Knowledge Distillation A Survey - 知识蒸馏综述
2020IJCV - Knowledge Distillation A Survey -arXiv2006.05525
文章目录
- 2020IJCV - Knowledge Distillation A Survey -arXiv2006.05525
-
-
- 模型压缩常见方法
- 知识蒸馏主要思想
- 本文贡献
- 知识 Knowledge
- 蒸馏方案 Distillation Schemes
- 师生架构 Teacher-Student Architecture
- 蒸馏算法 Distillation Algorithms
- 性能比较
- 应用
- 结论和讨论
-
@article{2020Knowledge,
title={Knowledge Distillation: A Survey},
author={ Gou, J. and Yu, B. and Maybank, S. J. and Tao, D. },
year={2020},
}
模型压缩常见方法
-
参数修建和共享 Parameter pruning and sharing
-
低秩因子分解 Low-rank factorization
-
转移紧凑的卷积滤波器 Transferred compact convolutional filters
-
知识蒸馏 Knowledge distillation (KD)
知识蒸馏主要思想
学生模型学习教师模型,以获得有竞争力或更加优越的表现。

本文贡献
-
提供知识蒸馏的概述,包括几种典型的知识、蒸馏和架构
-
回顾知识精馏的最新进展,包括算法和在不同现实场景中的应用
-
从知识迁移的不同视角(包括不同类型的知识、培训方案、知识迁移算法与结构、知识迁移应用等)解决知识迁移的障碍,为知识迁移提供思路。

知识 Knowledge
- 基于响应 Response-Based Knowledge
p ( z i , T ) = e x p ( z i / T ) ∑ j e x p ( z j / T ) p(z_{i}, T)= \frac{exp(z_{i}/T)}{\sum_{j}exp(z_{j}/T)} p(zi,T)=∑jexp(zj/T)exp(zi/T)
L R e s D ( p ( z t , T ) , p ( z s , T ) ) = L R ( p ( z t , T ) , p ( z s , T ) ) L_{ResD}(p(z_{t}, T), p(z_{s}, T)) = \mathcal{L}_{R}(p(z_{t}, T), p(z_{s}, T)) LResD(p(zt,T),p(zs,T))=LR(p(zt,T),p(zs,T))

- 基于特征 Feature-Based Knowledge
L F e a D ( f t ( x ) , f s ( x ) ) = L F ( Φ t ( f t ( x ) ) , Φ s ( f s ( x ) ) ) L_{FeaD}(f_{t}(x), f_{s}(x)) = \mathcal{L}_{F}(\Phi_{t}(f_{t}(x)), \Phi_{s}(f_{s}(x))) LFeaD(ft(x),fs(x))=LF(Φt(ft(x)),Φs(fs(x)))

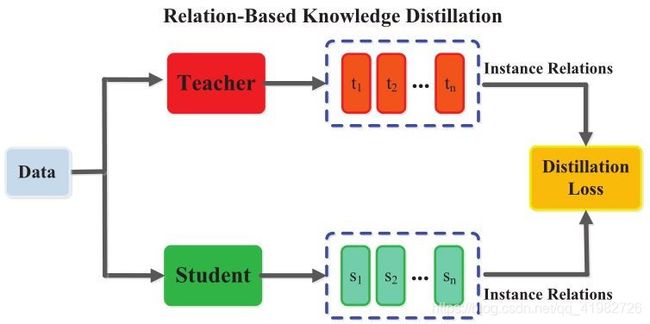
- 基于关系 Relation-Based Knowledge
L R e l D ( F t , F s ) = L R 2 ( ψ t ( t i , t j ) , ψ s ( s i , s j ) ) L_{RelD}(F_{t}, F_{s})=\mathcal{L}_{R^2}(\psi_{t}(t_{i}, t_{j}), \psi_{s}(s_{i}, s_{j})) LRelD(Ft,Fs)=LR2(ψt(ti,tj),ψs(si,sj))
蒸馏方案 Distillation Schemes
-
离线蒸馏:博学的老师教给学生知识
特点:教师模型预训练好,学生模型在教师模型指导下的离线精馏训练通常是高效的
缺点:复杂的高容量教师模型训练时间大,而且大型教师模型和小型学生模型之间的能力差距一直存在,学生往往在很大程度上依赖于老师
-
在线蒸馏:师生共同学习
特点:高效并行计算的单相端到端训练方案
问题:无法在在线设置中解决高容量教师的问题
-
自蒸馏:学生自学
特点:教师和学生使用相同的网络
师生架构 Teacher-Student Architecture
- 引入教师助理
- 使用辅助结构学习残差误差(残差学习)
- 将网络量化与知识蒸馏相结合
- 将多层学习得到的知识迁移到单层
- 块式知识迁移
- 基于高效元操作或块搜索全局结构
- 动态搜索知识迁移机制
蒸馏算法 Distillation Algorithms
-
对抗蒸馏 Adversarial Distillation
利用GAN和KD的联合产生有价值的数据,改善KD性能和克服不可用和不可访问的数据的限制,KD还可以用于压缩GANs

(a) GAN中的生成器生成训练数据以提高KD性能,这位教师可能被用作辨别人
(b) GAN中的鉴别器确保学生(也作为生成器)模仿老师
©) 教师和学生构成产生者;该方法增强了在线知识提取的能力
-
多教师蒸馏 Multi-Teacher Distillation
不同的教师网络可以为学生网络提供不同的知识

- 跨模态蒸馏 Cross-Modal Distillation

- 基于图的蒸馏 Graph-Based Distillation

-
基于注意力机制的蒸馏 Attention-Based Distillation
核心:定义嵌入神经网络各层次特征的注意力映射(attention maps),特征嵌入的知识是通过注意映射函数来传递的
-
无数据蒸馏 Data-Free Distillation
克服由于隐私、合法性、安全性和机密性担忧而导致的数据不可用问题
无训练数据,这些数据由教师网络(如GAN)生成

-
量化蒸馏 Quantized Distillation
网络量化通过将高精度网络(如32位浮点数)转换为低精度网络(如2位和8位),降低了神经网络的计算复杂度。

-
持续性蒸馏 Lifelong Distillation
持续学习、元学习
-
基于NAS(神经架构搜索)的蒸馏 NAS-Based Distillation
自动识别深度神经根模型,自适应学习合适的深度神经网络,搜索学生的网络结构
性能比较
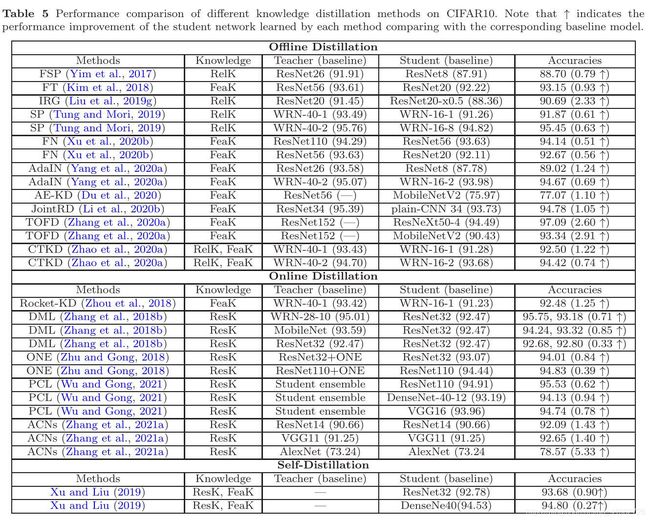
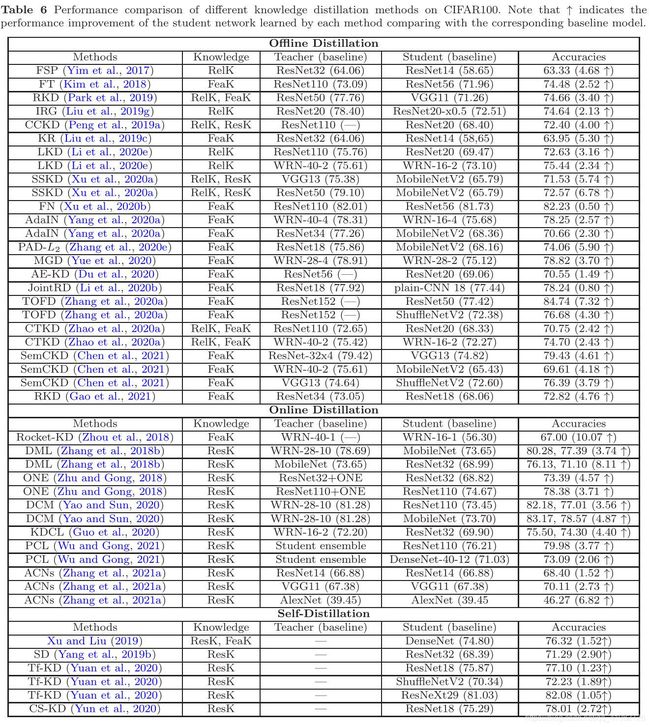
- 可以在不同深度模型上实现知识精馏
- 通过知识蒸馏可以实现不同深度模型的模型压缩
- 基于协作学习的在线知识精馏(Zhang et al., 2018b;Yao and Sun, 2020)可以显著提高深度模型的性能
- 自知识蒸馏(Yang et al., 2019b;Yuan等人,2020;刘旭,2019;Yun et al., 2020)可以很好地提高深度模型的性能
- 离线和在线的精馏方法通常分别传递基于特征的知识和基于响应的知识
- 轻量化深度模型(学生)的绩效可以通过高能力教师模型的知识转移得到提高
应用
-
视觉识别
人脸识别,图像/视频分割,动作识别,人员重新识别,目标检测,行人检测,面部地标检测,姿态估计,视频字幕,图像检索,阴影检测,显著性估计,深度估计,视觉里程测量,文本-图像合成,视频分类,视觉问答,异常检测等
-
NLP
神经机器翻译(NMT)(热门),文本生成,问答系统,事件检测,文档检索,文本识别
-
语音识别
-
其他应用
结论和讨论
-
挑战
在一个统一的、互补的框架中对不同类型的知识建模具有挑战性
为了提高知识迁移的有效性,需要进一步研究师生模型之间的关系
对知识提炼的概括性的深入理解,特别是如何衡量知识的质量或师生架构的质量,仍十分困难
-
未来方向
模型压缩和加速的方法:参数修建与共享、低秩分解、转移卷积滤波器和知识蒸馏
将知识蒸馏与上述其他方法相结合
如何确定不同压缩方法的恰当顺序
将知识蒸馏应用于一些新的问题,如数据隐私和安全等
将知识蒸馏与一切传统机器学习、深度学习方法结合
对知识提炼的概括性的深入理解,特别是如何衡量知识的质量或师生架构的质量,仍十分困难