INT201-Decision, Computation and Language
文章目录
- 1. DFA
-
- 1.1 Language defined by DFA
- 1.2 Regular operations on languages
- 2. NFA
-
- 2.1 Language accepted by NFA
- 2.2 Equivalence of DFAs and NFAs
- 2.3 DFA to NFA
- 2.4 NFA to DFA
- 3. Regular Language
-
- 3.1 Closed under operation
-
- 3.1.1 Regular Languages Closed Under Union
- 3.1.2 Regular Languages Closed Under Concatenation
- 3.1.3 Regular Languages Closed Under Kleene star
- 3.1.4 Regular Languages Closed Under Complement and Interaction
- 3.2 Regular Expressions
- 3.3 Kleene's Theorem
- 3.4 GNFA
-
- 3.4.1 DFA 转 GNFA
- 3.5 Pumping Lemma for Regular Languages
- 4. Context-Free Languages
-
- 4.1 CFG
-
- 4.1.1 Language of CFG
- 4.2 CNF
-
- 4.2.1 Converting CFG into CNF
- 4.3 PDA
-
- 4.3.1 Nondeterministic PDA
- 4.3.2 Language accepted by PDA
- 4.4 Equivalence of PDA and context-free languages
-
- 4.4.1 CFLs and regular languages
- 4.5 The pumping lemma for context-free languages
-
- 4.5.1 Pumping Lemma for CFLs
- 5. Turing Machine
-
- 5.1 TM Configuration
- 5.2 TM Transitions
- 5.3 TM Computation
- 5.4 Language accepted by TM
- 5.5 Decider
- 5.6 Multi-tape TM
-
- 5.6.1 Multi-tape TM equivalent to 1-tape TM
- 5.7 Nondeterministic TM
-
- 5.7.1 Address
- 5.7.2 NTM equivalent to TM
- 5.8 Enumerable Language and Enumerator
- 5.9 Encoding
-
- 5.9.1 Encoding of Graph
- 5.9.2 TM to decide the connectedness of a Graph
1. DFA
DFA is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string.
A DFA is defined as a 5-tuple: M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F)
- Q Q Q is a finite set of states.
- Σ \Sigma Σ is a finite set of symbols, called the alphabet of the automaton.
- δ : Q × Σ → Q \delta:Q\times\Sigma\rightarrow Q δ:Q×Σ→Q is a function, called the transition function.
- q ∈ Q q\in Q q∈Q is called the initial state.
- F ⊆ Q F\subseteq Q F⊆Q is a set of accepting / terminal states.
We can extend the definition of the transition function δ \delta δ so that it tells us which state we reach after a word Σ ∗ \Sigma^* Σ∗ (not just a single letter) has been scanned:
extend the map δ : Q × Σ → Q \delta:Q\times\Sigma\rightarrow Q δ:Q×Σ→Q to δ ∗ : Q × Σ ∗ → Q \delta^*:Q\times\Sigma^*\rightarrow Q δ∗:Q×Σ∗→Q by defining:
δ ∗ ( q , ϵ ) = q for all q ∈ Q δ ∗ ( q , w a ) = δ ( δ ∗ ( q , w ) , a ) for all q ∈ Q , w ∈ Σ ∗ , a ∈ Σ δ ∗ ( q , v w ) = δ ∗ ( δ ∗ ( q , v ) , w ) for all q ∈ Q , v , w ∈ Σ ∗ \begin{aligned}\delta^*(q,\epsilon)=q~~~~&\text{for all }q\in Q\\\delta^*(q,wa)=\delta(\delta^*(q,w),a)~~~~&\text{for all }q\in Q,w\in\Sigma^*,a\in\Sigma\\\delta^*(q,vw)=\delta^*(\delta^*(q,v),w)~~~~&\text{for all }q\in Q,v,w\in\Sigma^*\end{aligned} δ∗(q,ϵ)=q δ∗(q,wa)=δ(δ∗(q,w),a) δ∗(q,vw)=δ∗(δ∗(q,v),w) for all q∈Qfor all q∈Q,w∈Σ∗,a∈Σfor all q∈Q,v,w∈Σ∗
DFA 也可以看成是一张有向图

既然是一个图,那它也可以通过临接表的方式表示(可以试着画出下表的图)

1.1 Language defined by DFA
Suppose we have a DFA M M M, A word w ∈ Σ ∗ w\in\Sigma^* w∈Σ∗ is said to be accepted or recognized by M M M if δ ∗ ( q 0 , w ) ∈ F \delta^*(q_0,w)\in F δ∗(q0,w)∈F, otherwise it is said to be rejected. The set of all words accepted by M M M is called the language accepted by M M M and will be denoted by L ( M ) L(M) L(M).
L ( M ) = { w ∈ Σ ∗ : δ ∗ ( q 0 , w ) ∈ F } L(M)=\{w\in\Sigma^*:\delta^*(q_0,w)\in F\} L(M)={w∈Σ∗:δ∗(q0,w)∈F}
Any finite language is accepted by some DFA
1.2 Regular operations on languages
A language A A A is called regular, if there exists a finite automaton M M M such that A = L ( M ) A=L(M) A=L(M)
Let A A A and B B B be two languages over the same alphabet.
The union of A A A and B B B is defined as: A ∪ B = { w : w ∈ A or w ∈ B } A\cup B=\{w:w\in A\text{ or }w\in B\} A∪B={w:w∈A or w∈B}
The concatenation: A B = { w w ′ : w ∈ A and w ′ ∈ B } AB=\{ww^\prime:w\in A\text{ and }w^\prime\in B\} AB={ww′:w∈A and w′∈B}
The Kleene star of A A A is defined as: A ∗ = ⋃ i ∈ N A i = A 0 ∪ A 1 ∪ A 2 ⋯ A^*=\bigcup\limits_{i\in N}A_i=A_0\cup A_1\cup A_2\cdots A∗=i∈N⋃Ai=A0∪A1∪A2⋯where A 0 = { ϵ } A 1 = A A i + 1 = { w v : w ∈ A i , v ∈ A } \begin{aligned}A_0&=\{\epsilon\}\\A_1&=A\\A_{i+1}&=\{wv:w\in A_i,v\in A\}\end{aligned} A0A1Ai+1={ϵ}=A={wv:w∈Ai,v∈A}
2. NFA
A finite automata is deterministic, if the next state the machine goes to on any given symbol is uniquely determined.
DFA has exactly one transition leaving each state for each symbol.
A finite automata is nondeterministic, if the machine allows for several or no choices to exist for the next state on a given symbol. For a state q q q and symbol s ∈ Σ s\in\Sigma s∈Σ, NFA can have:
- Multiple edges leaving q q q labelled with the same symbol s s s
- No edge leaving q q q labelled with symbol s s s
- Edge leaving q q q labelled with ϵ \epsilon ϵ (without reading any symbol)
The machine splits into multiple copies of itself (threads):
- Each copy proceeds with computation independently of others
- NFA may be in a set of states, instead of a single state.
- NFA follows all possible computation paths in parallel.
- If a copy is in a state and next input symbol doesn’t appear on any outgoing edge from the state, then the copy dies or crashes.
- NFA accepts the input string, if any copy ends in an accept state after reading the entire string.
For any alphabet Σ \Sigma Σ, we define Σ ϵ = Σ ∪ { ϵ } \Sigma_\epsilon=\Sigma\cup\{\epsilon\} Σϵ=Σ∪{ϵ}
NFA is a 5-tuple M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F)
- Q Q Q is a finite set of states
- Σ \Sigma Σ is a finite set of symbols, called the alphabet of the automaton
- δ : Q × Σ ϵ → P ( Q ) \delta:Q\times\Sigma_\epsilon\rightarrow P(Q) δ:Q×Σϵ→P(Q) is a function, called the transition function
- q ∈ Q q\in Q q∈Q is called the initial / start state
- F ⊆ Q F\subseteq Q F⊆Q is a set of accepting / terminal states
Let M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F) be an NFA, and let w ∈ Σ ∗ w\in \Sigma^* w∈Σ∗. We say that M M M accepts w w w, if δ ∗ ( q 0 , w ) ∈ F \delta^*(q_0,w)\in F δ∗(q0,w)∈F
Extend the map δ \delta δ to a map Q × Σ ∗ → P ( Q ) Q\times\Sigma^*\rightarrow P(Q) Q×Σ∗→P(Q) by defining: δ ( q , ϵ ) = { q } for all q ∈ Q δ ( q , w a ) = ⋃ p ∈ δ ( q , w ) δ ( p , a ) for all q ∈ Q , w ∈ Σ ∗ , a ∈ Σ \begin{aligned}\delta(q,\epsilon)=\{q\}~~~~&\text{for all }q\in Q\\\delta(q,wa)=\bigcup\limits_{p\in\delta(q,w)}\delta(p,a)~~~~&\text{for all }q\in Q,w\in\Sigma^*,a\in\Sigma\end{aligned} δ(q,ϵ)={q} δ(q,wa)=p∈δ(q,w)⋃δ(p,a) for all q∈Qfor all q∈Q,w∈Σ∗,a∈Σ
Suppose, in a DFA, we can get from state p p p to state q q q via transitions labelled by letters of a word w w w. Then we say that the states p p p and q q q are connected by a path with label w w w.
In a NFA, if δ ( p , a ) = { q , r } \delta(p,a)=\{q,r\} δ(p,a)={q,r} we could write: { p } ⟶ a { q , r } \{p\}\stackrel{a}{\longrightarrow}\{q,r\} {p}⟶a{q,r}
2.1 Language accepted by NFA
Let M = ( Q , Σ , δ , a , F ) M=(Q,\Sigma,\delta,a,F) M=(Q,Σ,δ,a,F) be an NFA. The language L ( M ) L(M) L(M) accepted by M M M is defined as L ( M ) = { w ∈ Σ ∗ : M accepts w } L(M)=\{w\in\Sigma^*:M\text{ accepts } w\} L(M)={w∈Σ∗:M accepts w}
2.2 Equivalence of DFAs and NFAs
Two machines are equivalent if they recognize the same language.
DFA is a restricted form of NFA:
- Every NFA has an equivalent DFA
- We can convert an arbitrary NFA to a DFA that accepts the same language
- DFA has the same power as NFA
2.3 DFA to NFA
The formal conversion of a DFA to an NFA is done as follows: Let M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F) be a DFA. δ \delta δ is a function δ : Q × Σ → Q \delta:Q\times\Sigma\rightarrow Q δ:Q×Σ→Q. We define the function δ ′ : Q × Σ ϵ → P ( Q ) \delta^\prime:Q\times\Sigma_\epsilon\rightarrow P(Q) δ′:Q×Σϵ→P(Q). For any r ∈ Q r\in Q r∈Q and for any a ∈ Σ ϵ a\in\Sigma_\epsilon a∈Σϵ: δ ′ ( r , a ) = { { δ ( r , a ) } if a ≠ ϵ ϕ if a = ϵ \delta^\prime(r,a)=\begin{cases}\{\delta(r,a)\}&\text{if }a\ne\epsilon\\\phi&\text{if }a=\epsilon\end{cases} δ′(r,a)={{δ(r,a)}ϕif a=ϵif a=ϵThen N = ( Q , Σ , δ ′ ) N=(Q,\Sigma,\delta^\prime) N=(Q,Σ,δ′) is an NFA, whose behavior is exactly the same as that of the DFA M M M, the easiest way to see this is by observing that the state diagrams of M M M and N N N are equal. Therefore, we have L ( M ) = L ( N ) L(M)=L(N) L(M)=L(N)
2.4 NFA to DFA
Definition 1
The ϵ − closure \epsilon-\text{closure} ϵ−closure of a set of states R ⊆ Q R\subseteq Q R⊆Q:
E ( R ) = { q ∣ q can be reached from R by travelling over zero or more ϵ transitions } E(R)=\{q|q \text{ can be reached from }R\text{ by travelling over zero or more }\epsilon\text{ transitions }\} E(R)={q∣q can be reached from R by travelling over zero or more ϵ transitions }
Definition 2
Suppose that there is a set of states R R R and a ∈ Σ a\in\Sigma a∈Σ, we say that R a = ϵ − closure ( J ) R_a=\epsilon-\text{closure}(J) Ra=ϵ−closure(J) where J J J is the set that can be reached from R R R by travelling over a a a
e.g.

通过以上两个定义得到下表:
| R | R a R_a Ra | R b R_b Rb |
|---|---|---|
| {5,1} | {5,3,1} | {5,4,1} |
| {5,3,1} | {5,1,3,2,6,Y} | {5,4,1} |
| {5,4,1} | {5,3,1} | {5,1,4,2,6,Y} |
| {5,1,3,2,6,Y} | {5,1,3,2,6,Y} | {5,1,4,6,Y} |
| {5,1,4,2,6,Y} | {5,1,3,6,Y} | {5,1,4,2,6,Y} |
| {5,1,4,6,Y} | {5,1,3,6,Y} | {5,1,4,2,6,Y} |
| {5,1,3,6,Y} | {5,1,3,2,6,Y} | {5,1,4,6,Y} |
然后进行重新编号:
| S | a | b |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | 1 | 4 |
| 3 | 3 | 5 |
| 4 | 6 | 4 |
| 5 | 6 | 4 |
| 6 | 3 | 5 |
这个表就是临接表,然后画图,就是 DFA
3. Regular Language
Definition
Previous: A language is regular if it is recognized by some DFA
Now: A language is regular if and only if some NFA recognizes it
Some operations on languages: Union, Concatenation and Kleene star
3.1 Closed under operation
A collection S S S of objects is closed under operation f f f if applying f f f to members of S S S always returns an object still in S S S.
Regular languages are indeed closed under the regular operations (Union, Concatenation, Kleene star)
3.1.1 Regular Languages Closed Under Union
Proof
A A A and B B B are regular languages over the same alphabet Σ \Sigma Σ, there are automata M 1 = ( Q 1 , Σ , δ 1 , q 1 , F 1 ) M_1=(Q_1,\Sigma,\delta_1,q_1,F_1) M1=(Q1,Σ,δ1,q1,F1) and M 2 = ( Q 2 , Σ , δ 2 , q 2 , F 2 ) M_2=(Q_2,\Sigma,\delta_2,q_2,F_2) M2=(Q2,Σ,δ2,q2,F2) that accept A A A and B B B, respectively.
We can define M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F) where:
- Q = Q 1 × Q 2 = { ( q 1 , q 2 ) : q 1 ∈ Q 1 and q 2 ∈ Q 2 } Q=Q_1\times Q_2=\{(q_1,q_2):q_1\in Q_1\text{ and }q_2\in Q_2\} Q=Q1×Q2={(q1,q2):q1∈Q1 and q2∈Q2}
- q = ( q 1 , q 2 ) q = (q_1,q_2) q=(q1,q2)
- F = { ( q 1 , q 2 ) : q 1 ∈ F 1 or q 2 ∈ F 2 } F=\{(q_1,q_2):q_1\in F_1\text{ or }q_2\in F_2\} F={(q1,q2):q1∈F1 or q2∈F2}
- δ : δ ( ( q 1 , q 2 ) , a ) = ( δ ( q 1 , a ) , δ ( q 2 , a ) ) , a ∈ Σ \delta:\delta((q_1,q_2),a)=(\delta(q_1,a),\delta(q_2,a)),a\in\Sigma δ:δ((q1,q2),a)=(δ(q1,a),δ(q2,a)),a∈Σ
Then: M accept w ⟺ δ ∗ ( ( q 1 , q 2 ) , w ) ∈ F ⟺ δ ∗ ( q 1 , w ) ∈ F 1 or δ ∗ ( q 2 , w ) ∈ F 2 M\text{ accept } w\iff\delta^*((q_1,q_2),w)\in F\iff\delta^*(q_1,w)\in F_1\text{ or }\delta^*(q_2,w)\in F_2 M accept w⟺δ∗((q1,q2),w)∈F⟺δ∗(q1,w)∈F1 or δ∗(q2,w)∈F2
So that L ( M ) = L ( M 1 ) ∪ L ( M 2 ) L(M) = L(M_1)\cup L(M_2) L(M)=L(M1)∪L(M2)
Proof from the perspective of NFA
Consider M 1 , M 2 M_1,M_2 M1,M2 are NFAs, we assume that Q 1 ∩ Q 2 = ∅ Q_1\cap Q_2=\varnothing Q1∩Q2=∅
We can define M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F) where:
- Q = { q 0 } ∪ Q 1 ∪ Q 2 Q=\{q_0\}\cup Q_1\cup Q_2 Q={q0}∪Q1∪Q2
- q 0 q_0 q0 is the start state of M M M
- F = F 1 ∪ F 2 F=F_1\cup F_2 F=F1∪F2
Then: δ ( q , a ) = { δ 1 ( q , a ) if r ∈ Q 1 δ 2 ( q , a ) if r ∈ Q 2 { q 1 , q 2 } if r = q 0 and a = ϵ ∅ if r = q 0 and a ≠ ϵ \delta(q,a)=\begin{cases}\delta_1(q,a)&\text{if }r\in Q_1\\\delta_2(q,a)&\text{if }r\in Q_2\\\{q_1,q_2\}&\text{if }r=q_0\text{ and }a=\epsilon\\\varnothing&\text{if }r=q_0\text{ and }a\ne\epsilon\end{cases} δ(q,a)=⎩⎪⎪⎪⎨⎪⎪⎪⎧δ1(q,a)δ2(q,a){q1,q2}∅if r∈Q1if r∈Q2if r=q0 and a=ϵif r=q0 and a=ϵ
用图论的话来说,相当于建一虚点 q 0 q_0 q0,指向两个 NFA 的起点。
3.1.2 Regular Languages Closed Under Concatenation
The concatenation of A 1 A_1 A1 and A 2 A_2 A2 is defined as: A 1 A 2 = { w w ′ : w ∈ A 1 and w ′ ∈ A 2 } A_1A_2=\{ww^\prime:w\in A_1\text{ and }w^\prime\in A_2\} A1A2={ww′:w∈A1 and w′∈A2}
Proof
- Q = Q 1 ∪ Q 2 Q=Q_1\cup Q_2 Q=Q1∪Q2
- q = q 1 q=q_1 q=q1
- F = F 2 F=F_2 F=F2
Then: δ ( q , a ) = { δ 1 ( q , a ) if q ∈ Q 1 and q ∉ F 1 δ 1 ( q , a ) if q ∈ F 1 and a ≠ ϵ δ 1 ( q , a ) ∪ { q 2 } if q ∈ F 1 and a = ϵ δ 2 ( q , a ) if r ∈ Q 2 \delta(q,a)=\begin{cases}\delta_1(q,a)&\text{if }q\in Q_1\text{ and }q\notin F_1\\\delta_1(q,a)&\text{if }q\in F_1\text{ and }a\ne\epsilon\\\delta_1(q,a)\cup\{q_2\}&\text{if }q\in F_1\text{ and }a=\epsilon\\\delta_2(q,a)&\text{if }r\in Q_2\end{cases} δ(q,a)=⎩⎪⎪⎪⎨⎪⎪⎪⎧δ1(q,a)δ1(q,a)δ1(q,a)∪{q2}δ2(q,a)if q∈Q1 and q∈/F1if q∈F1 and a=ϵif q∈F1 and a=ϵif r∈Q2
相当于是把所有的 F 1 F_1 F1 连到了 q 2 q_2 q2,有种首尾相接的感觉。
3.1.3 Regular Languages Closed Under Kleene star
Proof
- Q = { q 0 } ∪ Q 1 Q=\{q_0\}\cup Q_1 Q={q0}∪Q1
- q 0 q_0 q0 is the start state of M M M
- F = { q 0 } ∪ F 1 F=\{q_0\}\cup F_1 F={q0}∪F1
Then: δ ( q , a ) = { δ 1 ( q , a ) if q ∈ Q 1 and q ∉ F 1 δ 1 ( q , a ) if q ∈ F 1 and a ≠ ϵ δ 1 ( q , a ) ∪ { q 1 } if q ∈ F 1 and a = ϵ { q 1 } if q = q 0 and a = ϵ ∅ if q = q 0 and a ≠ ϵ \delta(q,a)=\begin{cases}\delta_1(q,a)&\text{if }q\in Q_1\text{ and }q\notin F_1\\\delta_1(q,a)&\text{if }q\in F_1\text{ and }a\ne\epsilon\\\delta_1(q,a)\cup\{q_1\}&\text{if }q\in F_1\text{ and }a=\epsilon\\\{q_1\}&\text{if }q=q_0\text{ and }a=\epsilon\\\varnothing&\text{if }q=q_0\text{ and }a\ne\epsilon\end{cases} δ(q,a)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧δ1(q,a)δ1(q,a)δ1(q,a)∪{q1}{q1}∅if q∈Q1 and q∈/F1if q∈F1 and a=ϵif q∈F1 and a=ϵif q=q0 and a=ϵif q=q0 and a=ϵ
所有 F F F 都连到了 q 1 q_1 q1 上,白了就是递归
3.1.4 Regular Languages Closed Under Complement and Interaction
If A A A is a regular language over the alphabet Σ \Sigma Σ, then the complement: A ˉ { w ∈ Σ ∗ : w ∉ A } \bar A\{w\in\Sigma^*:w\notin A\} Aˉ{w∈Σ∗:w∈/A}is also a regular language.
If A 1 A_1 A1 and A 2 A_2 A2 are regular languages over the same alphabet Σ \Sigma Σ, then the interaction: A 1 ∩ A 2 = { w ∈ Σ ∗ : w ∈ A 1 and w ∈ A 2 } A_1\cap A_2=\{w\in\Sigma^*:w\in A_1\text{ and }w\in A_2\} A1∩A2={w∈Σ∗:w∈A1 and w∈A2} is also a regular language.
3.2 Regular Expressions
Regular expressions are means to describe certain languages.
Let Σ \Sigma Σ be a non-empty alphabet.
- ϵ \epsilon ϵ is a regular expression
- ∅ \varnothing ∅ is a regular expression
- For each a ∈ Σ a\in\Sigma a∈Σ, a a a is a regular expression
- If R 1 R_1 R1 and R 2 R_2 R2 are regular expressions, then R 1 ∪ R 2 R_1\cup R_2 R1∪R2 is a regular expression, the same as R 1 R 2 R_1R_2 R1R2, R 1 ∗ R_1^* R1∗
If R R R is a regular expression, then L ( R ) L(R) L(R) is the language generated / described / defined by R R R.
5. ϵ \epsilon ϵ describes the language { ϵ } \{\epsilon\} {ϵ}
6. ∅ \varnothing ∅ describes the language ∅ \varnothing ∅
7. For each a ∈ Σ a\in\Sigma a∈Σ, the regular expression a describes the language { a } \{a\} {a}
8. If R 1 , R 2 R_1,R_2 R1,R2 are regular expressions and L 1 , L 2 L_1,L_2 L1,L2 are the languages described by them, respectively. R 1 ∪ R 2 R_1\cup R_2 R1∪R2 describes the language L 1 ∪ L 2 L_1\cup L_2 L1∪L2, the same as R 1 R 2 R_1R_2 R1R2, R 1 ∗ R_1^* R1∗
3.3 Kleene’s Theorem
Let L L L be a language. Then L L L is regular iff there exists a regular expression that describes L L L.
- If a language is described by a regular expression, then it is regular.
- If a language is regular, then it has a regular expression.
3.4 GNFA
A GNFA can be defined as a 5-tuple ( Q , Σ , δ , { s } , { t } ) (Q,\Sigma,\delta,\{s\},\{t\}) (Q,Σ,δ,{s},{t})
- Q Q Q is a finite set of states
- Σ \Sigma Σ is a finite set of alphabet
- δ : ( Q ∖ { t } ) × ( Q ∖ { s } ) → R \delta:(Q\setminus\{t\})\times(Q\setminus\{s\})\rightarrow R δ:(Q∖{t})×(Q∖{s})→R
- s ∈ Q s\in Q s∈Q
- t ∈ Q t\in Q t∈Q
3.4.1 DFA 转 GNFA
Convert a DFA into a regular expression
DFA转GNFA
3.5 Pumping Lemma for Regular Languages
A tool that can be used to prove that certain languages are not regular. This theorem states that all regular languages have a special property.
This property states that all strings in the language can be “pumped” if they are at least as long as a certain special value, called the pumping length. That means each such string contains a section that can be repeated any number of times with resulting string remaining in the language.
- If a language L L L is regular, it always satisfies pumping lemma. If there exists at least one string made from pumping which is not in L L L, then L L L is surely not regular.
- If pumping lemma holds, it does not mean that the language is regular.
e.g.


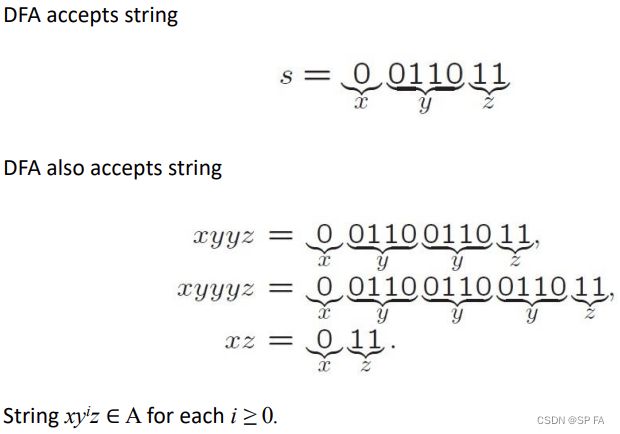

4. Context-Free Languages
4.1 CFG
Context-Free Grammar
A context-free grammar is a 4-tuple G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S), where
- V V V is a finite set, whose elements are called variables
- Σ \Sigma Σ is a finite set, whose elements are called terminals
- V ∩ Σ = ∅ V\cap\Sigma=\varnothing V∩Σ=∅
- S S S is an element of V V V, it is called the start variable
- R R R is a finite set, whose elements are called rules. Each rule has the form A → w A\rightarrow w A→w, where A ∈ V A\in V A∈V and w ∈ ( V ∪ Σ ) ∗ w\in(V\cup\Sigma)^* w∈(V∪Σ)∗
Definition 1: yeild ⇒ \Rightarrow ⇒
Let G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S) be a context free grammar with
- A ∈ V A\in V A∈V
- u , v , w ∈ ( V ∪ Σ ) ∗ u,v,w\in(V\cup\Sigma)^* u,v,w∈(V∪Σ)∗
- A → w A\rightarrow w A→w is a rule of the grammar
The string u w v uwv uwv can be derived in one step from the string u A v uAv uAv, written as u A v ⇒ u w v uAv\Rightarrow uwv uAv⇒uwv
Definition 2: derive ⇒ ∗ \stackrel{*}{\Rightarrow} ⇒∗
Let G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S) be a context free grammar with
- u , v ∈ ( V ∪ Σ ) ∗ u,v\in(V\cup\Sigma)^* u,v∈(V∪Σ)∗
The string v v v can be derived from the string u u u, written as u ⇒ ∗ v u\stackrel{*}{\Rightarrow}v u⇒∗v, if one of the following conditions holds:
- u = v u=v u=v
- there exist an integer k ≥ 2 k\geq2 k≥2 and a sequence u 1 , u 2 , ⋯ , u k u_1,u_2,\cdots,u_k u1,u2,⋯,uk of strings in ( V ∪ Σ ) ∗ (V\cup\Sigma)^* (V∪Σ)∗, such that
- u = u 1 u=u_1 u=u1
- v = u k v=u_k v=uk and u 1 ⇒ u 2 ⇒ u 3 ⋯ ⇒ u k u_1\Rightarrow u_2\Rightarrow u_3\cdots\Rightarrow u_k u1⇒u2⇒u3⋯⇒uk
4.1.1 Language of CFG
The language of CFG G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S) is L ( G ) = { w ∈ Σ ∗ ∣ S ⇒ ∗ w } L(G)=\{w\in\Sigma^*|S\stackrel*\Rightarrow w\} L(G)={w∈Σ∗∣S⇒∗w}Such a language is called context-free, and satisfies L ( G ) ⊆ Σ ∗ L(G)\subseteq\Sigma^* L(G)⊆Σ∗
Theorem
Let Σ \Sigma Σ be an alphabet and let L ⊆ Σ ∗ L\subseteq\Sigma^* L⊆Σ∗ be a regular language. Then L L L is a context-free language (Every regular language is context-free)
Proof
Since L L L is a regular language, there exists a deterministic finite automton M = ( Q , Σ , δ , q , F ) M=(Q,\Sigma,\delta,q,F) M=(Q,Σ,δ,q,F) that accepts L L L. To prove that L L L is context-free, we have to define a context-free grammar G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S), such that L = L ( M ) = L ( G ) L=L(M)=L(G) L=L(M)=L(G). Thus, G G G must have the following property:
- For every string w ∈ Σ ∗ w\in\Sigma^* w∈Σ∗ w ∈ L ( M ) iff w ∈ L ( G ) w\in L(M)~\text{iff}~w\in L(G) w∈L(M) iff w∈L(G)
- which can be reformulated as M accepts w iff S ⇒ ∗ w M\text{ accepts }w\text{ iff }S\stackrel*\Rightarrow w M accepts w iff S⇒∗w
Set V = { R i ∣ q i ∈ Q } V=\{R_i|q_i\in Q\} V={Ri∣qi∈Q} that is, G G G has a variable for every state of M M M. Now, for every transition δ ( q i , a ) = q j \delta(q_i,a)=q_j δ(qi,a)=qj add a rule R i → a R j R_i\rightarrow aR_j Ri→aRj. For every accepting state q i ∈ F q_i\in F qi∈F add a rule R i → ϵ R_i\rightarrow\epsilon Ri→ϵ. Finally, make the start variable S = R 0 S=R_0 S=R0
4.2 CNF
Chomsky Normal Form
A context-free grammar G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S) is said to be in Chomsky normal form, if every rule in R R R has one of the following three forms:
- A → B C A\rightarrow BC A→BC, where A , B , C A,B,C A,B,C are elements of V V V, B ≠ S B\ne S B=S and C ≠ S C\ne S C=S
- A → a A\rightarrow a A→a, where A A A is an element of V V V and a a a is an element of Σ \Sigma Σ
- S → ϵ S\rightarrow\epsilon S→ϵ, where S S S is the start variable
Grammars in CNF are far easier to analyze.
Theorem
Let Σ \Sigma Σ be an alphabet and let L ⊆ Σ ∗ L\subseteq\Sigma^* L⊆Σ∗ be a context-free language. There exists a context-free grammar in CNF, whose language is L L L. That is, every CFL can be described by a CFG in CNF
Proof
Given CFG G = ( V , Σ , R , S ) G=(V,\Sigma,R,S) G=(V,Σ,R,S). Replace, one-by-one, every rule that is not “Chomsky”
- Start variable (not allowed on RHS of rules)
- ϵ \epsilon ϵ-rules ( A → ϵ A\rightarrow\epsilon A→ϵ not allowed when A A A isn’t start variable)
- all other violating rules ( A → B , A → a B c , A → B C D E A\rightarrow B,A\rightarrow aBc, A\rightarrow BCDE A→B,A→aBc,A→BCDE)
4.2.1 Converting CFG into CNF
- Eliminate the start variable from the right-hand side of the rules.
- New start variable S 0 S_0 S0
- New rule S 0 → S S_0\rightarrow S S0→S
- Remove ϵ \epsilon ϵ-rules A → ϵ A\rightarrow\epsilon A→ϵ, where A ∈ V − { S } A\in V-\{S\} A∈V−{S}. When removing A → ϵ A\rightarrow\epsilon A→ϵ rules, insert all new replacements
- Before: B → A b A B\rightarrow AbA B→AbA and A → ϵ ∣ ⋯ A\rightarrow\epsilon|\cdots A→ϵ∣⋯
- After: B → A b A ∣ b A ∣ A b ∣ b B\rightarrow AbA|bA|Ab|b B→AbA∣bA∣Ab∣b and A → ⋯ A\rightarrow\cdots A→⋯
- Remove unit rules A → B A\rightarrow B A→B, where A ∈ V A\in V A∈V
- Before: A → B A\rightarrow B A→B and B → x C y B\rightarrow xCy B→xCy
- After: A → x C y A\rightarrow xCy A→xCy and B → x C y B\rightarrow xCy B→xCy
- Eliminate all rules having more than two symbols on the right-hand side.
- Before: A → B 1 B 2 B 3 A\rightarrow B_1B_2B_3 A→B1B2B3
- After: A → B 1 A 1 , A 1 → B 2 B 3 A\rightarrow B_1A_1, A_1\rightarrow B_2B_3 A→B1A1,A1→B2B3
- Eliminate all rules of the form A → a b A\rightarrow ab A→ab, where a a a and b b b are not both variables.
- Before: A → a b A\rightarrow ab A→ab
- After: A → B 1 B 2 , B 1 → a , B 2 → b A\rightarrow B_1B_2, B_1\rightarrow a, B_2\rightarrow b A→B1B2,B1→a,B2→b
4.3 PDA
Pushdown Automata
The class of languages that can be accepted by pushdown automata is exactly the class of context-free languages (finite automata are for regular languages).
- The input for a pushdown automaton is a string w w w in Σ ∗ \Sigma^* Σ∗
- Different from finite automata, PDAs have a single stack.
- Stack have 2 different operations:
- push: adds item to top of stack
- pop: removes item from top of stack

- Tape: divided into cells that store symbols belonging to Σ ϵ = Σ ∪ { ϵ } \Sigma_\epsilon=\Sigma\cup\{\epsilon\} Σϵ=Σ∪{ϵ}
- Tape head: move along the tape, one cell to the right per move.
- Stack: containing symbols from a finite set Γ Γ Γ, called the stack alphabet. This set contains a special symbol $ (often mark bottom of stack).
- State control: can be in any one of a finite number of states. The set of states is denoted by Q Q Q. The set Q Q Q contains one special state q, called the start state.
PDA Transition
If PDA
- in state q i q_i qi
- reads a ∈ Σ ϵ a\in\Sigma_\epsilon a∈Σϵ
- pops b ∈ Γ ϵ b\inΓ_\epsilon b∈Γϵ off the stack
If a = ϵ a=\epsilon a=ϵ, then no input symbol is read.
If b = ϵ b=\epsilon b=ϵ, then nothing is popped off stack.
Then PDA
- moves to state q j q_j qj
- push c ∈ Γ ϵ c\inΓ_\epsilon c∈Γϵ onto top of stack
If c = ϵ c=\epsilon c=ϵ, then nothing is pushed onto stack
If c = u 1 u 2 ⋯ u k c=u_1u_2\cdots u_k c=u1u2⋯uk with k ≥ 1 k\geq1 k≥1 and u 1 , u 2 , ⋯ , u k ∈ Γ u_1,u_2,\cdots,u_k\inΓ u1,u2,⋯,uk∈Γ, then b b b is replaced by c c c, and u k u_k uk becomes the new top symbol of the stack.
A pushdown automaton is a 6-tuple M = ( Q , Σ , Γ , δ , q , F ) M=(Q,\Sigma,Γ,\delta,q,F) M=(Q,Σ,Γ,δ,q,F)
- Q Q Q is finite set of states
- Σ \Sigma Σ is (finite) input (tape) alphabet
- Γ Γ Γ is (finite) stack alphabet
- δ \delta δ is the transition function: Q × Σ ϵ × Γ → Q × { N , R } × Γ ϵ ∗ Q\times\Sigma_\epsilon\timesΓ\rightarrow Q\times\{N,R\}\timesΓ_\epsilon^* Q×Σϵ×Γ→Q×{N,R}×Γϵ∗
- q ∈ Q q\in Q q∈Q is start state
- F ⊆ Q F\subseteq Q F⊆Q is set of accept states
Let r ′ ∈ Q , σ ∈ { N , R } r^\prime\in Q,\sigma\in\{N,R\} r′∈Q,σ∈{N,R}, and w ∈ Γ ∗ w\inΓ^* w∈Γ∗ δ ( r , a , b ) = ( r ′ , σ , c ) \delta(r,a,b)=(r^\prime,\sigma,c) δ(r,a,b)=(r′,σ,c)
The tape head moves according to σ \sigma σ:
- If σ = R \sigma=R σ=R, it moves one cell to the right
- If σ = N \sigma=N σ=N, it does not move
4.3.1 Nondeterministic PDA
PDA transition function allows for nondeterminism δ : Q × Σ ϵ × Γ ϵ → P ( Q × Γ ϵ ) \delta:Q\times\Sigma_\epsilon\timesΓ_\epsilon\rightarrow P(Q\timesΓ_\epsilon) δ:Q×Σϵ×Γϵ→P(Q×Γϵ)
4.3.2 Language accepted by PDA
The set of all input strings that are accepted by PDA M M M is the language recognized by M M M and is denoted by L ( M ) L(M) L(M)
4.4 Equivalence of PDA and context-free languages
Let Σ \Sigma Σ be an alphabet and let A ⊆ Σ ∗ A\subseteq\Sigma^* A⊆Σ∗ be a language. Then A A A is context-free if and only if there exists a pushdown automaton that accepts A A A.
- If A = L ( G ) A=L(G) A=L(G) for some CFG G G G, then A = L ( M ) A=L(M) A=L(M) for some PDA M M M.
- If A = L ( M ) A=L(M) A=L(M) for some PDA M M M, then A = L ( G ) A=L(G) A=L(G) for some CFG G G G.
Proof: If A = L ( G ) A=L(G) A=L(G) for some CFG G G G, then A = L ( M ) A=L(M) A=L(M) for some PDA M M M.
Basic idea: Given CFG G G G, convert it into PDA M M M with L ( M ) = L ( G ) L(M)=L(G) L(M)=L(G) by building PDA that simulates a leftmost derivation.
However, PDA cannot push strings instead of ≤ 1 \le1 ≤1 symbols onto stack. How can we solve this problem? δ : Q × Σ ϵ × Γ ϵ → P ( Q × Γ ϵ ) \delta:Q\times\Sigma_\epsilon\timesΓ_\epsilon\rightarrow P(Q\timesΓ_\epsilon) δ:Q×Σϵ×Γϵ→P(Q×Γϵ)
4.4.1 CFLs and regular languages
If A A A is a regular language, then A A A is also a CFL.
Proof
- Suppose A A A is regular, so it has a corresponding NFA
- NFA is a PDA without stack.
- So A A A has a PDA
- A A A is context-free
4.5 The pumping lemma for context-free languages
4.5.1 Pumping Lemma for CFLs
Let L L L be a context-free language. Then there exists an integer p ≥ 1 p\ge1 p≥1, called the pumping length, such that the following holds: Every string s in L L L, with ∣ s ∣ ≥ p |s|\ge p ∣s∣≥p, can be written as s = u v x y z s=uvxyz s=uvxyz, such that
- ∣ v y ∣ ≥ 1 |vy|\ge1 ∣vy∣≥1
- ∣ v x y ∣ ≤ p |vxy|\le p ∣vxy∣≤p
- u v i x y i z ∈ L uv^ixy^iz\in L uvixyiz∈L, for all i ≥ 0 i\ge0 i≥0.
Split String Using Parse Tree
- More generally, consider “long” string s ∈ A s\in A s∈A.
- Parse tree is “tall”, ∃ ∃ ∃ repeated variable R R R in path from root S S S to leaf.
- Split string s = u v x y z s=uvxyz s=uvxyz into 5 pieces based on repeated variable R R R:
- u u u is before R − R R-R R−R subtree (in depth-first order)
- v v v is before second R R R subtree within R − R R-R R−R subtree
- x x x is what second R R R eventually becomes
- y y y is after second R R R within R − R R-R R−R subtree
- z z z is after R − R R-R R−R subtree
5. Turing Machine

- k ≥ 1 k\ge1 k≥1 infinitely long tape (The tape is infinite both to the left and to the right), divided into cells. Each cell stores a symbol belonging to Γ Γ Γ (tape alphabet).
- Tape head can move both right and left, one cell per move. It read from or write to a tape.
- State control can be in any one of a finite number of states Q Q Q. It is based on: state and symbol read from tape.
- Machine has one start state, one accept state and one reject state.
- Machine can run forever: infinite loop.
Properties of Turing Machine
- Turing machine can both read from tape and write on it.
- Tape head can move both right and left.
- Tape is infinite and can be used for storage.
- Accept and reject states take immediate effect.
A Turing machine ™ is a 7-tuple M = ( Σ , Γ , Q , δ , q , q a c c e p t , q r e j e c t ) M=(\Sigma,Γ,Q,\delta,q,q_{accept},q_{reject}) M=(Σ,Γ,Q,δ,q,qaccept,qreject), where
- Σ \Sigma Σ is a finite set, called the input alphabet; the blank symbol is not contained in Σ \Sigma Σ
- Γ Γ Γ is a finite set, called the tape alphabet; this alphabet contains the blank symbol, and Σ ⊆ Γ \Sigma\subseteqΓ Σ⊆Γ
- Q Q Q is a finite set, whose elements are called states
- q q q is an element of Q Q Q; it is called the start state
- q a c c e p t q_{accept} qaccept is an element of Q Q Q; it is called the accept state
- q r e j e c t q_{reject} qreject is an element of Q Q Q; it is called the reject state, q r e j e c t ≠ q a c c e p t q_{reject}\ne q_{accept} qreject=qaccept
- δ \delta δ is called the transition function, which is a function δ : Q × Γ → Q × Γ × { L , R , N } \delta:Q\timesΓ\rightarrow Q\timesΓ\times\{L,R,N\} δ:Q×Γ→Q×Γ×{L,R,N}
L L L: move to left, R R R: move to right, N N N: no move.
Transition function
δ ( q , a ) = ( s , b , L ) \delta(q,a)=(s,b,L) δ(q,a)=(s,b,L)
If TM
- in state q ∈ Q q\in Q q∈Q
- tape head reads tape symbol a ∈ Γ a\inΓ a∈Γ
Then TM
- moves to state s ∈ Q s\in Q s∈Q
- overwrites a a a with b ∈ Γ b\inΓ b∈Γ
- moves head left

Computation steps
- Before the computation step, the Turing machine is in a state KaTeX parse error: Undefined control sequence: \inQ at position 2: r\̲i̲n̲Q̲, and the tape head is on a certain cell.
- TM M M M proceeds according to transition function: δ : Q × Γ → Q × Γ × { L , R , N } \delta:Q\timesΓ\rightarrow Q\timesΓ\times\{L,R,N\} δ:Q×Γ→Q×Γ×{L,R,N}
- Depending on r r r and k k k symbols read from tape:
- switches to a state r ′ ∈ Q r'\in Q r′∈Q
- tape head writes a symbol of Γ Γ Γ in the cell it is currently scanning
- tape head moves one cell to the left or right or stay at the current cell.
- Computation continues until q r e j e c t q_{reject} qreject or q a c c e p t q_{accept} qaccept is entered.
- Otherwise, M M M will run forever (input string is neither accepted nor rejected)
Start configuration
The input is a string over the input alphabet Σ \Sigma Σ. Initially, this input string is stored on the first tape, and the head of this tape is on the leftmost symbol of the input string.
Computation and termination
Starting in the start configuration, the Turing machine performs a sequence of computation steps. The computation terminates at the moment when the Turing machine enters the accept state q a c c e p t q_{accept} qaccept or the reject state q r e j e c t q_{reject} qreject. (If the machine never enters q a c c e p t q_{accept} qaccept and q r e j e c t q_{reject} qreject the computation does not terminate.)
Acceptance
The Turing machine M M M accepts the input string w ∈ Σ ∗ w\in\Sigma^* w∈Σ∗ , if the computation on this input terminates in the state q a c c e p t q_{accept} qaccept.
5.1 TM Configuration
Configuration of a TM M = ( Q , Σ , Γ , δ , q , q a c c e p t , q r e j e c t ) M=(Q,\Sigma,Γ,\delta,q,q_{accept},q_{reject}) M=(Q,Σ,Γ,δ,q,qaccept,qreject) is a string u q v uqv uqv with u , v ∈ Γ ∗ u,v\inΓ^* u,v∈Γ∗ and q ∈ Q q\in Q q∈Q, and specifies that currently
- M M M is in state q q q
- tape contains u v uv uv
- tape head is pointing to the cell containing the first symbol in v v v
5.2 TM Transitions
Configuration C 1 C1 C1 yields configuration C 2 C2 C2 if the Turing machine can legally go from C 1 C1 C1 to C 2 C2 C2 in a single step. For TM M = ( Q , Σ , Γ , δ , q , q a c c e p t , q r e j e c t ) M=(Q,\Sigma,Γ,\delta,q,q_{accept},q_{reject}) M=(Q,Σ,Γ,δ,q,qaccept,qreject), suppose
- u , v ∈ Γ ∗ u,v\inΓ^* u,v∈Γ∗
- a , b , c ∈ Γ a,b,c\inΓ a,b,c∈Γ
- q i , q j ∈ Q q_i,q_j\in Q qi,qj∈Q
- transition function δ : Q × Γ → Q × Γ × { L , R } \delta:Q\timesΓ\rightarrow Q\timesΓ\times\{L,R\} δ:Q×Γ→Q×Γ×{L,R}
5.3 TM Computation
Given a TM M = ( Q , Σ , Γ , δ , q , q a c c e p t , q r e j e c t ) M = (Q,\Sigma,Γ,\delta,q,q_{accept},q_{reject}) M=(Q,Σ,Γ,δ,q,qaccept,qreject) and input string w ∈ Σ ∗ w\in\Sigma^∗ w∈Σ∗. M M M accepts input w w w if there is a finite sequence of configurations C 1 , C 2 , … , C k C_1, C_2,\dots,C_k C1,C2,…,Ck for some k ≥ 1 k≥1 k≥1 with
- C 1 C_1 C1 is the starting configuration q 0 w q0w q0w
- C i C_i Ci yields C i + 1 C_{i+1} Ci+1 for all i = 1 , … , k − 1 i=1,\dots,k-1 i=1,…,k−1 ((sequence of configurations obeys transition function δ \delta δ)
- C k C_k Ck is an accepting configuration u q a c c e p t v uq_{accept}v uqacceptv for some u , v ∈ Γ ∗ u,v\inΓ^* u,v∈Γ∗
5.4 Language accepted by TM
The language L ( M ) L(M) L(M) accepted by the Turing machine M M M is the set of all strings in Σ ∗ Σ^∗ Σ∗ that are accepted by M M M.
Language A A A is Turing-recognizable if there is a TM M M M such that A = L ( M ) A=L(M) A=L(M)
- Also called recursively enumerable or enumerable language.
- On an input w ∈ L ( M ) w\in L(M) w∈L(M), the machine M M M can either halt in a rejecting state, or it can loop indefinitely.
- Turing-recognizable not practical because never know if TM will halt.
5.5 Decider
A decider is TM that halts on all inputs
Language A = L ( M ) A=L(M) A=L(M) is decided by TM M M M if on each possible input w ∈ Σ ∗ w\in Σ^∗ w∈Σ∗, the TM finishes in a halting configuration
- M M M ends in q a c c e p t q_{accept} qaccept for each w ∈ A w\in A w∈A
- M M M ends in q r e j e c t q_{reject} qreject for each w ∈ A w\in A w∈A
A A A is Turing-decidable if ∃ ∃ ∃ TM M M M that decides A
- Also called recursive or decidable language.
- Differences to Turing-recognizable language:
- Turing-decidable language has TM that halts on every string w ∈ Σ ∗ w \in Σ^∗ w∈Σ∗
- TM for Turing-recognizable language may loop on strings w ∉ w\notin w∈/ this language
5.6 Multi-tape TM
- Each tape has its own head
- Transition determined by
- state
- the content read by all heads
- Reading and writing of each head are independent of others
A k-tape Turing machine ™ is a 7-tuple M = ( Σ , Γ , Q , δ , q , q a c c e p t , q r e j e c t ) M=(\Sigma,Γ,Q,\delta,q,q_{accept},q_{reject}) M=(Σ,Γ,Q,δ,q,qaccept,qreject) has k k k different tapes and k k k different read/write heads, where,
- Σ \Sigma Σ is a finite set, called the input alphabet; the blank symbol ϵ \epsilon ϵ is not contained in Σ \Sigma Σ.
- Γ Γ Γ is a finite set, called the tape alphabet; this alphabet contains the blank symbol ϵ \epsilon ϵ, and Σ ⊆ Γ \Sigma\subseteqΓ Σ⊆Γ
- Q Q Q is a finite set, whose elements are called states
- q q q is an element of Q Q Q; it is called the start state
- q a c c e p t q_{accept} qaccept is an element of Q Q Q; it is called the accept state
- q r e j e c t q_{reject} qreject is an element of Q Q Q; it is called the reject state
- δ \delta δ is called the transition function, which is a function δ : Q × Γ k → Q × Γ k × { L , R , N } k \delta:Q\timesΓ^k\rightarrow Q\timesΓ^k\times\{L,R,N\}^k δ:Q×Γk→Q×Γk×{L,R,N}k
Γ k = Γ × Γ × ⋯ × Γ Γ^k=Γ\timesΓ\times\cdots\timesΓ Γk=Γ×Γ×⋯×Γ
Transition function
δ : Q × Γ k → Q × Γ k × { L , R , N } k \delta:Q\timesΓ^k\rightarrow Q\timesΓ^k\times\{L,R,N\}^k δ:Q×Γk→Q×Γk×{L,R,N}k
Given δ ( q i , a 1 , a 2 , ⋯ , a k ) = ( q j , b 1 , b 2 , ⋯ , b k , L , R , ⋯ , L ) \delta(q_i,a_1,a_2,\cdots,a_k)=(q_j,b_1,b_2,\cdots,b_k,L,R,\cdots,L) δ(qi,a1,a2,⋯,ak)=(qj,b1,b2,⋯,bk,L,R,⋯,L)
5.6.1 Multi-tape TM equivalent to 1-tape TM
simulate k-tape TM using 1-tape TM
Proof
Let TM M = ( Σ , Γ , Q , δ , q , q a c c e p t , q r e j e c t ) M=(\Sigma,Γ,Q,\delta,q,q_{accept},q_{reject}) M=(Σ,Γ,Q,δ,q,qaccept,qreject) be a k-tape TM.
M M M has:
- input w = w 1 , w 2 , ⋯ , w k w=w_1,w_2,\cdots,w_k w=w1,w2,⋯,wk
- other tapes contain only blanks ϵ \epsilon ϵ
- each head points to first cell.
Construct 1-tape TM M ′ M^\prime M′ by extending tape alphabet Γ ′ = Γ ∪ Γ ˙ ∪ { # } Γ^\prime=Γ\cup\dot{Γ}\cup\{\#\} Γ′=Γ∪Γ˙∪{#}where Γ ˙ \dot{Γ} Γ˙ contains the head positions of different tapes. These positions are marked by dotted symbol.
For each step of k-tape TM M M M, 1-tape M ′ M^\prime M′ operates its tape as:
- At the start of the simulation, the tape head of M ′ M^\prime M′ is on the leftmost # \# #
- Scans the tape from first # \# # to ( k + 1 ) s t # (k+1)st~\# (k+1)st # to read symbols under heads.
- Rescans to write new symbol and move heads.
Turing recognizable & Multiple-tape TM
Language L L L is TM-recognizable if and only if some multi-tape TM recognizes L L L.
5.7 Nondeterministic TM
A nondeterministic Turing machine (NTM) M can have several options at every step. It is defined by the 7-tuple M = ( Σ , Γ , Q , δ , q , q a c c e p t , q r e j e c t ) M=(\Sigma,Γ,Q,\delta,q,q_{accept},q_{reject}) M=(Σ,Γ,Q,δ,q,qaccept,qreject), where
- Σ \Sigma Σ is input alphabet (withoutblank)
- Γ Γ Γ is tape alphabet with { ϵ } ∪ Σ ⊆ Γ \{\epsilon\}\cup\Sigma\subseteqΓ {ϵ}∪Σ⊆Γ
- Q Q Q is a finite set, whose elements are called states
- δ \delta δ is transition function δ : Q × Γ → P ( Q × Γ × { L , R } ) \delta:Q\timesΓ\rightarrow P(Q\timesΓ\times\{L,R\}) δ:Q×Γ→P(Q×Γ×{L,R})
- q q q is start state ∈ Q \in Q ∈Q
- q a c c e p t q_{accept} qaccept is accept state ∈ Q \in Q ∈Q
- q r e j e c t q_{reject} qreject is reject state ∈ Q \in Q ∈Q
Transition

Computation
With any input w w w, computation of NTM is represented by a configuration tree.

If ∃ \exists ∃ at least one accepting leaf, then NTM accepts.
5.7.1 Address
Every node in the tree has at most b b b children. b b b is size of largest set of possible choices for N ′ s N's N′s transition function.
- Every node in tree has an address that is a string over the alphabet Γ b = { 1 , 2 , ⋯ , b } Γ_b=\{1,2,\cdots,b\} Γb={1,2,⋯,b}
5.7.2 NTM equivalent to TM
Every nondeterministic TM has an equivalent deterministic TM.
Proof
- Build TM D D D to simulate NTM N N N on each input w w w. D D D tries all possible branches of N ′ s N^\prime s N′s tree of configurations.
- If D D D finds any accepting configuration, then it accepts input w w w.
- If all branches reject, then D D D rejects input w w w.
- If no branch accepts and at least one loops, then D D D loops on w w w.
- Initially, input tape contains input string w w w. Simulation and address tapes are initially empty.
- Copy input tape to simulation tape.
- Use simulation tape to simulate NTM N N N on input w w w on path in tree from root to the address on address tape.
- At each node, consult next symbol on address tape to determine which branch to take.
- Accept if accepting configuration reached.
- Skip to next step if
- symbols on address tape exhausted.
- nondeterministic choice invalid
- rejecting configuration reached
- Replace string on address tape with next string in Γ b ∗ Γ_b^* Γb∗ in string order, and go to Stage 2.
Turing recognizable & Multiple-tape TM
Language L is TM-recognizable if a NTM recognizes it. Multiple-tape TMs and NTMs are not more powerful than standard TMs.
Turing decidable & NTM decidable
A nondeterministic TM is a decider if all branches halt on all inputs. A language is decidable if some nondeterministic TM decides it.
5.8 Enumerable Language and Enumerator
A language is enumerable if some TM recognizes it.
An enumerator is usually represented as a 2-tape Turing machine. One working tape, and one print tape.
Language A is Turing-recognizable if some enumerator enumerates it.
5.9 Encoding
Input to a Turing machine is a string of symbols over an alphabet
When we want TMs to work on different objects, we need to encode this object as a string of symbols over an alphabet.
5.9.1 Encoding of Graph
Given an undirected graph G G G

< G >
5.9.2 TM to decide the connectedness of a Graph
An undirected graph is connected if every node can be reached from any other node by travelling along edge. Let A A A be the language consisting of strings representing connected undirected graph.
On input < G > ∈ Ω
- Check if G G G is a valid graph encoding. If not, reject.
- Select first node of G G G and mark it.
- Repeat until no new nodes marked.
- For each node in G G G, mark it if it’s attached by an edge to a node already marked.
- Scan all nodes of G G G to see whether they all are marked. If they are, accept; otherwise, reject.
Ω \Omega Ω denotes the universe of a decision problem, comprising all instances.
For TM M M M that decides A = { < G > ∣ G is a connected undirected graph } A=\{
Step 1 checks that input G ∈ Ω G∈Ω G∈Ω is valid encoding:
- Two list
- First is a list of numbers
- Second is a list of pairs of numbers
- First list contains no duplicate
- Every node in second list appears in first list
Step 2-5 check if G G G is connected.