opencv_createsamples、opencv_traincascade的使用
转载出处:http://blog.csdn.net/wuxiaoyao12/article/details/39227189
一、基础知识准备
首先,opencv目前仅支持三种特征的训练检测, HAAR、LBP、HOG,选择哪个特征就去补充哪个吧。opencv的这个训练算法是基于adaboost而来的,所以需要先对adaboost进行基础知识补充啊,网上一大堆资料,同志们速度去查阅。我的资源里也有,大家去下载吧,这些我想都不是大家能直接拿来用的,我下面将直接手把手告诉大家训练怎么操作,以及要注意哪些细节。
二、关于正样本的准备
1、采集正样本图片
因为正样本最后需要大小归一化,所以我在采集样本的时候就直接把它从原图里抠出来了,方便后面缩放嘛,而不是只保存它的框个数和框位置信息(框个数、框位置信息看下一步解释),在裁剪的过程中尽量保持样本的长宽比例一致。比如我最后要归一化成20 X 20,在裁剪样本的时候,我都是20X20或者21X21、22X22等等,最大我也没有超过30X30(不超过跟我的自身用途有关,对于人脸检测这种要保证缩放不变性的样本,肯定就可以超过啦),我资源里也给出可以直接用的裁剪样本程序。
(这里我说错了,根据createsamples.cpp ,我们不需要提前进行缩放操作,它在第3步变成vec时就包含了缩放工作.如果我们是用objectMaker标记样本,程序同时生成的关于每一幅图的samplesInfo信息,直接给第三步用即可。当然,你提前缩放了也没关系,按照第2步操作即可)
2、获取正样本路径列表
在你的图片文件夹里,编写一个bat程序(get route.bat,bat是避免每次都需要去dos框输入,那里又不能复制又不能粘贴!),如下所示:

运行bat文件,就会生成如下dat文件:

把这个dat文件中的所有非图片的路径都删掉,比如上图的头两行,再将bmp 替换成 bmp 1 0 0 20 20,如下:

(1代表个数,后四个分别对应 left top width height,如果我们之前不是把样本裁剪下来的,那么你的这个dat可能就长成这样1. bmp 3 1 3 24 24 26 28 25 25 60 80 26 26,1.bmp是完全的原图啊,你之前的样本就是从这张图上扣下来的)
3、获取供训练的vec文件
这里,我们得利用opencv里的一个程序叫opencv_createsamples.exe,可以把它拷贝出来。针对它的命令输入也是写成bat文件啦,因为cascade训练的时候用的是vec。如下:

运行bat,就在我们得pos文件夹里生成了如下vec文件:

就此有关正样本的东西准备结束。
(vec中其实就是保存的每一个sample图,并且已经统一w、h大小了,如果你想看所有的sample,也可以通过调用opencv_createsamples.exe,使用操作,见附)
三、关于负样本的准备
这个特别简单,直接拿原始图,不需要裁剪抠图(不裁剪还能保证样本的多样性),也不需要保存框(网上说只要保证比正样本大小大哈,大家就保证吧),只要把路径保存下来。同正样本类似,步骤图如下:


至此有关负样本的也准备完成。
四、开始训练吧
这里我们用opencv_traincascade.exe(opencv_haartraining.exe的用法跟这个很相似,具体需要输入哪些参数去看opencv的源码吧,网上资料也有很多,主要是opencv_traincascade.exe比opencv_haartraining.exe包含更多的特征,功能齐全些啊),直接上图:

命令输入也直接用bat文件,请务必保证好大小写一致,不然不予识别参数。小白兔,跑起来~~~

这是程序识别到的参数,没有错把,如果你哪个字母打错了,你就会发现这些参数会跟你预设的不一样啊,所以大家一定要看清楚了~~~~
跑啊跑啊跑啊跑,如下:

这一级的强训练器达到你预设的比例以后就跑去训练下一级了,同志们那个HR比例不要设置太高,不然会需要好多样本,然后stagenum不要设置太小啊,不然到时候拿去检测速度会很慢。
等这个bat跑结束,我的xml文件也生成了。如下:

其实这个训练可以中途停止的,因为下次开启时它会读取这些xml文件,接着进行上次未完成的训练。哈哈~~~~好人性化啊!
训练结束,我要到了我的cascade.xml文件,现在我要拿它去做检测了啊!呼呼~~~~
五、开始检测吧
opencv有个opencv_performance.exe程序用于检测,但是它只能用在用opencv_haartraining.exe来用的,所以我这里是针对一些列图片进行检测的,检测代码如下:
- #include
- #include
- #include
- #include
- #include "wininet.h"
- #include
- #include
- #include
- #pragma comment(lib,"Wininet.lib")
- #include "opencv2/objdetect/objdetect.hpp"
- #include "opencv2/highgui/highgui.hpp"
- #include "opencv2/imgproc/imgproc.hpp"
- #include "opencv2/ml/ml.hpp"
- #include
- #include
- using namespace std;
- using namespace cv;
- String cascadeName = "./cascade.xml";//训练数据
- struct PathElem{
- TCHAR SrcImgPath[MAX_PATH*2];
- TCHAR RstImgPath[MAX_PATH*2];
- };
- int FindImgs(char * pSrcImgPath, char * pRstImgPath, std::list
&ImgList);
- int main( )
- {
- CascadeClassifier cascade;//创建级联分类器对象
- std::list
ImgList;
- std::list
::iterator pImgListTemp;
- vector
rects;
- vector
::const_iterator pRect;
- double scale = 1.;
- Mat image;
- double t;
- if( !cascade.load( cascadeName ) )//从指定的文件目录中加载级联分类器
- {
- cerr << "ERROR: Could not load classifier cascade" << endl;
- return 0;
- }
- int nFlag = FindImgs("H:/SrcPic/","H:/RstPic/", ImgList);
- if(nFlag != 0)
- {
- cout<<"Read Image error ! Input 0 to exit \n";
- exit(0);
- }
- pImgListTemp = ImgList.begin();
- for(int iik = 1; iik <= ImgList.size(); iik++,pImgListTemp++)
- {
- image = imread(pImgListTemp->SrcImgPath);
- if( !image.empty() )//读取图片数据不能为空
- {
- Mat gray, smallImg( cvRound (image.rows/scale), cvRound(image.cols/scale), CV_8UC1 );//将图片缩小,加快检测速度
- cvtColor( image, gray, CV_BGR2GRAY );//因为用的是类haar特征,所以都是基于灰度图像的,这里要转换成灰度图像
- resize( gray, smallImg, smallImg.size(), 0, 0, INTER_LINEAR );//将尺寸缩小到1/scale,用线性插值
- equalizeHist( smallImg, smallImg );//直方图均衡
- //detectMultiScale函数中smallImg表示的是要检测的输入图像为smallImg,rects表示检测到的目标序列,1.1表示
- //每次图像尺寸减小的比例为1.1,2表示每一个目标至少要被检测到3次才算是真的目标(因为周围的像素和不同的窗口大
- //小都可以检测到目标),CV_HAAR_SCALE_IMAGE表示不是缩放分类器来检测,而是缩放图像,Size(30, 30)为目标的
- //最小最大尺寸
- rects.clear();
- printf( "begin...\n");
- t = (double)cvGetTickCount();//用来计算算法执行时间
- cascade.detectMultiScale(smallImg,rects,1.1,2,0,Size(20,20),Size(30,30));
- //|CV_HAAR_FIND_BIGGEST_OBJECT//|CV_HAAR_DO_ROUGH_SEARCH|CV_HAAR_SCALE_IMAGE,
- t = (double)cvGetTickCount() - t;
- printf( "detection time = %g ms\n\n", t/((double)cvGetTickFrequency()*1000.) );
- for(pRect = rects.begin(); pRect != rects.end(); pRect++)
- {
- rectangle(image,cvPoint(pRect->x,pRect->y),cvPoint(pRect->x+pRect->width,pRect->y+pRect->height),cvScalar(0,255,0));
- }
- imwrite(pImgListTemp->RstImgPath,image);
- }
- }
- return 0;
- }
- int FindImgs(char * pSrcImgPath, char * pRstImgPath, std::list
&ImgList)
- {
- //源图片存在的目录
- TCHAR szFileT1[MAX_PATH*2];
- lstrcpy(szFileT1,TEXT(pSrcImgPath));
- lstrcat(szFileT1, TEXT("*.*"));
- //结果图片存放的目录
- TCHAR RstAddr[MAX_PATH*2];
- lstrcpy(RstAddr,TEXT(pRstImgPath));
- _mkdir(RstAddr); //创建文件夹
- WIN32_FIND_DATA wfd;
- HANDLE hFind = FindFirstFile(szFileT1, &wfd);
- PathElem stPathElemTemp;
- if(hFind != INVALID_HANDLE_VALUE)
- {
- do
- {
- if(wfd.cFileName[0] == TEXT('.'))
- continue;
- if(wfd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY || strcmp("Thumbs.db", TEXT(wfd.cFileName)) == 0)
- {
- ;
- }
- else
- {
- TCHAR SrcImgPath[MAX_PATH*2];
- lstrcpy(SrcImgPath, pSrcImgPath);
- lstrcat(SrcImgPath, TEXT(wfd.cFileName));
- lstrcpy(stPathElemTemp.SrcImgPath, SrcImgPath);
- TCHAR AdressTemp[MAX_PATH*2];
- lstrcpy(AdressTemp,pRstImgPath);
- //lstrcat(AdressTemp, TEXT("/"));
- lstrcat(AdressTemp, TEXT(wfd.cFileName));
- lstrcpy(stPathElemTemp.RstImgPath, AdressTemp);
- ImgList.push_back(stPathElemTemp);
- }
- }while(FindNextFile(hFind, &wfd));
- }
- else
- {
- return -1;
- }
- return 0;
- }
- " [-info
]\n"
- " [-img
]\n"
- " [-vec
]\n"
- " [-bg
]\n [-num
- " [-bgcolor
- " [-inv] [-randinv] [-bgthresh
- " [-maxidev
- " [-maxxangle
- " [-maxyangle
- " [-maxzangle
- " [-show [
- " [-w
[cpp] view plain copy
- /*
- * cvCreateTrainingSamples
- *
- * Create training samples applying random distortions to sample image and
- * store them in .vec file
- *
- * filename - .vec file name
- * imgfilename - sample image file name
- * bgcolor - background color for sample image
- * bgthreshold - background color threshold. Pixels those colors are in range
- * [bgcolor-bgthreshold, bgcolor+bgthreshold] are considered as transparent
- * bgfilename - background description file name. If not NULL samples
- * will be put on arbitrary background
- * count - desired number of samples
- * invert - if not 0 sample foreground pixels will be inverted
- * if invert == CV_RANDOM_INVERT then samples will be inverted randomly
- * maxintensitydev - desired max intensity deviation of foreground samples pixels
- * maxxangle - max rotation angles
- * maxyangle
- * maxzangle
- * showsamples - if not 0 samples will be shown
- * winwidth - desired samples width
- * winheight - desired samples height
- */
与1)类似
3)提供 infoname和 vecname时,调用以下操作(这里是我们训练需要的)
[cpp] view plain copy
- /*
- * cvCreateTrainingSamplesFromInfo
- *
- * Create training samples from a set of marked up images and store them into .vec file
- * infoname - file in which marked up image descriptions are stored
- * num - desired number of samples
- * showsamples - if not 0 samples will be shown
- * winwidth - sample width
- * winheight - sample height
- *
- * Return number of successfully created samples
- */
- int cvCreateTrainingSamplesFromInfo( const char* infoname, const char* vecfilename,
- int num,
- int showsamples,
- int winwidth, int winheight )
4)仅vecname时,可以将vec里面的所有缩放后的samples都显示出来
[cpp] view plain copy
- /*
- * cvShowVecSamples
- *
- * Shows samples stored in .vec file
- *
- * filename
- * .vec file name
- * winwidth
- * sample width
- * winheight
- * sample height
- * scale
- * the scale each sample is adjusted to(这个scale与3中的缩放不是一回事,这里仅为了显示而再次缩放)
- */
- void cvShowVecSamples( const char* filename, int winwidth, int winheight, double scale );
- " -data
\n"
- " -vec
\n"
- " -bg
\n"
- " [-bg-vecfile]\n"
- " [-npos
- " [-nneg
- " [-nstages
- " [-nsplits
- " [-mem
- " [-sym (default)] [-nonsym]\n"
- " [-minhitrate
- " [-maxfalsealarm
- " [-weighttrimming
- " [-eqw]\n"
- " [-mode
- " [-w
- " [-h
- " [-bt
- " [-err
- " [-maxtreesplits
- " [-minpos
[cpp] view plain copy
- " -data
\n"
- " -info
\n"
- " [-maxSizeDiff
- " [-maxPosDiff
- " [-sf
- " [-ni
- " [-nos
- " [-rs
- " [-w
- " [-h
- cout << "Usage: " << argv[0] << endl;
- cout << " -data
" << endl;
- cout << " -vec
" << endl;
- cout << " -bg
" << endl;
- cout << " [-numPos
- cout << " [-numNeg
- cout << " [-numStages
- cout << " [-precalcValBufSize
- cout << " [-precalcIdxBufSize
- cout << " [-baseFormatSave]" << endl; //是否按照旧版存xml文件默认false
- // cout << " [-numThreads
- // cout << " [-acceptanceRatioBreakValue
= " << acceptanceRatioBreakValue << ">]" << endl;//这个参数在3.0版本中才出现,默认-1.0
- cascadeParams.printDefaults();
- stageParams.printDefaults();
- for( int fi = 0; fi < fc; fi++ )
- featureParams[fi]->printDefaults();
- cout << " [-stageType <"; //默认BOOST
- for( int i = 0; i < (int)(sizeof(stageTypes)/sizeof(stageTypes[0])); i++ )
- {
- cout << (i ? " | " : "") << stageTypes[i];
- if ( i == defaultStageType )
- cout << "(default)";
- }
- cout << ">]" << endl;
- cout << " [-featureType <{"; //默认HAAR
- for( int i = 0; i < (int)(sizeof(featureTypes)/sizeof(featureTypes[0])); i++ )
- {
- cout << (i ? ", " : "") << featureTypes[i];
- if ( i == defaultStageType )
- cout << "(default)";
- }
- cout << "}>]" << endl;
- cout << " [-w
- cout << " [-h
[cpp] view plain copy
- cout << "--boostParams--" << endl;
- cout << " [-bt <{" << CC_DISCRETE_BOOST << ", "
- << CC_REAL_BOOST << ", "
- << CC_LOGIT_BOOST ", "
- << CC_GENTLE_BOOST << "(default)}>]" << endl; //默认CC_GENTLE_BOOST
- cout << " [-minHitRate
= " << minHitRate << ">]" << endl; //默认0.995
- cout << " [-maxFalseAlarmRate
- cout << " [-weightTrimRate
- cout << " [-maxDepth
- cout << " [-maxWeakCount
[cpp] view plain copy
- cout << " [-mode <" CC_MODE_BASIC << "(default)| " //默认CC_MODE_BASIC
- << CC_MODE_CORE <<" | " << CC_MODE_ALL << endl;
自己看看自己的检测结果咯。效果不好的改进样本,调整训练参数吧~~~嘎嘎
我觉得我写的够白痴,很方便大家直接拿来用。其中一些细节,大家自己琢磨吧~88
附:
1、opencv_createsamples.exe的参数
(createsamples.cpp)
以下1)~4)是按顺序判断,且有且仅有一个
函数内容:读取当前图中所有标记的sample(x,y,w,h),并将其缩放到winwidth、winheight大小,故在这之前的人为缩放操作不需要
2、opencv_haartraining.exe的参数
(haartraining.cpp )
3、opencv_performance.exe参数
(performance.cpp )
4、opencv_traincascade.exe参数说明
——traincascade.cpp
其中cascadeParams.printDefaults();——cascadeclassifier.cpp 如下
通用参数:
-data
目录名,如不存在训练程序会创建它,用于存放训练好的分类器
-vec
包含正样本的vec文件名(由 opencv_createsamples 程序生成)
-bg
背景描述文件,也就是包含负样本文件名的那个描述文件
-numPos
每级分类器训练时所用的正样本数目
-numNeg
每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目
-numStages
训练的分类器的级数。
-precalcValBufSize
缓存大小,用于存储预先计算的特征值(feature values),单位为MB
-precalcIdxBufSize
缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB。内存越大,训练时间越短
-baseFormatSave
这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储
级联参数:
-stageType
级别(stage)参数。目前只支持将BOOST分类器作为级别的类型
-featureType<{HAAR(default),LBP}>
特征的类型: HAAR - 类Haar特征;LBP - 局部纹理模式特征
-w
-h
训练样本的尺寸(单位为像素)。必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致
Boosted分类器参数:
-bt<{DAB,RAB,LB,GAB(default)}>
Boosted分类器的类型: DAB - Discrete AdaBoost,RAB - Real AdaBoost,LB - LogitBoost, GAB - Gentle AdaBoost
-minHitRate
分类器的每一级希望得到的最小检测率(正样本被判成正样本的比例)。总的检测率大约为 min_hit_rate^number_of_stages。可以设很高,如0.999
-maxFalseAlarmRate
分类器的每一级希望得到的最大误检率(负样本被判成正样本的比例)。总的误检率大约为 max_false_alarm_rate^number_of_stages。可以设较低,如0.5
-weightTrimRate
Specifies whether trimming should be used and its weight. 一个还不错的数值是0.95
-maxDepth
弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps)
-maxWeakCount
每一级中的弱分类器的最大数目。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given-maxFalseAlarmRate
类Haar特征参数:
-mode
选择训练过程中使用的Haar特征的类型。 BASIC 只使用右上特征, ALL 使用所有右上特征和45度旋转特征
5、detectMultiScale函数参数说明
该函数会在输入图像的不同尺度中检测目标:
image -输入的灰度图像,
objects -被检测到的目标矩形框向量组,
scaleFactor -为每一个图像尺度中的尺度参数,默认值为1.1
minNeighbors -为每一个级联矩形应该保留的邻近个数,默认为3,表示至少有3次检测到目标,才认为是目标
flags -CV_HAAR_DO_CANNY_PRUNING,利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域;
CV_HAAR_SCALE_IMAGE,按比例正常检测;
CV_HAAR_FIND_BIGGEST_OBJECT,只检测最大的物体;
CV_HAAR_DO_ROUGH_SEARCH,只做粗略检测。默认值是0
minSize和maxSize -用来限制得到的目标区域的范围(先找maxsize,再用1.1参数缩小,直到小于minSize终止检测)
6、opencv关于Haar介绍
(haarfeatures.cpp ——opencv3.0)
Detailed Description
Haar Feature-based Cascade Classifier for Object Detection
The object detector described below has been initially proposed by Paul Viola [pdf] and improved by Rainer Lienhart [pdf] .
First, a classifier (namely a cascade of boosted classifiers working with haar-like features) is trained with a few hundred sample views of a particular object (i.e., a face or a car), called positive examples, that are scaled to the same size (say, 20x20), and negative examples - arbitrary images of the same size.
After a classifier is trained, it can be applied to a region of interest (of the same size as used during the training) in an input image. The classifier outputs a "1" if the region is likely to show the object (i.e., face/car), and "0" otherwise. To search for the object in the whole image one can move the search window across the image and check every location using the classifier. The classifier is designed so that it can be easily "resized" in order to be able to find the objects of interest at different sizes, which is more efficient than resizing the image itself. So, to find an object of an unknown size in the image the scan procedure should be done several times at different scales.
The word "cascade" in the classifier name means that the resultant classifier consists of several simpler classifiers (stages) that are applied subsequently to a region of interest until at some stage the candidate is rejected or all the stages are passed. The word "boosted" means that the classifiers at every stage of the cascade are complex themselves and they are built out of basic classifiers using one of four different boosting techniques (weighted voting). Currently Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost are supported. The basic classifiers are decision-tree classifiers with at least 2 leaves. Haar-like features are the input to the basic classifiers, and are calculated as described below. The current algorithm uses the following Haar-like features:
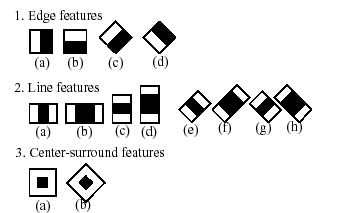
The feature used in a particular classifier is specified by its shape (1a, 2b etc.), position within the region of interest and the scale (this scale is not the same as the scale used at the detection stage, though these two scales are multiplied). For example, in the case of the third line feature (2c) the response is calculated as the difference between the sum of image pixels under the rectangle covering the whole feature (including the two white stripes and the black stripe in the middle) and the sum of the image pixels under the black stripe multiplied by 3 in order to compensate for the differences in the size of areas. The sums of pixel values over a rectangular regions are calculated rapidly using integral images (see below and the integral description).
To see the object detector at work, have a look at the facedetect demo: https://github.com/Itseez/opencv/tree/master/samples/cpp/dbt_face_detection.cpp
The following reference is for the detection part only. There is a separate application called opencv_traincascade that can train a cascade of boosted classifiers from a set of samples.
Note
In the new C++ interface it is also possible to use LBP (local binary pattern) features in addition to Haar-like features. .. [Viola01] Paul Viola and Michael J. Jones. Rapid Object Detection using a Boosted Cascade of Simple Features. IEEE CVPR, 2001. The paper is available online at https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf(上述有提到)
7、opencv关于boost
(boost.cpp——opencv3.0)
Boosting
A common machine learning task is supervised learning. In supervised learning, the goal is to learn the functional relationship F:y=F(x) between the input x and the output y . Predicting the qualitative output is called classification, while predicting the quantitative output is called regression.
Boosting is a powerful learning concept that provides a solution to the supervised classification learning task. It combines the performance of many "weak" classifiers to produce a powerful committee [125] . A weak classifier is only required to be better than chance, and thus can be very simple and computationally inexpensive. However, many of them smartly combine results to a strong classifier that often outperforms most "monolithic" strong classifiers such as SVMs and Neural Networks.
Decision trees are the most popular weak classifiers used in boosting schemes. Often the simplest decision trees with only a single split node per tree (called stumps ) are sufficient.
The boosted model is based on N training examples (xi,yi)1N with xi∈RK and yi∈−1,+1 . xi is a K -component vector. Each component encodes a feature relevant to the learning task at hand. The desired two-class output is encoded as -1 and +1.
Different variants of boosting are known as Discrete Adaboost, Real AdaBoost, LogitBoost, and Gentle AdaBoost [49] . All of them are very similar in their overall structure. Therefore, this chapter focuses only on the standard two-class Discrete AdaBoost algorithm, outlined below. Initially the same weight is assigned to each sample (step 2). Then, a weak classifier fm(x) is trained on the weighted training data (step 3a). Its weighted training error and scaling factor cm is computed (step 3b). The weights are increased for training samples that have been misclassified (step 3c). All weights are then normalized, and the process of finding the next weak classifier continues for another M -1 times. The final classifier F(x) is the sign of the weighted sum over the individual weak classifiers (step 4).
Two-class Discrete AdaBoost Algorithm
- Set N examples (xi,yi)1N with xi∈RK,yi∈−1,+1 .
- Assign weights as wi=1/N,i=1,...,N .
- Repeat for m=1,2,...,M :
- Fit the classifier fm(x)∈−1,1 , using weights wi on the training data.
- Compute errm=Ew[1(y≠fm(x))],cm=log((1−errm)/errm) .
- Set wi⇐wiexp[cm1(yi≠fm(xi))],i=1,2,...,N, and renormalize so that Σiwi=1 .
- Classify new samples x using the formula: sign(Σm=1Mcmfm(x)) .
- Note
- Similar to the classical boosting methods, the current implementation supports two-class classifiers only. For M > 2 classes, there is theAdaBoost.MH algorithm (described in [49]) that reduces the problem to the two-class problem, yet with a much larger training set.
To reduce computation time for boosted models without substantially losing accuracy, the influence trimming technique can be employed. As the training algorithm proceeds and the number of trees in the ensemble is increased, a larger number of the training samples are classified correctly and with increasing confidence, thereby those samples receive smaller weights on the subsequent iterations. Examples with a very low relative weight have a small impact on the weak classifier training. Thus, such examples may be excluded during the weak classifier training without having much effect on the induced classifier. This process is controlled with the weight_trim_rate parameter. Only examples with the summary fraction weight_trim_rate of the total weight mass are used in the weak classifier training. Note that the weights for all training examples are recomputed at each training iteration. Examples deleted at a particular iteration may be used again for learning some of the weak classifiers further [49]
- See also
- cv::ml::Boost
Prediction with Boost
StatModel::predict(samples, results, flags) should be used. Pass flags=StatModel::RAW_OUTPUT to get the raw sum from Boost classifier.
8、关于训练过程打印信息的解释
1)POS count : consumed n1 : n2
每次都调用updateTrainingSet( requiredLeafFARate, tempLeafFARate );函数
- bool CvCascadeClassifier::updateTrainingSet( double minimumAcceptanceRatio, double& acceptanceRatio)
- {
- int64 posConsumed = 0, negConsumed = 0;
- imgReader.restart();
- int posCount = fillPassedSamples( 0, numPos, true, 0, posConsumed );//Consumed消耗
- if( !posCount )
- return false;
- cout << "POS count : consumed " << posCount << " : " << (int)posConsumed << endl;//这就是打印信息,我的理解是这个stage判成正样本数和正样本数
- int proNumNeg = cvRound( ( ((double)numNeg) * ((double)posCount) ) / numPos ); // apply only a fraction of negative samples. double is required since overflow is possible
- int negCount = fillPassedSamples( posCount, proNumNeg, false, minimumAcceptanceRatio, negConsumed );
- if ( !negCount )
- return false;
- curNumSamples = posCount + negCount;
- acceptanceRatio = negConsumed == 0 ? 0 : ( (double)negCount/(double)(int64)negConsumed );
- cout << "NEG count : acceptanceRatio " << negCount << " : " << acceptanceRatio << endl;//打印信息,我的理解是
- return true;
- }
- int CvCascadeClassifier::fillPassedSamples( int first, int count, bool isPositive, double minimumAcceptanceRatio, int64& consumed )
- {
- int getcount = 0;
- Mat img(cascadeParams.winSize, CV_8UC1);
- for( int i = first; i < first + count; i++ )
- {
- for( ; ; )
- {
- if( consumed != 0 && ((double)getcount+1)/(double)(int64)consumed <= minimumAcceptanceRatio )
- return getcount;
- bool isGetImg = isPositive ? imgReader.getPos( img ) :
- imgReader.getNeg( img );
- if( !isGetImg )
- return getcount;
- consumed++;
- featureEvaluator->setImage( img, isPositive ? 1 : 0, i );
- if( predict( i ) == 1.0F )
- {
- getcount++;
- printf("%s current samples: %d\r", isPositive ? "POS":"NEG", getcount);
- break;
- }
- }
- }
- return getcount;
- }
- int CvCascadeClassifier::predict( int sampleIdx )
- {
- CV_DbgAssert( sampleIdx < numPos + numNeg );
- for (vector< Ptr
>::iterator it = stageClassifiers.begin(); - it != stageClassifiers.end(); it++ )
- {
- if ( (*it)->predict( sampleIdx ) == 0.f )
- return 0;
- }
- return 1;
- }
- float CvCascadeBoost::predict( int sampleIdx, bool returnSum ) const
- {
- CV_Assert( weak );
- double sum = 0;
- CvSeqReader reader;
- cvStartReadSeq( weak, &reader );
- cvSetSeqReaderPos( &reader, 0 );
- for( int i = 0; i < weak->total; i++ )
- {
- CvBoostTree* wtree;
- CV_READ_SEQ_ELEM( wtree, reader );
- sum += ((CvCascadeBoostTree*)wtree)->predict(sampleIdx)->value;
- }
- if( !returnSum )
- sum = sum < threshold - CV_THRESHOLD_EPS ? 0.0 : 1.0;
- return (float)sum;
- }