ACL2022 | 面向中文真实搜索场景的开放域文档视觉问答数据集
每天给你送来NLP技术干货!
论文名称:DuReadervis: A Chinese Dataset for Open-domain Document Visual Question Answering
论文作者:齐乐,吕尚文,李弘宇,刘璟,张宇,佘俏俏,吴华,王海峰,刘挺
原创作者:齐乐
论文链接:https://aclanthology.org/2022.findings-acl.105/
出处:哈工大SCIR
摘要
开放域问答在现实生活中有着广泛的应用,例如搜索引擎、企业问答、医疗问答等等。然而,现有开放域问答系统通常需要消耗大量成本针对不同格式的异构文档(如PDF、网页、扫描文档等)设计特定的内容抽取算法,预先从文档中抽取文本内容作为系统的信息来源。这不仅限制了现有系统的可扩展能力,还损失了文档中的布局和视觉信息。为此,本文提出了一个全新的开放域文档视觉问答任务,直接以异构文档图像集合为信息来源回答用户提问,并提出了中文开放域文档视觉问答数据集DuReadervis。DuReadervis共包含158K文档图像和15K对问答对,主要挑战包括:1)长文档理解;2)噪声干扰;和3)多片段答案抽取。目前数据集已开源至https://github.com/baidu/DuReader/tree/master/DuReader-vis。
1. 背景
现有开放域问答系统主要以文本集合作为信息来源回答用户提问,如图1所示,现有系统通常需要花费大量成本根据不同的文档格式设计特定的内容抽取算法,预先从异构文档中抽取文本内容。这无疑限制了开放域问答系统的可扩展(scalable)能力。一个可扩展的问答系统应能同时处理各种格式文档,还可以轻松地迁移到尚未见过的文档格式中。此外,现有系统由于只抽取了文本内容,因此会损失原始文档中极有价值的布局特征(如字体大小、列表格式或表格格式等)和视觉特征(如文本颜色、图像等)。
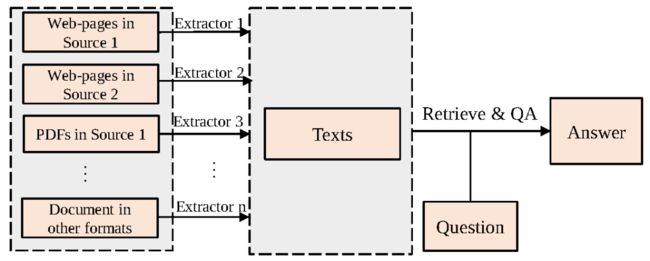
图1 开放域问答系统通用流程,需要根据文档格式和来源设计不同的内容抽取器抽取文本内容
2. 开放域文档视觉问答
为了提升开放域问答系统的可扩展能力,同时充分利用异构文档中的布局和视觉信息,本文提出了一个全新的问答任务,即开放域文档视觉问答(Open-domain Document Visual Question Answering,Open-domain DocVQA)。该任务从视觉角度描述异构文档,直接以从异构文档转换得到的文档图像集合为信息来源来回答用户提问。如图2所示,该任务通过通用抽取器(如OCR)抽取文档图像中的文本内容和布局结构,然后将这些信息连同文档图像的视觉特征应用于后续流程中。
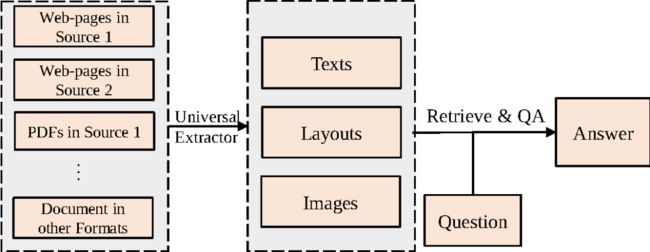
图2 开放域文档视觉问答通用流程,将不同格式文档视为文档图像,只需类似于OCR的通用抽取器抽取其中的文本内容和布局特征
与开放域问答类似,该任务也包含两个阶段:
文档视觉检索(Document Visual Retrieval,DocVRE):从原始的文档图像集合中检索和问题相关的小规模候选文档图像集合
文档视觉问答(Document Visual Question Answering,DocVQA):根据检索结果抽取单个或多个文本片段作为问题答案
3. DuReadervis
为了推动开放域文档视觉问答的发展,本文从百度搜索日志中收集用户向搜索引擎提出的真实问题和相关网页并进行了问答对的标注,提出中文开放域文档视觉问答数据集DuReadervis。相比于现有的文档视觉问答数据集[1][2][3],DuReadervis的问题面向真实用户提问,可以满足开放域的信息搜索需求。此外,DuReadervis中的文档图像均来自于互联网网页,包含丰富的文本内容和视觉特征以及复杂多样的布局结构,而且DuReadervis需要抽取格式复杂的长答案,如多片段文本型答案、列表型答案和表格型答案。表1对比了DuReadervis和现有文档视觉问答数据集。
表1 DuReadervis与其他文档视觉问答数据集的对比
| 数据集 | 任务 | 语言 | 问题来源 | 文档图像来源 | 答案类型 | 答案片段类型 |
|---|---|---|---|---|---|---|
| DocVQA[1] | 文档视觉问答 | 英文 | 众包 | 工业文档 | 抽取式 | 单片段 |
| VisualMRC[2] | 文档视觉问答 | 英文 | 众包 | 固定格式网页 | 生成式 | - |
| InfographicVQA[3] | 文档视觉问答 | 英文 | 众包 | 信息图表 | 抽取式 | 单/多片段 |
| DuReadervis | 开放域文档视觉问答 | 中文 | 搜索日志 | 开放域网页 | 抽取式 | 单/多片段 |
3.1 数据集统计分析
DuReadervis共包含158K文档图像和15K问答对,其中训练集包括11K问答对;开发集包括1.5K问答对;测试集包括2.5K问答对。
文档图像
DuReadervis中的文本内容的平均长度和文档图像的平均大小要远超于其他数据集,表明DuReadervis中的文档图像包含更丰富的文本内容和视觉特征。此外,DuReadervis中的文档图像来自于17000多个随机网站,文档主题和布局结构多样性高。另一方面,通常情况下网页中会包含大量的噪声信息,会对模型理解文档产生干扰。
问题和答案
现有文档视觉问答数据集中的问题主要为事实类问题。而在DuReadervis中,问题类型同时包含事实类和非事实类问题。本文随机筛选了200条问题人工进行分类,发现43%的问题是非事实类问题。DuReadervis中的答案平均长度也要远长于其他数据集中的答案平均长度。此外,DuReadervis的答案格式复杂,包含约40%的文本型答案、25%的列表型答案和35%的表格型答案。在列表型和表格型答案中,很多答案都是不连续的,需要抽取多片段答案。
表2 数据集统计特征
| 数据集 | 文档平均长度 | 图像平均大小 | 答案平均长度 |
|---|---|---|---|
| DocVQA[1] | 151.46 | (2084,1776) | 2.43 |
| VisualMRC[2] | 182.75 | - | 9.55 |
| InfographicVQA[3] | 217.89 | (2541,1181) | 1.60 |
| DuReadervis | 1986.21 | (4316,2054) | 180.54 |
3.2 数据集挑战
总体而言,DuReadervis的主要挑战包括以下三点:
长文档理解:DuReadervis中的文档图像均转换自互联网页面,包含更长的文本内容、更丰富的视觉特征和复杂的布局结构;
噪声干扰:来自于网页的文档图像中会包含大量噪声信息,例如广告、相关推荐等,增大了文档图像的理解难度;
多片段答案抽取:DuReadervis中的答案格式更加复杂,包含文本、列表和表格型答案,需要模型抽取多片段长答案。
3.3 数据集样例
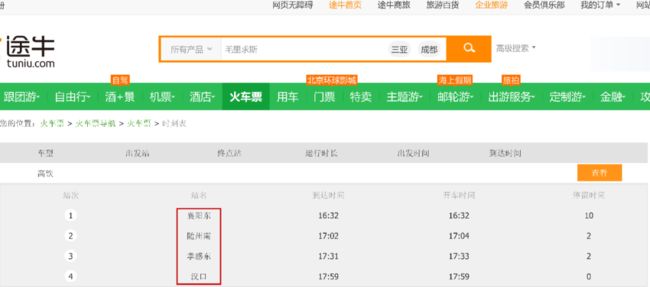
图3 DuReadervis中的表格型多片段答案数据样例,问题为“g6874经过站点”,文档图像中红框标注的文本为问题答案
图3展示了DuReadervis中一个表格型多片段答案的数据样例。在该样例中,系统需要抽取出位于“站点”这一列中所有单元格的文本内容。传统的开放域问答系统可以通过设计特殊的内容抽取算法可以很好地去除表格外的噪声干扰,但提取的文本内容很难保留表格的布局结构,系统很难得知不同单元格文本内容间的语义关联。相比之下,开放域文档视觉问答系统则可以通过表格的布局特征更轻松地建模单元格文本内容间的语义关联,通过“站点”这一列标题找到问题的答案。
4. 基线方法
本文为DuReadervis提出了一个基线方法。该方法包括三部分:
基于PaddleOCR的通用内容抽取:利用PaddleOCR技术从文档图像中抽取文本内容和布局结构作为系统输入;
基于BM25的文档视觉检索:根据抽取出的文本内容构建检索库,再利用BM25算法检索相关文档图像;
基于层次化LayoutXLM的文档视觉问答:为了从候选文档图像中抽取问题答案,本文提出了层次化LayoutXLM模型。如图4所示,该模型利用层次化建模的方式建模DuReadervis中的长文本内容,并通过基于CRF的序列标注算法抽取多片段答案。其中,LayoutXLM[4]是以文本、布局和视觉特征为输入的面向多语言跨模态文档的预训练模型。
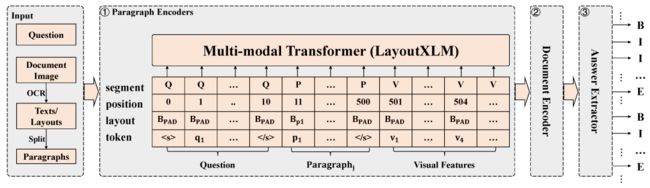
图4 层次化LayoutXLM模型架构
5. 实验
5.1 实验设置
为了验证所提方法的有效性,本文在文档视觉问答和开放域文档视觉问答任务上进行了实验,将层次化LayoutXLM与基于纯文本预训练模型的层次化RobertaXLM[5]以及层次化BERT[6]进行对比。其中,在开放域文档视觉问答实验中,本文使用BM25算法检索回与问题最相关的文档图像进行答案抽取。两个任务的评价指标均为F1和Rouge-L。
5.2 实验结果
表3 文档视觉问答实验结果
| 模型 | Rouge-L | F1 |
|---|---|---|
| Human | 89.74 | 90.20 |
| 层次化BERT | 47.31 | 49.02 |
| 层次化RobertaXLM | 48.57 | 50.53 |
| 层次化LayoutXLM | 53.10 | 54.61 |
表4 开放域文档视觉问答实验结果
| 模型 | Rouge-L | F1 |
|---|---|---|
| BM25+层次化BERT | 29.44 | 33.53 |
| BM25+层次化RobertaXLM | 30.40 | 33.69 |
| BM25+层次化LayoutXLM | 33.89 | 37.47 |
如表3和表4所示,相比于基于纯文本预训练模型的方法,层次化LayoutXLM的性能有明显提高,然而其整体性能仍与人类表现有一定差距。这表明,一方面布局结构和视觉特征有助于模型理解文档图像,另一方面无论是文档视觉问答亦或是开放域文档视觉问答均有着较大的提升空间。
6. 结论
本文为了提高开放域问答系统的可扩展能力,使其可以用较低的成本以不同格式的异构文档作为其信息来源,提出了一个全新的开放域文档视觉问答任务,直接以从异构文档转换得到的文档图像集合来回答用户提问。为了推动该任务的发展,本文提出了中文开放域文档视觉问答数据集DuReadervis,包含158K文档图像和15K问答对。DuReadervis包含三个挑战:1)长文档理解;2)噪声干扰;3)多片段答案抽取。同时,本文提出了一个基线系统并进行了实验,实验结果表明现有基线系统和人类表现仍有一定差距,开放域文档视觉问答任务仍有较大的提升空间。除研究目的外,开放域文档视觉问答的相关技术已初步应用于诸如汽车、电子、银行等行业的问答系统中,并在飞桨AI Studio上开放(https://aistudio.baidu.com/aistudio/projectdetail/4049663)。
参考文献
[1] Mathew M, Karatzas D, Jawahar C V. Docvqa: A dataset for vqa on document images. WACV 2021.
[2] Tanaka R, Nishida K, Yoshida S. VisualMRC: Machine Reading Comprehension on Document Images. AAAI 2021.
[3] Mathew M, Bagal V, Tito R, et al. InfographicVQA. WACV 2022.
[4] Xu Y, Lv T, Cui L, et al. LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding. arXiv:2104.08836, 2021.
[5] Conneau A, Khandelwal K, Goyal N, et al. Unsupervised Cross-lingual Representation Learning at Scale. ACL 2020.
[6] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
本期责任编辑:冯骁骋
本期编辑:彭 湃
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing