ConvMAE:当掩码卷积遇见掩码自编码器
原文:Gao P, Ma T, Li H, et al. ConvMAE: Masked Convolution Meets Masked Autoencoders[J]. arXiv preprint arXiv:2205.03892, 2022.
源码:https://github.com/Alpha-VL/ConvMAE
Vision Transformer(ViT)已成为各种视觉任务广泛采用的架构。用于特征预训练的掩码自编码方法和多尺度混合convolution-transformer架构可以进一步释放ViT的潜力,使其在图像分类、目标检测和语义分割方面获得SOTA性能。在本文中,我们提出的ConvMAE框架证明,多尺度混合convolution-transformer架构可以通过掩码自编码方法学到更多具有辨识性的表示。然而,直接使用原始掩码策略会导致计算量大、预训练-微调差异等问题。为了解决这一问题,我们采用了掩码卷积来防止卷积块中的信息泄露。为了保证计算效率,我们提出了一种简单的分块掩码策略。与MAE-Base相比,ConvMAE-Base在ImageNet-1k上的微调精度提高了1.4%。在COCO 2017目标检测任务上,微调了25轮的ConvMAE-Base比微调了100轮的MAE-Base高出2.9% AP box和2.2% AP Mask。
★ 相关工作
-
MAE(掩码自编码器)是可扩展的计算机视觉自监督学习方法
-
BEiT:图像Transformer的BERT式预训练
-
ViT:一图胜千言,用于大规模图像识别的Transformer
-
Swin Transformer:基于移动窗口的分层视觉Transformer
-
MoCo v3:自监督ViT训练的实证研究
-
DINO:自监督ViT的新特性
★ 论文故事
自监督学习框架,如DINO、MOCO-V3、MAE等,释放了Vision Transformers(ViT)的潜力,并在各种下游视觉任务上实现了高性能的表现。其中,掩码自编码器(MAE)表现出优异的学习能力和可扩展性。受自然语言处理领域BERT的启发,MAE采用了非对称编码器和解码器架构,其中编码器的掩码token由解码器重建。实验表明,MAE可以在不依赖大规模数据集(如ImageNet-22K)的情况下,从ImageNet-1K中学到有辨识性和可扩展的表示。
为了提高ViT的性能,研究者们探索了局部归纳偏置和层次化表示。局部卷积运算和全局transformer运算的结合使图像分类、目标检测和语义分割任务得到了明显的改进。与MAE相比,建立在局部和全局运算基础上的性能良好的多尺度骨干网络主要以有监督的方式进行训练。一个自然的问题是,是否可以利用具有局部和全局运算的多尺度骨干网络来增强掩码自编码范式。
本文提出了一种简单有效的自监督学习框架ConvMAE,通过在掩码自编码器中引入混合convolution-transformer架构和掩码卷积来训练可扩展的表示。尽管对原始MAE的修改很小,但ConvMAE在预训练视觉表示以提高各种任务的性能方面取得了巨大成功。
与MAE不同的是,ConvMAE的编码器将输入图像逐步抽象为多尺度token嵌入,而解码器则重建与掩码token对应的像素。对于前期的高分辨率token嵌入,我们采用卷积块对局部内容进行编码。对于后期的低分辨率token嵌入,我们使用transformer块融合全局上下文信息。因此,编码器在不同阶段获得局部和全局的感受野(FOV),并生成具有辨识性的多尺度特征。需要注意的是,ConvMAE编码器受到混合convolution-transformer骨干网络的启发,包括Co-AtNet、Early Convolution、Container和Uniformer。然而,之前的混合convolution-transformer网络要么没有探索掩码自编码,要么表现出与MAE非常相似的性能。我们没有设计新的架构,而是聚焦于把基本的混合convolution-transformer架构用于掩码自编码方法,并进行了大量实验,以证明其在各种下游任务中的有效性。
ConvMAE的高效训练是通过一种带有掩码卷积的分块掩码策略实现的。当前掩码自编码框架(如BEiT、MAE、SimMIM)中采用的掩码策略不能简单地用于ConvMAE,因为所有的token都需要在后期的transformer阶段保留。这导致大模型预训练的计算成本过高,失去了MAE在transformer编码器中省略掩码token的效率优势。此外,直接使用convolution-transformer编码器进行预训练会导致预训练-微调不一致,因为在微调阶段只处理可见的token。
为了解决这些问题,我们重点设计了适用于掩码自编码方法的混合convolution-transformer架构。具体来说,我们的ConvMAE采用了一种分块掩码策略,首先为transformer的后期阶段获得一个掩码,然后在前期卷积阶段逐步将该掩码上采样到更大的分辨率。这样,后期阶段处理的token可以完全分离为掩码token和可见token,并继承MAE的计算效率。为了防止信息泄漏,我们在前期阶段的卷积块中加入了掩码卷积,避免了后期阶段掩码区域和可见区域的特征混淆,保证了训练的有效性。掩码卷积在稀疏特征提取和图像修复中得到了很好的研究。它可以自然地集成到混合convolution-transformer架构中,以实现掩码自编码。
我们的ConvMAE可以自然地为目标检测和语义分割提供多尺度特征,这是现代检测和分割框架所需要的。与MAE相比,预训练的ConvMAE多尺度特征可以显著提高目标检测和语义分割的性能。基于掩码自编码的ConvMAE甚至可以超过有监督预训练的Swin和MViT。
综上所述,我们的贡献总结如下:(1)我们提出了强大而高效的自监督框架ConvMAE,该框架易于实现,并且在多项任务上表现出色。(2)ConvMAE能够自然地生成层次化表示,并在目标检测方面表现出良好的性能。(3)与MAE-Base相比,ConvMAE-Base在ImageNet上的微调精度提高了1.4%。在COCO 2017上,ConvMAE-Base使用Mask-RCNN实现了53.2%的AP box和47.1%的AP Mask,并且只训练了25轮,而MAE-Base实现了50.3%的AP box和44.9%的AP Mask,却训练了100轮。在ADE20K上, ConvMAE-Base超过MAE-Base 3.6 mIoU (48.1% vs. 51.7%)。
★ 模型方法
掩码自编码器(MAE)是一种自监督方法,通过从可见的RGB patches重建掩码的RGB patches来预训练ViT。MAE的设计虽然简单,但已被证明是一个强大的、可扩展的视觉表示学习预训练框架。如下图所示,MAE由基于transformer的编码器和解码器组成,编码器处理可见的tokens,解码器处理掩码的tokens,通过重建图像来学习视觉表示。由于编码器只需处理一小部分可见的tokens,因此它可以缓解大模型预训练的可扩展性问题。

ConvMAE是MAE的一个简单而有效的衍生工作,对编码器的设计和掩码策略进行了最小限度但有效的修改。ConvMAE的目标是学习有辨识性的多尺度视觉表示,并防止应用convolution-transformer网络时出现的预训练-微调差异。
直接对convolution-transformer编码器的特征映射应用原始掩码策略,会使transformer层在预训练时保留所有token,从而影响训练效率。我们在卷积阶段引入了一种分层掩码策略,该策略与掩码卷积相结合,确保只有少量的可见token被输入到transformer层。ConvMAE的总体流程如图1所示。

图1:ConvMAE主要由以下部分组成:混合convolution-transformer编码器、基于掩码卷积的分块掩码策略、多尺度解码器。

图2:对ConvMAE进行微调,并将其用到目标检测和语义分割任务上。
★ 实验结果
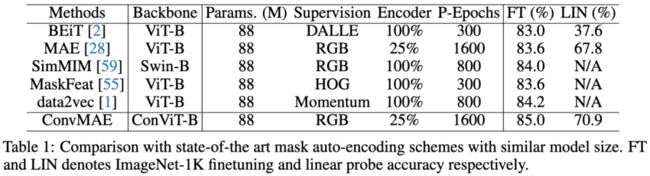
表1:ConvMAE与其他掩码自编码方法的比较。
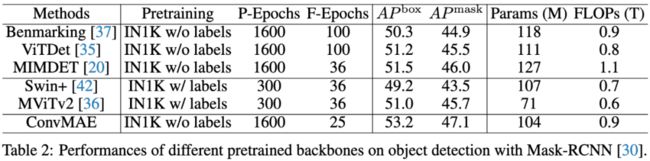
表2:在目标检测任务上,不同骨干网络性能的比较。

表3:在ADE20k数据集上,不同骨干网络性能的比较。

表3:在Kinetics-400和Something-Something-v2数据集上的微调精度。

表4:增加预训练轮数对各种下游任务的影响。

图4:MAE和ConvMAE在各种任务上的收敛情况。

表5:关于masked conv, block masking, kernel size的消融研究。

表6:关于多尺度解码器的消融研究。

表7:ConvMAE架构的细节。

表8:关于模型大小的消融研究。
★ 总结讨论
我们提出了一种简单的自监督学习框架ConvMAE,该框架证明了混合局部-全局模块可以提高MAE的性能,从而生成具有辨识性的多尺度特征。ConvMAE可以很好地保持原MAE的计算效率和较小的预训练-微调差异。ConvMAE在各种视觉任务上表现出色,并且易于实现。未来,我们将把ConvMAE和改进的重建目标结合起来进行研究。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号,一起进步^_^↑