ICLR2021 | USING LATENT SPACE REGRESSION TO ANALYZE 阅读笔记(翻译)
USING LATENT SPACE REGRESSION TO ANALYZE AND LEVERAGE COMPOSITIONALITY IN GANS
作者:Lucy Chai, Jonas Wulff & Phillip Isola
单位:MIT CSAIL, Cambridge, MA 02139, USA
邮箱:{lrchai,wulff,phillipi}@mit.edu
会议:ICLR 2021
项目地址:https://chail.github.io/latent-composition/
ABSTRACT
在这项工作中,我们以调查在潜空间的回归作为探针,来了解GAN中的组成性质。我们发现,结合回归器和预先训练的生成器提供了一个强的图像先验,允许我们可以以随机图像部分的拼接为输入来合成图像,并且同时保持了全局一致性。为了比较不同生成器的组成属性,我们测量了非真实输入的重建图像与重生成样本的图像质量之间的权衡(trade-offs)。我们发现,与直接编辑相比,回归方法可以在潜空间中对图像的个别部分进行更局部化的编辑,我们进行了实验来量化这种独立效果。我们的方法与编辑的语义无关,在训练期间不需要标签或预定义的概念。除了图像合成,我们的方法还扩展到许多相关的应用,如图像修复或example-based的图像编辑,我们在几个GANs和数据集上演示了这些应用,因为它只使用一个向前传递,所以它可以实时操作。我们的项目页面:https://chail.github.io/latent-composition/。
1 INTRODUCTION
在这里,我们使用潜回归器来探测预训练GAN的潜空间,从而揭示GAN是如何以无监督的方式来了解世界。
例如,给定一个教堂图像,是否有可能将一棵前景树换成另一棵?如果只考虑建筑的部分,那么缺失的部分能否被逼真的填补呢?为了实现这些修改,生成器必须是可组合的,即理解对象的离散和分隔表示。**我们表明,未经任何额外干预的预训练生成器已经在其潜代码中表示了这些组合属性。**此外,这些属性可以使用回归网络进行操作,该网络可以预测给定图像的潜代码。这个图像的像素为我们提供了一个直观的界面来控制和修改潜在代码。给定修改后的潜代码,网络应用从数据集学习到的图像先验,确保输出始终是一个连贯的场景,而不管输入是否不一致(图1)。

我们的方法很简单——给定一个固定的预训练生成器,我们训练一个回归网络来预测输入图像中的潜代码,同时添加一个掩码来学习处理缺失的像素。为了研究GAN生成全局一致场景的能力,我们给回归网络一个我们想要场景的粗糙的、不连贯的模板,然后使用这两个网络将其转换成真实的图像。即使我们的回归器从来没有在这些不切实际的模板上训练过,但它可以将给定的图像投射到潜空间中的合理部分,然后生成器将其映射到图像流形上。这种方法不需要标签或属性群集;我们所需要的只是一个样例,其可以大致说明我们想要生成的图像的样子。它只需要前向传递回归器和生成器,因此获得输出图像的延迟较低,不像迭代优化方法需要一分钟以上的时间来重建图像。
我们使用回归器来研究 预训练的GAN 在不同数据集上的组成能力。使用由不同图像部分组成的输入图像(“拼贴”),我们利用生成器将这些不现实的内容重新组合成连贯的图像。这需要同时解决三个任务——混合、对齐和修补。然后我们研究了GAN独立改变给定图像局部的能力。总而言之,我们的贡献是:
- 我们提出了一个潜回归模型,即使在图像不完整和缺少像素的情况下,也可以学习去执行图像重建,并表明回归器和生成器的组合形成了一个强的图像先验。
- 使用学习好的回归器,我们表明生成器的表征已经在潜在代码中具有组成性,而不必去探索中间层激活值。
- 不需要使用标签或测试时间优化,因此我们可以基于单个需要修改的示例编辑图像并实时重建。
- 我们使用回归器来探测场景的哪些部分可以独立变化,并研究使用编码器的图像混合和在潜空间内插值之间的区别。
- 相同的回归器设置可以用于各种其他图像编辑应用,如多模态编辑、场景补充或数据集重新平衡。
2 RELATED WORK
Image Inversion. 虽然这种回归器方式的重构精度低于基于优化的技术,但其较低的延迟允许我们以一种计算效率高的方式研究学到的先验,并使用这些先验实时编辑图像。
Composition in Image Domains.
Image Editing.
3 METHOD
3.1 LATENT CODE RECOVERY IN GANS
图像反演的目标是找到GAN G最能恢复所需目标图像x的潜码z: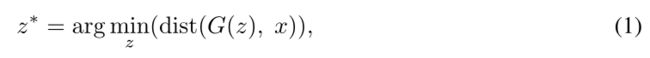
使用图像距离的度量,如像素级的L1误差或基于深度特征的度量。这个目标可以用L-BFGS (Liu & Nocedal, 1989)或其他优化器迭代求解。然而,迭代优化很慢——它需要大量的迭代才能收敛,容易出现局部极小值,并且必须对每个目标图像x单独执行。
另一种恢复潜码z的方法是训练神经网络从一个给定的图像x直接预测它。在这种情况下,恢复的潜码仅仅是通过前馈一个训练有素的回归网络得到的结果, z ∗ = E ( x ) z^∗= E(x) z∗=E(x),E可以用于任何 x ∈ X x∈X x∈X。为了训练回归网络(或编码器)E,我们使用潜编码器损失:
![]()
我们从潜分布中随机抽取z,通过预先训练的生成器G得到目标图像x = G(z)。在目标图像x和恢复的图像G(E(x))之间,我们使用均方误差损失来引导重构,使用感知损失 L p L_p Lp(Zhang et al., 2018)来恢复细节。在原始潜码z和恢复的潜码E(x)之间,我们使用潜恢复损失 L z L_z Lz。根据GAN的输入归一化,我们使用均方误差或余弦相似度的变体来进行潜恢复。
在本文的生成器被冻结,我们只优化编码器E的权重。当使用ProGAN(Karras et al ., 2017),我们训练编码器网络直接转化潜码z。对于StyleGAN(Karras et al ., 2019 b),我们编码去扩展 W + W^+ W+潜空间(Abdal et al ., 2019)。经过训练后,潜回归器的输出产生一个潜码,这样重建的图像在感知上看起来与目标图像相似。
3.2 LEARNING WITH MISSING DATA

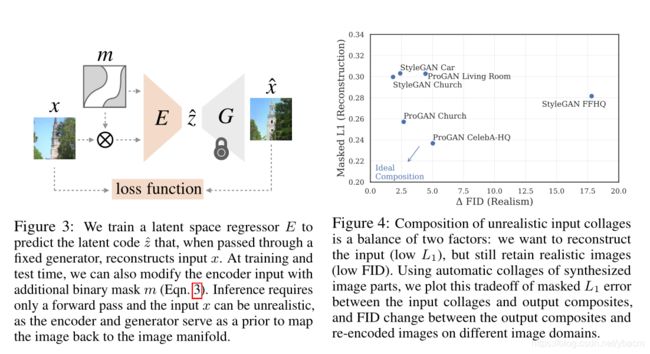
当研究输入图像局部化的效果时,我们可能希望明确地将一些图像区域视为“未知”,要么创建缓冲区以避免不同粘贴部分之间的接缝(either to create buffer zones to avoid seams between different pasted parts),要么明确地让图像事先填充未知区域(例如填充黑色)。在使用公式1的优化方法中,这可以通过仅对已知像素进行优化来处理。然而,回归器网络不能地处理这个问题——它不能区分未知像素和已知像素,并将尝试拟合未知像素的值。这可以通过对回归网络进行一个小的修改来减轻,需要指示哪些像素是已知的而哪些是未知的输入(图3):
![]()
编码器不采用图像x作为输入,而是采用掩码图像 x m x_m xm和掩码m,其中 x m = x ⊗ m x_m= x⊗m xm=x⊗m,m是一个额外的输入通道。直观上,这种掩蔽操作类似于像素上的“dropout”(Srivastava et al., 2014)——它鼓励编码器学习一种灵活的方法来恢复潜码,用此潜码生成器仍可重构图像。因此,如果只给出部分图像作为输入,编码器将从已知像素映射到与图像其余部分语义一致的潜码。这可以使得生成器重新生成一个图像,它既是来源于先验知识,又保持了与观察区域的一致性。
为了在训练中获得掩码图像,我们将一小块随机均匀噪声u, 使用双线性插值来上采样噪声从而获得完整的分辨率,并掩盖了上采样噪声(小于采样阈值t∼u(0, 1))的所有像素来模拟任意形状掩码的界限。然而,在测试时,掩模的确切形式并不重要——掩模只是指示生成器应该在何处进行重建或修复,而不区分输入的不同图像部分。我们将在附录A.1.1和A.2.3中提供更多细节。
回归器和生成器加强了全局一致性:当我们模糊或修改部分输入时,生成器将创建总体上然一致的输出。通过屏蔽图像的任意部分(公式3),我们允许GAN想象缺失像素的真实完成,这可以根据给定的上下文进行变化(图2)。这表明回归器内在地学习无监督对象表示,允许它仅从部分提示完成对象的预测,即使生成器和回归器在训练期间从未提供结构化的概念标签。
3.3 IMAGE COMPOSITION USING LATENT REGRESSION
回归器E与生成器G将一个输入图像 x i n p u t x_{input} xinput利用先验知识来映射到生成图像 X X X的流形,即使 x i n p u t ∉ X x_{input}\notin X xinput∈/X。我们利用这一点来研究潜码的组成属性。我们提取部分图像(由G生成或从真实图像中提取),并将它们组合成拼贴图像 x c l g x_{clg} xclg。这个提取过程不需要精确,可以有明显的接缝和缺失像素。同时,虽然 x c l g x_{clg} xclg通常不现实,但我们的编码器可以意识到这些缺失的像素,并可以正确地处理它们,如第3.2节所述。因此,我们可以使用E和G来混合接缝,并产生一个真实的合成输出。为了创建 x c l g x_{clg} xclg,我们采样基础图像 x i x_i xi与掩码 m a s k i mask_i maski,并将它们结合起来;一旦我们形成了拼贴图像 x c l g x_{clg} xclg,我们通过回归器和生成器进行重新投射,以获得复合图像 x r e c x_{rec} xrec:
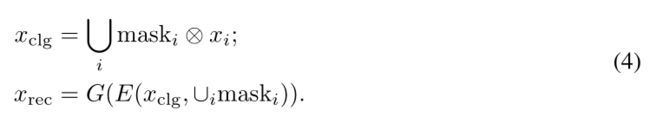
请注意,公式4中用于提取单个图像部分的每个掩码对编码器都不可用,只有联合版的才可用。此外,回归器仅针对潜恢复目标进行训练(公式3),在训练过程中从未见过拼贴图像。为了自动化提取mask图像的过程,我们使用预先训练的分割网络(Xiao et al., 2018)和输出类中的样本(参见附录a .1.2)。然而,掩码回归器是不知道如何提取图像部分;我们还实验了显著性网络(Liu et al., 2018)、近似矩形和用户自定义掩码(参见附录a .2.1和a .2.4)。

4 EXPERIMENTS
使用预先训练的Progressive GAN (Karras et al., 2017)和StyleGAN2 (Karras et al., 2019b)生成器,我们对CelebA-HQ和FFHQ人脸以及LSUN汽车、教堂、客厅和马进行实验,研究GAN从数据中学习的组成属性。
4.1 IMAGE COMPOSITION FROM APPROXIMATE COLLAGES
为了衡量网络维持原输入以及合成图像真实性的权衡能力,我们使用掩码 L 1 L_1 L1距离来当作重构的度量(越低越好)

和超过50k样本的FID评分(Heusel et al., 2017)作为图像质量的度量(越低越好)(图4)。
4.2 COMPARING COMPOSITIONAL PROPERTIES ACROSS ARCHITECTURES
到底是预训练的GAN作用大还是回归网络作用更大呢?在这里,我们研究了许多不同的图像重建方法,涉及三个主要类别:无预训练GAN的自动编码器架构,无编码器的基于优化的GAN潜码恢复方法,以及与预训练GAN成对的基于编码器的方法。由于样本量较小,我们在这里使用密度作为真实感的衡量标准(越高越好),它衡量的是与真实图像流形的接近程度(Naeem等人,2020),并与L1重构(Eqn. 5)进行比较;一个完美的复合图像具有高密度和低L1。我们在表4-5中报告了其他指标。

4.3 HOW DOES COMPOSITION DIFFER FROM INTERPOLATION?

4.4 USING REGRESSION TO INVESTIGATE INDEPENDENCE OF IMAGE COMPONENTS


5 CONCLUSION
*个人总结:*整体方法并不难,就是训练编码器来回复潜编码(包含缺失像素的版本),然后对四个方面进行了讨论。有一点值得注意的是,这个方法生成的结果并不能完全维持原输入,因为它也必须考虑到图像的真实性,所以对这两个方面进行了权衡。