hadoop集群搭建和配置
hadoop的优势是分布式集群计算,即搭建hadoop集群(完全分布式Hadoop)
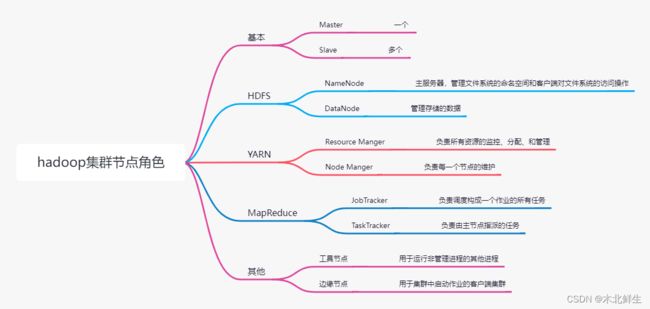
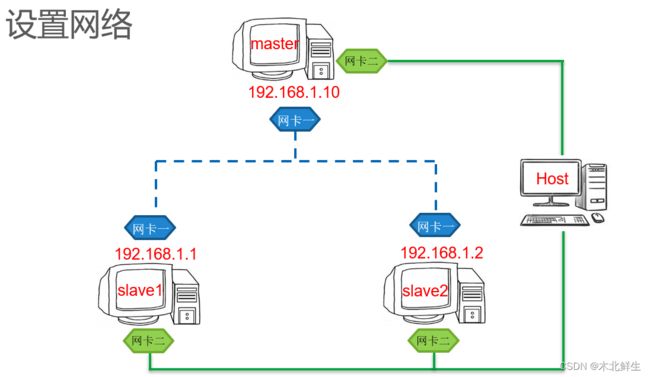
集群由节点组成,节点构成不同角色。
hadoop集群

各个节点的功能
搭建集群步骤
- 节点规划
- 设置网络
- 配置文件
- 复制虚拟机
- 格式化文件系统
- 启动集群
准备工作与搭建集群
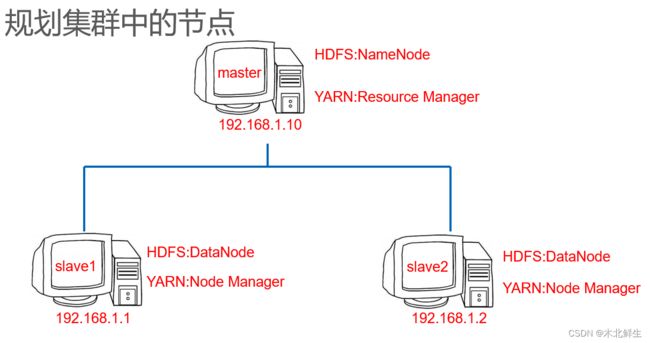
节点规划
服务器是什么?节点是什么?
服务器是计算机的一种,它比普通计算机运行更快、负载更高、价格更贵。
节点就相当于服务器,节点越多,性能越好,但成本增加。
集群最少需要三个节点,分别作为NameNode,Secondary NameNode ,DataNode
NameNode记录数据分布情况
SecondDary NameNode备份主节点数据,防止死机后数据丢失,可以通过这个节点恢复数据
DataNode存放真正的数据,文件以数据块形式存储。
用三个虚拟机模拟三个节点来学习(虚拟主机无法体会多台计算机并行处理的优势,但操作步骤与实体主机相同)
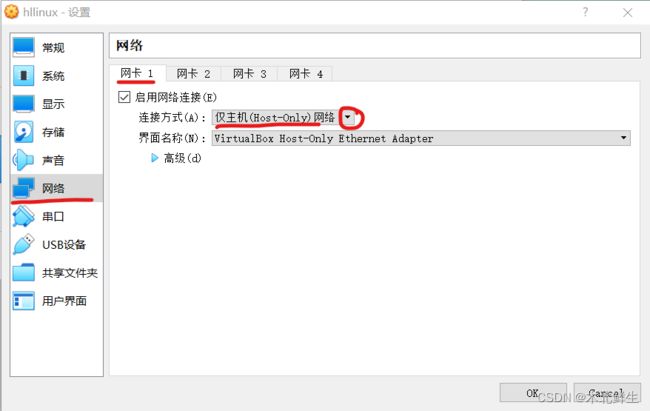
设置网络
设置两个网卡
-
网卡一,“仅主机网络”,连接主从节点与主机。
- 选中虚拟机,点击设置
- 进入虚拟机设置界面,点击网络,选择网卡1,选择连接方式——仅主机网络
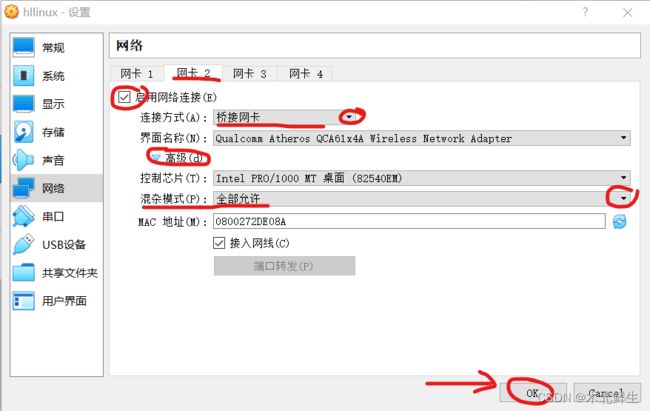
-
网卡二,“桥接连接”,连接主机和主节点、从节点与外部网络。
- 选择网卡2,勾选启用网络连接,选择连接方式——桥接连接,点击高级,在下拉内容的选择混杂模式——全部允许
- 完成点击ok
修改配置文件
设置服务器master
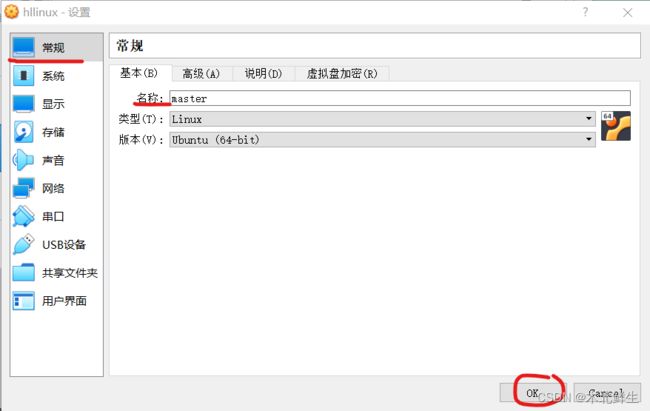
重命名虚拟机
进入设置,选择常规,选择基本,在名称中输入主节点名称,点击ok
修改IP地址
(修改后不能上网)
-
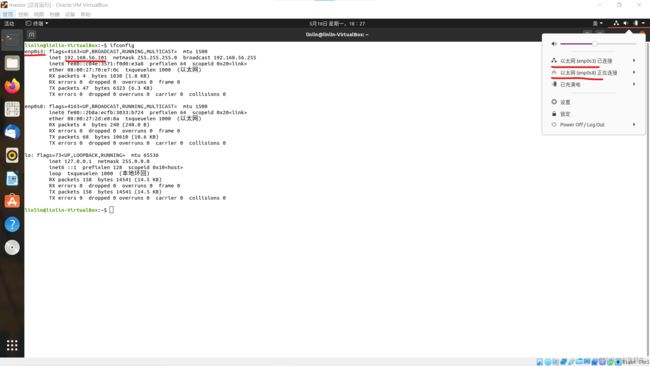
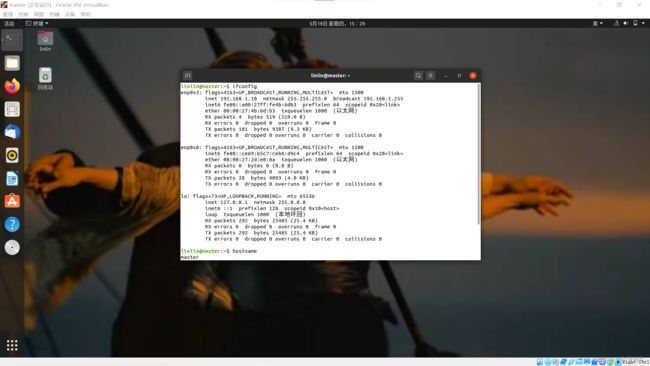
使用ifconfig命令查看IP端口名称与当前IP地址,掩码网关,广播地址。
ifconfig
使用下面方法,由于版本问题,对于Ubuntu20.04不能成功,参考:修改IP地址
修改IP地址,终端输入命令,编辑文件信息
sudo gedit /etc/network/interfaces
auto lo iface lo inet loopback auto enp0s3 iface enp0s3 inet static address 192.168.1.10 netmask 255.255.255.0 broadcast 192.168.1.255重启网络配置生效
sudo /etc/init.d/networking restart
-
在终端输入命令,编写文件(#后面的文字是注释,需要去掉)
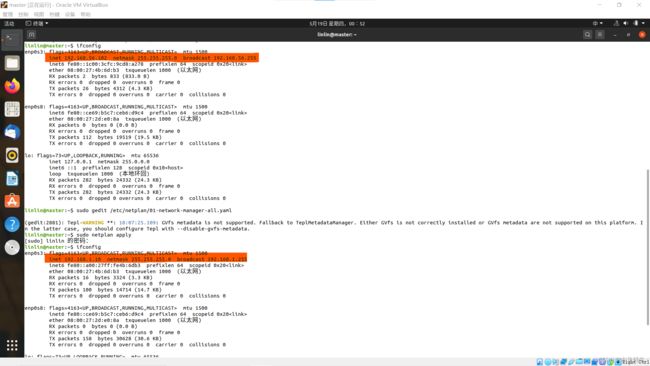
sudo gedit /etc/netplan/01-network-manager-all.yaml
# Let NetworkManager manage all devices on this system network:#网络 version: 2#版本 renderer: NetworkManager#渲染器 ethernets:#以太网 enp0s3: addresses: [192.168.1.10/24] dhcp4: no dhcp6: no gateway4: 192.168.1.1#网关 nameservers:#域名服务器 addresses: [192.168.1.1,8.8.8.8] -
输入命令,使刚才的配置生效
sudo netplan apply
-
再使用ifconfig命令查看IP地址是否修改成功
ifconfig
修改主机名
-
使用hostname命令查看主机名
hostname
-
修改主机名输入命令,将文件内容修改为主机名(master)
sudo gedit /etc/hostname
master -
需要重启生效
配置.xml文件
直接在home/linlin/hadoop/hadoop—/etc/hadoop/路径下打开终端
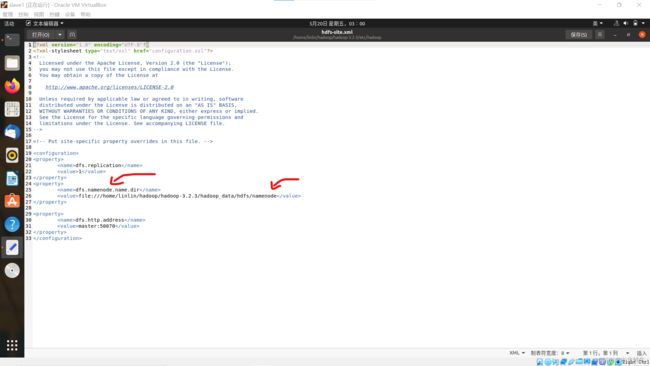
hdfs-site.xml
sudo gedit hdfs-site.xml
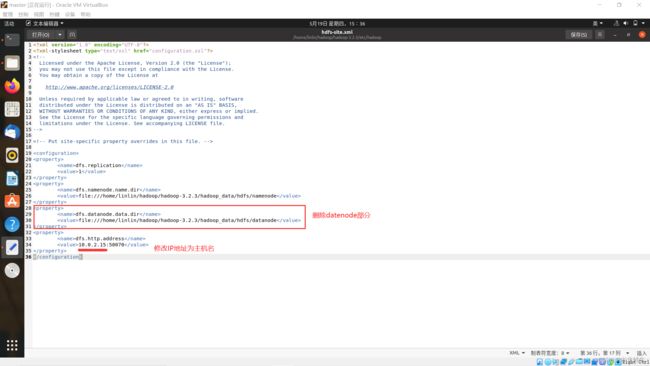
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/linlin/hadoop/hadoop-3.2.3/hadoop_data/hdfs/namenodevalue>
property>
<property>
<name>dfs.http.addressname>
<value>master:50070value>
property>
configuration>
删除datanode存储目录
将IP地址改为主机名
core-site.xml
sudo gedit core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/linlin/hadoop/hadoop-3.2.3/dataNode_1_dirvalue>
property>
configuration>
将IP地址改为主机名

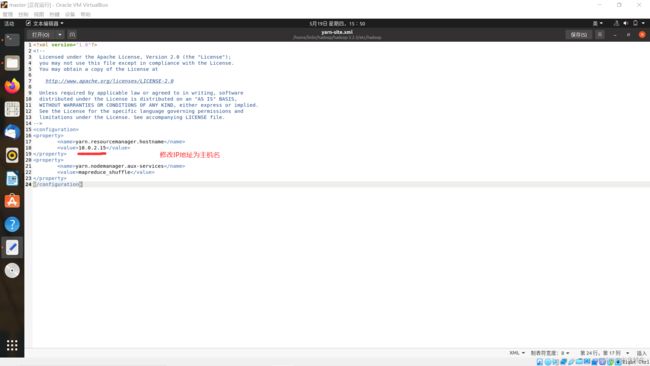
yarn-site.xml
sudo gedit yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
将IP地址改为主机名
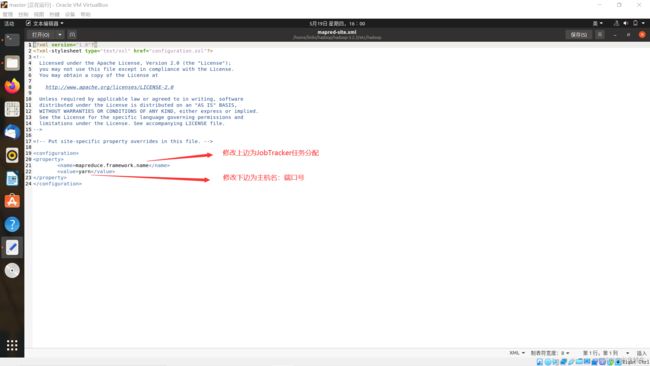
mapred-site.xml
sudo gedit mapred-site.xml
<property>
<name>mapred.job.trackername>
<value>master:54311value>
property>
修改内容(设置监控Map与Reduce程序的JobTracker任务分配情况,以及TaskTracker任务运行情况)
配置节点文件
在主目录/home/linlin下打开终端(为什么要在这里打开终端呢?我想多此一举罢了,多出点错,给自己找点麻烦~)
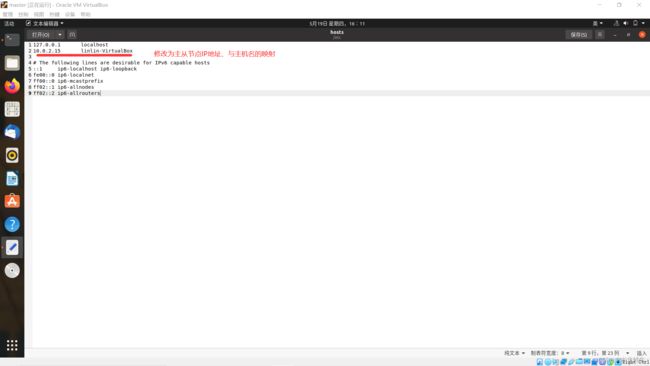
修改配置文件/etc/hosts
sudo gedit /etc/hosts
127.0.0.1 localhost
192.168.1.10 master
192.168.1.1 slave1
192.168.1.2 slave2
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
修改主节点、增加从节点的IP地址和主机名
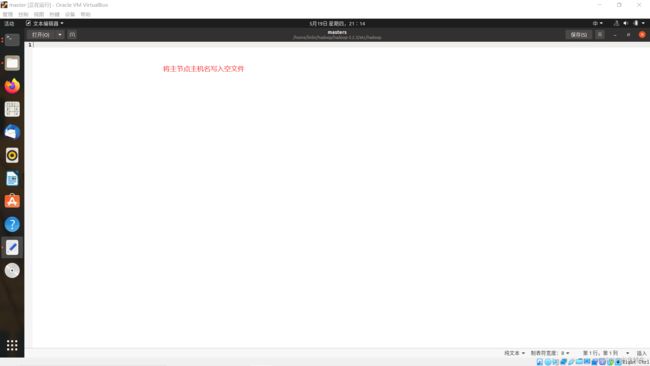
修改masters文件
注意使用了相对路径(原本不存在这个文件,参考文档:Apache Hadoop 3.2.3 – Hadoop Cluster Setup,通过root用户创建)
sudo gedit ./hadoop/hadoop—/etc/hadoop/masters
master
添加主节点主机名
修改workers文件
hadoop3使用workers文件列出从节点,hadoop2使用slaves文件
sudo gedit ./hadoop/hadoop—/etc/hadoop/workers
slave1
slave2
修改从节点主机名

防止启动出错
将/hadoop—路径下的dataNode_1_dir文件夹和logs文件夹删除(选中按delete)
建议将hadoop—/hadoop_data/hdfs/datanode和hadoop—/hadoop_data/hdfs/namenode路径下的current文件夹删除。否则可能和我一样出错,缺少DataNode进程,参考:slave缺少datanode进程
原因是需要将master的namenode与slave的datenode的current/VERSION文件中clusterID改为一致,才能守护进程。但是在格式化namenode之后,三个服务器的clusterID就会让人觉得很乱。所以直接删除,让其自行创建文件——在master的namenode下会创建current文件夹,在slave的datanode下会创建current文件夹;在hadoop—路径下会创建dir文件夹和logs文件夹
复制虚拟机
将服务器master复制出slave1,slave2,省略操作
复制虚拟机之前,关闭虚拟机
-
选中虚拟机,右键复制
-
进入新虚拟机名称和保存路径界面,输入新虚拟机名称,在下拉框Mac地址设定,选择包含所有网卡的Mac地址,单击下一步
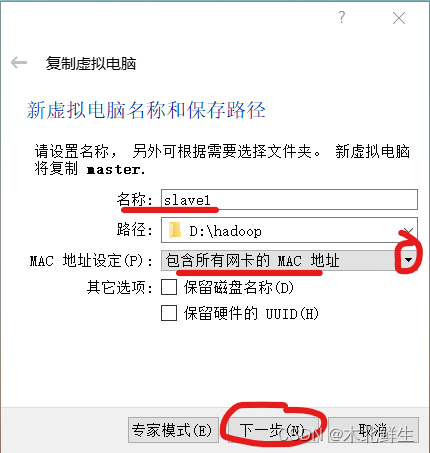
-
进入副本类型界面,默认选中完全复制,单击复制
-
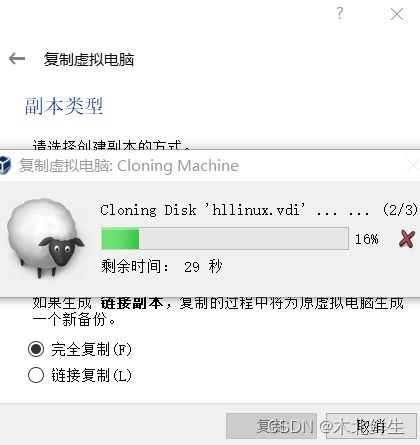
弹出进度条,等待复制完成,virtualbox出现新的虚拟机(同样复制下一个虚拟机)
设置服务器slave
与服务器master操作相同(同样方式操作slave1,slave2)
修改IP地址
修改addresses分别为192.168.1.1(192.168.1.2)
-
使用ifconfig命令查看IP端口名称与当前IP地址,掩码网关,广播地址。
ifconfig
-
在终端输入命令,编写文件(#后面的文字是注释,需要去掉)
sudo gedit /etc/netplan/01-network-manager-all.yaml
# Let NetworkManager manage all devices on this system network: version: 2 renderer: NetworkManager ethernets: enp0s3: addresses: [192.168.1.1/24]#[192.168.1.2/24] dhcp4: no dhcp6: no gateway4: 192.168.1.1 nameservers: addresses: [192.168.1.1,8.8.8.8] -
输入命令,使刚才的配置生效
sudo netplan apply
-
再使用ifconfig命令查看IP地址是否修改成功
ifconfig
修改主机名
修改slave1(slave2)
-
使用hostname命令查看主机名
hostname
-
修改主机名输入命令,将文件内容修改为主机名
sudo gedit /etc/hostname
slave1#slave2 -
需要重启生效
配置hdfs-site.xml
直接在主目录下输入命令,打开文件
sudo gedit ./hadoop/hadoop—/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/linlin/hadoop/hadoop-3.2.3/hadoop_data/hdfs/datanodevalue>
property>
<property>
<name>dfs.http.addressname>
<value>master:50070value>
property>
configuration>
将之前保留的namenode存储目录替换为datanode存储目录
ssh无密码连接登录
-
启动全部服务器master,slave1,slave2

-
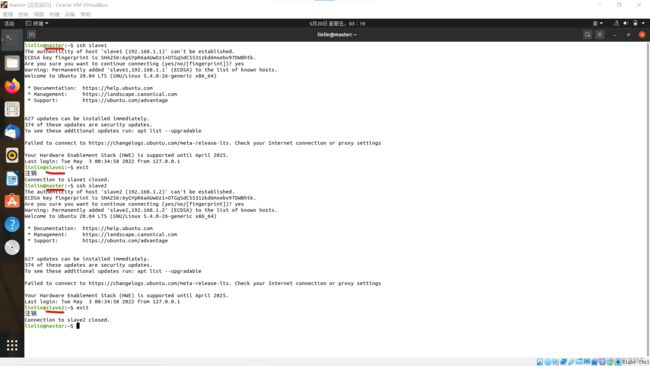
在master终端输入连接命令,提示输入yes,发现命令提示符会发生变化,即成功连接
ssh slave1
ssh slave2
-
输入命令关闭ssh,发现命令提示符变回,即中断连接
exit
格式化文件系统
部署HDFS文件系统,只需要在master上格式化,输入命令,弹出提示输入y,出现successfully则成功格式化
hdfs namenode -format

启动和关闭hadoop集群
(首次启动需要格式化,下次启动无需格式化)
-
启动hadoop命令(分为启动HDFS命令start.dfs.sh和启动YARN命令start.yarn.sh)
start-all.sh
-
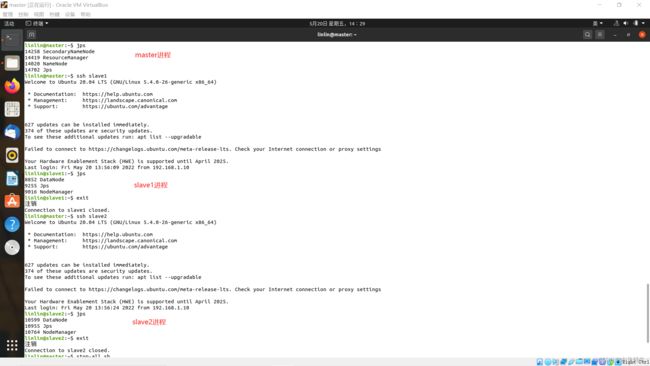
检验hadoop的全部守护进程(需要分别用ssh连接节点服务器,查看各个从节点的守护进程ssh slave1/ssh slave2、exit)
jps
master出现守护进程:NameNode;SecondaryNameNode;ResourceManger;jps
slave1出现守护进程:NodeManager;DataNode;jps
slave2出现守护进程:NodeManager;DataNode;jps
-
关闭hadoop命令(分为关闭HDFS命令stop.dfs.sh和关闭YARN命令stop.yarn.sh)
stop-all.sh
查看集群信息
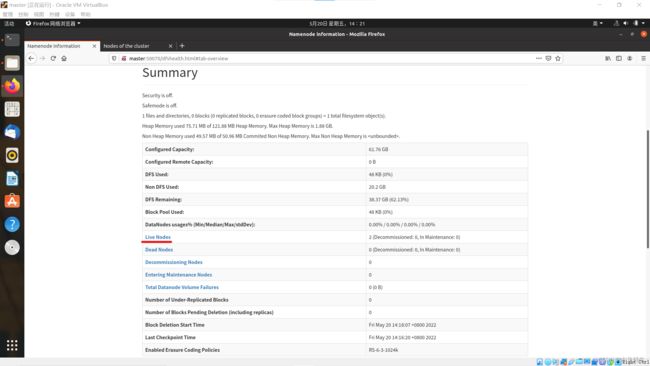
进入网址https://master:50070查看HDFS监控页面

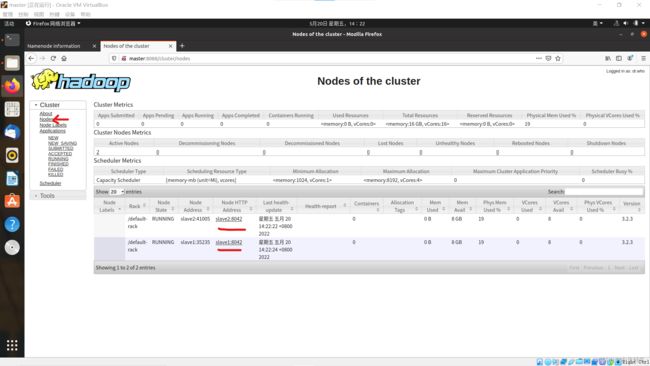
进入网址https://master:8088查看YARN监控页面
体验并理解分布式计算
运行自带的mapreduce程序,计算圆周率的java程序包
位置:hadoop—/share/hadoop/mapreduce
文件名:hadoop-mapreduce-examples—.jar
在终端输入命令,其中pi是类名,第一个10表示map次数,第二个10表示随机生成点的次数
hadoop jar ./hadoop—/share/hadoop/mapreduce/hadoop-mapreduce-examples—.jar pi 10 10

最后两行会显示计算时间、计算结果
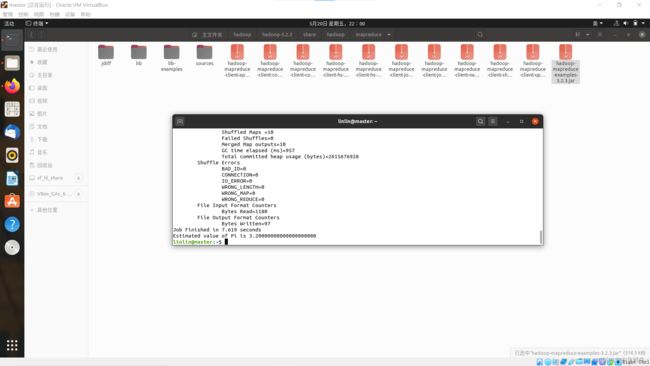
总结:验证hadoop启动成功的三种方式
- jps查看进程
- web页面验证
- 执行MapReduce程序
理论公式都是火热的思考下产生的冰冷的美丽!
弗赖登塔尔曾说过:“没有一种数学思想如当初刚被发现时那样发表出来。一旦问题解决了,思考的程序便颠倒过来,把火热的思考变成冰冷的美丽。”
燃烧的问题:解决搭建hadoop集群出现的问题