HBase shell操作,看这一篇就够了
目录
0 前言
1.基本操作
1. 进入 HBase客户端的命令
2. 查看帮助命令
3. 查看当前数据库有哪些表
4. 查看当前用户及对应所属组
5. 查看Hbase服务器状态
6. 查看版本信息
2.表的基本操作
1. 创建表(create)
2. 插入数据到表(put)
3. 扫描查看表数据(scan操作)
4. 查看表结构(describe)
5. 更新指定字段的数据(put)
6.查看“指定行”或“指定列族:列”的数据(get)
7. 统计表数据行数(记录数)(count)
8. 删除数据(delete)
9. 清空表数据( truncate)
10. 删除表(drop)
11. 变更表信息(alter)
12 修改表的压缩格式
13 . 采用RowCounter快速统计Hbase中的表
14. 查看Hbase表的meta表的数据
15 获取表所对应的Region个数( get_split)
16 HBase建表语句解析
3.小结
0 前言
HBase的命令行工具,最简单的接口,适合HBase管理使用,可以使用shell命令来查询HBase中数据的详细情况。本文从增、删、改、查几个方面详细介绍了Hbase shell的基本操作,最后又介绍了Hbase 快速统计行数的方法及meta表的查看方法,及快速查看具体某个表元信息的方法。通过本文您可以获取以下知识:
(1)Hbase shell的基本操作
(2)Hbase meta表的作用及查看方法
(3)如何快速获取Hbase中某张表的meta信息
(4)如何快速统计一张Hbase表的记录数
1.基本操作
1. 进入 HBase客户端的命令
hbase shell
2. 查看帮助命令
help
3. 查看当前数据库有哪些表
list
4. 查看当前用户及对应所属组
结果如下:
hbase(main):038:0> whoami
hbase (auth:SIMPLE)
groups: hadoop
5. 查看Hbase服务器状态
hbase(main):039:0> status
1 active master, 1 backup masters, 3 servers, 0 dead, 21.3333 average load
6. 查看版本信息
hbase(main):040:0> version
1.1.2.1.1.0.0-0131, r8c3e6f0c9bb687c3caaafc932e38e6042ac73e0c, 2017年 11月 27日 星期一 15:16:41 CST
2.表的基本操作
1. 创建表(create)
hbase(main):006:0> create 'student','infor'
2. 插入数据到表(put)
hbase(main):008:0> put 'student','1001','infor:sex','male'
0 row(s) in 0.0230 seconds
hbase(main):009:0> put 'student','1001','infor:age','18'
0 row(s) in 0.0130 seconds
hbase(main):010:0> put 'student','1002','infor:name','guozi'
0 row(s) in 0.0110 seconds
hbase(main):011:0> put 'student','1002','infor:sex','male'
0 row(s) in 0.0110 seconds
hbase(main):012:0> put 'student','1002','infor:age','18'
0 row(s) in 0.0110 seconds
3. 扫描查看表数据(scan操作)
(1)全表扫描
hbase(main):013:0> scan 'student'
(2)按指定的rowkey查看
hbase(main):014:0> scan 'student',{STARTROW => '1001',STOPROW=>'1001'}结果如下:

scan
scan命令可以按照rowkey的字典顺序来遍历指定的表的数据。
scan ‘表名’:默认当前表的所有列族。
scan ‘表名’,{COLUMNS=> [‘列族:列名’],…} : 遍历表的指定列
scan '表名', { STARTROW => '起始行键', ENDROW => '结束行键' }:指定rowkey范围。如果不指定,则
会从表的开头一直显示到表的结尾。区间为左闭右开。
scan '表名', { LIMIT => 行数量}: 指定返回的行的数量
scan '表名', {VERSIONS => 版本数}:返回cell的多个版本
scan '表名', { TIMERANGE => [最小时间戳, 最大时间戳]}:指定时间戳范围
注意:此区间是一个左闭右开的区间,因此返回的结果包含最小时间戳的记录,但是不包含最大时间戳记录
scan '表名', { RAW => true, VERSIONS => 版本数}
显示原始单元格记录,在Hbase中,被删掉的记录在HBase被删除掉的记录并不会立即从磁盘上清除,而是先被打
上墓碑标记,然后等待下次major compaction的时候再被删除掉。注意RAW参数必须和VERSIONS一起使用,但
是不能和COLUMNS参数一起使用。
scan '表名', { FILTER => "过滤器"} and|or { FILTER => "过滤器"}: 使用过滤器扫描
HBase(main):008:0> scan 'student'
HBase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'}
HBase(main):010:0> scan 'student',{STARTROW => '1001'}
4. 查看表结构(describe)
hbase(main):015:0> describe 'student'
5. 更新指定字段的数据(put)
put 'student','1001','info:name','xiaoyanjing'6.查看“指定行”或“指定列族:列”的数据(get)
(1)获取指定行的数据
hbase(main):031:0> get 'student','1001'
(2)获取指定字段值信息
hbase(main):033:0> get 'student','1001','infor:name'
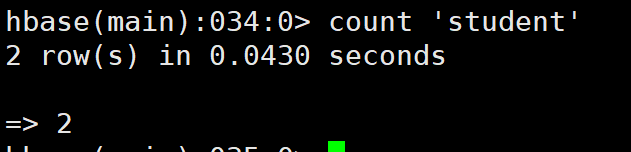
7. 统计表数据行数(记录数)(count)
hbase(main):034:0> count 'student'
结果如下:
8. 删除数据(delete)
hbase(main):016:0> deleteall 'student','1001'
hbase(main):017:0> delete 'student','1002','infor:sex'9. 清空表数据( truncate)
hbase(main):018:0>disable 'student'
hbase(main):018:0> truncate 'student'
*先禁止表,然后再清空10. 删除表(drop)
首先需要先让该表为 disable 状态:
hbase(main):019:0> disable 'student'
然后才能 drop 这个表:
hbase(main):020:0> drop 'student'
提示:如果直接 drop 表,会报错:ERROR: Table student is enabled. Disable it first.11. 变更表信息(alter)
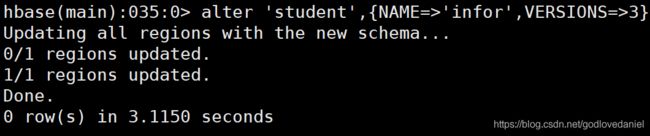
将infor列族中的信息存放三个版本
hbase(main):035:0> alter 'student',{NAME=>'infor',VERSIONS=>3}
结果如下:
查看内容:
hbase(main):037:0> get 'student','1001',{COLUMN=>'infor:name',VERSIONS=>3}
12 修改表的压缩格式
(1) 先disable表
hbase(main):018:0> disable 'test_dd‘
(2) 修改表的压缩格式
hbase(main):018:0> alter 'test_dd', NAME => 'f', COMPRESSION => 'snappy‘ps:假如你不小心创建了一个新列族的话,可以通过以下方式删除:
hbase(main):018:0> alter 'test_dd', {NAME=>'f', METHOD=>'delete'}
(3) 重新enable表
hbase(main):018:0> enable 'test_dd‘(4)enable表后,HBase表的压缩格式并没有生效,还需要一个动作,即HBase major_compact
hbase(main):018:0> major_compact 'test_dd‘该动作耗时较长,会对服务有很大影响,可以选择在一个服务不忙的时间来做。
describe一下该表,可以看到HBase 表压缩格式修改完毕。
13 . 采用RowCounter快速统计Hbase中的表
RowCounter相比于count要快很多,他利用map-reduce进行统计.
su - hbase
[hbase@bigdata3 ~]$ hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'test_dd'
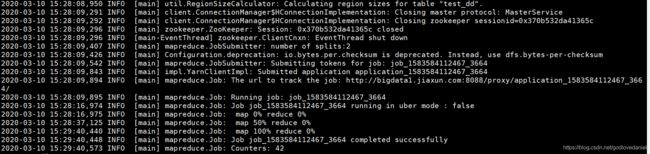
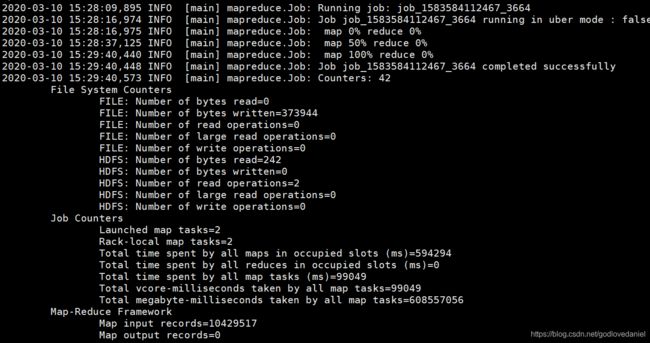
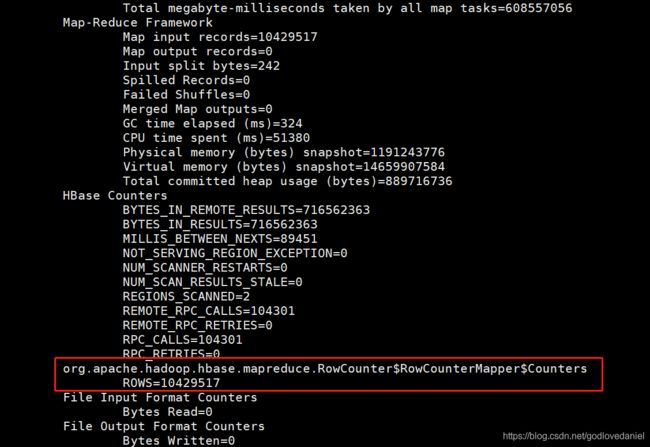
统计1千多万条数据总共耗时大概 51秒
14. 查看Hbase表的meta表的数据
Hbase的meta表的结构信息如下图所示:
| meta表结构 | |||
|---|---|---|---|
| Row(行健) | Column Family(列族) | Column(列) | Value |
| tableName(表名), table produce epoch (表创建的时间戳) |
info(信息) | regioninfo(分区信息) | NAME=> STARTKEY=> ENDKEY=> ENCODED=>(编码) |
| server | 服务器地址:端口 | ||
| serverstartcode | 服务开始的时间戳 | ||
scan ‘hbase:meta’
目的是为了查看该表是由哪台服务器所维护,读写请求时候该向哪个服务器发送请求信息。
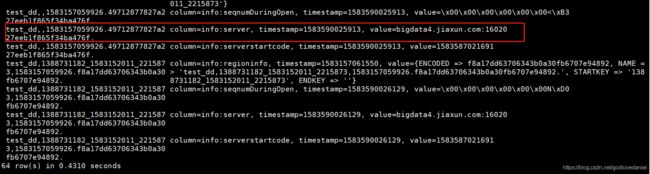
scan ‘hbase:meta’往往得到的是Hbase中所有表的元信息,如果得到指定的表的元信息呢?
利用下面的shell语句可以得到想要的表的信息
su - hbase
[hbase@bigdata3 ~]$ echo "scan 'hbase:meta'" | hbase shell | grep 'test_dd'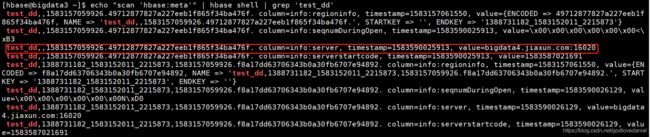
15 获取表所对应的Region个数( get_split)
hbase(main):015:0> get_splits 'person'
Total number of splits = 1
=> []获取表所对应的Region个数。每个表在一开始只有一个region,之后记录增多后,region会被自动拆分。
16 HBase建表语句解析
像所有其他数据库一样,HBase也有表的概念,有表的地方就有建表语句,而且建表语句还很大程度上决定了这张表的存储形式、读写性能。比如我们熟悉的MySQL,建表语句中数据类型决定了数据的存储形式,主键、索引则很大程度上影响着数据的读写性能。虽然HBase没有主键、索引这些概念,但在HBase的世界里,有些东西和它们一样重要!
废话不说,直接奉上一条HBase建表语句,来为各位看官分解剖析:
create 'NewsClickFeedback',
{NAME=>'Toutiao',VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>'ROW'
,COMPRESSION=>'SNAPPY',
TTL => ' 259200 '},{SPLITS =>
['1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}上述建表语句表示创建一个表名为“NewsClickFeedback”的表,该表只包含一个列簇“Toutiao”。接下来重点讲解其他字段的含义以及如何正确设置。Note:因为篇幅有限本文并不讲解具体的工作原理,后续会有相关专题对其进行分析。
VERSIONS
数据版本数,HBase数据模型允许一个cell的数据为带有不同时间戳的多版本数据集,VERSIONS参数指定了最多保存几个版本数据,默认为1。假如某个用户想保存两个历史版本数据,可以将VERSIONS参数设置为2,再使用如下Scan命令就可以获取到所有历史数据:
scan 'NewsClickFeedback',{VERSIONS => 2}BLOOMFILTER
布隆过滤器,优化HBase的随机读取性能,可选值NONE|ROW|ROWCOL,默认为NONE,该参数可以单独对某个列簇启用。启用过滤器,对于get操作以及部分scan操作可以剔除掉不会用到的存储文件,减少实际IO次数,提高随机读性能。Row类型适用于只根据Row进行查找,而RowCol类型适用于根据Row+Col联合查找,如下:
- Row类型适用于:get ‘NewsClickFeedback’,’row1′
- RowCol类型适用于:get ‘NewsClickFeedback’,’row1′,{COLUMN => ‘Toutiao’}
- 对于有随机读的业务,建议开启Row类型的过滤器,使用空间换时间,提高随机读性能。
COMPRESSION
数据压缩方式,HBase支持多种形式的数据压缩,一方面减少数据存储空间,一方面降低数据网络传输量进而提升读取效率。目前HBase支持的压缩算法主要包括三种:GZip | LZO | Snappy,下面表格分别从压缩率,编解码速率三个方面对其进行对比:
Snappy的压缩率最低,但是编解码速率最高,对CPU的消耗也最小,目前一般建议使用Snappy
TTL
默认是 2147483647 即:Integer.MAX_VALUE 值大概是 68 年 , 这个参数是说明该列族数据的存活时间,单位是 毫秒。这个参数可以根据具体的需求对数据设定存活时间,超过存过时间的数据将在表中不在 显示,待下次 major compact 的时候再彻底删除数据。注意的是 TTL 设定之后 MIN_VERSIONS=>'0' 这样设置之后, TTL 时间戳过期后,将全部 彻底删除该 family 下所有的数据,如果 MIN_VERSIONS 不等于 0 那将保留最新的 MIN_VERSIONS 个版本的数据,其它的全部删除,比如 MIN_VERSIONS=>'1' 届时将保留一个最新版本的数据,其它版本的数据将不再保存。用户可以根据具体业务场景设置为一个月或者三个月。示例中TTL => ‘ 259200’设置数据过期时间为三天
IN_MEMORY
数据是否常驻内存,默认为false。HBase为频繁访问的数据提供了一个缓存区域,缓存区域一般存储数据量小、访问频繁的数据,常见场景为元数据存储。默认情况,该缓存区域大小等于Jvm Heapsize * 0.2 * 0.25 ,假如Jvm Heapsize = 70G,存储区域的大小约等于3.2G。需要注意的是HBase Meta元数据信息存储在这块区域,如果业务数据设置为true而且太大会导致Meta数据被置换出去,导致整个集群性能降低,所以在设置该参数时需要格外小心。
BLOCKCACHE
是否开启block cache缓存,默认开启。
SPLITS
region预分配策略。通过region预分配,数据会被均衡到多台机器上,这样可以一定程度上解决热点应用数据量剧增导致系统自动split引起的性能问题。HBase数据是按照rowkey按升序排列,为避免热点数据产生,一般采用hash + partition的方式预分配region,比如示例中rowkey首先使用md5 hash,然后再按照首字母partition为16份,就可以预分配16个region。
3.小结
本文为读者讲解了有关Hbase shell的一些基本命令,可作为读者具体操作的命令手册,也可以作为Hbase入门阶段实验案例,读者只需在自己服务器中尝试即可。
references:
Hbase Meta表基本介绍_JY_He的博客-CSDN博客_hbase meta表
HBase - 建表语句解析 – 有态度的HBase/Spark/BigData
欢迎关注石榴姐公众号"我的SQL呀",关注我不迷路
