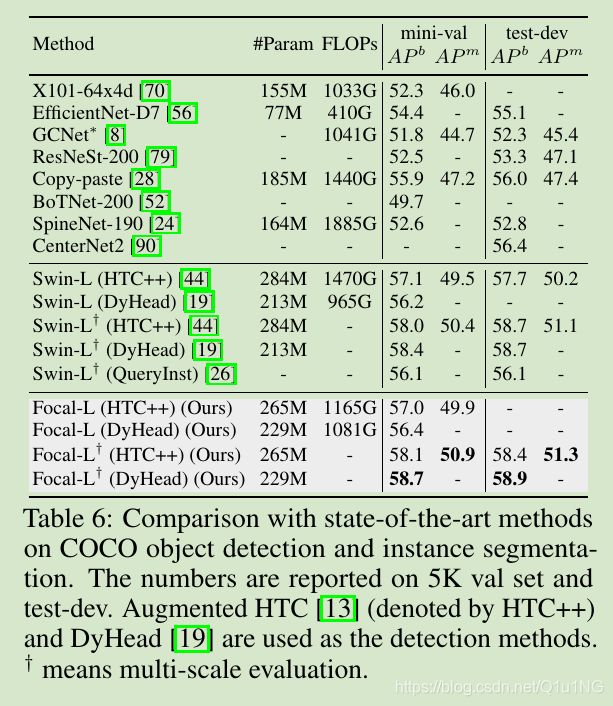
消融实验
window size
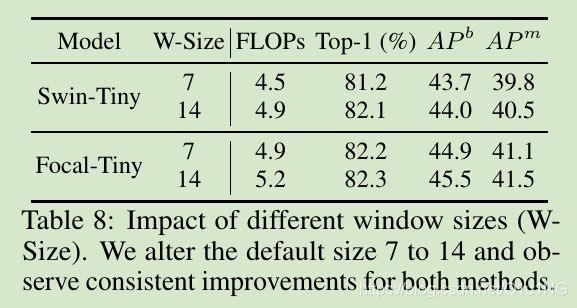
window shift
Focal Transformer无论使不使用window shift,各个windows之间在细粒度和粗粒度都有交互,Swin Tranformer去掉window shift会有明显精度下降(Swin Transformer就是靠window shift来进行windows之间的交互的);而Focal Transformer在加上window shift后在分类任务上反而降点,因此Focal Transformer中window shift不是必需的,意味着可以去掉Swin Transformer中的大量windows shift操作;
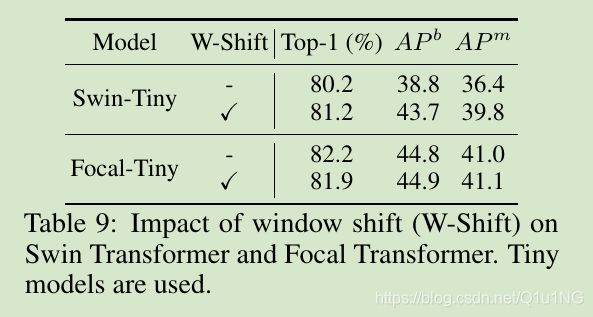
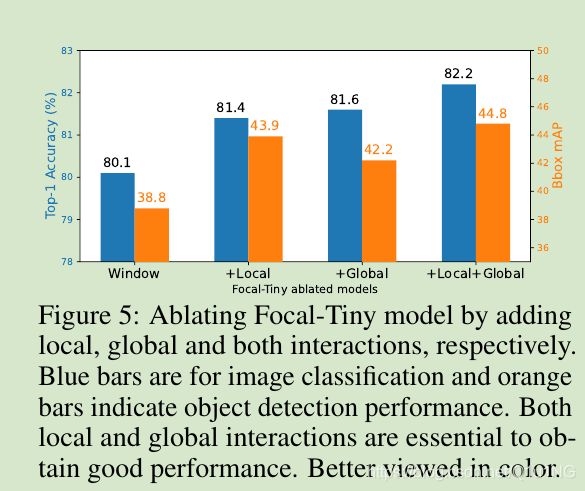
short-range和long-range交互的贡献
Window: 每个window仅在内部做self-attention;
+Local:添加了周围额外的细粒度tokens;
+Global:添加了较远距离的粗粒度tokens;
+Local+Global:周围的细粒度和较远的粗粒度都有添加;
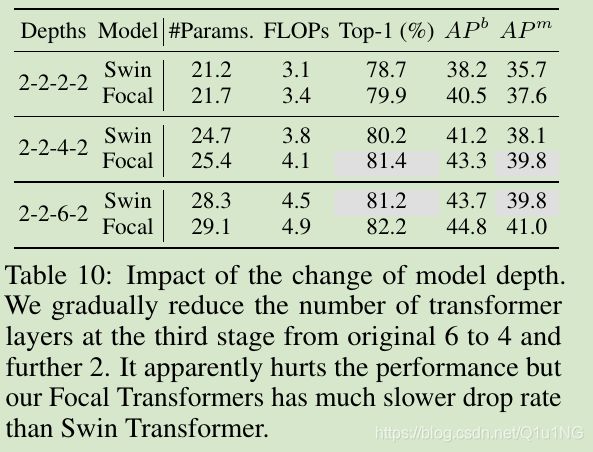
模型深度和模型能力
由于Focal Transformer有着局部和全局交互,所以实验是否可以通过更少的层数来获得仅有局部交互的Swin Transformer的模型能力;
实验可见在少量层数下,Focal Transformer能够达到与Swin Transformer媲美的精度(但还是略低);
在分类任务上,Focal-Tiny更少的层数比Swin-Tiny精度更高;