Hive 基本操作(二)DML操作
Hive 基本操作(二)DML操作
- 1、DML 操作
-
- 1.1、Load 装载数据
- 1.2、Insert 插入数据
- 1.3、Insert 导出数据
- 1.4、Select 查询数据
- 1.5、Hive Join 查询
- 2、学习内容
1、DML 操作
1.1、Load 装载数据
语法结构:
LOAD DATA [LOCAL] INPATH 'filepath/uri'
[OVERWRITE] INTO TABLE tb_name [PARTITION (partcol1=val1, partcol2=val2 ...)];
关键字说明:
(1)LOAD 操作只是单纯的复制或者移动操作,将数据文件移动到 Hive 表对应的位置。
(2)LOCAL 关键字:如果指定了 LOCAL, LOAD 命令会去查找本地文件系统中的 filepath。如果没有指定 LOCAL 关键字,则根据 inpath 中的 uri 查找文件。
注意:uri 是指 hdfs 上的路径,分简单模式和完整模式两种,例如:
简单模式:/user/hive/project/data1
完整模式:hdfs://namenode_host:9000/user/hive/project/data1
(3)filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/home/project/data1
包含模式的完整 URI,列如:hdfs://namenode_host:9000/user/home/project/data1
注意:inpath 子句中的文件路径下,不能再有文件夹。
(4)overwrite 关键字:如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
具体实例:
(1)加载本地相对路径数据:
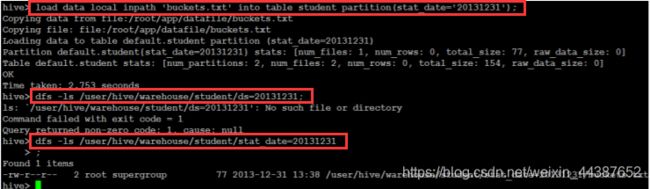
(2)加载绝对路径数据:
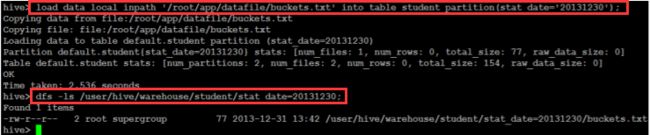
(3)加载包含模式数据:
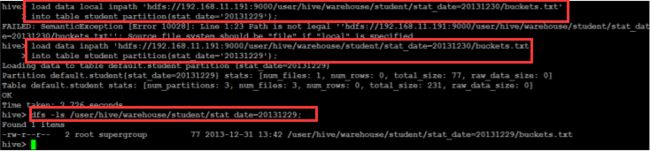
(4)overwrite 关键字使用:

1.2、Insert 插入数据
语法结构:
(1)插入一条数据:
INSERT INTO TABLE table_name VALUES(XX,YY,ZZ);
(2)利用查询语句将结果导入新表:
INSERT OVERWRITE [INTO] TABLE table_name [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement;
(3)多重插入:
FROM from_statement
INSERT OVERWRITE TABLE table_name1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1
INSERT OVERWRITE TABLE table_name2 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement2] ...;
示例:
from mingxing
insert into table mingxing2 select id,name,sex,age
insert into table mingxing select id,name,sex,age,department;
# 从 student 表中,按不同的分区字段进行查询得的结果分别插入不同的 hive 表分区中
from student
insert into table ptn_student partition(city='MA') select id,name,sex,age,department where
department='MA'
insert into table ptn_student partition(city='IS') select id,name,sex,age,department where
department='IS';
insert into table ptn_student partition(city='CS') select id,name,sex,age,department where
department='CS';
(4)分区插入:
分区插入有两种,一种是静态分区,另一种是动态分区。如果混合使用静态分区和动态分区,则静态分区必须出现在动态分区之前。现分别介绍这两种分区插入。
静态分区:
A、创建静态分区表;
B、从查询结果中导入数据;
C、查看插入结果。
动态分区:
静态分区需要创建非常多的分区,那么用户就需要写非常多的 SQL!Hive 提供了一个动态分区功能,其可以基于查询参数推断出需要创建的分区名称。
A、创建分区表,和创建静态分区表是一样的;
B、参数设置:
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
注意:动态分区默认情况下是开启的。但是却以默认是”strict”模式执行的,在这种模式下要求至少有一列分区字段是静态的。这有助于阻止因设计错误导致查询产生大量的分区。但是此处我们不需要静态分区字段,估将其设为 nonstrict。
对应还有一些参数可设置:

| 参数设置 | 描述 |
|---|---|
| set hive.exec.max.dynamic.partitions.pernode=100; | 每个节点生成动态分区最大个数 |
| set hive.exec.max.dynamic.partitions=1000; | 生成动态分区最大个数,如果自动分区数大于这个参数,将会报错 |
| set hive.exec.max.created.files=100000; | 一个任务最多可以创建的文件数目 |
| set dfs.datanode.max.xcievers=4096; | 限定一次最多打开的文件数 |
| set hive.error.on.empty.partition=false; | 表示当有空分区产生时,是否抛出异常 |
小技能补充:如果以上参数被更改过,想还原,请使用 reset 命令执行一次即可。
C、动态数据插入:
# 一个分区字段:
insert into table test2 partition (age) select name,address,school,age from students;
# 多个分区字段:
insert into table student_ptn2 partition(city='sa',zipcode) select id, name, sex, age, department, department as zipcode from studentss;
注意:查询语句 select 查询出来的动态分区 age 和 zipcode 必须放最后,和分区字段对应,不然结果会出错。
D、查看插入结果:
select * from student_ptn2 where city=’sa’ and zipcode=’MA’;
(5)CTAS(create table … as select …):
在实际情况中,表的输出结果可能太多,不适于显示在控制台上,这时候,将 Hive 的查询输出结果直接存在一个新的表中是非常方便的,我们称这种情况为 CTAS。
展示:
CREATE TABLE mytest AS SELECT name, age FROM test;
注意:CTAS 操作是原子的,因此如果 select 查询由于某种原因而失败,新表是不会创建的!
1.3、Insert 导出数据
语法结构:
# 单模式导出:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement;
# 多模式导出:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...;
具体实例:
(1)导出数据到本地:
insert overwrite local directory '/home/hadoop/student.txt' select * from studentss;

注意:数据写入到文件系统时进行文本序列化,且每列用 ^A 来区分,\n 为换行符。用 more 命令查看时不容易看出分割符,可以使用: sed -e 's/\x01/\t/g' filename 来查看。
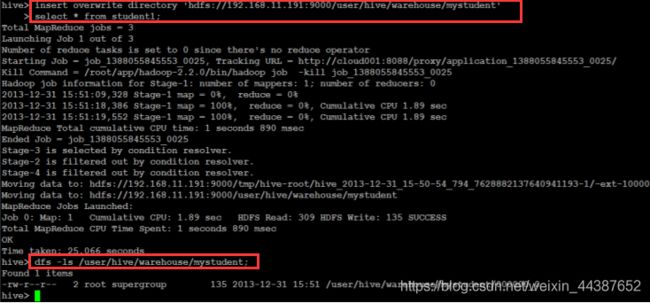
(2)导出数据到 HDFS:
insert overwrite directory '/student' select * from studentss where age >= 20;
insert overwrite directory 'hdfs://hadoop02:9000/user/hive/warehouse/mystudent' select * from studentss;
1.4、Select 查询数据
Hive 中的 SELECT 基础语法和标准 SQL 语法基本一致,支持 WHERE、DISTINCT、GROUP BY、ORDER BY、HAVING、LIMIT、子查询等;
1、select * from db.table1;
2、select count(distinct uid) from db.table1;
3、支持 select、union all、join(left、right、full join)、like、where、having、各种聚合函数、支持 json 解析;
4、支持 UDF(User Defined Function)/ UDAF/UDTF;
5、不支持 update 和 delete;
6、hive 虽然支持 in/exists(老版本是不支持的),但是 hive 推荐使用 semi join 的方式来代替实现,而且效率更高。
7、支持 case … when …。
语法结构:
SELECT [ALL | DISTINCT] select_ condition, select_ condition, ...
FROM table_name a
[JOIN table_other b ON a.id = b.id]
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list | ORDER BY col_list] ]
[LIMIT number]
关键字说明:
(1)select_ condition 查询字段。
(2)table_name 表名。
(3)order by(字段) 全局排序,因此只有一个 reducer,只有一个 reduce task 的结果,比如文件名是 000000_0,会导致当输入规模较大时,需要较长的计算时间。
(4)sort by(字段) 局部排序,不是全局排序,其在数据进入 reducer 前完成排序。因此,如果用 sort by 进行排序,并且设置 mapred.reduce.tasks>1,则 sort by 只保证每个 reducer的输出有序,不保证全局有序。
那万一,我要对我的所有处理结果进行一个综合排序,而且数据量又非常大,那么怎么解决?我们不适用 order by 进行全数据排序,我们适用 sort by 对数据进行局部排序,完了之后,再对所有的局部排序结果做一个归并排序。
(5)**distribute by(字段) **根据指定的字段将数据分到不同的 reducer,且分发算法是 hash 散列。
(6)**cluster by(字段) **除了具有 Distribute by 的功能外,还会对该字段进行排序。
因此,如果分桶和 sort 字段是同一个时,此时 cluster by = distribute by + sort by ,如果我们要分桶的字段和要排序的字段不一样,那么我们就不能使用 clustered by。
分桶表的作用:最大的作用是用来提高 join 操作的效率;
(思考这个问题:如果下例查询语句中 a 表和 b 表已经是分桶表,而且分桶的字段是 id 字段做这个 join 操作时,还需要全表做笛卡尔积吗?)
select a.id,a.name,b.addr from a join b on a.id = b.id;
具体实例:
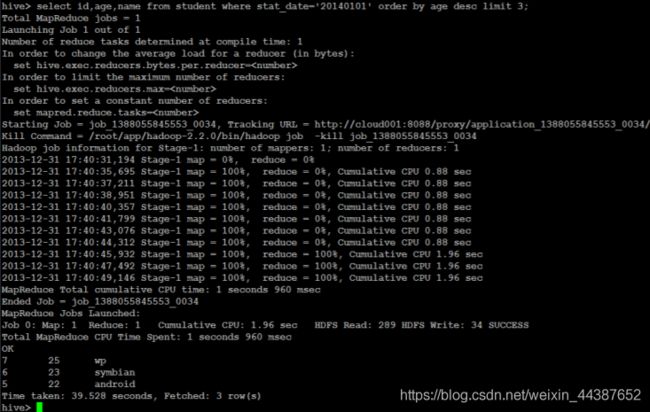
(1)获取年龄大的三个学生:
select id,age,name from student where stat_date= '20140101' order by age desc limit 3;
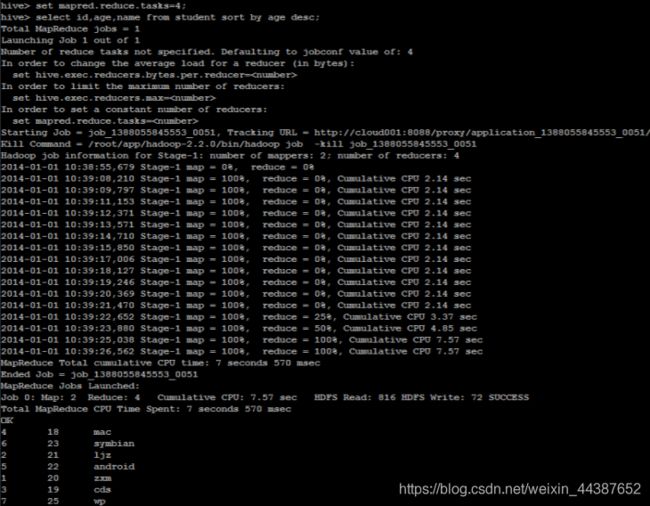
(2)查询学生年龄按降序排序:
set mapred.reduce.tasks=4;
select id, age, name from student sort by age desc;
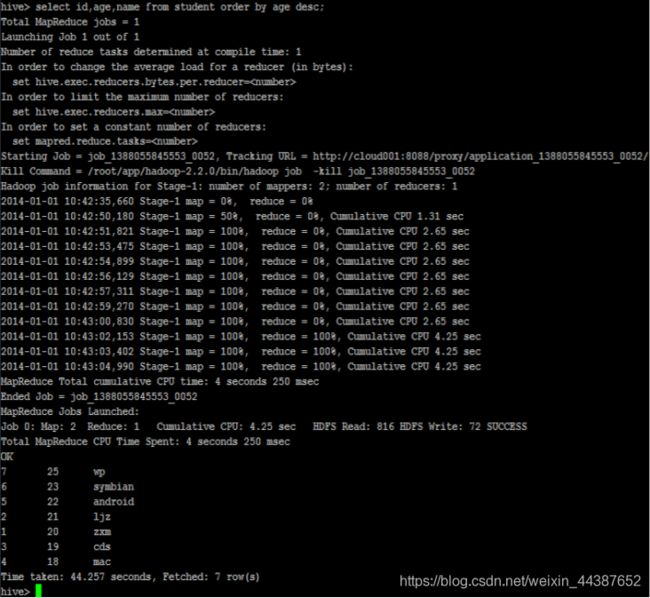
select id, age, name from student order by age desc;
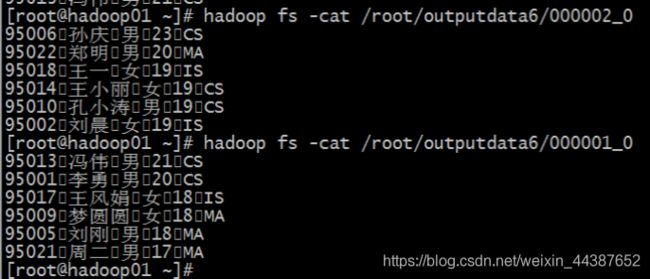
select id, age, name from student distribute by age;

这是分桶和排序的组合操作,对 id 进行分桶,对 age,id 进行降序排序:
insert overwrite directory '/root/outputdata6'
select * from mingxing2
distribute by id
sort by age desc, id desc;
这是分桶操作,按照 id 分桶,但是不进行排序:
insert overwrite directory '/root/outputdata4'
select * from mingxing2
distribute by id
sort by age;
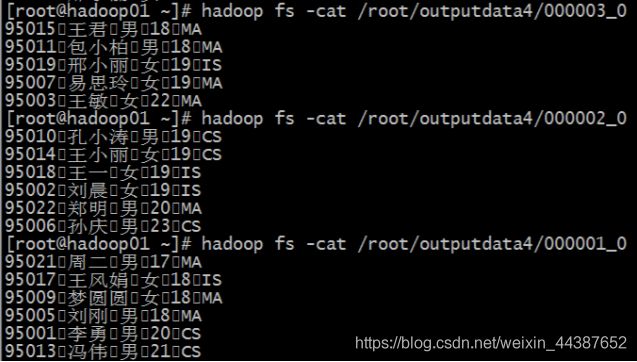
这是分桶操作,按照 id 分桶,并且按照 id 排序:
insert overwrite directory '/root/outputdata3'
select * from mingxing2
cluster by id;
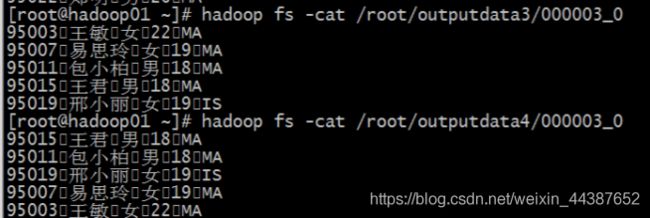
分桶查询:
指定开启分桶:set hive.enforce.bucketing = true; ,在旧版本中需要开启分桶查询的开关。
指定 reducetask 数量,也就是指定桶的数量:
set mapreduce.job.reduces=4;
insert overwrite directory '/root/outputdata3'
select * from mingxing2
cluster by id;
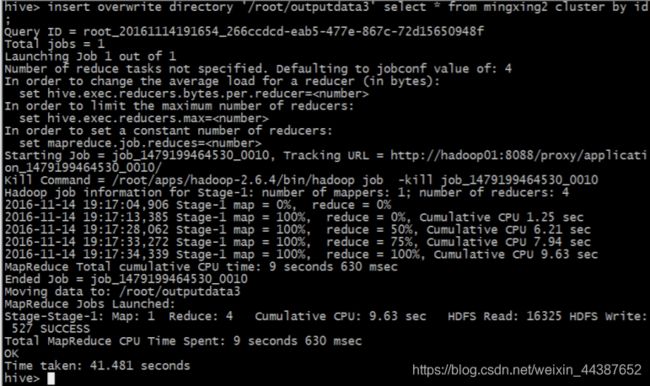
(3)按学生名称汇总学生年龄:
select name, sum(age) from student
group by name;

总结:
(1)解释三个执行参数
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
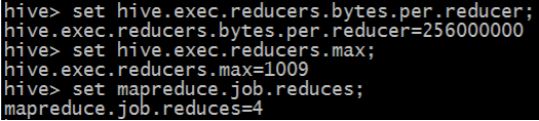
A、直接使用不带设置值得时候是可以查看到这个参数的默认值:
set hive.exec.reducers.bytes.per.reducer
hive.exec.reducers.bytes.per.reducer:一个 hive,就相当于一次 hive 查询中,每一个 reduce 任务它处理的平均数据量。
如果要改变值,我们使用这种方式:
set hive.exec.reducers.bytes.per.reducer=51200000
B、查看设置的最大 reducetask 数量:
set hive.exec.reducers.max
hive.exec.reducers.max:一次 hive 查询中,最多使用的 reduce task 的数量。
我们可以这样使用去改变这个值:
set hive.exec.reducers.max = 20
C、查看设置的一个 reducetask 常量数量:
set mapreduce.job.reduces
mapreduce.job.reduces:我们设置的 reducetask 数量。
(2)HQL 是否被转换成 MR 的问题:
前面说过,HQL 语句会被转换成 MapReduce 程序执行,但是上面的例子可以看出部分 HQL 语句并不会转换成 MapReduce,那么什么情况下可以避免转换呢?
A、select * from student; // 简单读取表中文件数据时不会。
B、where 过滤条件中只是分区字段时不会转换成 MapReduce。
C、set hive.exec.mode.local.auto=true; // hive 会尝试使用本地模式执行。否则,其他情况都会被转换成 MapReduce 程序执行。
1.5、Hive Join 查询
语法结构:
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
Hive 支持等值连接(equality join)、外连接(outer join)和(left/right join)。Hive 不支持非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。另外,Hive 支持多于 2 个表的连接。
写查询时要注意以下几点:
(1)只支持等值链接,支持 and,不支持 or:
例如:
SELECT a.* FROM a JOIN b ON (a.id = b.id);
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department);
是正确的;
然而:
SELECT a.* FROM a JOIN b ON (a.id>b.id);
是错误的。
(2)可以 join 多于 2 个表:
例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
如果 join 中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务,例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1);
被转化为单个 map/reduce 任务,因为 join 中只使用了 b.key1 作为 join key。
例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
而这一 join 被转化为 2 个 map/reduce 任务。因为 b.key1 用于第一次 join 条件,而 b.key2 用于第二次 join。
(3)Join 时,每次 map/reduce 任务的逻辑:
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。**实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。**例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1);
所有表都使用同一个 join key(使用 1 次 map/reduce 任务计算)。Reduce 端会缓存 a 表和 b 表的记录,然后每次取得一个 c 表的记录就计算一次 join 结果,类似的还有:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
这里用了 2 次 map/reduce 任务:
第一次缓存 a 表,用 b 表序列化;
第二次缓存第一次 map/reduce 任务的结果,然后用 c 表序列化。
(4)HiveJoin 分三种:inner join, outer join, semi join:
其中:outer join 包括 left join,right join 和 full outer join,主要用来处理 join 中空记录的情况。
具体实例操作:
(1)创建两张表:
create table tablea (id int, name string) row format delimited fields terminated by ',';
create table tableb (id int, age int) row format delimited fields terminated by ',';

2、 准备数据:
先准备两份数据,例如:
tablea 表数据:
1,huangbo
2,xuzheng
4,wangbaoqiang
6,huangxiaoming
7,fengjie
10,liudehua
tableb 表的数据:
2,20
4,50
7,80
10,22
12,33
15,44

(3)分别导入数据 a.txt 到 tablea 表,b.txt 到 tableb 表:
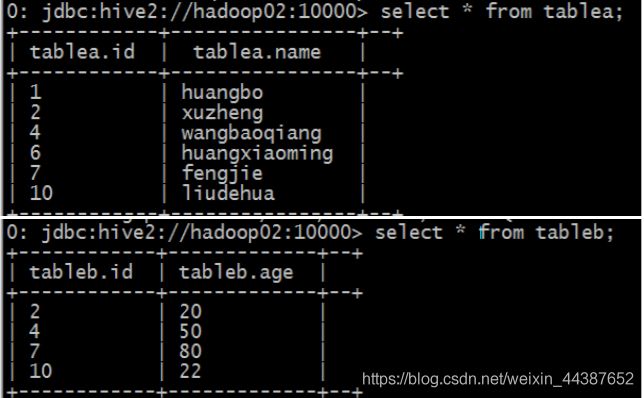
(4)数据准备完毕:
load data local inpath '/home/hadoop/a.txt' into table tablea;
load data local inpath '/home/hadoop/b.txt' into table tableb;
(5)Join 演示:
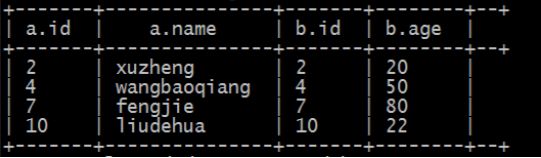
A、inner join(内连接)(把符合两边连接条件的数据查询出来):
select * from tablea a
inner join tableb b
on a.id=b.id;
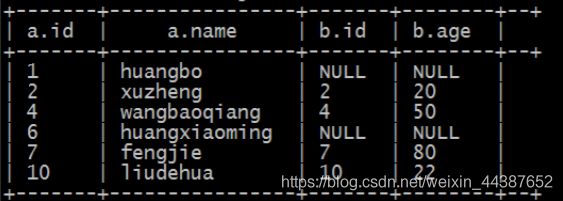
B、left join(左连接,等同于 left outer join):
(1)以左表数据为匹配标准,左大右小;
(2)匹配不上的就是 null;
(3)返回的数据条数与左表相同。
HQL 语句:
select * from tablea a
left join tableb b
on a.id=b.id;
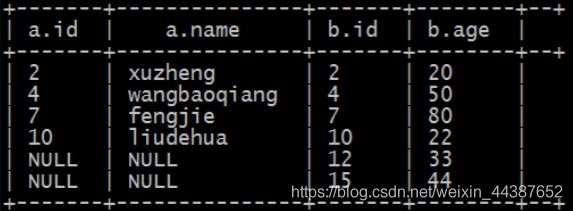
C、right join(右连接,等同于 right outer join):
(1)以右表数据为匹配标准,左小右大;
(2)匹配不上的就是 null;
(3)返回的数据条数与右表相同。
HQL 语句:
select * from tablea a
right join tableb b
on a.id=b.id;
D、left semi join(左半连接):
(因为 hive 不支持 in/exists 操作(1.2.1 版本的 hive 支持 in 的操作),所以用该操作实现,并且是 in/exists 的高效实现)
select * from tablea a
left semi join tableb b
on a.id=b.id;
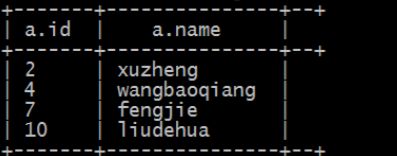
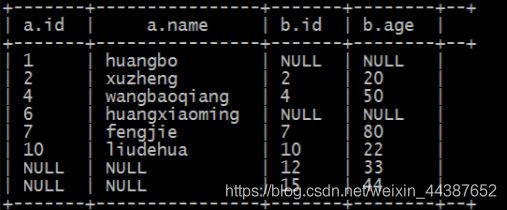
E、full outer join(完全外链接):
select * from tablea a
full outer join tableb b
on a.id=b.id;
2、学习内容
上节学习内容:Hive 基本操作(一)DDL操作
下节学习内容:Hive 高级操作(一)之数据类型(原子,array,map,struct,union)