Knowledge Distillation 笔记
Inter-Region Affinity Distillation for Road Marking Segmentation (2020.04)
Yuenan Hou1, Zheng Ma2, Chunxiao Liu2, Tak-Wai Hui1, and Chen Change Loy3y
1The Chinese University of Hong Kong 2SenseTime Group Limited 3Nanyang Technological University
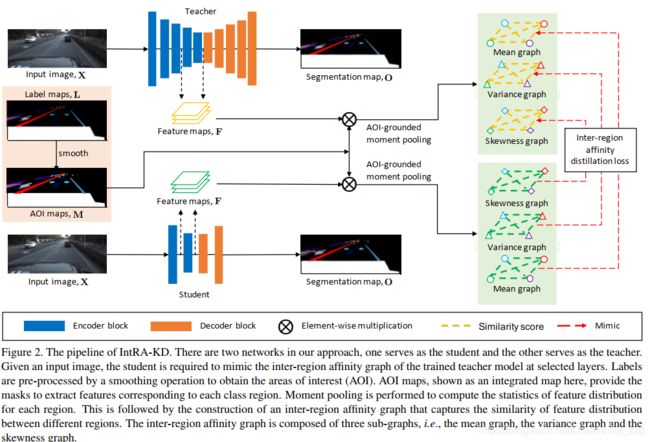
用 inter-region affinity graph 描述 structural relationship。
每个node表示一种class的 areas of interest (AOI)(同类算一个 or instance算一个?),edge 代表 Affinity

Generation of AOI:smooth the label map with an average kernel φ and AOI map as ![]()
AOI-grounded moment pooling:分别描述 mean, variance, skewness

Inter-region affinity :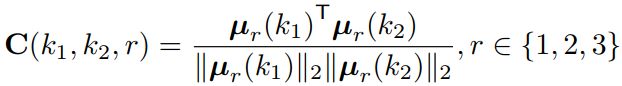
distillation:


![]()
Experiments



Learning Lightweight Lane Detection CNNs by Self Attention Distillation (2019.08)
Yuenan Hou1, Zheng Ma2, Chunxiao Liu2, and Chen Change Loy3y
1The Chinese University of Hong Kong 2SenseTime Group Limited 3Nanyang Technological University
用于lane det 的self attention distillation,
backbone:Enet、Resnet18/34
每个block输出的feature map转为attention map,后层attention map监督指导前层的attention map。
生成attention map:![]()
![]() -> Bilinear upsampling B(.) -> spatial softmax operation Φ(.)
-> Bilinear upsampling B(.) -> spatial softmax operation Φ(.)

Loss
![]() m为block数,Ld为L2 loss
m为block数,Ld为L2 loss
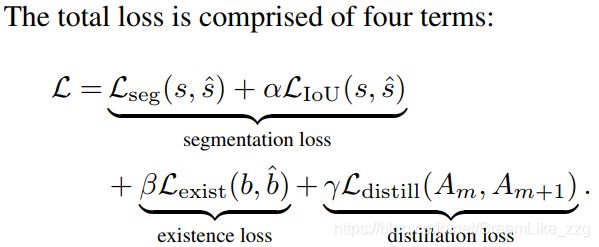
Ablation Study
Distillation paths of SAD:SAD用于block 1起反作用,造成low-level info细节损失?
Backward distillation.:后层为student,前层为teacher不行
SAD v.s. Deep Supervision:soft target,feedback connection
When to add SAD:adding SAD in later training stage would benefit
Knowledge Adaptation for Efficient Semantic Segmentation(CVPR 2019)
Tong He1 Chunhua Shen1y Zhi Tian1 Dong Gong1 Changming Sun2 Youliang Yan3
1The University of Adelaide 2Data61, CSIRO 3Noah’s Ark Lab, Huawei Technologies
motivation:Teacher和Student间结构差异,使得abilities to capture context and long range dependencies不同,给直接蒸馏造成难度。应该将knowledge去冗去噪后再用于蒸馏。

Knowledge Translation
用auto-encoder压缩feature ![]()
Feature Adaptation(有Fitnet的影子)
solve the problem of feature mismatching and decrease the effect of the inherent network difference of two model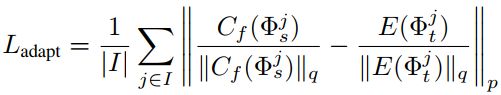
Cf uses a 3 × 3 kernel with stride of 1, padding of 1, BN layer and ReLU
Affinity Distillation
cosine距离表示相似度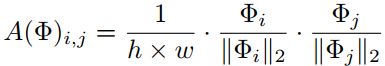
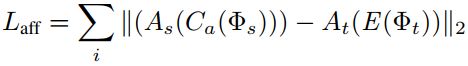

backbone: T: resnet50、 S:mobilenetV2
Knowledge Distillation via Instance Relationship Graph (CVPR 2019)
Yufan Liu∗a, Jiajiong Cao*b, Bing Li†a, Chunfeng Yuan†a, Weiming Hua, Yangxi Lic and Yunqiang Duanc
aNLPR, Institute of Automation, Chinese Academy of Sciences bAnt Financial cNational Computer Network Emergency Response Technical Team/Coordination Center of China
分类task,蒸馏中引入instance(样本) relationship。构建graph:instance feature为顶点,邻接矩阵A表示relationship。A与batch size有关,loss中λ需根据batch size尝试。
backbone: Resnet dataset: cifar、ImageNet



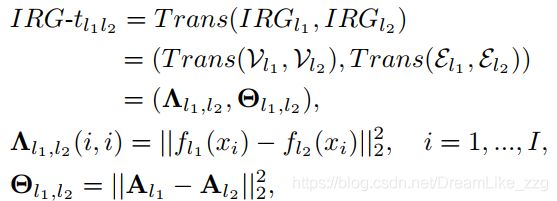 L2 feature + L2 edge
L2 feature + L2 edge

Relational Knowledge Distillation (CVPR2019)
distill info中加入batch中样本间的差异。用于metric learning,classification也能涨点。
backbone:resnet
embedding vectors不加L2 normalization效果更好(by exploiting a larger embedding space.)
Distance-wise distillation loss
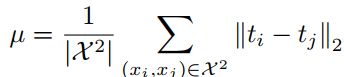
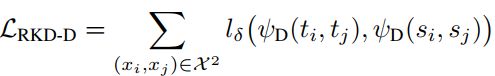
Angle-wise distillation loss


A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning (CVPPR 2017)
Junho Yim1 Donggyu Joo1 Jihoon Bae2 Junmo Kim1
1School of Electrical Engineering, KAIST, South Korea 2Electronics and Telecommunications Research Institute
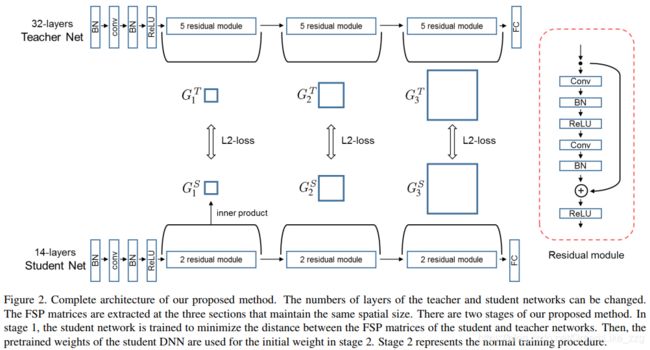
用网络自身不同层feature间的相似性作为蒸馏知识(Gramian matrix)
The knowledge transfer performance is very sensitive to how the distilled knowledge is defined. we believe that demonstrating the solution process for the problem provides better generalization than teaching the intermediate result
论文通过实验证明蒸馏三个好处:
1、Fast optimization
2、Performance improvement for the small DNN
3、Transfer Learning
Gij = Feature1的 i 通道和Feature2的 j 通道elem-product后求和
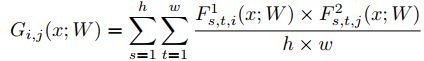
![]()
![]()
![]()

训练过程:分阶段
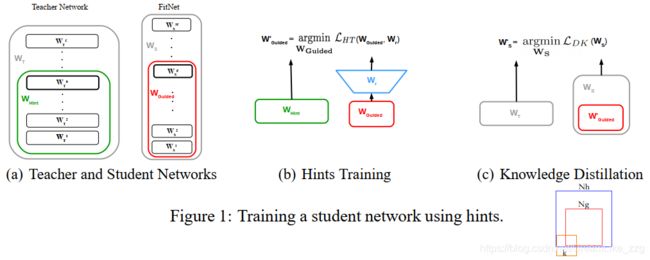
FITNETS: HINTS FOR THIN DEEP NETS (2015.03)
teacher:wide shallow student:thin deep。也许由于当时resnet未出,deep net不好训练
先蒸馏中间层(student中间层加一层conv和teacher match size),再蒸馏输出分布
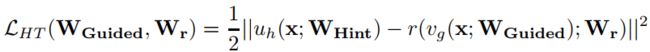
![]() λ逐渐减小
λ逐渐减小
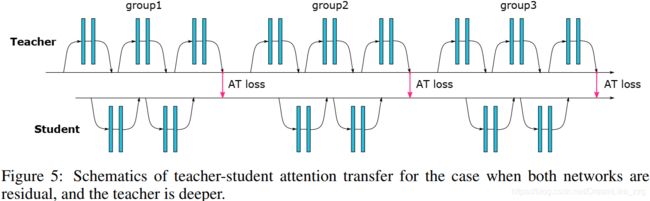
PAYING MORE ATTENTION TO ATTENTION: IMPROVING THE PERFORMANCE OF CONVOLUTIONAL NEURAL NETWORKS VIA ATTENTION TRANSFER (2017.02)
attention map作为distill info。![]()

attention based attention transfer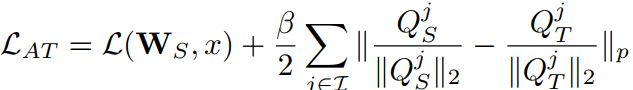 p=2
p=2
gradient-based attention transfer
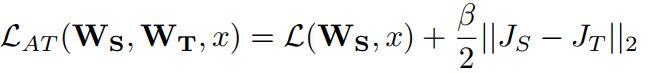

![]()
Low-resolution Face Recognition in the Wild via Selective Knowledge Distillation (2019.03 TIP2018)
人脸识别任务,只选择有用的info用于distill
teacher:大网络、high-resolution input
student:小网络、low-resolution input
Initialization of the Two-stream CNNs
teacher:可用其他dataset预训练
student:随机初始化
Selective Knowledge Distillation from the Teacher Stream
引入feature centroid (uc),减少graph edge:保留类内fi间的edge,不同类间只有fi和uc相连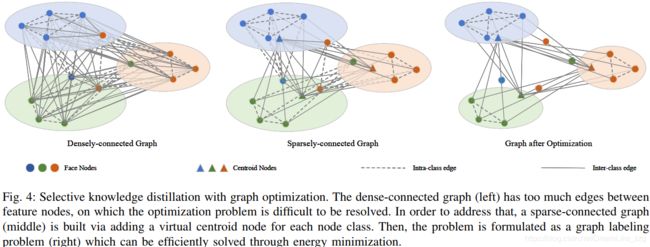

Cosine distance d(·) λ is a negative weight(第一项倾向少选node,第二项倾向多选node)
Teacher-supervised Student Stream Fine-tuning

