wandb(Weights & Biases) 深度学习轻量级可视化工具
wandb是Weights & Biases的缩写,是类似TensorBoard, visdom的一款可视化工具
是属于Python的,不是Pytorch的
wandb是最大的特点是能自动上传云端,让你即使在外面或者旅行途中也能随时随地查看模型崩没崩。甚至觉得某个模型跑的不好了在手机上就可以停掉它。
但是wandb必须要联网,没网的本地电脑是没法跑的
首先要注册账号
wandb能够很好解决tensorboard的痛点
我们使用tensorboard的痛点是,如果想要在一张图里比较多个模型的曲线,要将不同模型都copy到同一个目录下才行
如果想要记录一些超参配置的话,可能要起很长的名字才行
wandb能够很好解决这些痛点
Weights & Biases - Documentation (wandb.ai)
Quickstart (快速上手) - Documentation (wandb.ai)
wandb的重要的工具:
- Dashboard:跟踪实验,可视化结果;
- Reports:分享,保存结果;
- Sweeps:超参调优;
- Artifacts:数据集和模型的版本控制。
pip install wandb然后
wandb login在代码里
args.wandb_id = wandb.util.generate_id() wandb.init( project = "DAB_DETR", config = args, name = 'debug', id = args.wandb_id, #resume = True, )log
log不需要记录step,会自动一直递增
wandb.log({'accuracy': train_acc}) wandb.log({'loss': train_loss})但是这样会引起一个问题,一旦batchsize改变,训的step数是不同的,就不好一块比了
训练的时候主要是看趋势,还可以
但是在测试的时候,要把epoch也记录上,这样的话,查看的时候x轴转换成epoch就可以比较了
wandb.log({'AP': stats['coco_eval_bbox'][0], 'AP50': stats['coco_eval_bbox'][1], 'epoch': epoch, })watch
可以记录模型parameters和gradient
要在定义好model之后,开始训练之前加
wandb.watch(net, log='all', log_freq=1)默认log_freq是1000
但是记录的时候会不显示
把模型点进去之后才能看到
当模型的performance/loss开始趋平,不再提升的时候,梯度值也应该shrink到0.
如果梯度值在减小,而performance/loss并不是我们所期望的那样,那么很可能是被困在了一个局部最优值点了。此时,提升lr或者relax regularization约束都有可能help
resume
要resume的时候,把wandb.init的id换成之前那个实验的id
然后wandb.init()的resume设成True即可
这样的话有一个小问题,wandb会继续之前中断的step开始写入,例如latest epoch是epoch_10,但是这个终端的地方有可能是epoch_11已经训了一半了,我们load epoch_10是从epoch_11从头开始训,而wandb却会从epoch_11训到一半的step开始继续记录,所以这个epoch_11的曲线会更长,后面的也就会有错位了,像
导出report
可以选择某些图然后导出report
可以通过链接/邮件或者转成pdf给别人分享
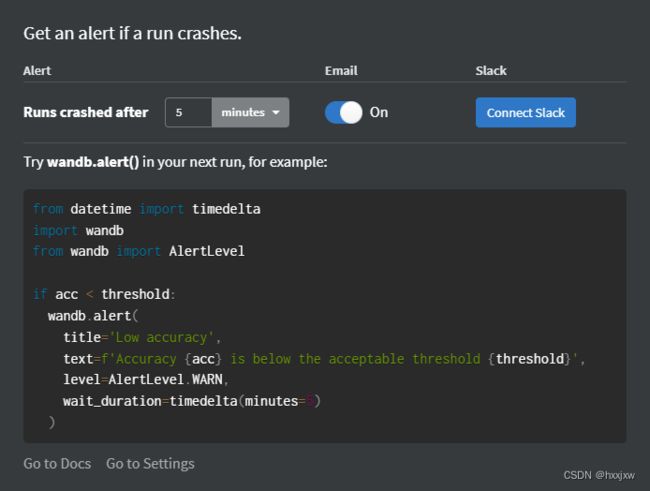
设置提醒
将一个run移到另一个project中
- Sweeps:通过改变超参数来优化模型;
- Artifacts:可以自己搭建pipline实现保存储存数据集和模型以及评估结果的流程。
wandb使用教程(一):基础用法 - 知乎 (zhihu.com)
wandb使用教程(二):基于Launchpad实现分布式超参搜索 - 知乎 (zhihu.com)
wandb使用教程(三):数据与模型管理 - 知乎 (zhihu.com)
wandb: 深度学习轻量级可视化工具入门教程_紫芝的博客-CSDN博客_wandb使用
Wandb:模型训练最强辅助 - 知乎




sweep超参搜索
要把整个训练的代码写成一个train函数,并且在这个train函数内部wandb.init()
搜索方法有
- grid search(网格搜索): 穷举法,在所有的参数组合中,通过循环便利,尝试每一种可能性,选取评价指标最好的参数输出
- random search(随即搜索):在预先设定的定义域内随机选取超参数组合
- bayes search(贝叶斯搜索):区别于grid search和bayes search相对独立的参数搜索方式,bayes search希望通过上一次的效果来决定下一次的参数选择,以提高搜索效率
import torch import torchvision from torchvision import transforms from matplotlib import pyplot as plt from torch import nn from torch.nn import functional as F from torch import optim import os import wandb import math def one_hot(label, depth=10): out = torch.zeros(label.size(0), depth) idx = torch.LongTensor(label).view(-1, 1) out.scatter_(dim=1, index=idx, value=1) return out class Net(nn.Module): def __init__(self): super(Net, self).__init__() #三层全连接层 #wx+b self.fc1 = nn.Linear(28*28, 256) self.fc2 = nn.Linear(256,64) self.fc3 = nn.Linear(64,10) def forward(self, x): # x: [b, 1, 28, 28] x = F.relu(self.fc1(x)) #F.relu和torch.relu,用哪个都行 x = F.relu(self.fc2(x)) x = self.fc3(x) return x cnt = -1 def train(): global cnt cnt += 1 wandb.init( project = "test", # config = args, name = f'debug_hypersearch_{cnt}', # id = args.wandb_id, #resume = True, ) print(wandb.config) print(wandb.config.batch_size) batch_size = wandb.config.batch_size transform = transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.1307,), (0.3081,)) ]) trainset = torchvision.datasets.MNIST( root='dataset/', train=True, #如果为True,从 training.pt 创建数据,否则从 test.pt 创建数据。 download=True, #如果为true,则从 Internet 下载数据集并将其放在根目录中。 如果已下载数据集,则不会再次下载。 transform=transform ) train_loader = torch.utils.data.DataLoader( dataset=trainset, batch_size=batch_size, shuffle=True #在加载的时候将图片随机打散 ) testset = torchvision.datasets.MNIST( root='dataset/', train=False, download=True, transform=transform ) test_loader = torch.utils.data.DataLoader( dataset=testset, batch_size=batch_size, shuffle=True ) net = Net() #创建网络对象 # [w1, b1, w2, b2, w3, b3] optimizer = optim.SGD(net.parameters(), lr=1e-2, momentum=0.9) lr = wandb.config.learning_rate train_loss = [] for epoch in range(3): #train_loader长度118 for idx, data in enumerate(train_loader): #当然这里你也可以写next(iter(train_loader)) if idx > 50: break inputs, labels = data inputs = inputs.view(inputs.size(0), 28*28) #现在inputs是[512, 28*28] outputs = net(inputs) #outputs是[512,10] labels_onehot = one_hot(labels) # 就是将y转成onehot # y是512个label值,是一个512*1的tensor数组 # y_onehot是512个10维的,即512*10的tensor数组 # 例如y的label是2,那么对应的y_onehot就是0,1,2,第三个位置为1,其余位置为0这样 loss = F.mse_loss(outputs, labels_onehot) #用torch.nn.MSELoss()也行 optimizer.zero_grad() loss.backward() optimizer.step() train_loss.append(loss.item()) wandb.log({'loss': loss.item(),'lr': lr,'epoch': epoch}) if idx % 10 == 0: print(epoch, idx, loss.item()) torch.save(net.state_dict(), 'params.pkl') print('model has been save into params.pkl.') if __name__ == '__main__': #第一步:定义sweeps 配置,也就是超参数搜索的方法和范围 # 超参数搜索方法,可以选择:grid random bayes sweep_config = { 'method': 'random' } # 参数范围 parameters_dict = { 'learning_rate': { # a flat distribution between 0 and 0.1 'distribution': 'uniform', 'min': 0, 'max': 0.1 }, 'batch_size': { # integers between 32 and 256 # with evenly-distributed logarithms 'distribution': 'q_log_uniform', 'q': 1, 'min': math.log(32), 'max': math.log(256), } } sweep_config['parameters'] = parameters_dict # from pprint import pprint # pprint(sweep_config) #第二步:初始化sweep #一旦定义好超参数调优策略和搜索范围,需要一个sweep controller管理调优过程 sweep_id = wandb.sweep( sweep_config, project="test" ) wandb.agent(sweep_id, train, count=5)画图
基于wandb sweeps的pytorch超参数调优实验 - 知乎 (zhihu.com)