一次完整的Pytorch卷积神经网络训练
学习完土堆的Pytorch教程之后,进行了一次完整的卷积神经网络搭建、训练以及测试(文末附最好的Pytorch入门教程,来自B站UP土堆)。
本次搭建的是CIFAR10模型,模型结构见下图;数据集选用的是CIFAR-10数据集,其中训练集有50000张图片,测试集有10000张图片,类别为10分类。

本次实验的文件结构见下图:

其中,model.py中是对模型的定义;train.py中是创建模型并进行训练;dataset中存放的则是训练和测试所用的数据集。
本文将从模型搭建、训练以及测试三部分进行讲解。
- 模型搭建
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
# 搭建网络
class CIFAR10Model(nn.Module):
def __init__(self):
super(CIFAR10Model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model(x)
return x
创建一个CIFARModel的对象,并打印,从结果可以看出,模型已经正确定义完成!
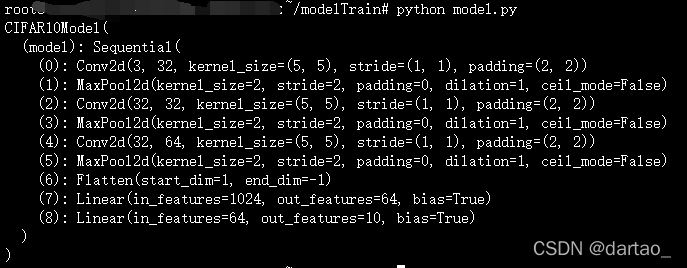
2. 模型的训练
import torchvision
import torch
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from model import *
'''
训练过程如下:
1. 加载数据集,并对读入的数据进行ToTensor()变换
2. 使用DataLoader获取数据集中的数据,定义batch_size大小
3. 创建模型model,因为我这里直接把模型的定义单独放到一个文件中,并且在文件头全部import进入了,因此可以直接创建模型
4. 定义训练过程中的相关参数,包括损失函数、优化器以及训练轮数
5. 设置双层循环,开始训练,在每一轮训练中,完成训练集的一次训练后,需要在测试集上进行一次验证
6. 每完成一轮训练,保存一次模型的参数,实际训练时可以根据自己需要每几轮保存一次
7. 训练完成
'''
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_set = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_set = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
traindata_size = len(train_set)
testdata_size = len(test_set)
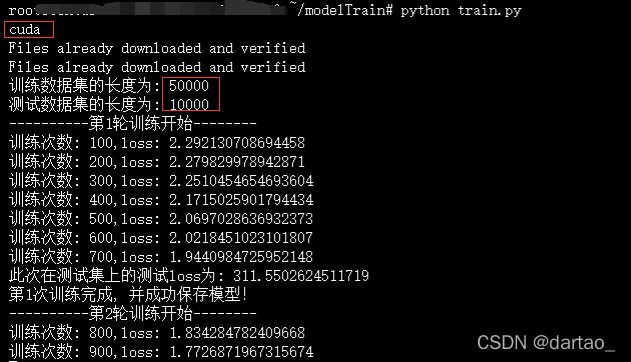
print("训练数据集的长度为: {}".format(traindata_size))
print("测试数据集的长度为: {}".format(testdata_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_set, batch_size=64)
test_dataloader = DataLoader(test_set, batch_size=64)
# 创建模型
model = CIFAR10Model()
model = model.to(device) # 调用GPU
# 损失函数
loss = nn.CrossEntropyLoss()
loss = loss.to(device) # 调用GPU
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 训练次数
total_train_step = 0
# 测试次数
total_test_step = 0
# 训练轮数
epochs = 10
for epoch in range(epochs):
print("----------第{}轮训练开始--------".format(epoch+1))
# 训练开始 每次以batch_size=64训练
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # 调用GPU
targets = targets.to(device)
output = model(imgs)
# 计算损失
result_loss = loss(output, targets)
optimizer.zero_grad()
result_loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数: {},loss: {}".format(total_train_step, result_loss))
# 在每一轮的训练中,训练完,会使用测试集进行一次测试
total_test_loss = 0.0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = model(imgs)
result_loss = loss(output, targets)
total_test_loss = total_test_loss + result_loss
print("此次在测试集上的测试loss为: {}".format(total_test_loss))
# 每训练一轮, 保存一次模型
torch.save(model, "model_{}.pth".format(epoch+1))
print("第{}次训练完成, 并成功保存模型!".format(epoch+1))
在命令行输入python train.py开始运行:
模型参数保存成功:

- 对模型进行测试
在上面的模型训练的过程中,保存了一些已经训练好的模型参数,对模型进行测试的时候,直接加载已经训练好的模型即可。
import torch
import torchvision
from PIL import Image
from torch import nn
from model import *
'''
我这里是使用单张图片对模型进行验证
对模型的测试过程如下:
1. 读取图片数据
2. 对数据进行处理
3. 加载模型,因为保存模型的时候使用torch.load(.),因此读入的时候,要在
'''
image_pth = "dddog.jpeg"
image = Image.open(image_pth)
print(image)
# 对读入的数据进行处理,包括ToTensor()、Resize()以及reshape()等等
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
image = torch.reshape(image, (1,3,32,32)) # reshape之后为 [1,3,32,32]
print(image.shape)
# 加载模型
model = torch.load("model_15.pth")
# 开启模型验证模式
model.eval()
with torch.no_grad():
output = model(image.type(torch.cuda.FloatTensor))
print(output)
print(output.argmax(1))
在命令行中输入python test.py得到如下结果:

由于时间关系,我只训练了10个epochs,但是可以看出,还是能够将图片正确分类为dog。

- 一次完整的炼丹完成!
附:最好的Pytorch入门教程-土堆(向所有准备入坑炼丹的人疯狂安利!!!)
有问题欢迎大家评论区指出,欢迎叨扰,哈哈哈…