【spark】一文(10分钟)入门spark
文章目录
- 前言
- 一、开启分布式运算
-
- 1、单机运算
- 2、分布式运算思路
- 3、分布式运算代码示例
- 4、spark运算
- 总结
前言
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,在处理大量的数据时,采用分布式计算来加快运算速度。
采用一些官方的解释,总会让人摸不到头脑,spark是用来计算的,但是计算啥呢?啥时候用呢?来一个"hello world"。如果有一个集合:
List(1,2,3,4)
计算集合中每个数值乘2得多少?这点数据瞬间即可口算出来。但是在遇到足够多的数据的时候,人脑无法一眼看出,并且单体的计算机运算起来也可能吃力起来。
一、开启分布式运算
1、单机运算
通过代码来实现List(1,2,3,4) 的运算(scala)
def main(args: Array[String]): Unit = {
var data = List(1,2,3,4);
val list = compute(data);
list.foreach(println)
}
// 运算方法
var compute=(list:List[Int])=>{
list.map(logic);
}
// 逻辑方法
var logic=(num:Int)=>{
num*2
}
如上例子,实现了将集合中的数据全部乘2然后返回。这个例子很简单,数据量又小,完全没有必要进行分布式计算,但是,可以引入分布式计算的新篇章。
2、分布式运算思路
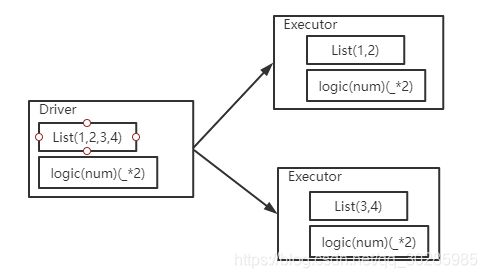
(图 A)
如图所示,分布式计算时存在一个任务的发布者Driver,和任务的执行者Executor。任务发布者把要计算的数据按照按照一定的规则拆分,将拆分的数据和逻辑发送到执行者中执行,执行完毕返回。
数据拆分的过程可以成为数据分区,拆分的结果可以称之为分片,按照如上的思路,即使再多的数据,都可以按照特有的规则进行数据分区,将每个分片发送到不同的机器执行,提高执行速度。
3、分布式运算代码示例
按照图A的思路的话,在进行任务的发布和执行过程中,应该有3台机器,此时可以假设Executor为server,Driver为client,他们之间通过Socket来进行信息传输。
代码如下(server或者称为Executor):
def main(args: Array[String]): Unit = {
// 启动服务器,接收数据
val server = new ServerSocket(9999)
println("服务器启动,等待接收数据")
// 等待客户端的连接
val client: Socket = server.accept()
val in: InputStream = client.getInputStream
val objIn = new ObjectInputStream(in)
val task: SubTask = objIn.readObject().asInstanceOf[SubTask]
val ints: List[Int] = task.compute()
println("计算节点[9999]计算的结果为:" + ints)
objIn.close()
client.close()
server.close()
}
启动两个Executor,一个为端口为8888另一个端口为9999(代码一样)。来模拟两个执行者,等待Driver提交执行数据和逻辑。
代码如下(Driver或者称为Client):
// 注意Serializable关键字,否则socket传输会报错
class Task extends Serializable {
val datas = List(1,2,3,4)
//val logic = ( num:Int )=>{ num * 2 }
val logic : (Int)=>Int = _ * 2
}
class SubTask extends Serializable {
var datas : List[Int] = _
var logic : (Int)=>Int = _
// 计算
def compute() = {
datas.map(logic)
}
}
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
object Driver {
def main(args: Array[String]): Unit = {
// 连接服务器
val client1 = new Socket("localhost", 9999)
val client2 = new Socket("localhost", 8888)
val task = new Task()
val out1: OutputStream = client1.getOutputStream
val objOut1 = new ObjectOutputStream(out1)
// 获取发送给Executor1的数据和逻辑
val subTask = new SubTask()
subTask.logic = task.logic
subTask.datas = task.datas.take(2)
objOut1.writeObject(subTask)
objOut1.flush()
objOut1.close()
client1.close()
val out2: OutputStream = client2.getOutputStream
val objOut2 = new ObjectOutputStream(out2)
// 获取发送给Executor2的数据和逻辑
val subTask1 = new SubTask()
subTask1.logic = task.logic
subTask1.datas = task.datas.takeRight(2)
objOut2.writeObject(subTask1)
objOut2.flush()
objOut2.close()
client2.close()
println("客户端数据发送完毕")
}
}
输出:
Driver:
客户端数据发送完毕
Executor:
服务器启动,等待接收数据
计算节点[8888]得到数据:List(3, 4),计算的结果为:List(6, 8)
Executor2:
服务器启动,等待接收数据
计算节点[9999]得到数据:List(1, 2),计算的结果为:List(2, 4)
代码思路如下:
- 两个Executor启动服务等待客户端提交数据和逻辑。
- Driver将数据List(1,2,3,4)拆分为List(1,2)和List(3,4)
- Driver将分片分别发送到两个Executor执行。
- Executor收到数据和计算逻辑进行计算,计算结果打印。
4、spark运算
上面展示了最原始的分布式计算逻辑方式。但是spark为分布式计算框架,既然是框架,肯定会把很多公有的逻辑进行分装。通过spark实现如上功能
代码如下(scala示例):
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local")
.appName("test")
.getOrCreate()
val sc = spark.sparkContext;
//上面代码暂时不需要理解,是spark的本地调试的固定写法。
//创建RDD并且处理逻辑
val value = sc.makeRDD(List(1, 2, 3, 4))
.map(_*2);
value.collect().foreach(println)
sc.stop()
这点代码,spark即可帮我们完成数据的分区、数据和逻辑的发送、执行中异常的处理等等。
为何spark这么强,因为spark有一个很强的数据结构RDD。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。着重说下不可变是指计算的逻辑不可变,RDD中分装了计算逻辑是不允许改变的;可分区是指RDD的数据可以自行分区,分区之后才可以在不同的机器上并行执行。
代码中的makeRDD是将List集合转换成了RDD数据结构,.map(_*2)方法简化版本的写法,意思是数据乘以2。
虽然RDD帮我们做了那么多,有些时候还是需要更详细的看一看才会理解,比如它是按照什么规则分区呢?分几个区?数据又是如何划分呢?参考【spark】RDD分区解析
总结
虽然只是一个简单的例子,但是也足以了解spark的工作的思想。通过这一思想可以实现很多复杂的逻辑的计算。这样看来spark是如此的简单,但是现在又想说spark又是如此的复杂,因为spark封装了很多逻辑需要了解。
比如spark的一个任务的某一个Execotor执行错误之后需要如何处理呢?比如发送的数据巨大,好几个G的时候,spark又是如何处理呢?spark集群又是如何工作呢?这里面也有太多太多需要学习的地方。