<2021SC@SDUSC>博客(9)山东大学软件工程应用与实践Jpress代码分析(8)
2021SC@SDUSC
Lucene和ElasticSearch
在上一篇博客中提到的Elasticsearch是一个基于Lucene搜索引擎为核心构建的开源,分布式,RESTful搜索服务器。这里提一下Lucene和ElasticSearch的关系。因为在Jpress当中呢,有LuceneSearcher和ElasticSearcher两个针对性业务。
Lucene是一个开源的全文检索引擎工具包(类似于Java api),而Elasticsearch底层是基于这些包,对其进行了扩展,提供了比Lucene更为丰富的查询语言,可以非常方便的通过Elasticsearch的HTTP接口与底层Lucene交互。
如果在应用程序中直接使用Lucene,你需要覆盖大量的集成框架工作,而使用ElasticSearch就省下了这些集成工作。一句话概括: Elasticsearch是Lucene面向企业搜索应用的扩展,极大的缩短研发周期。
es底层的索引机制是基于lucene实现的,但是使用es的场景并不是主要操作索引,比如通过elk对系统进行监控可以做ng日志的采集,或者自研sdk埋点日志采集,这些和lucene本身都没啥关系,相反,es的运维,官方client的使用,这些是es所关心的。
举个简单的例子,你直接拿汽车(Elasticsearch)来开,开好车就行,无需了解里面的发动机、各个组件(Lucene library)。后面你在去了解一些原理,对于修车等等会有帮助。所以初学者首先要对ElasticSearch要有一个熟悉的掌握,之后可以深入探究lucene的原理。
AliyunOpenSearch
智能开放搜索 OpenSearch是基于阿里巴巴自主研发的大规模分布式搜索引擎搭建的一站式智能搜索业务开发平台,目前为包括淘宝、天猫在内的阿里集团核心业务提供搜索服务支持。通过内置各行业的查询语义理解、机器学习排序算法等能力,提供充分开放的引擎能力,助力开发者快速搭建智能搜索服务。
1.OpenSearch 不是百度谷歌这种泛搜索。它主要用于站内搜索,比如大家在淘宝里搜个商品,这种站内搜索的实现,可以使用 OpenSearch。
2.阿里云的 OpenSearch 可以说是封装版的云 ElasticSearch。很多常用功能帮大家包好了,可以直接使用。ES 搭建起来还是太费劲。
3.虽然 OpenSearch 已经极大的降低了接入难度,但对于非技术类的公司来说,在排序调优等方面仍然有不小的复杂度。当然这也是 OpenSearch 的取舍,调低复杂度就损失了灵活性,调高复杂度又伤害了非技术类公司。毕竟这类公司没必要单独招一名搜索后端工程师。
OpenSearch和ElasticSearch
对比内容阿里云opensearch阿里云elasticsearch备注优点多种中英文分词器、行业分词器,均来自阿里NLP的技术成果,效果明显好于开源分词器。内置已成熟的多种高级算法功能,用户在控制台通过简单的交互即可使用,无需额外自主研发,搜索效果即可一键提升。人工干预功能即干预即生效。开源产品更加灵活,对于有开发能力的客户来说,使用es可以自研更适合自身业务的插件和算法使用,并且迭代节奏完全可以
优势
OpenSearch:
多种中英文分词器、行业分词器,均来自阿里NLP的技术成果,效果明显好于开源分词器。
内置已成熟的多种高级算法功能,用户在控制台通过简单的交互即可使用,无需额外自主研发,搜索效果即可一键提升。
人工干预功能即干预即生效。
0运维,免部署。(针对自建es)
ES:
开源产品更加灵活,对于有开发能力的客户来说,使用es可以自研更适合自身业务的插件和算法使用,并且迭代节奏完全可以自行把控。
数据接入方式基本没有局限。所以不管业务数据存放在哪里都可以较方便的接入es。
品牌软实力,全世界闻名的开源搜索引擎。
没有数据敏感性的困扰。(自建es)
劣势
OpenSearch:
数据接入方式相比es来说较局限,目前仅支持云上的rds、odps或用户通过API/SDK的方式推送。
基本上所有的算法功能都是黑盒的,用户无法根据业务自己迭代opensearch的算法功能,灵活性不够;
服务部署目前暂时较少
ES:
如果对搜索效果有较高要求,es的开发难度相对较高,比如OpenSearch默认支持两轮排序,用户在控制台上填写每轮排序表达式即可,但是es的两轮排序的实现对于索引配置的合理性有要求。
自定义分词文件每次上传都需要重启服务,方便性较弱。
需要复杂繁琐的运维。(自建es)
ElasticSearch能否代替数据库存储?
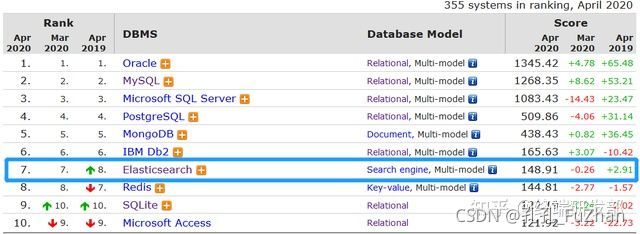
可见Elasticsearch当前热度排名很高
对于经常修改的数据,高并发并且有嵌套的情况下,按照一定条件数据库的一页数据(select *),然后通过elasticsearch相同条件搜索出一页数据(source=true),看一下性能。
你会发现,elasticsearch性能极差。但是,source=false的情况下,elasticsearch性能极好。其实是因为elasticsearch倒排索引,导致回表性能本来就很难优化。并且,elasticsearch对于查询缓存,没有做很多优化导致的,直接用单id查询es性能也是极好的,因为做了优化。所以,一般通过es搜索出id,之后根据id去其他存储进行查询

ES的排名热度非常高,但是如果想要代替数据库存储,还需要考虑以下方面:
作者:鹅厂架构师
链接:https://www.zhihu.com/question/45510463/answer/2229851308
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、使用场景方面
我们把 ES 定位为分布式的搜索分析型数据库,并通过实际业务验证,可以非常好的支持下列场景:
- 全文搜索:ES 最初的目标场景,非常多的大型互联网公司都在基于 ES 搭建自己的核心搜索,包含 Git 的代码搜索、美团的电商搜索、头条的视频搜索等。ES 在 DB-Engines 的 Search Engine 领域也是常年排名第一。
- 日志实时分析:这是推动 ES 快速发展的场景,从官方统计数字、云上运营经验看,占据了 ES 使用场景的 70%+。Elastic Stack 提供的完整日志解决方案,已经助力 ES 成为日志实时分析的开源首先方案。
- 时序数据处理:我们从 2017 年中开始探索使用 ES 作为时序数据解决方案,逐步完善 ES 的时序处理能力,相比开源的时序数据库,在写入吞吐、查询性能等方面已经追齐、甚至超越竞品,并且很好的支持了腾讯云监控单集群每秒千万级的业务吞吐。受腾讯在时序场景的启发,Elastic 官方也在探索支持 Metrics、APM 等时序场景。
- 其他:社区和公司内也有其他团队把 ES 应用于 OLAP 分析、文档数据库等场景,有需要的团队可结合场景需求评估测试。
由于不支持事务,以及在建立索引方面的计算 / 存储成本,ES 并不适合于 OLTP 及 离线日志数据处理等场景。
2、大规模使用方面
开源 ES 的易用性和完整的日志解决方案,推动 ES 非常快速的发展。但不少用户在大规模应用 ES 时遇到了不少问题,例如稳定性方面有集群易雪崩、压力不均等,成本方面硬盘、内存开销高等。TencentES 在兼容开源 API 的同时,在内核方面做了非常多的优化,用于支撑腾讯云 ES 服务、公司内部大量核心业务,包含日志实时分析、全文搜索、时序数据处理等众多场景。具体内核优化内容简单介绍如下:
可用性
- 自保护机制:提供权限认证、漏斗限流、内存限流、多租户隔离等多层级、全链路的自我保护均衡策略优化:支持节点间、多盘间的分片均衡,避免容量、读写压力不均集群扩展性:单集群达到千级节点,支持 50w 分片,索引创建速度控制在秒级,相比开源提升 30+ 倍Bug Fix:修复 Master 阻塞、分布式死锁等已知 Bug,提升集群稳定性
成本
- 堆内存优化:通过 LRU+Off Heap 技术降低堆内存使用 80%,单节点支撑容量由 3T 提升至 20T
- 冷热分离:集群内支持多层级存储设备混部,降低用户成本
- Rollup:支持高性能 Rollup 计算,降低存储成本,数量级级别提升分析性能
性能
- Merge重构:支持时间序 Merge、冷索引自动 merge 等,搜索等场景查询性能提升 50%+
- 查询执行计划优化:基于 CBO 模型优化 Range 查询,长时间范围 Range 查询性能提升 10+ 倍
- 写入性能优化:降低主键唯一性检查开销,支持存储裁剪,性能提升 50%+