阿里云(轻量级Ubuntu 16.04 )服务器搭建Hadoop伪分布式集群及实现pi值的计算
环境:在ubuntu16.04
jdk1.8.0_171
hadoop 2.8.4
一.租用服务器
https://www.aliyun.com/?spm=5176.2020520001.aliyun_topbar.1.69864bd3NRoSf9
二.安装jdk
主要有两种方式:
(1)通过ppa(源)方式安装(建议选择第一种,简单)
(2)通过下载官网安装包
1.添加ppa (博主用的最高权限root,所以不需要sudo)
add-apt-repository ppa:webupd8team/java
apt-get update
apt-get install oracle-java8-installer
按照提示,一步一步安装即可,期间:同意一次默认条款。
这里遇到
Ubuntu无法找到add-apt-repository的问题
按照安装提示,apt-get install software-properties-common一下就可以。
2.安装完成 java -version 出现版本号,即安装成功
![]()
三.安装hadoop
hadoop各个版本安装包下载方式参考:
(参考来源:https://blog.csdn.net/u011138533/article/details/53405198)
http://mirror.bit.edu.cn/apache/hadoop/common/
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
1.选择.tar.gz结尾的安装包(非src)获取下载连接wget 连接
2.解压缩到新创建的opt文件夹子,按步骤提示,等待安装完成
sudo tar zxvf hadoop-2.8.4.tar.gz -C /opt
3.创建软链接
ln -snf /opt/hadoop-2.8.4 /opt/hadoop
4.配置环境变量
vi /etc/profile
写入首行
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile 使生效
5. hadoop version
测试是否安装成功

三.配置伪分布式
1.cd 下面这个目录,更改五个配置文件
hadoop-env.sh、core-site.xml、hdfs-site.xml、hdfs-site.xml 、mapred-site.xml
参考来源:https://www.cnblogs.com/zhangyinhua/p/7647686.html#_lab2_2_0
(写的很清楚,文中许多内容参考这位博主,给予感谢!

注意事项:
1.需要注意的是:coresite.xml和yarnsite.xml里面的主机名:使用自己的主机名localhost)
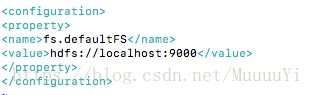 和
和
2.hadoop-env.sh:这两个位置需务必按照自身安装情况书写正确。
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
(java的实际安装位置:通过whereis java获取软连接,一层一层找到实际位置)
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
2.启动集群
(多种启动方式参考来源:https://blog.csdn.net/u011528448/article/details/50962223)
start-all.sh
3.jps测试节点主namenode、从节点datanode、以及备用主节点secondarynamenode 等是否正常启用
如下图所示,即配置成功

4.查看节点信息
hdfs dfsadmin -report

5.hdfs常用的几个命令

查看文件夹:如图

6.计算pi值
yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar pi 4 100
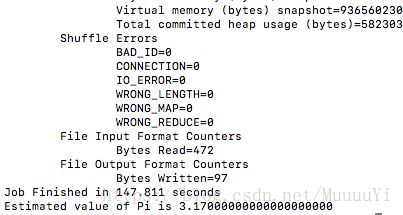
jar包计算原理:

其中:
![]()
结果是:3.170000....,精度可根据运算次数的增加而增加
四.遇到的几个问题及解决办法
1.hadoop命令不可用
解决办法:重新配置环境变量vi /etc/profile
2.hadoop-env.sh里面的两个export写错
通过whereis java找到真实安装路径,更改后记得source生效。
(参考来源:https://blog.csdn.net/xbw12138/article/details/68298836)
3.伪分布式,格式化失败(解决这个耗时最久)
错误提示:

解决办法:
vim /etc/hosts
加上:127.0.0.1 主机名(阿里云服务名)
如图:

4.jobtracker启动失败
原因:忽略了版本问题,这里可以无视。。 。
![]()