Knowledge Distillation with Conditional Adversarial Networks论文初读
目录
摘要
引言
相关工作
网络加速
知识蒸馏
GAN
知识蒸馏的损失函数
残差结构
知识蒸馏
用对抗网络学习知识
实验
实验设置
GAN学习的优势
GAN方法的分析
分布可视化
结论
摘要
提出了使用CAN(conditional adversarial networks)来搭建teacher-student架构
提出的方法对相对较小的student网络特别有效
实验展示了当前流行的网络作为student时,网络大小对结果的影响
实验研究了分类准确率和效率的权衡,给出了如何挑选student网络的建议
引言
- 工作
采用CAN将dark knowledge从teacher网络中迁移到student网络中
实验表明通过对抗训练学到的损失要比teacher-student网络中的预定损失更有优势,这种优势在student网络非常小的时候格外明显
- 动机
由于student网络结构一般小于teacher网络,所以强制让student网络蒸馏众多soft targets中的一种(多个teacher网络的平均或者集成)不仅时没有必要的,而且时非常苦难的
通过引入判别器,student网络可以从teacher网络中自动地学到好的损失来保留类之间的关系,并且保持多态性,如下图所示

相关工作
网络加速
低精度保存:有的甚至用1-bit来保存权重,但这知识概念上的,因为很多GPU不支持这些bit的操作
裁剪和分解权重:假设权重时稀疏的,并且都有两个阶段,一个后处理一个fine-tune,并且裁剪只是减少了基础操作数量,而没有减少推理时间
知识蒸馏
KD
有一些研究将中间层的信息作为监督信息的
作者的方法时对这些方法的补充,用CAN代替了手动设计损失的过程
GAN
图像到图像的任务
知识蒸馏的损失函数
残差结构
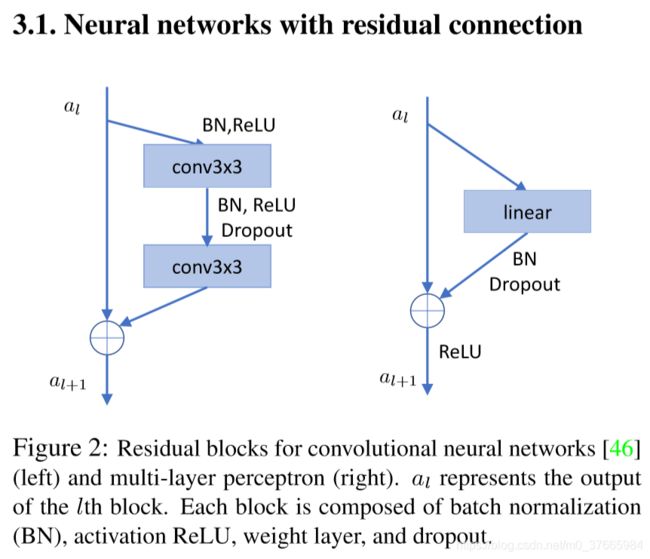
student和teacher网络都是用的左侧的残差结构
用WRN-d-m表示网络的大小,d代表网络的深度

m时宽度因子,用来提升每一层中filter的数量
网络分三个group,每个group有2n层,每一层的filter的数量会逐渐倍增
总深度:d = 6n + 4
student网络的d和m一般比较小,teacher的d和m一般比较大
知识蒸馏
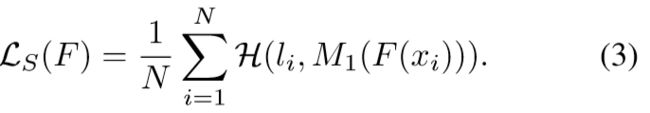
KD的做法不再回顾,当KD中的temperature变量为1的时候,这时候soften部分的损失函数变成了普通的交叉熵损失函数
用对抗网络学习知识
- 总览
介绍
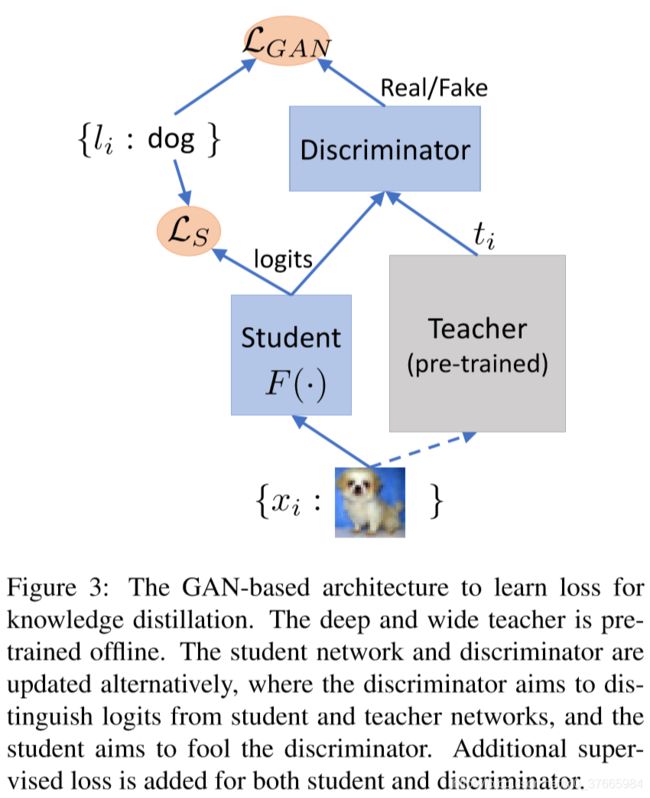
像普通的GAN一样,D用来分辨输入是有teacher网络生成的(Real)还是由student网络生成的(Fake)
student网络充当G的功能,尽可能生成让D不能分辨的输出
用GAN来学习损失的好处:
GAN学习这类任务是有效的
减少了人工设计损失和调参的复杂性,尽管网络需要手工设计,但是最终的性能对这种设计方式的敏感性还不如对temperat参数的敏感性高
放松了网络学习目标的限制,保持了输出的多态性
- 鉴别器更新
结构:
鉴别器的结构如Figure 2(right)所示,是一个MLP
每一层中神经元的数量是与logits的维度相同的(类别数量C)
损失:

D(.)代表鉴别器,F(.)代表生成器
鉴别器是为了最大化上式
问题:
即使用新发明的损失技巧(Wasserstein GAN或者Least Squares GAN),也会不稳定和收敛很慢
由于鉴别器鉴别的高层的对齐,这回造成低层的对齐可能会丢失掉,比如student将cat预测成了dog,但是由于在高层信息上,预测的概率分布很类似teacher网络的输出,这会让teacher网络认为student网络的输出是Real
解决方案:
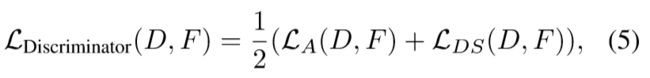

让鉴别器多一个预测2C维的向量的输出,通过log-likelihood损失预测每一个输入所处的类别
这样做可以将student网络和teacher的输出都与相同的label联系起来,使得相同类别的图片,不管经过teacher网络还是student网络,都有相同的特征,引导他们对齐
- student网络的更新(生成器)
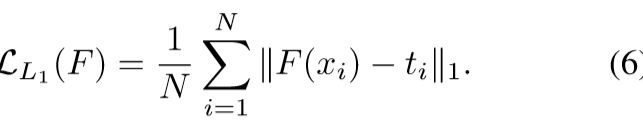
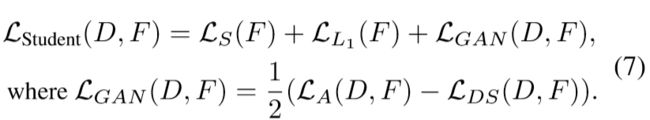
student网络的更新不仅有category-level的对齐(LDS),还增加了instance-level的对齐
在(7)式中,LDS的符号与(5)式中的符号相反,这是因为,不管是鉴别器还是学生网络(生成器)都要去保留category-level知识
实验
实验设置
略
GAN学习的优势

前两行是在纯监督学习下的结果(普通的交叉熵损失)
KD在CIFAR上表现都超过了student网络,而在ImageNet32上表现差于student网络,这可能是由于网络能力不够,不能够通过蒸馏学习到ImageNet32这么复杂数据集的规律
KD的temperature参数的提升是有效的
GAN的方法在三个数据集上都有效
GAN方法的分析
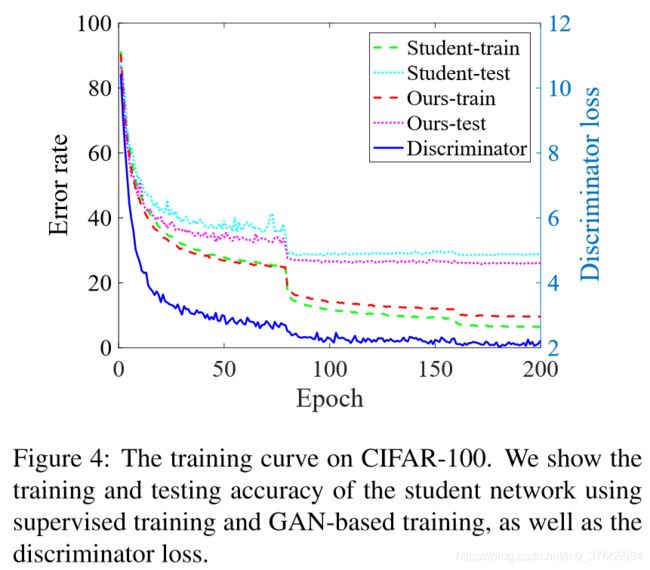
从鉴别器的曲线可以看出,这样训练时稳定收敛
一个有意思的现象是在训练集上,GAN方法误差要大于纯监督训练的误差,但是在测试集上,GAN的效果要好,这说明GAN帮助studnet网络学到了泛化能力更强的知识
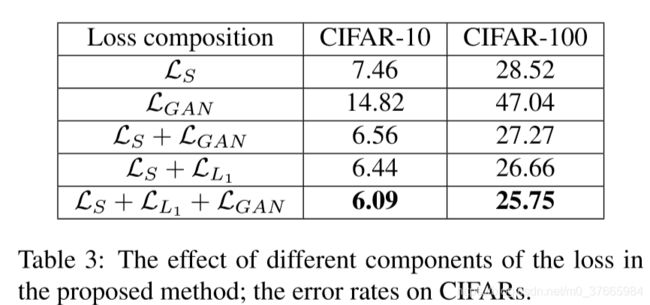
可以看出来GAN和L1是互补的两种知识蒸馏的策略
文章中说不带category-level损失的纯粹的GAN的效果要很差,这是因为没有将低级信息对齐,表格中对应的是第二行,这里猜测应该是没有将这种GAN和带有category-level损失的GAN区别
分布可视化

绿色是正样本,紫色是负样本
横轴是输出的概率,纵轴是样本数量的归一化的值
可以看到GAN方法的分布和teacher的分布很类似,证明了GAN的有效性
结论
提出了GAN方法来蒸馏知识