经典实战案例:用机器学习 KNN 算法实现手写数字识别

手写数字识别是KNN算法一个特别经典的实例,其数据源获取方式有两种,一种是来自MNIST数据集,另一种是从UCI欧文大学机器学习存储库中下载,本文基于后者讲解该例。
基本思想就是利用KNN算法推断出如下图一个32x32的二进制矩阵代表的数字是处于0-9之间哪一个数字。

数据集包括两部分,一部分是训练数据集,共有1934个数据;另一部分是测试数据集,共有946个数据。所有数据命名格式都是统一的,例如数字5的第56个样本——5_56.txt,这样做为了方便提取出样本的真实标签。

数据的格式也有两种,一种是像上图一样由0、1组成的文本文件;另一种则是手写数字图片,需要对图片做一些处理,转化成像上图一样的格式,下文皆有介绍。

收集数据:公开数据源
分析数据,构思如何处理数据
导入训练数据,转化为结构化的数据格式
计算距离(欧式距离)
导入测试数据,计算模型准确率
手写数字,实际应用模型
由于所有数据皆由0和1构成,所以不需要数据标准化和归一化这一步骤

在计算两个样本之间的距离时,每一个属性是一一对应的,所以这里将32x32的数字矩阵转化成1x1024数字矩阵,方便计算样本之间距离。
1#处理文本文件
2def img_deal(file):
3 #创建一个1*1024的一维零矩阵
4 the_matrix=np.zeros((1,1024))
5 fb=open(file)
6 for i in range(32):
7 #逐行读取
8 lineStr=fb.readline
9 for j in range(32):
10 #将32*32=1024个元素赋值给一维零矩阵
11 the_matrix[0,32*i+j]=int(lineStr[j])
12 return the_matrix
numpy有一个tile方法,可以将一个一维矩阵横向复制若干次,纵向复制若干次,所以将一个测试数据经过tile方法处理后再减去训练数据,得到新矩阵后,再将该矩阵中每一条数据(横向)平方加和并开根号后即可得到测试数据与每一条训练数据之间的距离。
下一步将所有距离升序排列,取到前K个,并在这个范围里,每个数字类别的个数,并返回出现次数较多那个数字类别的标签。
1def classify(test_data,train_data,label,k):
2 Size=train_data.shape[0]
3 #将测试数据每一行复制Size次减去训练数据,横向复制Size次,纵向复制1次
4 the_matrix=np.tile(test_data,(Size,1)) - train_data
5 #将相减得到的结果平方
6 sq_the_matrix=the_matrix ** 2
7 #平方加和,axis=1 代表横向
8 all_the_matrix=sq_the_matrix.sum(axis=1)
9 #结果开根号得到最终距离
10 distance=all_the_matrix ** 0.5
11 #将距离由小到大排序,给出结果为索引
12 sort_distance=distance.argsort
13 dis_Dict={}
14 #取到前k个
15 for i in range(k):
16 #获取前K个标签
17 the_label=label[sort_distance[i]]
18 #将标签的key和value传入字典
19 dis_Dict[the_label]=dis_Dict.get(the_label,0)+1
20 #将字典按value值的大小排序,由大到小,即在K范围内,筛选出现次数最多几个标签
21 sort_Count=sorted(dis_Dict.items, key=operator.itemgetter(1), reverse=True)
22 #返回出现次数最多的标签
23 return sort_Count[0][0]
首先要对训练数据集处理,listdir方法是返回一个文件夹下所有的文件,随后生成一个行数为文件个数,列数为1024的训练数据矩阵,并且将训练数据集中每条数据的真实标签切割提取存入至labels列表中,即计算距离classify函数中传入的label。
1labels=
2#listdir方法是返回一个文件夹中包含的文件
3 train_data=listdir('trainingDigits')
4 #获取该文件夹中文件的个数
5 m_train=len(train_data)
6 #生成一个列数为train_matrix,行为1024的零矩阵
7 train_matrix=np.zeros((m_train,1024))
8 for i in range(m_train):
9 file_name_str=train_data[i]
10 file_str=file_name_str.split('.')[0]
11 #切割出训练集中每个数据的真实标签
12 file_num=int(file_str.split('_')[0])
13 labels.append(file_num)
14 #将所有训练数据集中的数据都传入到train_matrix中
15 train_matrix[i,:]=img_deal('trainingDigits/%s'%file_name_str)
然后对测试训练数据集做与上述一样的处理,并将测试数据矩阵TestClassify、训练数据矩阵train_matrix、训练数据真实标签labels、K共4个参数传入计算距离classify函数中,最后计算出模型准确率并输出预测错误的数据。
1error=
2 test_matrix=listdir('testDigits')
3 correct=0.0
4 m_test=len(test_matrix)
5 for i in range(m_test):
6 file_name_str=test_matrix[i]
7 file_str=file_name_str.split('.')[0]
8 #测试数据集每个数据的真实结果
9 file_num=int(file_str.split('_')[0])
10 TestClassify=img_deal('testDigits/%s'%file_name_str)
11 classify_result=classify(TestClassify,train_matrix,labels,3)
12 print('预测结果:%s 真实结果:%s'%(classify_result,file_num))
13 if classify_result==file_num:
14 correct +=1.0
15 else:
16 error.append((file_name_str,classify_result))
17 print("正确率:{:.2f}%".format(correct / float(m_test) * 100))
18 print(error)
19 print(len(error))
代码运行部分截图如下
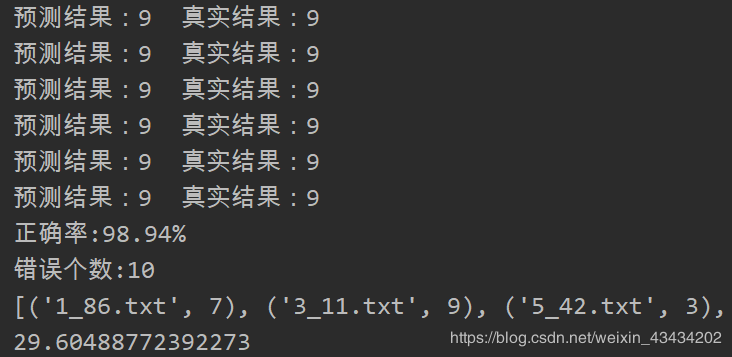
当K=3时,准确率达到了98.94%,对于这个模型而言,准确率是十分可观的,但运行效率却比较低,接近30秒的运行时间。因为每个测试数据都要与近2000个训练数据进行距离计算,而每次计算又包含1024个维度浮点运算,高次数多维度的计算是导致模型运行效率低的主要原因。
下图是K值与模型准确率的关系变化图,K=3时,模型准确率达到峰值,随着K增大,准确率越来越小,所以这份数据的噪声还是比较小的。

建模完成了,模型的准确率也不错,为何自己手写的数字测试一下呢?所以偶就手动写了几个数字.
正常拍出的图片是RGB彩色图片,并且像素也各不相同,所以需要对图片做两项处理:转化成黑白图片、将像素转化为32x32,这样才符合我们上文算法的要求;对于像素点,数值一般位于0-255,255代表白、0代表黑,但因为手写数字像素点颜色并不规范,所以我们设置一个阈值用以判断黑白之分。
图片转文本代码如下:
1def pic_txt:
2 for i in range(0,10):
3 img=Image.open('.\handwritten\%s.png'%i)
4 #将图片像素更改为32X32
5 img=img.resize((32,32))
6 #将彩色图片变为黑白图片
7 img=img.convert('L')
8 #保存
9 path='.\handwritten\%s_new.jpg'%i
10 img.save(path)
11 for i in range(0,10):
12 fb=open('.\hand_written\%s_handwritten.txt'%i,'w')
13 new_img=Image.open('.\handwritten\%s_new.jpg'%i)
14 #读取图片的宽和高
15 width,height=new_img.size
16 for i in range(height):
17 for j in range(width):
18 # 获取像素点
19 color=new_img.getpixel((j, i))
20 #像素点较高的为图片中的白色
21 if color>170:
22 fb.write('0')
23 else:
24 fb.write('1')
25 fb.write('
')
26 fb.close
整体代码运行截图如下:

正确率为70%,毕竟测试数据很少,10个数字中4、7、8三个数字预测错误,还算可观;由于光线问题,有几个数字左下角会有一些黑影,也会对测试结果产生一定的影响,若避免类似情况,并且多增加一些测试数据,正确率定会得到提升的。