逻辑回归评分卡实战-toad
实战使用的数据集为天池-零基础入门金融风控-贷款违约预测的数据集。此处导入的数据集为已完成特征工程的数据集,特征工程思路可以参考:天池-金融风控训练营-task3-特征工程_nikita_zj的博客-CSDN博客天池-金融风控训练营-task3-特征工程https://blog.csdn.net/nikita_zj/article/details/122499348
toad官方文档可见:Welcome to toad’s documentation! — toad 0.1.0 documentation https://toad.readthedocs.io/en/latest/index.html
https://toad.readthedocs.io/en/latest/index.html
1. 数据导入
all_for_train = pd.read_csv('data/01_feature_all_for_train.csv', index_col = 0)
label_for_train = pd.read_csv('data/01_y_for_train.csv', index_col = 0)
all_for_train['isDefault'] = label_for_train.isDefault
data_test_a = pd.read_csv('data/01_test_for_predict.csv', index_col = 0)2. EDA
-toad的eda部分类似dataframe的describe,展示一些基本信息。
eda_df = toad.detect(all_for_train)
eda_df.head()
3. 特征选择
特征选择同样在<天池-金融风控训练营>-task-特征工程中有提及,天池-金融风控训练营-task3-特征工程_nikita_zj的博客-CSDN博客天池-金融风控训练营-task3-特征工程https://blog.csdn.net/nikita_zj/article/details/122499348
此处补充两个特征选择的思路:
3.1 iv值
可以基于iv值进行特征选择,iv值的计算可用toad包实现:
to_drop = ['postCode', 'title']
toad_quality = toad.quality(all_for_train.drop(to_drop, axis = 1), target='isDefault', iv_only=True)
toad_quality.head()
3.2 psi值
在比赛中可以考虑训练集和测试集上的psi值,剔除psi值较大(比如大于0.3)的特征。使用toad计算psi值的代码如下:
feat_lst = list(data_test_a.columns[1:])
psi_df = toad.metrics.PSI(all_for_train[feat_lst], data_test_a[feat_lst]).sort_values(0)
psi_df_ = psi_df.to_frame().reset_index().rename(columns = {'index':'feat',0:'psi'})
psi_df_.to_csv('data/psi_df.csv')
train_col = psi_df[psi_df<0.3].index.to_list()3.3 相关系数
toad可以通过对缺失值比例、iv值、相关系数阈值的设置,进行特征选择。相关系数阈值起作用的方式为,对于相关系数大于阈值的两个特征,只保留iv值较大的特征。
train_selected, dropped = toad.selection.select(all_for_train,target = 'isDefault', empty = 0.5, iv = 0.02, corr = 0.7, return_drop=True, exclude=to_drop)
print(dropped)
print(train_selected.shape)
{'empty': array([], dtype=float64), 'iv': array(['employmentLength', 'purpose', 'regionCode', 'delinquency_2years',
'openAcc', 'pubRec', 'pubRecBankruptcies', 'revolBal', 'totalAcc',
'initialListStatus', 'applicationType', 'earliesCreditLine',
'policyCode', 'n0', 'n1', 'n4', 'n5', 'n6', 'n7', 'n8', 'n10',
'n11', 'n12', 'n13'], dtype=object), 'corr': array(['grade_to_mean_n14', 'grade_to_mean_n11', 'grade_to_std_n11',
'grade', 'grade_target_mean', 'grade_to_std_n12',
'grade_to_mean_n12', 'grade_to_mean_n5', 'grade_to_std_n0',
'grade_to_mean_n0', 'grade_to_mean_n13', 'grade_to_std_n13',
'grade_to_mean_n8', 'grade_to_mean_n6', 'grade_to_std_n5',
'grade_to_std_n6', 'grade_to_std_n4', 'grade_to_std_n8',
'grade_to_std_n9', 'grade_to_std_n10', 'interestRate',
'grade_to_std_n2', 'grade_to_mean_n10', 'grade_to_std_n7',
'grade_to_std_n1', 'grade_to_mean_n4', 'grade_to_mean_n7',
'grade_to_std_n14', 'grade_to_mean_n1', 'grade_to_mean_n9', 'n9',
'grade_to_mean_n2', 'n3', 'loanAmnt', 'ficoRangeHigh',
'subGrade_target_mean'], dtype=object)}
(612742, 16)
4. 特征分箱并调整
toad默认的分箱方式为‘卡方分箱’。
# initialise
c = toad.transform.Combiner()
# 使用特征筛选后的数据进行训练:使用稳定的卡方分箱,规定每箱至少有5%数据, 空值将自动被归到最佳箱。
c.fit(train_selected.drop(to_drop, axis=1), y = 'isDefault', method = 'chi', min_samples = 0.05) #empty_separate = False
{'term': [5],
'installment': [161.42, 251.46, 301.11, 322.9, 451.73, 496.96,
602.3, 662.21, 793.85],
'subGrade': [3, 5, 8, 10, 13, 18],
'employmentTitle': [55.0, 203741.0],
'homeOwnership': [1, 2],
'annualIncome': [28038.0, 37104.87, 45505.0, 54003.0, 60626.0, 65940.0,
75500.0, 85002.0, 100671.0, 120024.0],
'verificationStatus': [1, 2],
'dti': [10.12, 14.85, 19.15, 21.45, 24.38, 26.81, 30.26],
'ficoRangeLow': [665.0, 675.0, 685.0, 700.0, 710.0, 725.0, 740.0],
'revolUtil': [19.5, 35.0, 42.6, 52.0, 62.0, 79.7],
'n2': [4.0, 6.0, 8.0],
'n14': [1.0, 2.0, 3.0, 4.0, 5.0],
'issueDateDT': [2496, 3227]}
分箱是否需要调整可以通过可视化每个箱体内的badrate直观感受:
from toad.plot import bin_plot
col = train_selected.columns[2]
bin_plot(c.transform(train_selected[[col,'isDefault']], labels=True), x=col, target='isDefault')
分箱的调整可以如下进行:
rule = {'issueDateDT':[2496, 3227]}
c.update(rule)
bin_plot(c.transform(train_selected[['issueDateDT','isDefault']], labels=True), x='issueDateDT', target='isDefault')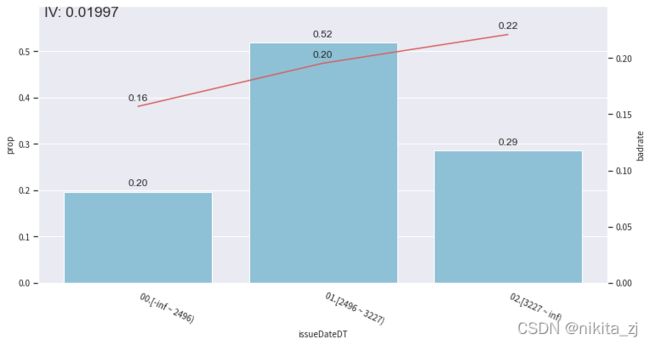
5. woe转换
基于前面分箱的结果,可以对训练集和测试集进行woe转换:
transer = toad.transform.WOETransformer()
# combiner.transform() & transer.fit_transform() 转化训练数据,并去掉target列
train_woe = transer.fit_transform(c.transform(train_selected), train_selected['isDefault'], exclude=to_drop+['isDefault'])
test_woe = transer.fit_transform(c.transform(train_selected[train_selected.columns]), train_selected['isDefault'], exclude=to_drop+['isDefault'])
test_woe.head()
6. 逻辑回归模型训练
逻辑回归模型训练之前,toad提供了一种简单的方式来实现逐步回归。
逐步回归的基本思想是将变量逐个引入模型,每引入一个解释变量后都要进行F检验,并对已经选入的解释变量逐个进行t检验,当原来引入的解释变量由于后面解释变量的引入变得不再显著时,则将其删除。以确保每次引入新的变量之前回归方程中只包含显著性变量。这是一个反复的过程,直到既没有显著的解释变量选入回归方程,也没有不显著的解释变量从回归方程中剔除为止。以保证最后所得到的解释变量集是最优、最简单的。更多详细介绍可见文末关于逐步回归的文章。
# 将woe转化后的数据做逐步回归
final_data = toad.selection.stepwise(train_woe,target = 'isDefault', estimator='ols', direction = 'both', criterion = 'aic', exclude = to_drop)
# 确定建模要用的变量
col = list(final_data.drop(to_drop+['isDefault'],axis=1).columns)toad.selection.stepwise参数相关
1.estimator:可选'ols','lr','lasso'(线性回归+l1范数),'ridge'(线性回归+l2范数)
2.criterion:可选'ks','aic'
极小化aic可以在提高模型预测能力的同时,尽可能控制模型复杂程度。
- aic:
其中l为似然函数。
- ols、lasso、ridge等方法用极大似然估计的方式求解和对应损失函数求解方式是等价的【对模型参数进行相应的假设即可】
*tip: 经验证,direction = ‘both’效果最好。estimator = ‘ols’以及criterion = ‘aic’运行速度快且结果对逻辑回归建模有较好的代表性*
ref:
机器学习算法系列(五)- Lasso回归算法(Lasso Regression Algorithm)_Saisimonzs的博客-CSDN博客_lasso回归
极大似然估计的直观推导和应用(OLS、Lasso、Ridge)_To_be_thinking的博客-CSDN博客_极大似然估计推导
可以简单看下这些变量在训练集和测试集上的psi值:
# 输出每个变量的psi
toad.metrics.PSI(final_data[col], test_woe[col])term 0.0 installment 0.0 subGrade 0.0 employmentTitle 0.0 homeOwnership 0.0 annualIncome 0.0 verificationStatus 0.0 dti 0.0 ficoRangeLow 0.0 revolUtil 0.0 n2 0.0 n14 0.0 issueDateDT 0.0 dtype: float64
调用sklearn包进行模型训练。
# 用逻辑回归建模
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(final_data[col], final_data['isDefault'])
# 预测训练集和测试集上的结果
pred_train = lr.predict_proba(final_data[col])[:,1]
pred_test = lr.predict_proba(test_woe[col])[:,1]
7.模型结果查看
from toad.metrics import KS, AUC
print('train KS',KS(pred_train, final_data['isDefault']))
print('train AUC',AUC(pred_train, final_data['isDefault']))train KS 0.3094248674341346 train AUC 0.7128617664579651
ks和auc可以通过scorecardpy进行可视化。
import scorecardpy as sc
# auc和ks值可视化输出
sc.perf_eva( final_data['isDefault'].values,pred_train)
psi验证分数稳定性
print(toad.metrics.PSI(pred_train,pred_test))0.0
8. 评分卡转换及结果查看
card = toad.ScoreCard(
combiner = c,
transer = transer,
#class_weight = 'balanced',
#C=0.1,
#base_score = 600,
#base_odds = 35 ,
#pdo = 60,
#rate = 2
)
card.fit(final_data[col], final_data['isDefault'])评分卡格式转化:
l_box_name = []
l_box_value = []
l_box_score = []
for key in card.export().keys():
for box_value in card.export().get(key):
l_box_name.append(key)
# print(box_value)
l_box_value.append(box_value)
# print(card.export().get(key).get(box_value))
l_box_score.append(card.export().get(key).get(box_value))
score_card = pd.DataFrame({'box_name':l_box_name,'box_value':l_box_value,'box_score':l_box_score})
score_card.head()
注意,toad在评分卡转换时,将逻辑回归模型的偏置项等分后加到各个特征的box_score中,计算公式如下:

9. 用评分卡进行预测
使用card进行预测时,要传入原始数据,而不要传入woe转化后的数据。
score_train = card.predict(train_selected)
score_test = card.predict(data_test_a)plt.hist(score_train, label = 'train', bins = 100)
plt.hist(score_test, label = 'test', bins = 100)
plt.legend()
plt.show()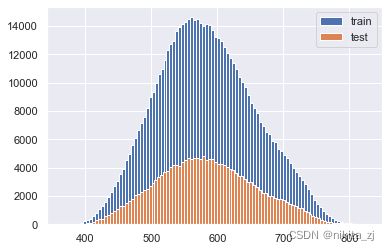
plt.hist(score_train[train_selected.isDefault == 0], label = 'good', bins = 100)
plt.hist(score_train[train_selected.isDefault == 1], label = 'bad', bins = 100)
plt.legend()
plt.show()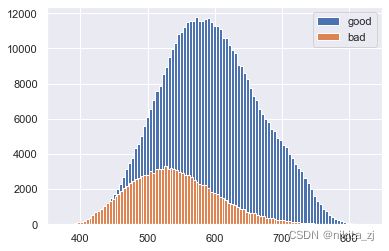
REF:
多元线性回归、逐步回归、逻辑回归的总结_大数据技术派-CSDN博客_逐步线性回归线性回归,前面用Python从底层一步一个脚印用两种方法实现了回归拟合。在这个高级语言层出不穷的年代,这样做显然不明智,所以我考虑用优秀的数据分析工具——R语言(不敢说最...https://blog.csdn.net/ddxygq/article/details/101351479?ops_request_misc=&request_id=&biz_id=102&utm_term=%E9%80%90%E6%AD%A5%E5%9B%9E%E5%BD%92&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-101351479.nonecase&spm=1018.2226.3001.4187