Transformer: Attention Is All You Need,NIPS 2017
Transformer: Attention Is All You Need, NIPS 2017
=============================================================
NLP Model Evolution:
Transformer 编码器层堆叠6层,解码器层堆叠6层
Bert 编码器层堆叠 Base12层, Large 24层
GPT-1 解码器层堆叠 12层
GPT-2 解码器层堆叠 24层 36层 48层
GPT-3 解码器层堆叠 96层
=============================================================
Transformer Encode/Decoder Layer Blocks:
Feed Forward 就是/来自 FFNN/MLP , NNLM Bengio 2003;
Add& Normal 就是/来自 Layer Normalization,Jimmy Lei Ba 2016;
Residual Learning 来自 ResNet Kaiming, 2015;
Self Attention 就是一层网络,Multi-Head就是搞出来8个不同的层代码就是一次numpy.reshape;
创新多的稍微费解的就是Muliti-head Attention,先读代码,再回头看paper。
=============================================================
NIPS 2017 https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Attention Is All You Need https://arxiv.org/abs/1706.03762
Transformer (Google AI blog) , https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
The Illustrated Transformer http://jalammar.github.io/illustrated-transformer/
【中】 https://blog.csdn.net/yujianmin1990/article/details/85221271 https://zhuanlan.zhihu.com/p/54356280
Layer Normalization https://arxiv.org/pdf/1607.06450.pdf
Image Transformer https://arxiv.org/pdf/1802.05751.pdf
Music Transformer https://arxiv.org/pdf/1809.04281.pdf
TensorFlow official implementation of Transformer:
The implementation leverages tf.keras and makes sure it is compatible with TF 2.x.
https://github.com/tensorflow/models/tree/master/official/nlp/transformer
Google注解Transformer, tf2.x Keras https://tensorflow.google.cn/tutorials/text/transformer
harvardnlp: The Annotated Transformer, Pytorch http://nlp.seas.harvard.edu/2018/04/03/attention.html
中文, https://daiwk.github.io/posts/platform-tensor-to-tensor.html
Lilian Weng,,Attention? Attention! https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html
-
-
chao-ji/tf-transformer 文档很好, https://github.com/chao-ji/tf-transformer
Create The Transformer With Tensorflow 2.0, https://trungtran.io/2019/04/29/create-the-transformer-with-tensorflow-2-0/
Transformer implementation in TensorFlow with notes, https://blog.varunajayasiri.com/ml/transformer.html OK
Transformer/tensor2tensor Github https://github.com/tensorflow/tensor2tensor/
Tensor2Tensor Colab https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb
解析Google Tensor2Tensor系统, 张金超, https://cloud.tencent.com/developer/article/1153079
Ashish Vaswani的视频
Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 14 – Transformers and Self-Attention
Ashish Vaswani & Anna Huang, Google https://www.youtube.com/watch?v=5vcj8kSwBCY
-
RAAIS 2019 - Ashish Vaswani, Senior Research Scientist at Google AI
https://www.youtube.com/watch?v=bYmeuc5voUQ
Attention is all you need; Łukasz Kaiser | Masterclass
https://www.youtube.com/watch?v=rBCqOTEfxvg
[Transformer] Attention Is All You Need | AISC Foundational
https://www.youtube.com/watch?v=S0KakHcj_rs
=============================================================
-
-
-
-
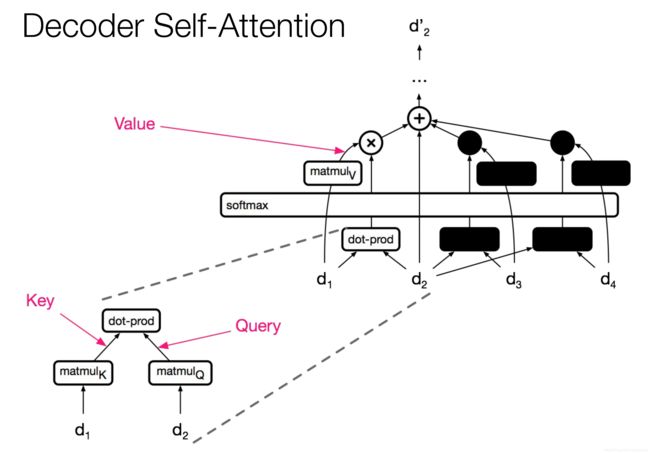
-
--
=============================================================
Illustrated Guide to Transformers- Step by Step Explanation
https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
理解Transformer的三层境界 https://www.jianshu.com/p/e9650103b813
Transformer of 2 stacked encoders and decoders:

Leo Dirac == 量子力学奠基人 Paul Dirac 保罗·狄拉克之孙
00.LSTM is dead. Long Live Transformers!--2019
https://www.youtube.com/watch?v=S27pHKBEp30
Transformer的细枝末节 https://zhuanlan.zhihu.com/p/60821628