【MySQL】Spring Boot项目基于Sharding-JDBC和MySQL主从复制实现读写分离(8千字详细教程)

目录
- 前言
- 一、 介绍
- 二、 主从复制
-
- 1. 原理
- 2. 克隆从机
- 3. 克隆从机大坑
- 4. 远程登陆
- 5. 主机配置
- 6. 从机配置
- 7. 主机:建立账户并授权
- 8. 从机:配置需要复制的主机
- 9. 测试
- 10. 停止主从同步
- 三、 读写分离
-
- 1. Sharding-JDBC介绍
- 2. 一主一从
- 3. 一主一从读写分离
-
- 3.1 实现步骤
- 3.2 配置读写分离规则
- 3.3 允许bean定义覆盖配置项
- 3.4 启动项目测试
前言
- 本篇文章将手把手教你如何在 Linux 虚拟机上搭建 MySQL 一主一从的数据库架构,教你如何实现 MySQL 主从复制,再到手把手教你如何在 Spring Boot 项目上使用 Sharding-JDBC 框架实现读写分离。
- 笔者开发环境介绍:
- Linux 系统:Centos 7
- 虚拟机:VMware 16
- MySQL :8.0.31
- 如果还没安装 VMware 虚拟机软件和 CentOS 7 的小伙伴可以移步到我的这篇博文进行学习——《Linux系统CentOS7虚拟机VMware安装保姆级教程》。
- 如果不知道在 CentOS 7 如何安装 MySQL 的小伙伴可以移步到我的这篇博文进行学习——《Linux下如何安装MySQL以及远程登录保姆级教程》。
一、 介绍
-
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行级锁,使得整个系统的查询性能得到极大的改善。这就称为读写分离。
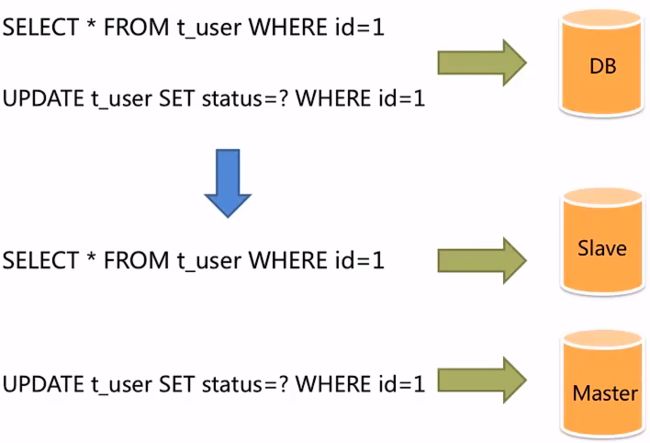
二、 主从复制
1. 原理
- MySQL 主从复制是一个异步的复制过程,底层是基于 MySQL 数据库自带的二进制日志 (Binlog) 功能。就是一台或多台 MySQL 数据库 (slave,即从库) 从另一台 MySQL 数据库 (master,即主库) 进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL 主从复制是 MySQL 数据库自带功能,无需借助第三方工具。
- MySQL 复制过程分成三步:
- master 将改变记录到二进制日志 (binary log) ;
- slave 将 master 的 binary log 拷贝到它的中继日志 (relay log) ;
- slave 重做中继日志中的事件,将改变应用到自己的数据库中。

2. 克隆从机
-
首先要准备两台 Linux 虚拟机,笔者已经安装过一台虚拟机作为主机,IP 地址为
192.168.148.100(server100) ,现在我们通过 VMware 软件的 “克隆” 功能来克隆出第二台 Linux 虚拟机作为从机,IP 地址设置为192.168.148.101。 -
首先关闭 server100 :

-
然后左侧右击 server100 –> 管理 –> 克隆:

-
点击 “下一页” :
-
保持默认,下一页:
-
选择 “创建完整克隆” ,点击下一页:

-
改名、改存放路径:

-
开始克隆:

-
克隆完成:
-
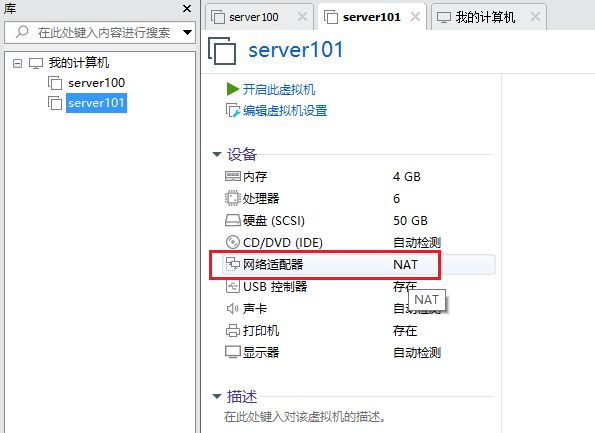
克隆完成后,要修改四个位置。第一个是网络,双击 server101 的网络适配器:
-
点击 “高级” :

-
点击 “生成” 来修改 MAC 地址,确保两台虚拟机的 MAC 地址不同:

-
然后,开机 server101 ,登录 root 用户:


-
修改主机名称。命令如下:
vim /etc/hostname
记得
:wq保存退出。 -
重命名后需要重启:
reboot
-
重启完再以 root 用户登录,下一步是更改 IP 地址:
vim /etc/sysconfig/network-scripts/ifcfg-ens33 -
改两个地方,一个是
UUID,确保和 server100 不同即可;另一个是IPADDR,我修改为192.168.148.101。
修改好后按
:wq保存退出。 -
然后重启网络:
systemctl restart network -
这样,一台虚拟机就克隆完成了。重要的是,里面曾经安装的 JDK、MySQL、Redis 等软件和数据都是跟 server100 保持一致的。这就省去了我们重复安装和配置的麻烦了。

3. 克隆从机大坑
-
克隆的方式生成的虚拟机 (包含 MySQL Server),则克隆的虚拟机 MySQL Server 的 UUID 相同 (此 UUID 是 MySQL 服务的 UUID,和前面修改的 Linux 网络配置的 UUID 不是同一个东西) ,必须修改,否则在有些场景会报错。比如:
show slave status\G,报如下的错误:Last_IO_Error: Fatal error: The slave I/0 thread stops because master and slave have equal MySQL server UUIDs; these UUIDS must be different for replication to work. -
解决方法:
修改 MySQL Server 的 UUID 方式:
vim /var/lib/mysql/auto.cnf
自己随便改,与 server 100 不同即可。
-
然后,重启 MySQL 服务即可:
systemctl restart mysqld
4. 远程登陆
-
笔者采用 MobaXTerm 远程登陆:

-
新建连接:

-
成功远程连接:

-
此时,server100 也可以开机了:

-
server100 作为主机、server101 作为从机,一主一从实现读写分离。
-
SQLyog 远程登录 - 教程详见我的这篇博文的第 4 章《4. SQLyog远程连接》。
5. 主机配置
-
建议 MySQL 版本一致且后台以服务运行,主从所有配置项都配置在[mysqld] 节点下,且都是小写字母。具体参数配置如下:
-
必选:
# [必须]主服务器唯一ID server-id=100 # [必须]启用二进制日志,指名路径。比如:自己本地的路径/log/mysqlbin log-bin=ouc-bin -
可选:
# [可选] 0(默认)表示可读可写(主机),1表示只读(从机) read-only=0 # 设置日志文件保留的时长,单位是秒 binlog_expire_logs_seconds=6000 # 控制单个二进制日志大小。此参数的最大和默认值是1GB max_binlog_size=200M # [可选]设置不要复制的数据库 binlog-ignore-db=test # [可选]设置需要复制的数据库,默认全部记录。比如: binlog-do-db=atguigu_master_slave binlog-do-db=需要复制的主数据库名字 # [可选]设置binlog格式 binlog_format=STATEMENT -
重启后台 MySQL 服务,使配置生效。
【注意】
- 先搭建完主从复制,再创建数据库。MySQL 主从复制起始时,从机不继承主机数据。
-
进入主机 server100 ,输入以下命令进入 biglog 配置文件:
vim /etc/my.cnf -
在第 3 行左右,修改成如下的样子:

按
:wq保存并退出。 -
然后重启 MySQL 服务:
systemctl restart mysqld
6. 从机配置
-
从机 server101 也如法炮制。
-
要求主从所有配置项都配置在
/etc/my.cnf的[mysqld]栏位下,且都是小写字母。 -
必选:
[mysqld] # [必须]从服务器唯一ID,要与主服务器不同 server-id=101 -
可选:
# [可选]启用中继日志 relay-log=mysql-relay
-
重启后台 mysql 服务,使配置生效。
systemctl restart mysqld
【注意】
- 主、从机都要开放 MySQL 端口号 3306 的防火墙。
7. 主机:建立账户并授权
-
如果你使用的是 MySQL 5.7 ,只需执行下面一条指令即可:
-- MySQL 5.7专用 GRANT REPLICATION SLAVE ON *.* TO 'slave101'@'从机器数据库IP' IDENTIFIED BY 'xsh981104';其中,
‘slave101’是你自己起的从机名称。 -
注意,笔者使用的是 MySQL 8.0 ,在主机端进入 MySQL root 用户,输入以下命令创建名为
slave101的账户,用于主机和从机之间的通信:mysql> CREATE USER 'slave101'@'%' IDENTIFIED BY 'xsh981104'; -
我创建的时候报了一个错误:
ERROR 1396 (HY000): Operation CREATE USER failed for 'slave101'@'%' -
原因是这个用户之前创建过,但删除了,没有刷新权限。解决方法是先删除这个用户,然后再刷新权限,再次创建即可。
-- 删除用户 DROP USER 'slave101'; -- 刷新权限 FLUSH PRIVILEGES; -- 再次创建用户 CREATE USER 'slave101'@'%' IDENTIFIED BY 'xsh981104'; -
成功创建用户
slave101:
-
然后,赋予用户
slave101权限:GRANT REPLICATION SLAVE ON *.* TO 'slave101'@'%';其中,
REPLICATION指的是主从复制的权限、*.*表示任何数据库下的任何表、'slave101'@'%'表示授予权限的用户。
-
授权后,可以用下面的命令来查看用户
slave101拥有的所有权限:SHOW GRANTS FOR 'slave101'@'%';
-
然后,如果你是 MySQL 8.0 ,下面的语句必须执行。否则出问题:
ALTER USER 'slave101'@'%' IDENTIFIED WITH mysql_native_password BY 'xsh981104';
【注意】
- 上面这句不执行,从机执行
show slave status\G时会报下面的错误:Last_IO_Error: error connecting to master ‘[email protected]:3306’ - retry-time: 60 retries: 1 message: Authentication plugin ‘caching_sha2_password’ reported error: Authentication requires secure connection.
-
刷新权限:
FLUSH PRIVILEGES;
-
接下来是比较重要的步骤:查询 Master 的状态,并记录下
File和Position的值:SHOW MASTER STATUS;
记录下
File和Position的值。注意执行完此步骤后不要再操作主服务器,防止主服务器状态值变化。 -
到这里,主库的配置就完成了。
8. 从机:配置需要复制的主机
-
步骤1-从机上,进入 MySQL ,开始复制主机:
CHANGE MASTER TO MASTER_HOST='主机的IP地址', MASTER_USER='主机用户名', MASTER_PASSWORD='主机用户名的密码', MASTER_LOG_FILE='ouc-bin.00000X', MASTER_LOG_POS=主机的Position值; -
举例:
CHANGE MASTER TO MASTER_HOST='192.168.148.100',MASTER_USER='slave101',MASTER_PASSWORD='xsh981104',MASTER_LOG_FILE='ouc-bin.000002',MASTER_LOG_POS=1805;
-
步骤2-启动 slave 同步:
START SLAVE;
-
疑难杂症 1 - 有的小伙伴在步骤一时遇到类似下面的报错:
ERROR 3021 (HY000): This operation cannot be performed with a runing slave io thread; run STOP SLAVE IO_THREAD FOR CHANNEL '' first.这是因为从库之前已经配置过主从复制,必须先停掉原来的:
STOP SLAVE;再重新执行步骤 1 和 2 即可。
-
疑难杂症 2 - 有的小伙伴还遇到下面的报错:
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository这是因为之前你开启过中继日志,又关掉了。解决方法是重置一下即可:
RESET SLAVE; -
接着,查看从库的同步状态:
SHOW SLAVE STATUS\G;
-
这样,主从复制就搭建完毕了。
9. 测试
-
用 SQLyog 远程连接至主库和从库。
-
在主库
192.168.148.100中创建一个新的数据库test1:CREATE DATABASE IF NOT EXISTS test1 CHARACTER SET 'utf8'; -
使用该数据库,在该数据库下创建数据表
students:CREATE TABLE IF NOT EXISTS students( id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT, last_name VARCHAR(15) NOT NULL ); -
在该表下插入数据:
INSERT INTO students(last_name) VALUES('Tom'), ('Amy'); -
查看主库:
SELECT * FROM students;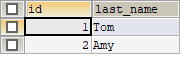
-
打开从库
192.168.148.101,再没有任何操作的情况下,发现已经把主库的数据库test1以及数据表students复制过来了:
-
且数据表
students中的数据也是完全相同的:SELECT * FROM students; -
说明主从复制搭建成功。
10. 停止主从同步
-
如果你想停止主从同步,只需在从库输入下面指令即可:
STOP SLAVE;
三、 读写分离
1. Sharding-JDBC介绍
-
Sharding-JDBC 定位为轻量级 Java 框架,在Java的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。使用 Sharding-JDBC 可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于 JDBC 的 ORM 框架,如: JPA、Hibernate、 Mybatis、Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如: DBCP、 C3PO、 BoneCP、Druid、 HikariCP 等。
- 支持任意实现 JDBC 规范的数据库。目前支持 MySQL、 Oracle、 SQLServer、 PostgreSQL 以及任何遵循 SQL92 标准的数据库。
-
与 Spring Boot 结合使用时,只需要添加 Maven 依赖坐标即可:
<dependency> <groupId>org.apache.shardingspheregroupId> <artifactId>sharding-jdbc-spring-boot-starterartifactId> <version>4.0.1version> dependency>
2. 一主一从
-
在实现读写分离之前,要把 MySQL 的主从复制的结构搭建好。
-
笔者的主库 IP 地址为
192.168.148.100,从库 IP 地址为192.168.148.101。版本都是 MySQL 8.0.31 。 -
如果你的 MySQL 数据库安装在 Windows 电脑上,把 Windows 电脑上的数据库备份成
.sql文件,恢复到主库上即可。不知道的小伙伴可以转到我的这篇博文中学习——《如何把Windows上的MySQL数据库迁移到Linux服务器上》。

3. 一主一从读写分离
3.1 实现步骤
- 使用 Sharding-JDBC 实现读写分离只需要三步:
- 导入 Sharding-JDBC 的 Maven 坐标;
- 在配置文件
application.yml中配置读写分离规则; - 在配置文件
application.yml中配置允许 bean 定义覆盖配置项。
3.2 配置读写分离规则
-
打开 Spring Boot 的配置文件
application.yml。在spring:节点下添加下面的配置:spring: # 配置Sharding-JDBC读写分离规则 shardingsphere: # 指定数据源 datasource: names: master,slave # 一主一从 # 配置主库数据源 master: # 必须跟上面names对应 type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.148.100:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true username: root password: xsh981104 # 配置从库数据源 slave: # 必须跟上面names对应 type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.148.101:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true username: root password: xsh981104 # 读写分离配置 masterslave: load-balance-algorithm-type: round_robin # 多个从库的负载均衡策略:轮询 name: dataSource # 最终的数据源名称 master-data-source-name: master # 主库数据源名称 slave-data-source-names: slave # 从库数据源名称列表,多个逗号分隔 props: sql: show: true # 开启SQL显示,默认false -
大家根据自己的主、从库的 IP 地址和密码作相应的修改即可。
-
如果有爆红的情况,那就把
pom.xml中的 Duird 的 Maven 坐标改成下面即可:<dependency> <groupId>com.alibabagroupId> <artifactId>druidartifactId> <version>1.2.8version> dependency> -
然后,清除 IDEA 缓存并重启 IDEA 即可正常启动 Spring Boot 项目:


3.3 允许bean定义覆盖配置项
-
为什么要配置这一项呢?是因为 Sharding-JDBC 和 Druid 都会创建一个
DataSource的 bean ,这样两个重名的 bean 就会发生冲突。因此必须在 Spring Boot 配置文件application.yml中配置允许 bean 定义覆盖为 true ,这样,后定义的 bean 就会覆盖前面定义的 bean ,从而解决了 bean 冲突的问题。spring: main: # 允许bean定义覆盖 allow-bean-definition-overriding: true -
这样,基于 MySQL 主从复制实现读写分离就成功实现了。
3.4 启动项目测试
-
启动 Spring Boot 项目,可以看到启动日志里生成了两个数据源:

-
打开浏览器来测试一下,在浏览器地址栏输入你项目的地址,笔者这里是黑马的《瑞吉外卖》的后台管理系统。
-
从日志中可以看到,读取员工表是从 slave 从库中读取的:

-
我们来测试一下写操作,编辑一下员工信息:

-
可以看到,写操作是主库 master 操作的:

-
至此,基于 MySQL 主从复制实现读写分离就成功开发完毕了!
-
如果你还有任何疑问,欢迎随时在下方评论或者私信我,我会尽快给大家解答。