Wandb——Pytorch模型指标可视化及超参搜索
Wandb——Pytorch模型指标可视化及超参搜索
文章目录
- Wandb——Pytorch模型指标可视化及超参搜索
- 前言
- 一、wandb是什么?
- 二、可视化模型参数
-
- 1.伪代码
- 2.官方示例
-
- >> step0:
- >> step1:
- >>>>>>>>>>>>> 中场休息梳理后续代码结构<<<<<<<<<<<<
- >> step2:
- >> step3:
- >> step4:
- >> step5:
- 三、超参搜索
-
- 替换
- 添加
- 最后
- 附录
前言
之前在使用YOLOV5开源代码的过程中注意到里面有个名为wandb的包,用来记录并可视化模型参数(类似tensorboard,但更好看嘿嘿),用起来非常方便。 最近抽了两天折腾了一下,但感觉不论是官网的示例还是中文平台上的一些教程都非常模棱两可(不排除是我菜一时半会看不明白,所以决定记录一下自己探索的过程,一方面方便自己复盘,另一方面也方便其他有类似需求的人参考。
提示:这里仅尝试了结合Pytorch进行模型参数记录以及超参搜索,更多用法仍有待探索
一、wandb是什么?
wandb全称“ Weights & Biases ”,说白了就是“ y = w*x + b ”中的权重和偏置,只不过对应到深度学习中会更为复杂一些。
按照官网的解释,wandb是一款提供给开发人员的用来更好更快构建机器学习模型的平台,具有轻量化、可交互、快速跟踪实验、追踪版本、迭代数据集、评估模型性能、重现模型、可视化结果和点回归等特性。同时也非常方便将实验分享给其他人。

这里给出一些相关网址:
wandb官网:https://wandb.ai/site
wandb文档:https://docs.wandb.ai/v/zh-hans/
常见报错及解决:https://docs.wandb.ai/guides/sweeps/faq
模型参数可视化colab示例:http://wandb.me/pytorch-colab
超参搜索colab示例:https://colab.research.google.com/github/wandb/examples/blob/master/colabs/pytorch/Organizing_Hyperparameter_Sweeps_in_PyTorch_with_W%26B.ipynb
提示:如果网上不去说明需要xxx,不用担心后面给出了重要部分的截图 或也可参考下方代码
二、可视化模型参数
1.伪代码
代码大致可分为以下步骤:
①导包
②初始化一个项目
③设置参数
④设定好模型和数据集
⑤追踪模型参数并记录
⑥储存模型
# import the library
import wandb
# start a new experiment
wandb.init(project="new-sota-model")
# capture a dictionary of hyperparameters with config
wandb.config = {"learning_rate": 0.001, "epochs": 100, "batch_size": 128}
# set up model and data
model, dataloader = get_model(), get_data()
# optional: track gradients
wandb.watch(model)
for batch in dataloader:
metrics = model.training_step()
# log metrics inside your training loop to visualize model performance
wandb.log(metrics)
# optional: save model at the end
model.to_onnx()
wandb.save("model.onnx")
2.官方示例
>> step0:
这步的主要作用是引入一些后续需要使用的包并初始化设备是GPU还是CPU
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm.notebook import tqdm
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
>> step1:
导入wandb的包 并登录(代码执行后会弹出网址 ,点进去先注册,然后就会给一串代码用来登录 复制粘贴即可)
在此之前需要先在命令行使用‘pip install wandb --upgrade’以安装该包
注意:如果上述过程是使用jupyternotebook操作,会有警告“找不到你正在使用的notebook”,不用担心,这是个bug忽视即可,不会对后续产生影响;再有就是使用jupyternotebook的话输出行是没有办法进行交互的,也就是没办法把那串代码粘贴进去,这时候用命令行运行这两行代码即可,然后在回来就好
import wandb
wandb.login()
>>>>>>>>>>>>> 中场休息梳理后续代码结构<<<<<<<<<<<<
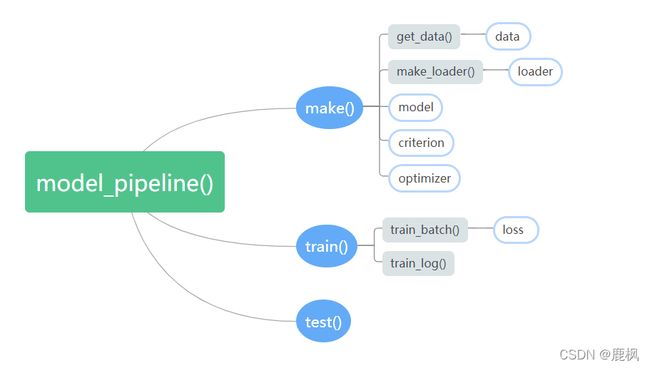
官方示例将运行一个模型所需的所有部分全部层层嵌套进了一个名为model_pipeline()的函数之中,最后只需将config输入其中即可。
结构理清之后剩下的代码很容易看懂,不多赘述。
>> step2:
初始化模型的一些参数
config = dict(
epochs=5,
classes=10,
kernels=[16, 32],
batch_size=128,
learning_rate=0.005,
dataset="MNIST",
architecture="CNN")
>> step3:
定义整个流程
def model_pipeline(hyperparameters):
# tell wandb to get started
with wandb.init(project="pytorch-demo", config=hyperparameters):
# access all HPs through wandb.config, so logging matches execution!
config = wandb.config
# make the model, data, and optimization problem
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# and use them to train the model
train(model, train_loader, criterion, optimizer, config)
# and test its final performance
test(model, test_loader)
return model
>> step4:
定义一些具体的函数
def make(config):
# Make the data
train, test = get_data(train=True), get_data(train=False)
train_loader = make_loader(train, batch_size=config.batch_size)
test_loader = make_loader(test, batch_size=config.batch_size)
# Make the model
model = ConvNet(config.kernels, config.classes).to(device)
# Make the loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
def get_data(slice=5, train=True):
full_dataset = torchvision.datasets.MNIST(root=".",
train=train,
transform=transforms.ToTensor(),
download=True)
# equiv to slicing with [::slice]
sub_dataset = torch.utils.data.Subset(
full_dataset, indices=range(0, len(full_dataset), slice))
return sub_dataset
def make_loader(dataset, batch_size):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True, num_workers=2)
return loader
# Conventional and convolutional neural network
class ConvNet(nn.Module):
def __init__(self, kernels, classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * kernels[-1], classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(model, loader, criterion, optimizer, config):
# Tell wandb to watch what the model gets up to: gradients, weights, and more!
wandb.watch(model, criterion, log="all", log_freq=10)
# Run training and track with wandb
total_batches = len(loader) * config.epochs
example_ct = 0 # number of examples seen
batch_ct = 0
for epoch in tqdm(range(config.epochs)):
for _, (images, labels) in enumerate(loader):
loss = train_batch(images, labels, model, optimizer, criterion)
example_ct += len(images)
batch_ct += 1
# Report metrics every 25th batch
if ((batch_ct + 1) % 25) == 0:
train_log(loss, example_ct, epoch)
def train_batch(images, labels, model, optimizer, criterion):
images, labels = images.to(device), labels.to(device)
# Forward pass ➡
outputs = model(images)
loss = criterion(outputs, labels)
# Backward pass ⬅
optimizer.zero_grad()
loss.backward()
# Step with optimizer
optimizer.step()
return loss
def train_log(loss, example_ct, epoch):
# Where the magic happens
wandb.log({"epoch": epoch, "loss": loss}, step=example_ct)
print(f"Loss after " + str(example_ct).zfill(5) + f" examples: {loss:.3f}")
def test(model, test_loader):
model.eval()
# Run the model on some test examples
with torch.no_grad():
correct, total = 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} " +
f"test images: {100 * correct / total}%")
wandb.log({"test_accuracy": correct / total})
# Save the model in the exchangeable ONNX format
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
>> step5:
运行下面的函数会显示所有的记录过的指标
# Build, train and analyze the model with the pipeline
model = model_pipeline(config)
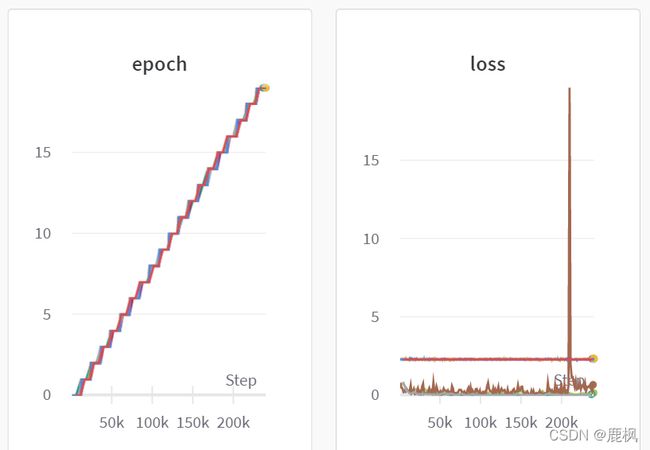
最后把上方代码放到一起即可正常运行
三、超参搜索
提示:官方示例这部分看着就像是另一个人写的一样,逻辑和之前的示例完全不一样,所以我这里就直接结合和上一个示例稍加修改实现超参搜索的功能。
替换
1.将上面代码中的config部分替换为:
import math
# 超参数搜索方法,可以选择:grid random bayes
sweep_config = {
'method': 'random'
}
metric = {
'name': 'test_accuracy',#这里是最后要追踪用作判断的指标
'goal': 'minimize'
}
sweep_config['metric'] = metric
# 参数范围
parameters_dict = {
'learning_rate': {
# a flat distribution between 0 and 0.1
'distribution': 'uniform',
'min': 0,
'max': 0.1
},
'batch_size': {
# integers between 32 and 256
# with evenly-distributed logarithms
'distribution': 'q_log_uniform',
'q': 1,
'min': math.log(32),
'max': math.log(256),
}
}
parameters_dict.update({#有些哦参数定死不需要范围写进去
'epochs': {
'value': 20},
'classes': {
'value': 10},
'kernels': {
'value': [16, 32]}
})
sweep_config['parameters'] = parameters_dict
2.将pipeline的前面的部分替换为下列代码
def model_pipeline(hyperparameters=None):# tell wandb to get started
with wandb.init(config=hyperparameters):
添加
在原先s2和s3中间添加代码:该部分用来将参数范围上传至服务器由服务器负责初始化参数,这也解释了为什么‘hyperparameters=None’
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")
最后
#Build, train and analyze the model with the pipeline
wandb.agent(sweep_id, model_pipeline, count=50)#这里的50代表初始化多少次,注意model_pipeline不要括号
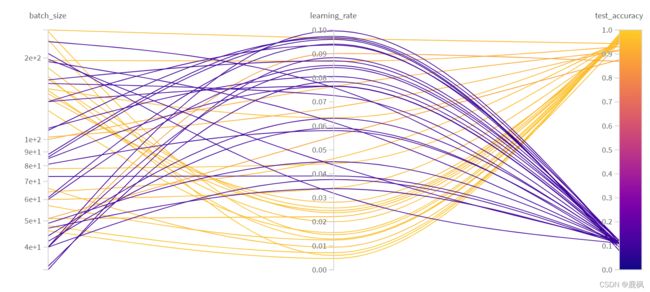
附录
提供两官方示例的截图:可视化和超参搜索