解压jdk,配置ssh,安装hadoop
目录
伪分布式安装
安装jdk
配置SSH
hadoop下载和安装
hadoop的环境配置
修改配置文件/etc/hosts
设置环境变量~/.bashrc
修改hadoop配置文件
hadoop-env.sh
core-site.xml
yarn-site.xml
mapred-site.xml
hdfs-site.xml
修改系统/etc/profile文件
创建并格式化系统文件
启动hadoop
查看页面
hadoop安装、运行方式
单机模式——不需要配置,只是单独的java进程,用于测试。
伪分布式模式——只在一台主机上运行Hadoop,主节点和从节点都在一个节点上。
集群模式(完全分布式)——安装到多个节点,节点可以是不同的电脑或虚拟机的系统,一个主节点master,多个从节点slave。
伪分布式安装
步骤:
-
下载VirtualBox软件
-
创建虚拟机
-
安装linux系统(Ubuntu版本)
-
安装jdk,hadoop使用java的编写程序,使用jdk编译
-
安装ssh(安全外壳协议),为了让从节点的各台主机密码联通
-
安装hadoop
安装jdk
检测Ubuntu里有没有jdk
终端输入:javac
应该是没有的,需要下载,安装,配置,重新加载,验证
-
windows下载jdk,Java Downloads | Oracle
官网下载需要注册账户,并到邮箱确认邮件,然后返回下载(下载1.8版本原因:我的教材是8u181版,维护时间长久)
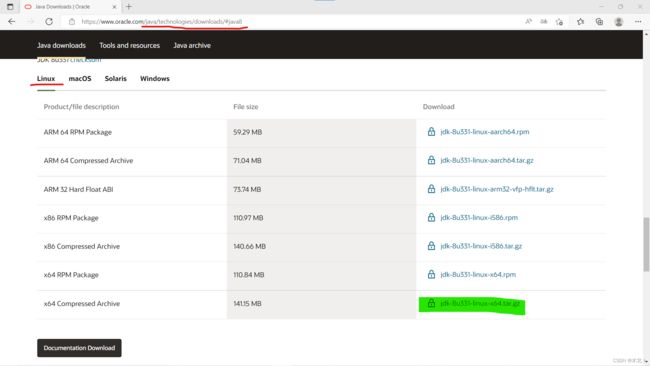
-
下载了jdk---.tar.gz安装包,放到共享文件夹
-
复制到主目录的文件夹,该文件夹路径下打开终端
-
解压(安装),产生jdk文件夹
tar -zxvf jdk---.tar.gz
-
设置环境变量,打开配置文件(vi和gedit的区别?一个是编辑器,一个是记事本,两个都可以,用法不同,新手用gedit)
(gedit /etc/profile这条只能访问、查看;用下面的命令,管理员可修改(输入密码时看不见,输入后回车))
sudo gedit /etc/profile
-
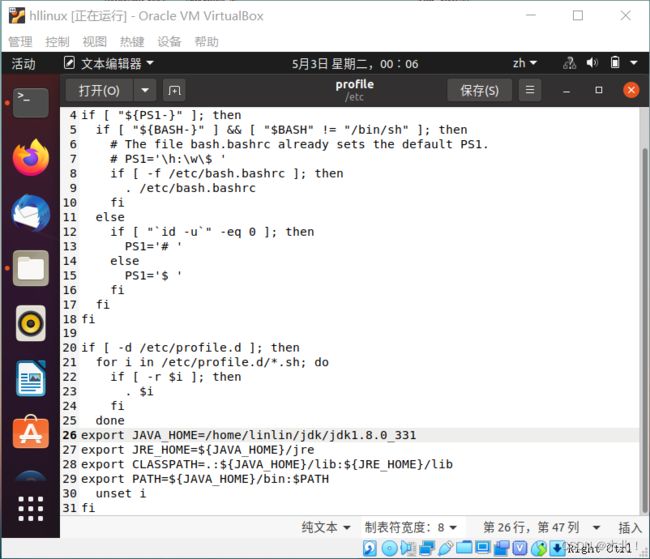
进入编辑界面,特定位置输入信息,保存关闭文件
(vi编辑界面命令:I:编辑状态;delete:修改状态;esc:退出编辑状态;:wq:保存退出;命令完回车)
export JAVA_HOME=/home/linlin/jdk/jdk---
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
-
重新加载配置文件,(命令提示符会变颜色)
source /etc/profile
-
验证jdk
java -version
javac

-
出现版本信息,安装成功。
配置SSH
通过SSH对所有传输的数据加密,利用SSH可以防止远程管理系统时出现信息外泄的问题。
启动hadoop,NameNode必须与DataNode连接,并且主节点管理从节点,可以设置无密码登录(使用SSH Key来验证身份)
SSH Key 会产生密钥(私钥id_rsa和公钥id_rsa.pub),主节点将公钥给从节点,从节点匹配(authorized_keys)与主节点传递的请求信息,产生字符串并用公钥加密给主节点,主节点用私钥解密,解密后的字符串再发送给从节点,对比正确后即可实现数据传输且加密。
-
打开终端,输入命令(保证网络,便可以在Ubuntu系统上下载),输入y安装
sudo apt-get install ssh
-
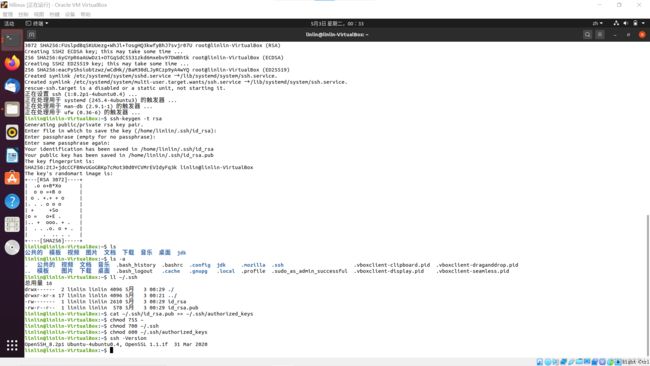
产生SSH Key(密钥),输入命令,产生私钥(id_rsa)和公钥(id_rsa.pub),(这个命令会停顿三下,按回车)
ssh-keygen -t rsa
-
把公钥放到许可证(authorized_keys)中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
-
更改权限
chmod 755 ~
chmod 700 ~/.ssh
chmod 700 ~/.ssh/authorized_keys
-
验证ssh安装成功
ssh -Version
-
验证本机无密码登录,本机名就是@后面的,也可以hostname查看,输入yes
ssh linlin-VirtualBox
-
退出ssh连接
exit

在伪分布式中ssh作用不明显,但是在千万节点下的hadoop集群就很会明显的方便。
hadoop下载和安装
终于可以安装小象了~
安装伪分布式hadoop,将hadoop看做是一个节点的集群。节点既是master,也是slave;既是namenode,也是datanode;既是jobtracker,也是tasktracker。
-
下载官网:Apache Hadoop
-
下载了hadoop---.tar.gz安装包。复制到共享文件夹。
-
移到Ubuntu系统的主目录,打开终端
-
解压安装,产生hadoop文件夹,安装好了~ 开心吧~
tar -zxvf hadoop---.tar.gz

-
配置(下面的大模块内容都是hadoop环境配置,提起1000%的精神,因为一错皆错)
hadoop的环境配置
修改配置文件
-
查看本机ip地址,有异常使用提示语句下载安装网络工具
ifconfig
sudo apt install net-tools
-
查看本机主机名
hostname
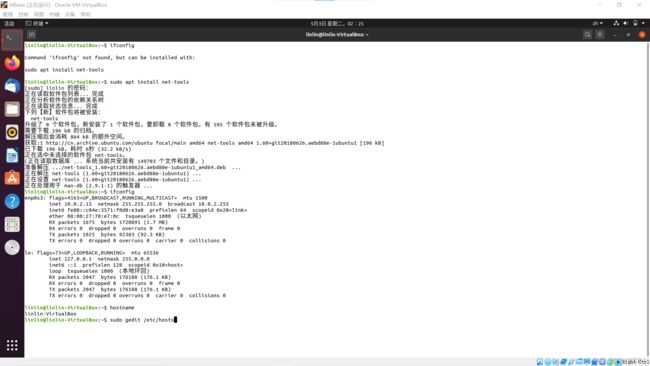
-
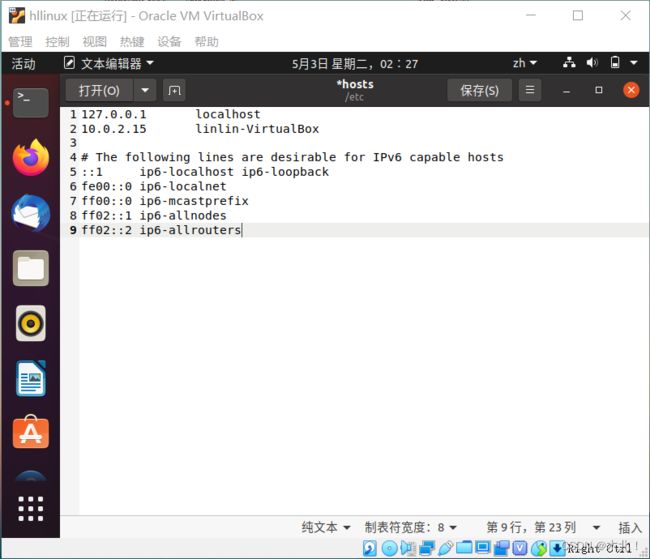
写入配置文件/etc/hosts,打开文件输入命令,修改ip地址,保存关闭
sudo gedit /etc/hosts
设置环境变量
-
设置环境变量,永久设置(需要修改~/.bashre),打开文件
sudo gedit ~/.bashrc
-
进入编辑界面,输入信息,保存关闭
(其中的信息:jdk安装路径;hadoop安装路径;路径X2;其他环境变量X4(设为$HADOOP_HOME);链接库设置X3)
export JAVA_HOME=/home/linlin/jdk/jdk---
export HADOOP_HOME=/home/linlin/hadoop---
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMOM_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH

-
重新加载配置文件
source ~/.bashrc
-
验证配置
hadoop version
-
出现版本信息,配置成功
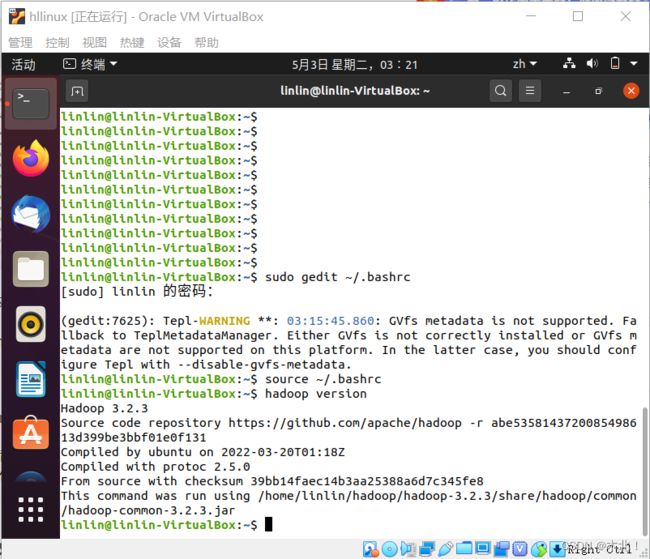
出错->解决->满足
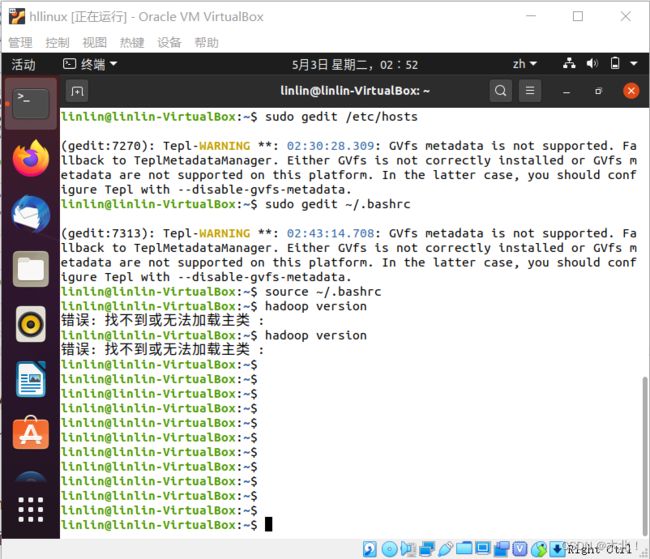
运行hadoop version命令后出现:错误: 找不到或无法加载主类 :
原因:仔细检查~/.bashrc文件(图片——当时的配置信息),是/bashrc配置时有多余空格
错误:export HADOOP_OPTS=多余空格
解决:重新修改/bashrc文件,去掉多余空格
参考:使用命令“hadoop version “找不到或无法加载主类的问题
修改hadoop配置文件
一共有六个文件,注意打开终端的位置(相对路径、绝对路径),在/home/linlin/hadoop路径下打开终端
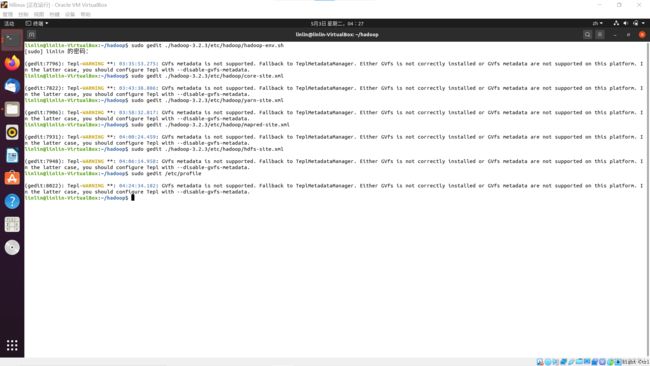
hadoop-env.sh
-
终端打开文件,输入命令
sudo gedit ./hadoop---/etc/hadoop/hadoop-env.sh
-
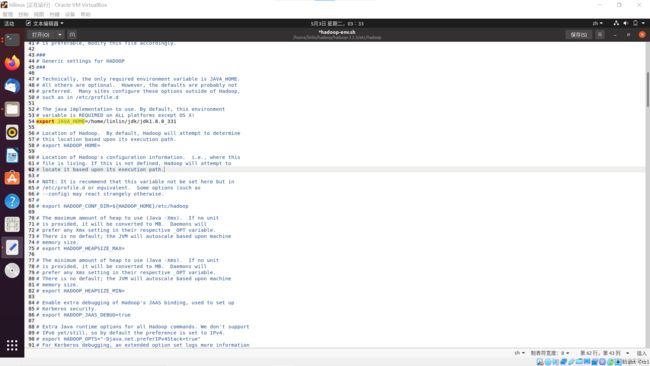
将(# export JAVA_HOME=...)改为jdk目录:(ctrl + f查找)
export JAVA_HOME=/home/linlin/jdk/jdk---
-
保存关闭
core-site.xml
-
终端打开文件,输入命令
sudo gedit ./hadoop---/etc/hadoop/core-site.xml
-
设置HDFS默认名称,地址10.0.2.15,端口号9000(配置HDFS的主节点;配置hadoop运行产生文件的存储目录)
fs.defaultFS hdfs://{ip地址}:{端口号} hadoop.tmp.dir /home/linlin/hadoop/hadoop---/dataNode_1_dir -
保存关闭

yarn-site.xml
-
终端打开文件,输入命令
sudo gedit ./hadoop---/etc/hadoop/yarn-site.xml
-
设置站点(配置resourcemanager的地址;配置nodemanager执行任务的方式shuffle)
yarn.resourcemanager.hostname {ip地址} yarn.nodemanager.aux-services mapreduce_shuffle -
保存关闭

mapred-site.xml
-
终端打开文件,输入命令
sudo gedit ./hadoop---/etc/hadoop/mapred-site.xml
-
设置mapreduce的框架为YARN
mapreduce.framework.name yarn -
保存关闭

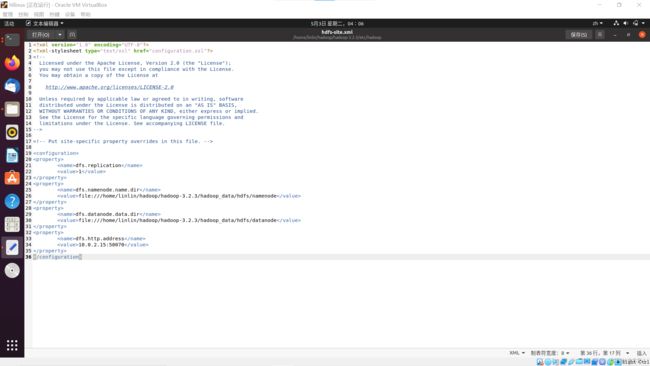
hdfs-site.xml
-
终端打开文件,输入命令
sudo gedit ./hadoop---/etc/hadoop/hdfs-site.xml
-
修改hdfs默认块的副本属性,将副本数改为1,设置namenode和datenode存储位置,设置IP地址10.0.2.15、端口号50070(伪分布式只有一个数据节点)
dfs.replication 1 dfs.namenode.name.dir file:///home/linlin/hadoop/hadoop---/hadoop_data/hdfs/namenode dfs.datanode.data.dir file:///home/linlin/hadoop/hadoop---/hadoop_data/hdfs/datanode dfs.http.address {IP地址}:{端口号} -
保存关闭
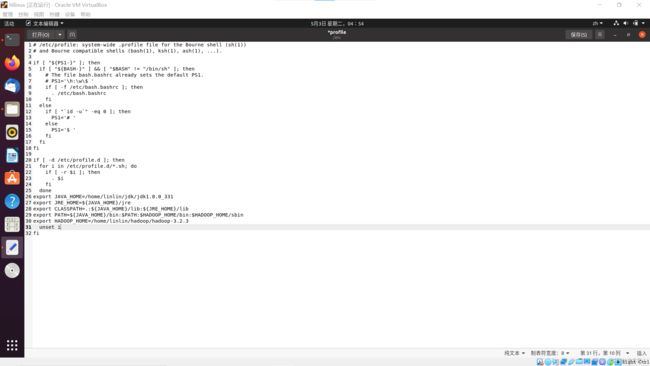
修改系统/etc/profile文件
-
终端打开文件,输入命令
sudo gedit /etc/profile
-
添加环境变量,hadoop的路径
export HADOOP_HOME=/home/linlin/hadoop/hadoop---
-
修改PATH
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
-
保存关闭
终于修改完了,继续
创建并格式化系统文件
前面的配置文件中写了这三个目录(不存在),因此需要创建目录。主目录下打开终端(/home/linlin)
namenode存储路径file:///home/linlin/hadoop/hadoop---/hadoop_data/hdfs/namenode
datanode存储路径file:///home/linlin/hadoop/hadoop---/hadoop_data/hdfs/datanode
hadoop运行产生文件的存储目录/home/linlin/hadoop/hadoop---/dataNode_1_dir/datanode
-
创建目录
mkdir -p ./hadoop/hadoop---/hadoop_data/hdfs/namenode
mkdir -p ./hadoop/hadoop---/hadoop_data/hdfs/datanode
mkdir -p ./hadoop/hadoop---/dataNode_1_dir/datanode
-
HDFS格式化(将namenode中的数据格式化)输入y
hdfs namenode -format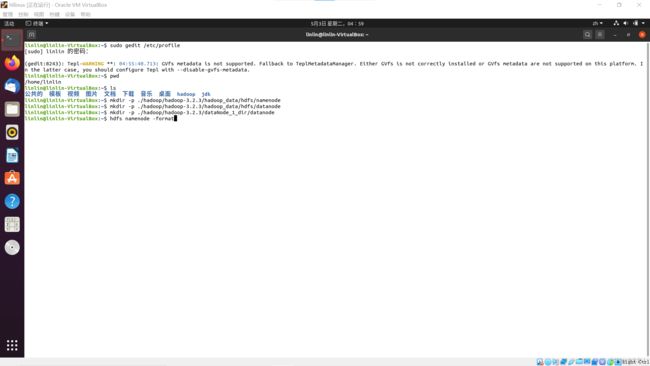
-
出现successful表示成功
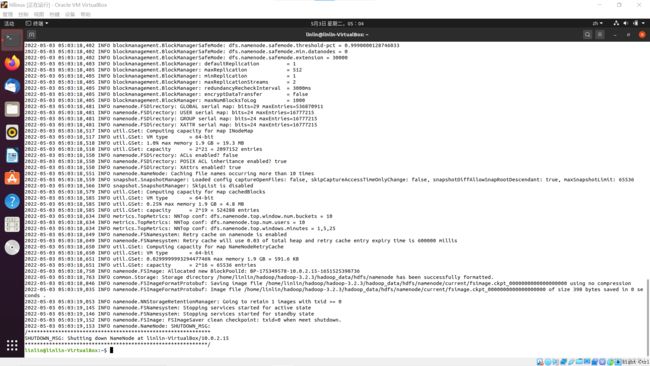
启动hadoop
尽管配置过程艰辛,但此刻的你必然激动!
或许启动会出错,但是每一个错误又何尝不是一种挑战呢?
想起一句梗:消灭恐惧的最好方法就是面对恐惧,奥利给。
-
启动hadoop命令(分为启动HDFS命令start.dfs.sh和启动YARN命令start.yarn.sh)
start-all.sh
-
检验hadoop的全部守护进程,(可能提示安装openjdk---headless)
jps
-
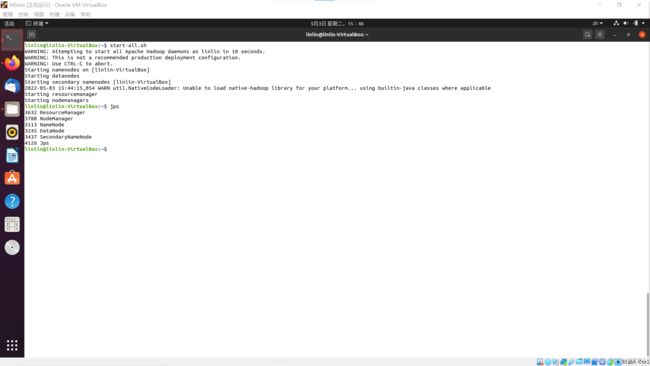
出现五个进程:
DataNode;SecondaryNameNode;NameNode;NodeManager;ResourceManger -
关闭hadoop命令(分为关闭HDFS命令stop.dfs.sh和关闭YARN命令stop.yarn.sh)
stop-all.sh

出错->解决->满足
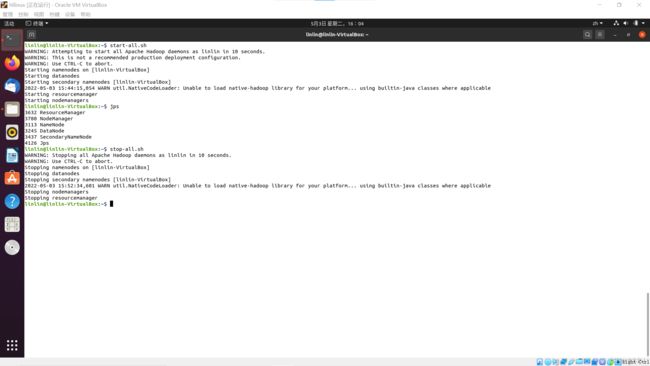
上面的进程中出现警告:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable stopping nodemanagers
原因:无法加载本地hadoop库
错误:缺少配置信息,需要修改hadoop---/etc/hadoop/log4j.properties文件,增加下面信息
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
解决:解决方法见警告warn:无法加载本地hadoop库
解决之后就好了,不解决也不会影响hadoop的进程
再次输入启动hadoop进程命令,便不会出现警告
出错->解决->满足
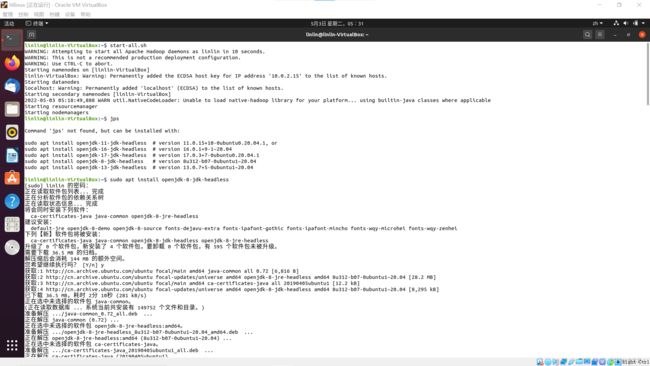
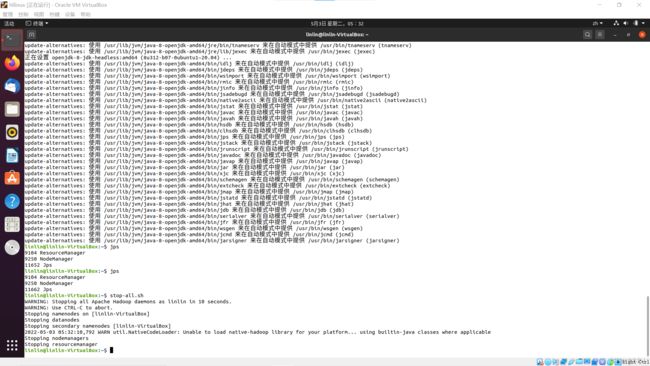
原因:发现我的只能守护两个进程,都是yarn的进程,说明yarn正确,而hdfs进程的配置出错了,仔细检查core-site.xml文件(图片——当时的配置信息)
错误:hdfs不能启动——core-site.xml少两个//
解决:重新修改core-site.xml文件
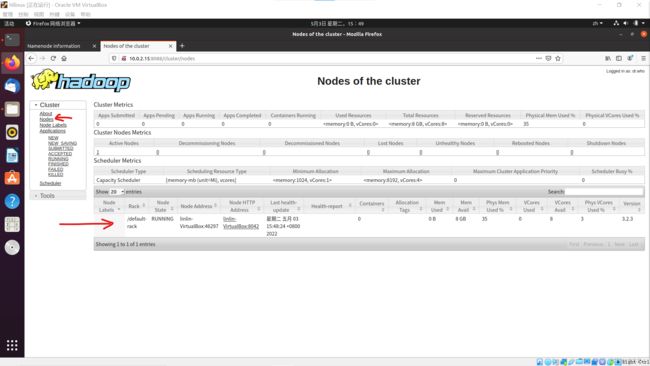
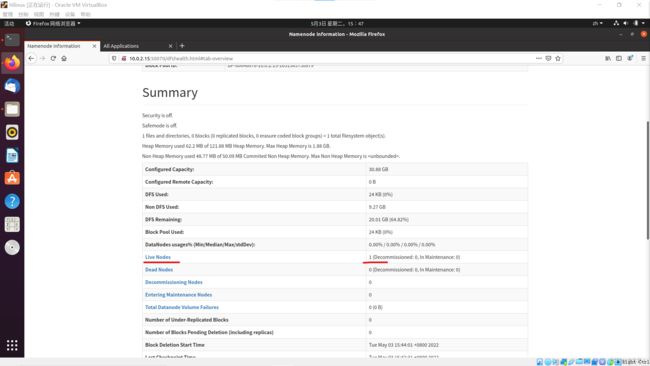
查看页面
先格式化dhfs的节点信息,启动运行hadoop,使用Ubuntu自带火狐浏览器输入网址
在地址栏输入{IP地址}:{端口号},进入HDFS Web界面,查看活动节点
在地址栏输入{IP地址}:8088,进入YARN Web界面,选择nodes连接,显示当前运行的节点(伪分布式只有一个节点)