PyTorch Geometric(PyG)+Cuda+Pytorch安装与使用
问题
主要是各个版本之间的对应问题,这里以cuda11.3,Pytorch11.2进行说明
安装Cuda
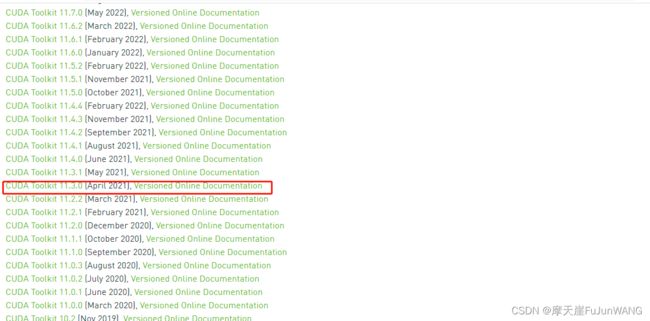
地址:https://developer.nvidia.com/cuda-toolkit-archive
选择11.3.0下载安装。
安装python 3.7
conda install python=3.7
安装Pytorch
网址:https://pytorch.org/get-started/locally/
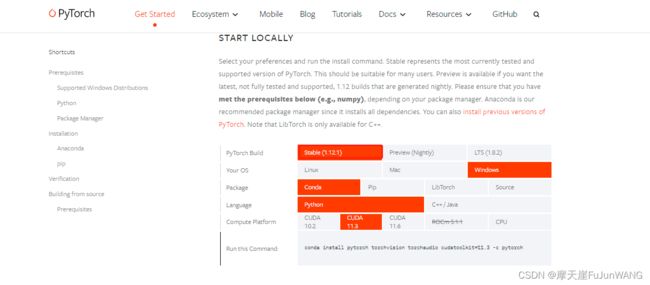
一定要选11.3
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
安装PyTorch Geometric(PyG)
确保以上都没问题后。
进入网址:
https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html
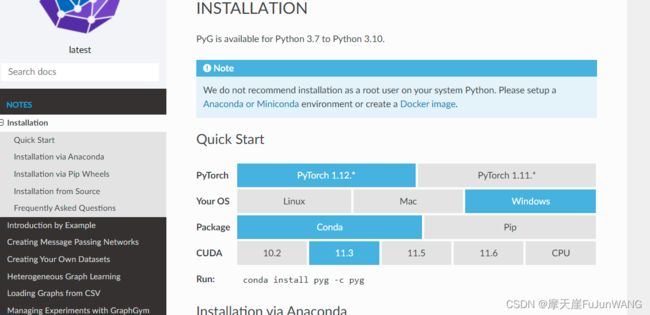
运行:
conda install pyg -c pyg
一定保证版本号的对应。
测试PyG
import os.path as osp
import torch
import torch.nn.functional as F
from torch.nn import Sequential as Seq, Linear as Lin, ReLU
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
from torch_geometric.nn import GINConv, TopKPooling
from torch_geometric.nn import global_add_pool
from torch_scatter import scatter_mean
class HandleNodeAttention(object):
def __call__(self, data):
data.attn = torch.softmax(data.x[:, 0], dim=0)
data.x = data.x[:, 1:]
return data
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', 'COLORS-3')
dataset = TUDataset(path, 'COLORS-3', use_node_attr=True,
transform=HandleNodeAttention())
train_loader = DataLoader(dataset[:500], batch_size=60, shuffle=True)
val_loader = DataLoader(dataset[500:3000], batch_size=60)
test_loader = DataLoader(dataset[3000:], batch_size=60)
class Net(torch.nn.Module):
def __init__(self, in_channels):
super(Net, self).__init__()
self.conv1 = GINConv(Seq(Lin(in_channels, 64), ReLU(), Lin(64, 64)))
self.pool1 = TopKPooling(in_channels, min_score=0.05)
self.conv2 = GINConv(Seq(Lin(64, 64), ReLU(), Lin(64, 64)))
self.lin = torch.nn.Linear(64, 1)
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch
out = F.relu(self.conv1(x, edge_index))
out, edge_index, _, batch, perm, score = self.pool1(
out, edge_index, None, batch, attn=x)
ratio = out.size(0) / x.size(0)
out = F.relu(self.conv2(out, edge_index))
out = global_add_pool(out, batch)
out = self.lin(out).view(-1)
attn_loss = F.kl_div(torch.log(score + 1e-14), data.attn[perm],
reduction='none')
attn_loss = scatter_mean(attn_loss, batch)
return out, attn_loss, ratio
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net(dataset.num_features).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Initialize to optimal attention weights:
# model.pool1.weight.data = torch.tensor([0., 1., 0., 0.]).view(1,4).to(device)
def train(epoch):
model.train()
total_loss = 0
for data in train_loader:
data = data.to(device)
optimizer.zero_grad()
out, attn_loss, _ = model(data)
loss = ((out - data.y).pow(2) + 100 * attn_loss).mean()
loss.backward()
total_loss += loss.item() * data.num_graphs
optimizer.step()
return total_loss / len(train_loader.dataset)
def test(loader):
model.eval()
corrects, total_ratio = [], 0
for data in loader:
data = data.to(device)
out, _, ratio = model(data)
pred = out.round().to(torch.long)
corrects.append(pred.eq(data.y.to(torch.long)))
total_ratio += ratio
return torch.cat(corrects, dim=0), total_ratio / len(loader)
for epoch in range(1, 301):
loss = train(epoch)
train_correct, train_ratio = test(train_loader)
val_correct, val_ratio = test(val_loader)
test_correct, test_ratio = test(test_loader)
train_acc = train_correct.sum().item() / train_correct.size(0)
val_acc = val_correct.sum().item() / val_correct.size(0)
test_acc1 = test_correct[:2500].sum().item() / 2500
test_acc2 = test_correct[2500:5000].sum().item() / 2500
test_acc3 = test_correct[5000:].sum().item() / 2500
print(('Epoch: {:03d}, Loss: {:.4f}, Train: {:.3f}, Val: {:.3f}, '
'Test Orig: {:.3f}, Test Large: {:.3f}, Test LargeC: {:.3f}, '
'Train/Val/Test Ratio={:.3f}/{:.3f}/{:.3f}').format(
epoch, loss, train_acc, val_acc, test_acc1, test_acc2,
test_acc3, train_ratio, val_ratio, test_ratio))