ECCV 2022 | 从单目RGB图像中进行类别级6D物体姿态估计
作者 | CVer 编辑 | 汽车人
原文链接:https://mp.weixin.qq.com/s/RYE8R7W-5j1E2bpHSbw8yQ
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【数据集下载】获取计算机视觉近30种数据集!

题目:Object Level Depth Reconstruction for Category Level 6D Object Pose Estimation From Monocular RGB Image
原文:https://arxiv.org/abs/2204.01586
01
摘要
最近,基于RGBD的类别级6D物体姿态估计在性能上取得了很大的进步,然而,对于深度信息的需求阻碍了其更广泛的应用。为了解决这一问题,本文提出了一种 "物体深度重建网络"(OLD-Net)的新方法。该方法仅输入RGB图像进行类别级6D物体姿态估计。我们通过将类别级形状先验变形为物体级深度和规范的NOCS表示,从而实现由单目RGB图像中直接预测物体级深度。我们引入了两个新的模块,即归一化全局位置提示(NGPH)和形状感知解耦深度重建(SDDR)模块,以学习高精度的物体级深度和形状表示。最后,通过将预测的规范表征与反向投影的物体级深度对齐,解决了6D物体的姿态问题。在CAMERA25和REAL275数据集上进行的广泛实验表明,虽然我们的模型,但达到了最先进的性能。
02
本文主要工作
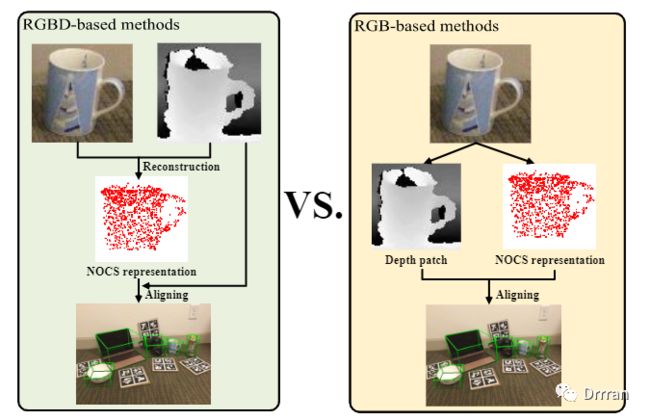
本文提出了一种基于RGB的类别级6D物体姿态估计新方法——Object Level Depth reconstruction Network(OLD-Net)。上图右示为OLD-Net的主要管道。具体而言,从输入的RGB图像中同时预测物体级深度和NOCS表示,并将两者对齐预测6D物体的姿态。与以往通过重构网格预测物体区域深度的方法不同,本文采用端到端方式直接从RGB图像中预测物体的观测深度。
要获得物体区域的深度,一种直接的方法是预测场景级深度。然而,由于视场的多样性,通常预测的景深较粗,导致物体形状细节的丢失。姿态估计性能也会受到影响。为了解决这一问题,我们通过直接学习变形类别级形状先验重构物体级深度。与预测场景级深度图相比,重建对象级深度图计算方便,能够更好地保存形状细节,有利于后续的物体级深度和NOCS表示对齐过程。
为了更好地重构物体级深度,在OLD-Net中提出了一种新的模块——归一化全局位置提示(NGPH),以平衡场景级全局信息和局部特征级形状细节。NGPH是带相机本征的归一化二维检测结果,提供物体在场景中的绝对深度的全局位置线索,以及对不同相机捕捉到的图像的泛化能力。此外,利用形状感知解耦深度重建(SDDR)方法预测形状细节和绝对深度。SDDR利用两个独立的深度网络将绝对深度解耦预测为形状点和深度平移。直观上,形状点是为了保留形状细节,而深度平移是为了预测绝对物体中心。
除深度外,我们进一步采用基于RGBD的方法预测目标对象的NOCS表示。在训练过程中使用鉴别器提高重建质量。在NOCS表示和观测到的物体级深度都被预测之后,我们将物体级深度逆向投影到点云中。通过Umeyama算法对它们进行对齐,求解出6D物体姿态。我们在CAMERA25数据集和REAL275数据集上进行了大量的实验。实验结果表明,该方法具有先进的性能。
03
网络主要结构
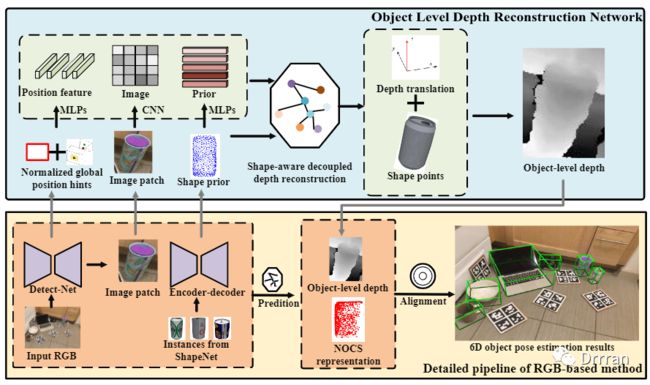
主要的OLD-Net的网络架构如上图所示。
我们的pipeline以图像 和一个形状先验 作为输入。图像由一个训练过的检测器(Detect-Net)裁剪,用以表示物体特定的信息。采用均值嵌入的编码器-解码器网络物体类别的形状先验进行预测,来解决类别差异的问题。
然后,将图像和形状先验输入到OLD-Net中,重建上图顶部所示的物体级深度。此外,OLD-Net还将来自(Detect-Net的二维检测结果和摄像机本征信息作为输入,并将其归一化为NGPH。在OLD-Net中采用一种形状感知的解耦深度重建方案来保持物体的形状细节和绝对中心。
最后,利用深度网络对NOCS表示进行预测。然后,我们将对象级深度反向投影到点云中,采用Umeyama算法恢复物体姿态。
03
OLD-Net
如上图图OLD-Net的网络结构所示,OLD-Net以图像、形状先验和NGPH为输入,首先使用两个MLP和一个CNN学习图像特征图 ,先验特征 ,位置特征 。然后,利用这些特征,利用形状感知解耦深度重构(SDDR)方案同时预测形状点和深度平移。最后,将形状点和深度平移重新组合在一起,得到物体级深度。接下来,我们详细介绍NGPH和SDDR。
规范化全局位置提示
我们的旨在直接从高质量的图像中预测物体层次的深度。实现这一目标的最直接方法是预测场景级深度图。然而,从原始图像预测场景级深度图的计算成本很高。此外,它还可能导致物体形状细节的丢失。而形状细节对于我们的管道非常重要,因为我们需要对齐两个3D表示来恢复物体的姿态。因此,我们选择以特定物体的图像作为输入来预测物体级深度。然而,由于裁剪和调整大小的操作,图像失去了目标的绝对全局位置信息,导致预测深度存在尺度模糊。为此,我们提出了NGPH,通过提供绝对全局位置信息和解决尺度模糊,很好地解决了这一问题。
我们选择Detect-Net输出的2D边界框(l, t, r, b)的参数组成NGPH,它代表左、上、右,下二维边界框的坐标。这些信息足够有效,可以提供给网络来推断尺度线索。例如,如果所有的图像都是由同一台相机捕获的,则恢复物体的绝对深度。然而,图像通常会被不同的相机收集。从单目RGB图像中推断出物体的绝对深度会受到相机本身的影响,这是一个常识。因此,我们提出将相机本征注入NGPH中。因此,经过训练的网络也可以被推广到其他由不同相机捕捉到的图像。我们通过将2D边界框和摄像机intrinsic归一化到规范坐标中来使用它们:
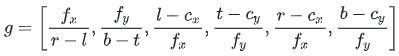
其中 表示我们使用的最终NGPH。 和 表示相机光学中心坐标, 和 表示焦距。前两个术语将对象的边界框大小与焦距归一化,消除了对象大小引起的尺度模糊。后四个术语使用边界框的焦距和大小对物体的中心进行归一化,消除了模糊性,但保留了位置信息。该方法虽然简单,但在对象级深度重构中是必不可少的。实验结果表明,NGPH虽然简单,但在物体层次深度重建中不可或缺。
形状感知解耦深度重建
OLD-Net中使用的特征是重塑后的图像特征矩阵 (其中 为像素数),位置特征 ,先验特征 。我们还应用MLPs和自适应池化 ,得到全局图像特征集 和全局先验特征集 。
形状点预测:我们采用了形状先验变形(SPD)的思想重构形状点,这将为模型提供更多的物体形状约束。具体来说,利用上述特征,网络将学习一个形变场 ,一个 ,并将先前的形状先验反向投影到对象级深度的点云中:
![]()
为了学习 ,我们重复 , , 共 次并将它们与 连接。将连接的特征输入到MLP中以学习 。类似地,为了学习 ,我们重复 , , 共 次,并将它们与 连接。另一个MLP用于学习 。在本文中,我们使用形状先验来预测对象级深度,为未来基于RGB的工作提供指导。
深度变换预测:为了学习物体中心的绝对位置,我们建议使用一个独立的MLP来学习深度平移。我们连接 和 作为输入。输出是表示对象中心绝对深度的单个值。我们把它命名为 。
SDDR方案主要从三个方面来保留对象形状细节。首先,由于我们只使用图像块来重建物体层深度,模型可以专注于物体的形状而不是整个场景的几何形状。其次,形状先验对物体的形状提供了强大的约束,使其更容易恢复形状细节。第三,分别学习绝对物体中心和物体形状,并给予不同的注意。
在 和 被预测后,对象级深度可以表示为 ,其中 为 的第三分量。注意,我们选择监督Z而不是反向投影的点云。因为一方面,网络在训练过程中更容易学习Z,另一方面,将Z逆向投影到点云上进行对齐,物体的2D坐标将为全局位置提供额外的约束,这也有利于最后的物体姿态的恢复步骤。
04
NOCS预测
我们还预测管道中目标对象的NOCS表示,这是一种规范表示,用于与物体级深度对齐,以恢复6D对象姿势。为了预测NOCS表示,我们将Z反投影到点云中,并将其输入到MLP中,以获得深度特征 。取 , , 输入,类似于重建对象级深度,我们使用SPD来预测NOCS表示:
![]()
然而,我们发现在某些情况下, 不够真实,这将影响最终的6D目标姿态估计精度。因此我们采用对抗训练策略训练网络。具体来说,我们设计了一个判别器来判断预测的NOCS表示是否足够真实。判别器的优化目标可表示为:
同样,NOCS预测网络的优化目标 : 在训练过程中,对判别器和NOCS预测网络的参数进行迭代更新。两个网络都将通过对抗变得越来越强大。因此,预测的NOCS表现也会变得越来越现实。
05
损失函数
对于物体级深度重建,我们使用Z和真实值的L1损失: 对于NOCS表示预测,我们使用损失函数包括重建的NOCS表示和真实值之间的平滑L1 loss ,倒角距离损失 ,交叉熵损失 ,以鼓励分配矩阵xmnocs的峰值分布,L2正则化损失。我们使用的总损失函数为:
![]()
06
实验
我们通过PyTorch实现我们的方法,并使用Adam优化器对其进行优化。我们在训练过程中随机选择1024像素来预测深度。Detect-Net是Mask-RCNN。使用带有ResNet-18骨干的PSPNet来学习图像特征。形状先验点数为1024。我们设C = 64, = 1024。该模型训练50个epoch,批次大小为96。主网络的初始学习率为0.0001,第40个epoch的衰减率为0.1。我们在CAMERA25数据集和REAL275数据集上进行了实验。
重建质量评价:
在我们的工作中,主要思想是重建物体级深度和NOCS表示。因此,我们首先在表1中评估我们方法的重构质量。计算反向投影深度与地面真实值之间的倒角距离,验证深度重建的质量。我们也计算预测的NOCS值与真实NOCS值之间的倒角距离评价NOCS预测质量。
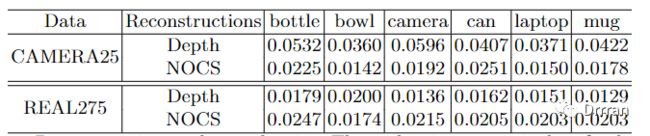
如上表所示对于物体级深度重构,REAL275数据集的误差小于2cm。对于NOCS预测,REAL275数据集的误差也接近2cm。与我们的大物体尺寸和景深相比,2厘米是一个相对较小的尺度误差。因此,我们可以得出结论,我们的方法确实具有良好的物体级深度重构质量和NOCS表示预测质量。在CAMERA25数据集上,大多数类别的NOCS表示预测误差仍在2cm以下。然而,物体级深度构造误差增加到3cm到5cm。其原因可能是在较大的合成数据集中存在较大的深度分布方差。这一观察结果还表明,重构物体级深度比预测NOCS表示更难。
6D位姿估计的定量结果:
我们将我们的方法与下表中最先进的方法进行定量比较。
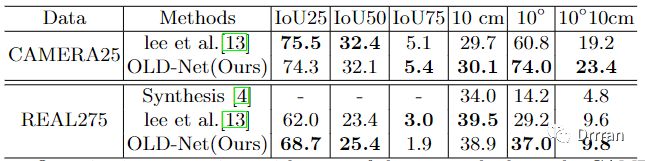
我们首先将我们的方法与Lee et al.在CAMERA25数据集上进行比较。Lee等人通过首先重建网格,然后将网格渲染成深度图来预测深度。相比之下,我们选择直接重构对象级深度,这更简单,也更有效。我们可以看到,我们的方法在6个指标中的4个指标上优于Lee et al.。在最严格的10◦10cm度量,我们的方法超过Lee等人4.2分,这是一个显著的改进。在IoU25和IoU50指标上,尽管我们的结果略低于Lee等人,但我们仍然实现了相当的性能。这些结果表明,使用我们的SDDR方案和NGPH重构对象级深度是比重构对象网格更好的选择。主要原因可能是,如果深度平移和形状点解耦,网络更容易学习有用的信息,如物体的形状细节或物体的绝对中心。
为了进一步验证我们重构物体级深度比估计场景级深度的动机和好处,我们将我们的方法与下表中的两个场景级深度估计基线进行比较。场景级基线-1和场景级基线-2共享相同的编码器-解码器网络架构。不同的是,在训练时,场景级基线-1与NOCS重构分支共享编码器,而场景级基线-2独立训练深度估计器。这两个网络都经过精心调优,以实现最佳性能。下表显示了OLD-Net显著优于两个场景级基线。原因可能是由预测的物体级深度OLD-Net在保存形状细节方面比粗糙的场景级深度要好得多,而形状细节对于NOCS深度对齐过程至关重要。

所有这些结果都证明了我们的方法的优越性。此外,我们还在下图中展示了3D IoU、旋转误差和平移误差的不同阈值下的平均精度(AP)图。我们将我们的方法与基于rgbd的NOCS方法进行比较。从图中可以看出,我们的方法在所有类别的IoU和旋转方面都表现出色。旋转预测的优异性能很大程度上是由于我们将形状点解耦到深度之外,以保留形状细节。在对准中,旋转是否准确主要取决于物体形状的质量。因此,我们的模型在旋转预测方面甚至达到了与基于rgbd的方法相当的性能。相比之下,基于rgbd的预测结果相对较低。这是因为从单目RGB图像中恢复物体的绝对全局位置是一个问题。因此,今后的工作应更加重视获得更精确的绝对深度预测。
6D位姿估计的定性结果:
为了定性分析我们方法的有效性,我们将估计的边界框可视化,如下图所示。给出了综合数据和实际数据的计算结果。可以看出,OLD-Net可以预测的物体边界框,这对于增强现实产品来说是足够准确的。在下图中我们还展示了一些失败案例。OLDNet有时可能会漏掉物体。我们把解决它作为我们未来的工作。

07
消融实验
Vanilla SPD:
我们采用SPD来学习SDDR中的形状点。人们可能会想,我们的模型的良好性能是否来自于SPD,而不是我们设计的其他模块。因此,我们展示了仅使用普通SPD模块(不使用OLD-Net,不使用SDDR,仅使用SPD直接预测对象级深度的反向投影点云)时的性能。没有我们的其他设计,Vanilla SPD的性能很差。
SDDR方案的影响:
在本文中,SDDR被引入,将物体级深度解耦为深度转换和形状点。与Vanilla SPD相比,我们在下表中的所有模型版本都采用了SDDR方案,因此,它们的性能在很大程度上得到了改善。
表中的第3行,我们没有使用两个单独的模块来独立学习深度转换和形状点,而是使用一个单一的模块直接预测绝对的物体级深度。我们发现,IoU25指标和IoU50指标下降了很多。这可能是因为如果不把深度解耦出来,网络可能会丢失物体的细节,如物体的长宽高比例或一些特定的物体成分。此外,在第4行,我们显示了用MLP代替SPD来预测形状点的结果,即直接回归NOCS和物体级深度。很明显,所有的指标都有明显的下降。这个结果证明了在SDDR中采用SPD是非常必要的。SPD为模型提供了关于物体形状的强大约束。请注意表的第3行和第4行,虽然我们删除了一些设计,但属于物体的像素的二维坐标仍被用于反向投影(它也是SDDR的一部分),这将为绝对深度提供额外的约束。否则,性能会更差,如表第2行所示,它直接预测了物体点云。总之,SDDR方案在OLD-Net中对物体形状细节的保存和绝对物体中心的预测都起着重要的作用。
NGPH的影响:
由于我们的模型只采取RGB图像来预测深度以保存形状细节,全局位置信息将被丢失。为了弥补这一缺陷,我们将NGPH注入到我们的网络中。在表的第5行中,我们将NGPH从我们的网络中移除,以研究其影响。当它被移除后,所有的指标都下降了很多。这是因为,没有NGPH,网络就很难预测绝对深度。尽管三维点之间的相对位置可以从图像中推断出来,但错误的绝对深度会使我们很难通过对齐来准确恢复物体的姿势。
我们采用对抗性训练策略来提高预测的NOCS表示的质量。当它被移除时,如表的倒数第二行所示,除了10◦指标外,所有指标都下降了。这一结果证明了对抗性训练对于提高性能是必要的。它还表明,NOCS表示的质量和对象层面的深度都很重要。两者都不能被忽视。
08
总结
本文提出了一种新的基于rgb的类别级6D目标位姿估计网络OLD-Net。利用形状先验直接预测物体层次深度是我们研究的关键。在OLD-Net中引入了归一化全局位置提示和形状感知解耦深度重构方案。我们还使用对抗性训练预测管道中对象的规范NOCS表示。在真实数据集和合成数据集上的大量实验表明,我们的方法可以实现新的最先进的性能。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
