深入理解Aarch64内存管理
本文介绍了AAR64内存管理中最重要的内容--内存转换,解释了虚拟地址是如何翻译为物理地址的,翻译表的格式,以及如何管理TLBS。
什么是内存管理
内存管理描述了如何控制操作性系统对内存的访问。每次操作系统或应用程序访问内存时,硬件都会进行内存管理。内存管理是一种给应用程序动态分配内存区域的方法。
处理器是用来运行复杂系统的,比如Linux 支持虚拟内存系统。软件在操作系统上运行只能看到虚拟地址,而处理器负责把虚拟地址转换为物理地址。这些物理地址最终都会被内存系统转换为实际的物理位置。
虚拟地址和物理地址
使用虚拟地址的好处是它允许对软件进行管理,比如操作系统可以控制内存以什么样的方式呈现给应用程序。操作系统可以控制那些内存是可见的,控制该内存可见的虚拟地址以及允许对该内存那些区域进行访问。这就可以实现操作系统对应用程序的沙箱管理(对另一个应用程序隐藏一个应用程序的资源),并且提供对底层的硬件抽象。
使用虚拟地址的另一个好处是操作系统可以将多个零散的物理内存区域组织为单个连续的虚拟地址空间呈现给应用程序。
虚拟地址也有利于软件开发人员,软件开发人员编写应用程序时不需要关心物理内存。应用程序知道,物理内存转换为虚拟内存由操作系统和硬件共同完成。
实际上,每个应用程序都可以使用自己的一组虚拟地址。这些虚拟地址将映射到物理系统中的不同位置。当操作系统在不同的应用程序之间切换的时候,它会重新组织物理地址和虚拟地址的映射关系。这就意味着不同的应用程序都会映射到正确的物理位置。
虚拟地址通过映射关系转换为物理地址。虚拟地址和物理地址之间的映射关系存储在转换表(有时称为页表)中,如下图所示:
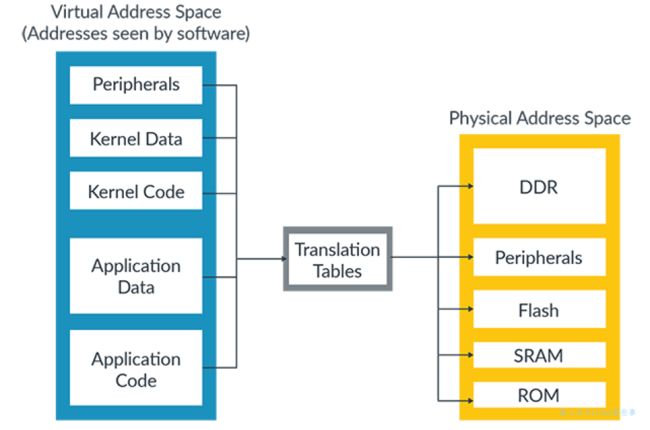
翻译表在内存中由操作系统或者hypervisor管理,转换表不是静态的,它可以随着软件变化的需要而更新表。因为不同软件的物理地址是不同的,所以这就会改变虚拟地址和物理地址之间的映射关系。
内存管理单元
内存管理单元(MMU)负责把软件使用的虚拟地址转换为内存系统使用的物理地址。MMU组成如下:
- Table wake unit,从内存中读出翻译表的逻辑。
- TLBs,近期使用的翻译表的缓存。
软件使用的所有地址都是虚拟地址,这些地址会传递给MMU,MMU在TLB中检查这些地址是否存在。如果在TLB中没有找到,Table wake unit会从内存中读取适当的table entry(一个或多个),如下所示:
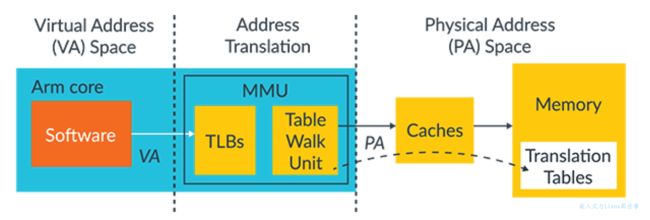
在进行内存访问时,虚拟地址必须被转换为物理地址。这种转换需求也适用于缓存数据,因为在 Armv6 和更高版本的处理器上,数据缓存(DCACHE)使用物理地址(物理标记的地址)存储数据。因此,必须先翻译地址,然后才能完成高速缓存查找。
Table entry
翻译表的工作原理是把虚拟地址空间划分为同等大小的块。并且每个块在表中提供一个entry。
表中的entry 0映射到块0,entry1映射到块1,依此类推。每个entry都包含对应物理内存块的地址以及访问物理地址时要使用的属性。
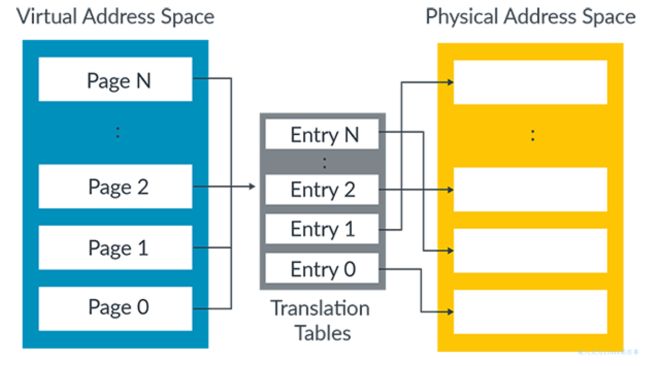
Table lookup
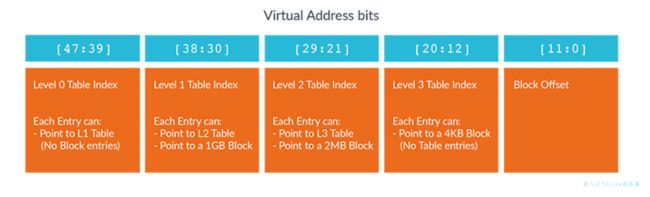
当虚拟地址转换为物理地址时,就会去查表,虚拟地址会被分为两部分:
下图展示了一级页表查找过程。
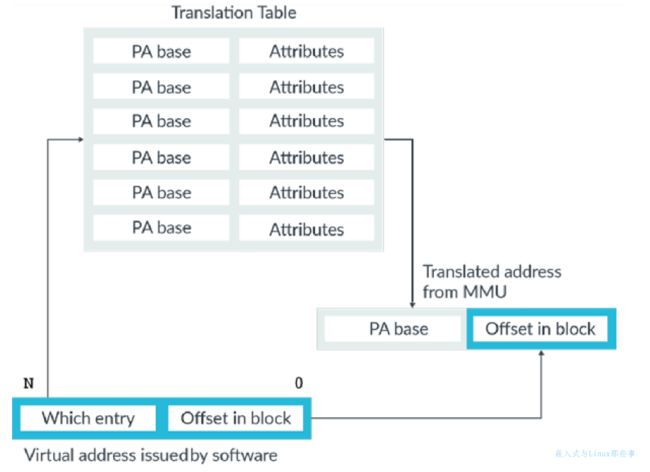
图中标有“which entry”的高位表明要查看那个块的entry,在表中搜索时被用作索引。此entry是虚拟地址对应的物理地址。图中标记为“offset in block”的是该块内的偏移量,虚拟地址与物理地址的offset是一一对应的,不会因为发生转换而改变。
Multilevel translation
在单级lookup中,虚拟地址空间被分成大小相等的块。而在实际中,使用最多的是多级页表。
第一级页表将虚拟地址划分为大块,表中的每个entry都可以指向一个相同大小的物理内存块,或者指向下一级页表,下一级页表中将表将细分更小的块。我们称这种类型的表为“多级页表”。
下图是一个三级页表的例子:
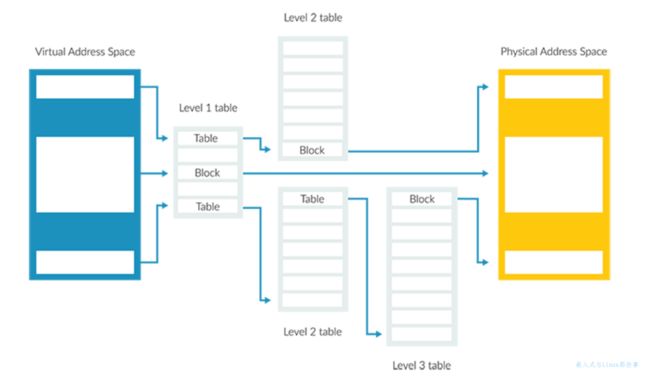
在 Armv8-A 中,最大级别数为 4,级别编号为 0 到 3。这种多级方法允许使用更大的块和更小的块。大块和小块的特点如下:
- 与小块相比,大块在在转译时需要的级别更少,在TLB中缓存效率更高。
- 小块为软件提供了对内存分配的细粒度控制。然而,小块在 TLB 中的缓存效率较低。缓存效率较低是因为小块需要通过多级进行多次读取才能转译。
为了管理这种权衡,操作系统必须平衡使用大块映射的效率与使用小块映射的灵活性来获得最佳性能。处理器在开始查表时不知道转译的大小,它通过执行 table walk 计算出正在转换的块的大小。
地址空间
AArch64 中有几个独立的虚拟地址空间。此图显示了这些虚拟地址空间:
- Non-secure EL0 and EL1
- Non-secure EL2
- EL3
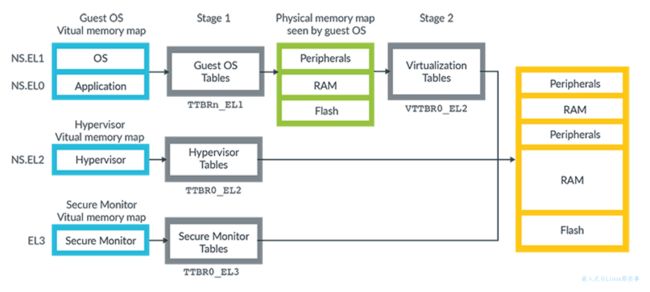
这些虚拟地址空间中的每一个都是独立的,并且有自己的setting和table。我们经常将这些setting和table称为“translation regimes”。 Secure EL0、Secure EL1 和 Secure EL2 也有虚拟地址空间,但图中未显示。
因为有多个虚拟地址空间,所以指定一个地址在哪个地址空间很重要。例如NS.EL2:0x8000指的是Non-secure EL2虚拟地址空间中的地址0x8000。
该图还表明NS-EL0 和NS-EL1 的虚拟地址会使用两组table。这些table支持虚拟化并允许hypervisor将虚拟机看到的物理地址虚拟化。
Armv9-A 支持上述 Armv8-A 的所有虚拟地址空间。 Armv9-A 引入了可选的RME。实现RME时,还存在其他转译机制:
- Realm EL1和EL0
- Realm EL2和EL0
- Realm EL2
在虚拟化中,我们将操作系统控制的翻译称之为stage1,stage1将虚拟地址转换为中间物理地址(IPA)。在stage1,操作系统认为 IPA 是物理地址空间。但是,hypervisor控制第二组转换,我们称之为stage2。stage2转换将 IPA 转换为物理地址。下图显示了两组翻译的工作原理:
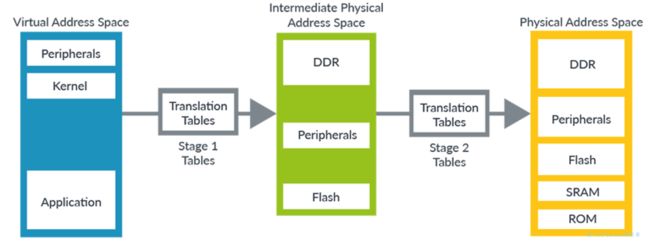
虽然table格式有一些细微差别,但 Stage 1 和 Stage 2 翻译的过程通常是相同的。
在Arm,我们在许多例子中都使用了0x8000这个地址。0x8000也是 用Arm链接器armlink进行链接的默认地址。这个地址来自于 早期的微型计算机,BBC Micro Model B,它的ROM的地址为 地址为0x8000。BBC Micro Model B是由一家名为 Acorn的公司,该公司开发了Acorn RISC Machine(ARM),后来成为Arm。
物理地址
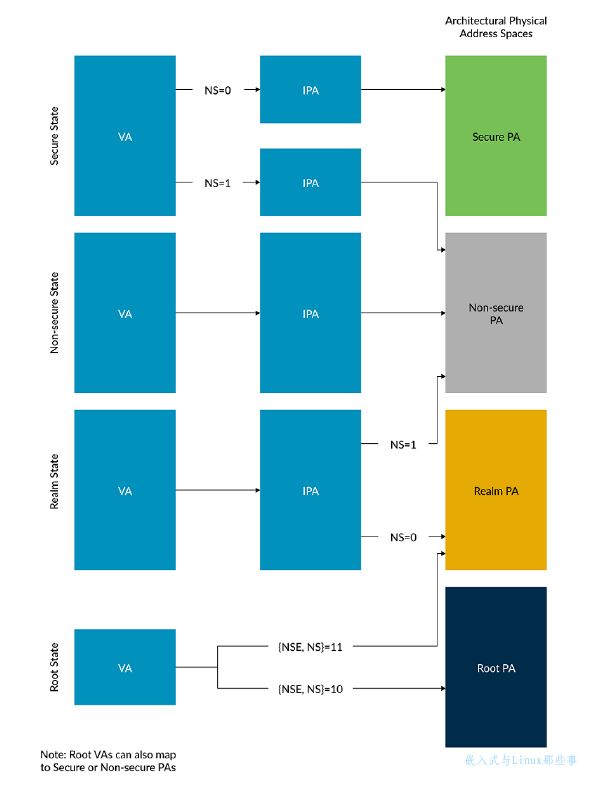
除了多个虚拟地址空间,AArch64 还有多个物理地址空间(PAS):
- Non-secure PAS0
- Secure PAS
- Realm PAS (Armv9-A only)
- Root PAS (Armv9-A only)
虚拟地址可以映射到哪一个或哪几个物理地址空间取决于 处理器的当前安全状态。下面的列表显示了安全状态和其
对应的虚拟地址映射目的地。
- Non-secure state:虚拟地址只能映射到非安全的物理地址
- Secure state:虚拟地址可以映射到安全的/非安全的物理地址
- Realm state:虚拟地址可以映射到Realm 和非安全的物理地址
- Root state:虚拟地址可以映射到任何物理地址
当处于具有多个物理地址空间可见性的安全状态时,转换表entry控制哪个物理地址空间被使用。下图展示了多个物理地址空间的映射关系:
地址大小
AArch64 是 64 位架构,但这并不意味着所有地址都是 64 位的。虚拟地址以 64 位格式存储。因此,加载指令 (LDR) 和存储指令 (STR) 中的地址始终在由X 寄存器指定。但是,并非 X 寄存器中的所有地址都有效。下图显示了 AArch64 中虚拟地址空间的布局:
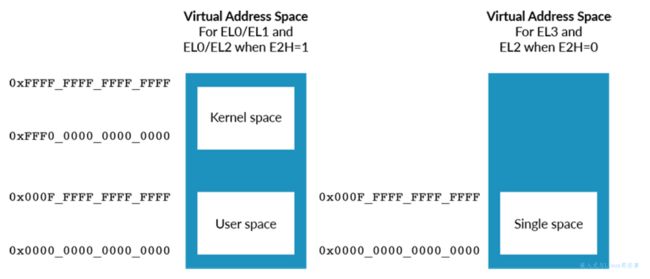
如左图所示,EL0/EL1的虚拟地址空间有两个区域:内核空间和用户空间。内核空间在顶部,用户空间在底部。内核空间和用户空间有各自单独的转换表。
如右图所示,其他所有异常级别的地址空间在底部有一块单独的区域。
每个区域的地址空间的大小最多为52位。然而,每个区域都可以独立地缩小。TCR_ELx寄存器中的TnSZ字段控制虚拟地址空间的大小。例如,该图显示TCR_EL1控制EL0/EL1 虚拟地址空间。
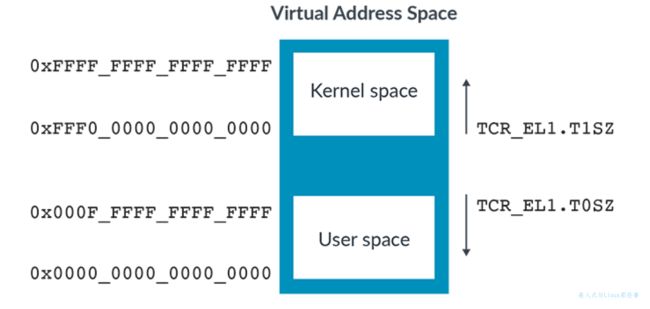
虚拟地址被设置为264-TCR_ELx.TnSZ。虚拟地址的大小也可以用地址位数来表示:64 - TnSZ。
因此,如果TCR_EL1.SZ1设置为32,则 EL0/EL1 虚拟地址空间中内核区域的大小为 2的32次方个字节(0xFFFF_FFFF_0000_0000 到 0xFFFF_FFFF_FFFF_FFFF)。当访问超出超出配置范围的虚拟地址的空间时,会被当作翻译错误。
这种配置的好处是我们只需要描述尽可能多的我们想要使用的地址空间,这样可以节省时间和空间。
例如,假设操作系统内核需要 1GB 的地址空间(30 位地址大小)作为其内核空间。如果操作系统将 T1SZ 设置为 34,描述 1GB 的转换表entry被创建,因为64 - 34 = 30。
物理地址大小
物理地址的大小是可以自定义的,最大可支持到52位。ID_AA64MMFR0_EL1 寄存器规定了处理器实现的大小。对于 Arm Cortex-A 处理器,这通常是 40 位或 44 位。
对于Armv8.0-A,物理地址最大为48位。Armv8.2-A中最大为52位。
中间物理地址(IPA)的大小
如果你在翻译表项(translation table entry)中指定的输出地址大于实际的最大值,内存管理单元(MMU)将产生一个异常,即地址大小错误。IPA空间的大小可以用与虚拟地址空间相同的方式进行配置。
VTCR_EL2.T0SZ寄存器可以设置的最大值与处理器支持的物理地址大小相同。这意味着不能配置比支持的物理地址空间更大的 IPA 空间。
地址空间标识-标记进程
许多现代操作系统的应用程序似乎都是在同一个地址区运行的,这就是我们所说的用户空间。事实上,不同的应用程序需要不同的映射。这意味着虚拟地址0X8000的转换取决于当前运行的应用程序。
理想情况下,我们希望不同应用程序的转译能在转译缓冲区(TLB)内共存。以防止在上下文切换时影响性能。但是处理器如何知道要使用哪个版本的 VA 0x8000 转换呢?在 Armv8-A 中,答案是地址空间标识符 (ASID)。
对于EL0/EL1虚拟地址空间,可以使用转译表entry属性字段中的nG位将转译标记为全局(G)或非全局(nG)。例如,内核映射是全局转译,而应用程序映射是非全局转译。全局转译适用于当前正在运行的任何应用程序。非全局转译只适用于一个特定的应用程序。
非全局映射在 TLB 中使用 ASID 进行标记。在TLB中搜索时,TLB entry 中的ASID 与当前选择的 ASID 进行比较。如果它们不匹配,则不使用 TLB 条目。下图显示了内核空间中没有 ASID 标记的全局映射和用户空间中具有 ASID 标记的非全局映射:
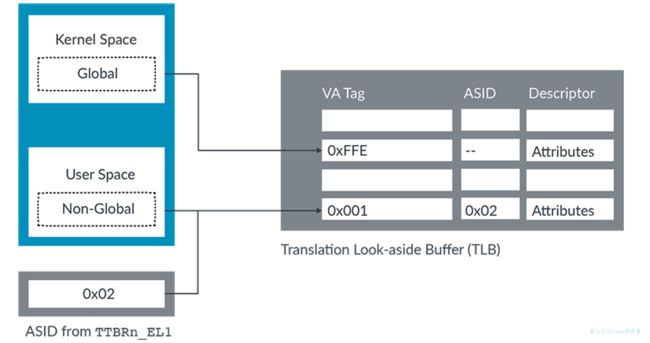
图中显示,多个应用程序的TLB条目被允许在缓存中共存。而ASID决定使用哪个条目。
ASID被存储在两个TTBRn_EL1寄存器中的一个。通常,TTBR0_EL1用于用户空间。因此,单个寄存器更新可以同时更改 ASID 和它指向的转换表。
虚拟机标识-使用拥有的虚拟机来标记翻译
EL0/EL1转换也可以用虚拟机标识符(VMID)进行标记。VMID 允许来自不同 VM 的转译在缓存中共存。这类似于 ASID 为来自不同应用程序的在翻译工作的方式。实际上,这意味着某些转换将同时使用 VMID 和 ASID 进行标记,并且两者都必须匹配才能使用 TLB entry。
当安全状态支持虚拟化时,EL0/EL1转换总是被标记为VMID--即使Stage 2转换没有被启用。这意味着,如果你正在编写初始化代码,并且没有使用hypervisor,那么在设置Stage 1 MMU之前设置一个已知的VMID值是很重要的。
Common not Private
如果一个系统包括多个处理器,在一个处理器上使用的ASIDs和VMIDs在其他处理器上是否有相同的意义?
对于 Armv8.0-A,答案是它们的含义不一定相同。软件不需要在多个处理器上以相同的方式使用给定的 ASID。例如,ASID 5 可能由一个处理器上的计算器和另一个处理器上的 Web 浏览器使用。这意味着由一个处理器创建的 TLB entry不能被另一个处理器使用。
实际上,软件不太可能在处理器之间以不同的方式使用 ASID。软件在给定系统中的所有处理器上以相同方式使用 ASID 和 VMID 更为常见。因此,Armv8.2-A 在转换表基址寄存器 (TTBR) 中引入了 Common not Private (CnP) 位。当设置 CnP 位时,软件承诺在所有处理器上以相同的方式使用 ASID 和 VMID,这允许由一个处理器创建的 TLB 条目被另一个处理器使用。
转换表格式
在这里,我们可以看到翻译表entry允许的不同格式。

每个entry是 64 位,低两位确定entry的类型。
请注意,某些table entry仅在特定级别有效。table的最大级别数是四级,这就是为什么没有level3(或第四级)表的表描述符的原因。同样地,第0级也没有块描述符或页描述符。因为第0级 entry覆盖了很大的虚拟地址空间区域,因此在level0允许块是没有意义的。
转换粒度
转换粒度是可以描述的最小的内存块。AArch64 支持三种不同的粒度大小:4KB、16KB 和 64KB。
处理器支持的粒度是自定义的并由 ID_AA64MMFR0_EL1 保存。所有Arm Cortex-A处理器都支持4KB和64KB。选择的粒度是最高level table中描述的大小。
一个处理器所支持的粒度大小是ID_AA64MMFR0_EL1定义的,所有Arm Cortex-A处理器都支持4KB和64KB。选择的颗粒是可以在最新级别表中描述的最小块。也可以描述更大的块。此表显示了基于所选粒度的每个级别表的不同块的尺寸:

在 Armv9.2-A 和 Armv8.7-A 推出之前,使用 52 位地址是有限制的。当所选颗粒为4KB或16KB时,最大虚拟地址大小为48位。同样,输出物理地址限制为 48 位。只有在使用 64KB 颗粒时,才能使用完整的 52 位。
地址转换的初始level
虚拟地址空间的粒度和大小共同控制地址转换的起始级别。
上表总结了每个级别表中每个粒度的块大小(单个entry覆盖的虚拟地址范围的大小)。从块的大小,你可以算出虚拟地址的哪些位是用来索引每一级表的。
让我们以4KB的粒度为例。这张图显示了用于索引4KB粒度的 不同级别表的索引。
如图所示,将TCR_ELx.T0SZ设置为32,以地址为单位的虚拟地址空间的大小计算方式如下:64 - T0SZ = 32-bit
从之前的4KB配置的粒度图中可以看出,level0是47:39位索引的。这些在32位地址空间是不存在的。因此,地址翻译是从level1开始的。
接着,假设设置T0SZ为34:64 - T0SZ = 30
这一次,不存在level0 和level1的索引。因此,该配置的转译起始级别是level2。
当虚拟地址空间的大小减少时,您需要更少级别的表来描述它。这些示例基于使用 4KB 粒度。当使用 16KB 和 64KB 颗粒时,同样的原理也适用,但地址位会发生变化。
控制地址转换的寄存器
地址转换由系统寄存器组合来控制:
- SCTLR_ELx
M:使能MMU
C:使能Dcache
- TTBR0_ELx and TTBR1_ELx
BADDR:转译表物理地址/中间物理地址的起点
ASID:非全局转译的标识符
- TCR_ELx
PS/IPS:物理地址/中间物理地址的大小。
TnSZ:转译表能表示的地址空间的大小
TGn:粒度大小
SH/IRGN/ORGN:缓存能力共享能力的使能
TBIn:禁止搜索table中的某一行
- MAIR_ELx
Attr:statge1 的类型和缓存能力控制
关闭MMU
当MMU被禁用时,所有的地址都是平行映射的。即物理地址和虚拟地址是一一对应的。
维护TLB
Translation Lookaside Buffers (TLB) 缓存最近使用的转译项。此缓存允许后续查找重复使用转译,而无需重新读取table。
如果要更改转换表entry或控制entry的解释方式,则需要使 TLB 中受影响的entry无效。如果不使这些entry无效,则处理器可能会继续使用旧的转译。
处理器不允许导致以下任何故障的翻译缓存到 TLB:
- 翻译错误(未映射的地址)
- 地址大小错误(超出地址范围)
- 非法访问
因此,在第一次映射地址时,你不需要让TLB 无效。然而,如果要做以下操作,需要让TLB失效:
- Unmap an address:将有效的地址标记为无效
- 改变映射关系:将地址权限从只读改为读写。
- 改变table 的转译方式:修改粒度大小时,table的转译方式也会改变。
TLB操作的格式
TLBI 指令用于使 TLB 中的entry无效。该指令的语法是
TLBI < type >< level >{IS|OS} {, < xt >}
-
< type >:指定无效的entries
- All - 所有entries
- VA - Entry matching VA and ASID in Xt
- VAA - Entry matching VA in Xt, for any ASID
- ASID - Any entry matching the ASID in Xt
-
< level >: 操作哪一个地址空间
- E1 = EL0/1 virtual address space
- E2 = EL2 virtual address space
- E3 = EL3 virtual address space
-
< IS|OS >内部共享还是外部共享
-
< Xt >:操作那个地址或者ASID
例如,一个正在更新其内核转换表中entry的操作系统 (OS)。典型的 TLB 无效序列如下所示:

地址翻译指令
地址转换指令(AT)可以查询特定地址的转换。地址翻译的结果,属性会写入物理寄存器PAR_EL1。
AT指令的语法具有优先级。例如,EL2指令可以查询EL0/EL1的翻译表,但是EL1指令不能查询EL2的。
总结
下面对本文内容做个简单总结,以下这些问题是我们要明白的。
- 地址翻译中,statge和level有什么区别?
statge 指的是把输入地址转换为输出地址的过程。对于stage1,就是从VA到IPA的过程。stage2 从IPA到PA的过程。
level指的是翻译给定阶段的table,将一个大块划分为小块的过程。
- 物理地址最大是多少?
物理地址大小由IMPLEMENTATION DEFINED定义,在ARMV8.2-A后为52位。
- 虚拟地址大小由哪些寄存器控制?
stage2的TCR_ELx.TnSZ, or VTCR_EL2.T0SZ
- 翻译粒度是什么?支持的大小是多少?
翻译粒度指的是内存可以描述的最小的块。支持4KB, 16KB, and 64KB.
- TLBI ALLE3 作用是什么?
EL3虚拟地址中使所有的TLB entries无效。
- 发生翻译错误时的翻译表项能缓存在TLB中吗?
不能
- 当MMU关闭时,地址是如何映射的?
平行映射,即输入地址和输出地址相同。
- 什么是ASID?什么时候TLB entry会包含ASID?
ASID是地址空间标识符,它标识了翻译与那个应用相关联。非全局映射(nG=1)在在TLB中被标记为一个ASID。