爬取《中国医生》影评分析可视化
暑假在家闲着,因为疫情复发了,就只能待在家。在网上看着词云图挺好玩的,然后自己就想着整一个中国医生的影评词云图玩玩。好家伙,就这样开始了一段“奇妙的旅程”。

首先实现写爬虫来将自己想要的数据爬取下来。网址:豆瓣电影
写爬虫不是什么问题,因为写过很多了,这其中唯一遇到的问题就是写入csv文件时出了点问题,就是我将csv写入操作写在了爬虫里面,但是无论我怎么调试,每一次都会将表头再次写入,这样就会影响之后的步骤。于是几经调试,我将表头单独在外面写了一次,在内部的时候就不用再写表头。诶,就解决了。
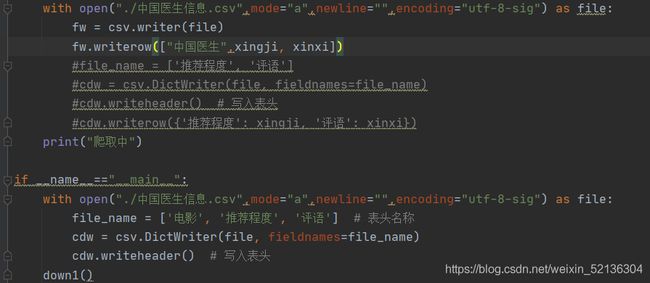
爬取后是下来是这个样子的:

有点奇怪哈,数据相对来说都是比较完整的,需要处理的也很少,于是我就用pandas简单的处理了一下,就开始接下来的数据可视化了。
因为自己是想做一个词云图吗,所以就会用到jieba库,于是我先看了一下大概最多的一些分词是啥,然后再去除一些没有意义的词,再进行展示:
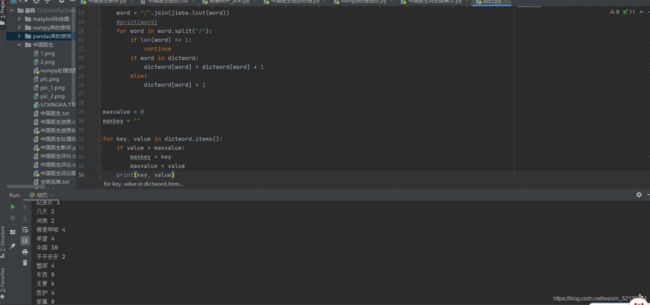
接下来就是做词云图了,我这里用到了一些库,都是自己没学过的。没办法呀,为了自己能够更好的去理解,所以都是花了好几天的时间去重头学的。
下面是代码:
import jieba
import wordcloud as wc
from matplotlib import pyplot as plt
from PIL import Image
import numpy as np
plt.rcParams["font.sans-serif"] = ["SimHei"]
with open("./中国医生信息.csv", "r", encoding="utf-8") as f:
t = f.read()
t = t.replace("推荐","").replace("力荐","").replace("还行","").replace("较差","").replace("一般","").replace("的","").replace("我","").replace("了","").replace("都","").replace("是","").replace("也","").replace("就","").replace("但","").replace("电影","").replace("没有","")
# 分词
t = jieba.lcut(t)
# wordcloud库要用空格分割
t = " ".join(t)
# 将图片转为多维数组,忽略白色部分
mask = np.array(Image.open("2.png"))
#print(t)
f.close()
fig = plt.figure(figsize=(20, 20), dpi=300))
# 中文设置字体样式,不然无法显示中文 , background_color="blue"设置背景颜色
w = wc.WordCloud(font_path="STXINGKA.TTF",mask=mask)
# 要转换成字符串类型,然后生成词云图
w.generate(str(t))
#w.to_file("pic_2.png")
plt.title("中国医生评论热词")
plt.imshow(w)
plt.show()
这里的去除不要的词我就是用的替换,肯定还有别的方法,只是说替换我更熟悉而已。其中的字体路径我是复制到和py文件一个目录下的。电脑字体的路径一般都是在C:\Windows\Fonts这个路径下。
运行结果如下:
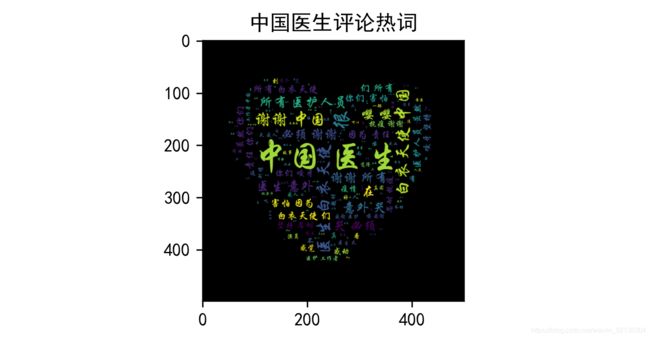
诶,到这词云图就做好了。但是我看到我还爬取了对电影的推荐指数,于是乎我又想到做一个推荐程度占比图。话不多说,直接上代码:
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["font.size"] = 20
df = pd.read_csv("中国医生信息.csv")
# 显示相关的信息
df1 = df[df["推荐程度"] == "还行"]
df2 = df[df["推荐程度"] == "力荐"]
df3 = df[df["推荐程度"] == "较差"]
df4 = df[df["推荐程度"] == "推荐"]
#print(len(df1))
x = [len(df1), len(df2), len(df3), len(df4)]
labels = ["还行", "力荐", "较差", "推荐"]
plt.pie(x, labels=labels, autopct="%.2f%%", explode=[0.1, 0.1, 0.1, 0.1])
plt.title("推荐程度占比图")
plt.show()
这里的df1、df2、df3的意思是满足这个条件的信息,将其打印出来便是这样的:
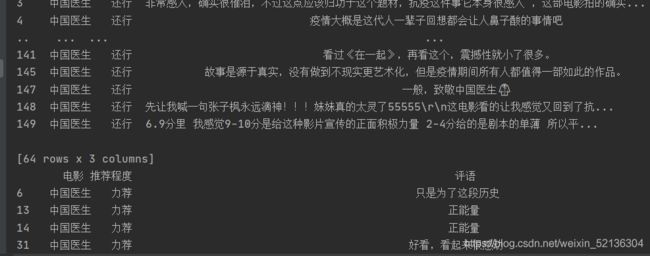
所以我就直接将其转为长度来传入x中进行绘图,我以为可能会报错的。诶,结果没有报错直接成功啦!不错不错,哈哈。下面是运行结果:
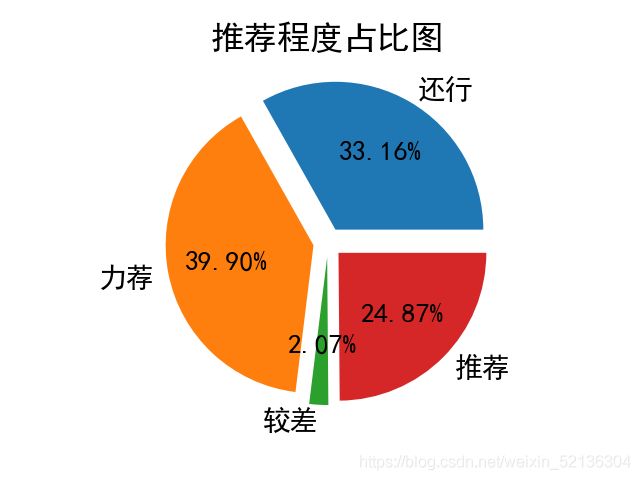
整了好多天终于把这玩意儿给弄完了。说实话,弄这个之前真的有点茫然,不止从何下手。于是就上网查,会涉及到哪些知识点,好家伙,涉及到的还真不少。于是就挨个去学,唉,毫无疑问自学是个痛苦的过程,其中遇到问题了,就使劲扣脑袋,使劲查资料,慢慢的去解决,还好,都一一搞定了。过程很痛苦,但是结果很nice啊!不知不觉又学到了好多东西,真的很不错!
作为一个学生,就是该不断地进取,不断地去磨练,努力丰富自己,然后不断地成长!
道路还很漫长,但我会永远记住:吾将上下而求索!
