【计算机视觉】小目标检测优化专题
前言
小目标检测长期以来是计算机视觉中的一个难点和研究热点。在深度学习的驱动下,小目标检测已取得了重大突破,并成功应用于国防安全、智能交通和工业自动化等领域。本文致力于分析和整理一些前沿的小目标检测算法研究,并给出一些自己的思考和实践心得!
注:个人比较喜欢paperswithcode网站上查看对应的专题论文,推荐给大家:Small Object Detection | Papers With Code

论文分析
1.Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection

(paper:https://arxiv.org/abs/2202.06934 ,code:https://github.com/obss/sahi)
摘要:场景中的小物体检测是视频监控的主要挑战。这类物体由于图像中的像素占比较少,缺乏足够的细节,因此难以使用传统目标检测方法进行检测。本文提出了一个名为 Slicing Aided Hyper Inference (SAHI) 的开源框架,它为小目标检测提供了一个通用的切片辅助推理和微调Pipeline。它可以应用在任何现有的目标检测网络上。在 Visdrone 和 xView 无人机目标检测数据集的实验评估表明,所提出的推理方法可以分别将 FCOS、VFNet 和 TOOD 检测器的目标检测 mAP 提高 6.8%、5.1% 和 5.3%。另外,通过切片辅助微调可以进一步提高检测精度,mAP在原来基础上增加12.7%、13.4%和14.5%。

方法
和滑动窗口的思想类似,作者将图像分割成多个重叠的切片slices。这样就使得输入网络的图像的小目标占比较高。
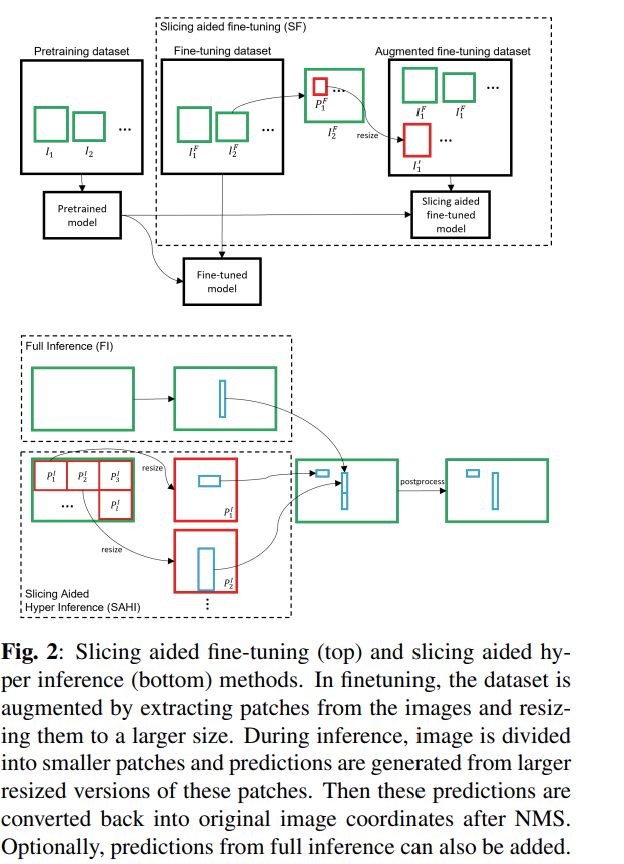
先说第一个虚线框(Slicing aided fine-tuning)和 Fig.2 展示的那样,其中 I1F,I2F,...,IjF 是原始的图片,每个图片被切分为有重叠的patches, P1FP2F,...,PkF ,有M个维度,在fine-tuning过程中,保持每个patch的横纵比,调整所有patches的大小,resized到800至1333像素之间。得到新的增强过后的图片 I1′,I2′,...,Ik′ 。通过切片叠加后的新图像与原来图像相比要大一些。
注意:切片,然后叠加的操作可能会影响大目标的检测效果。
再说第二和第三个虚线框(Slicing Aided Hyper Inference)在推理过程中,也使用切片的方法。首先将原始图 I 片切为 P1I,P2I,...,PlI 。然后同样的在保持横纵比的前提下进行resize,对每个patches进行单独的前向推理。原始图像的推理可以用来检测较大的目标。最后使用NMS将两者(第二和第三个虚线框)的结果合并回原始的大小。
实验
作者将本文提出的切片操作进行实验。将其集成到FCOS,VarifocalNet,TOOD的目标检测网络中。在VisDrone和xView两个数据集上进行实验。

作者使用随机设定的patches大小,对于VisDrone数据集的patches大小在480到640之间,对于xView数据集的patches的补丁在800到1333像素之间(保持原始横纵比)。NMS阈值=0.5。
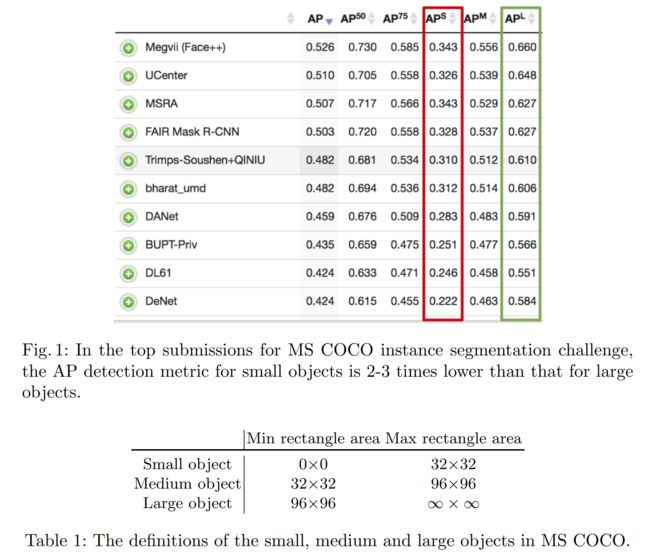
从Table 1可以看出,SAHI将目标检测的AP分别提高了6.8%,5.1%和5.3%。使用SF可以进一步提高检测精度,使得分别累计增加12.7%,13.4%和14.5%。应用重叠区域大小为25%。
总结:经过SAHI之后,整体AP均有所提升。不过同样需要注意的是对于大目标(AP50l),经过SAHI之后,AP反而有所下降。个人猜测可能是因为切片太小导致大目标被分割。
注:这里小目标的定义是宽度小于图像宽度的1%。
2.Augmentation for small object detection

(paper:https://arxiv.org/pdf/1902.07296v1.pdf, code:https://github.com/finepix/small_object_augmentation)
摘要:近年来,目标检测取得了令人瞩目的进展。尽管有这些改进,但在检测小物体和大物体的性能上仍有很大的差距。作者在一个具有挑战性的数据集MS COCO上分析了当前最先进的模型Mask-RCNN。作者证明了小的地面真实物体和预测锚点之间的重叠远低于预期的IoU阈值。作者推测这是由于两个因素:(1)只有少数图像包含小物体,(2)小物体即使在包含它们的每张图像中也没有足够的出现。因此,作者建议用小对象对这些图像进行过采样,并通过多次复制粘贴小对象来增强每个图像。它允许作者在大物体和小物体上权衡探测器的质量。作者评估了不同的粘贴增强策略,最终,与MS COCO上目前最先进的方法相比,作者在实例分割上取得了9.7%的相对改进,在小对象的对象检测上取得了7.1%的相对改进。
现有解决方案通常在小型物体上表现不佳,其中小型物体在MS COCO的情况下如表1中所定义:
小物体检测在许多下游任务中至关重要。在汽车的高分辨率场景照片中检测小物体或远处的物体是安全地部署自驾车的必要条件。许多物体,例如交通标志或行人,在高分辨率图像上几乎看不到。在医学成像中,早期检测肿块和肿瘤对于进行准确的早期诊断至关重要,因为这些元素很容易只有几个像素。通过在材料表面上可见的小缺陷的定位,自动工业检查还可以受益于小物体检测。另一个应用是卫星图像分析,其中必须有效地注释诸如汽车,船舶和房屋之类的物体。平均每像素分辨率为0.5-5m,这些对象的大小只有几个像素。换句话说,小物体检测和分割需要更多关注,因为在现实世界中部署了更复杂的系统。因此,作者提出了一种改进小物体检测的新方法。

作者专注于最先进的物体探测器Mask R-CNN和数据集MS COCO上。作者注意到该数据集关于小对象的两个属性。首先,在数据集中包含小对象的图像相对较少,这可能会使任何检测模型更多地偏向于关注中型和大型对象。其次,小物体所覆盖的区域要小得多,这意味着小物体的位置缺乏多样性。作者猜想,当物体检测模型出现在图像的较少探索的部分时,难以在测试时间内推广到小物体。
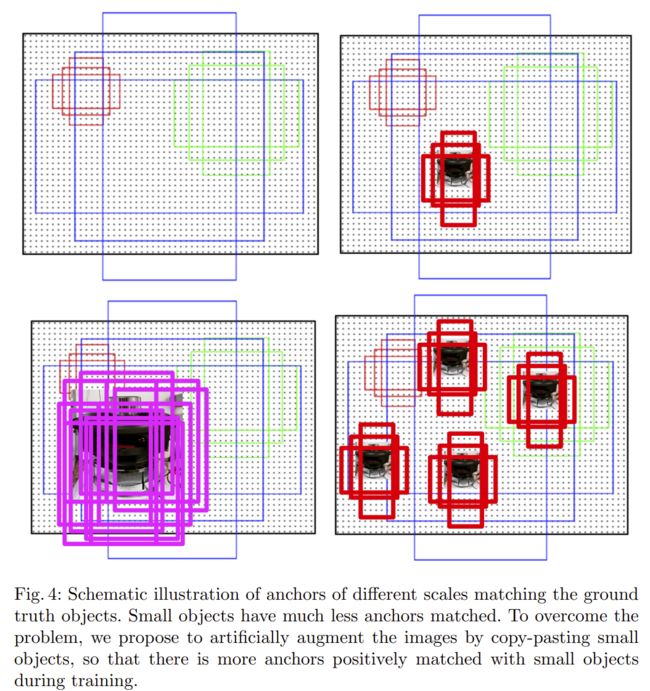
作者通过对包含小对象的图像进行过采样来解决第一个问题。第二个问题是通过在包含小对象的每个图像中多次复制粘贴小对象来解决。粘贴每个对象时,作者确保粘贴的对象不与任何现有对象重叠。这增加了小物体位置的多样性,同时确保这些物体出现在正确的上下文中,如图3所示。每个图像中小物体数量的增加进一步解决了少量正匹配锚点的问题。我们在第3节中进行了定量分析。总体而言,在MS COCO中与目前最先进的方法Mask R-CNN相比,实例分割的相对改进率为9.7%,小物体的物体检测率为7.1%。
目标检测 (Object Detection)的相关工作
更快的基于区域的卷积神经网络( Faster region-based convolutional neural network,Faster R-CNN),基于区域的完全卷积网络( Region-based fully convolutional network,R-FCN)和单射击检测器(Single Shot Detector,SSD)是对象检测的三种主要方法,它们根据区域提案是否以及在何处而不同连接。 Faster R-CNN及其变体旨在帮助处理各种对象尺度,因为差异裁剪将所有提议合并为单个分辨率。 然而,这发生在深度卷积网络中,并且所得到的裁剪框可能与对象不完全对齐,这可能在实践中损害其性能。 SSD最近扩展到解卷积单发探测器(Deconvolutional Single Shot Detector,DSSD),它通过解码器部分中的转置卷积对SSD的低分辨率特征进行上采样,以增加内部空间分辨率。 类似地,特征金字塔网络( Feature Pyramid Network,FPN)利用解码器类型的子网络扩展 Faster R-CNN。
小目标(Small objects):
检测小物体可以通过增加输入图像分辨率[7,26]或通过融合高分辨率特征与低分辨率图像[36,2,5,27]的高维特征来解决。 然而,这种使用较高分辨率的方法增加了计算开销,并且没有解决小物体和大物体之间的不平衡。 [22]而是使用生成对抗网络( Generative Adversarial Network,GAN)在卷积网络中构建特征,这些特征在交通标志和行人检测的上下文中的小对象和大对象之间难以区分。 [12]在区域提案网络中使用基于不同分辨率层的不同锚定比例。 [13]通过锚尺寸的正确分数来移动图像特征以覆盖它们之间的间隙。 [6,33,8,19]在裁剪小对象提案时添加上下文。
在MS COCO检测挑战中,主要评估指标是平均精度(average precision,AP)。 通常,AP被定义为所有召回值的真阳性与所有阳性的比率的平均值。 因为对象需要被定位和正确分类,所以如果预测的掩模或边界框具有高于0.5的交叉结合( intersection-over-union,IoU),则正确的分类仅被计为真正的正检测。 AP分数在80个类别和10个IoU阈值之间取平均值,均匀分布在0.5和0.95之间。 指标还包括跨不同对象尺度测量的AP。 在这项工作中,我们的主要兴趣是关于小物体的AP。
Mask R-CNN:
对于我们的实验,我们使用[16]中的Mask R-CNN实现和ResNet-50 backbone,并调整[17]中提出的线性缩放规则来设置学习超参数。我们使用比[16]中的基线更短的训练计划。我们使用0.01的基本学习率训练分布在四个GPU上的36k迭代模型。为了优化,我们使用随机梯度下降,动量设置为0.9,权重衰减,系数设置为0.0001。在24k和32k迭代之后,在训练期间,学习率按比例缩小0.1倍。所有其他参数保留在[16]的基线Mask R-CNN + FPN + ResNet-50配置中。
在我们的调查中,网络的区域提案阶段尤为重要。我们使用特征金字塔网络( feature pyramid network,FPN)来生成对象提议[24]。它预测了相对于五个尺度(32, 62, 122 , 256, 512)^2和三个纵横比(1, 0.5, 2)的十五个锚箱的对象建议。如果锚具有高于0.7的IoU对抗任何地面实况框,或者如果它具有针对地面实况边界框的最高IoU,则锚接收正标签。
Small object detection by Mask R-CNN on MS COCO
在MS COCO中,训练集中出现的所有对象中有41.43%是小的,而只有34.4%和24.2%分别是中型和大型对象。 另一方面,只有约一半的训练图像包含任何小物体,而70.07%和82.28%的训练图像分别包含中型和大型物体。 请参阅表2中的(Object Count and Images)对象计数和图像。这确认了小对象检测问题背后的第一个问题:使用小对象的示例较少。
通过考虑每个尺寸类别的总对象面积(Total Object Area),可以立即看出第二个问题。 仅有1.23%的带注释像素属于小对象。 中等大小的对象占用面积的8倍以上,占总注释像素的10.18%,而大多数像素,82.28%被标记为大对象的一部分。在该数据集上训练的任何探测器都没有看到足够的小物体情况,包括图像和像素。
如本节前面所述,来自区域提案网络的每个预测锚点如果具有最高的IoU具有地面实况边界框或者如果其具有高于0.7的任何地面实况框的IoU,则接收正标签。这个过程非常适合大型物体,因为跨越多个滑动窗口位置的大型物体通常具有带有许多锚箱的高IoU,而小物体可能仅与具有低IoU的单个锚箱匹配。如表2所列,只有29.96%的正匹配锚与小物体配对,而44.49%的正匹配锚与大物体配对。从另一个角度来看,它意味着每个大对象有2.54个匹配的锚点,而每个小对象只有一个匹配的锚点。此外,正如平均最大(Average Max IoU )IoU度量标准所揭示的那样,即使是小物体的最佳匹配锚箱通常也具有低IoU值。小物体的平均最大IoU仅为0.29,而中型和大型物体的最佳匹配锚点分别为IoU,0.57和0.66的两倍。我们在图中说明了这种现象。 5通过可视化几个例子。这些观察结果表明,小型物体对计算区域建议损失的贡献要小得多,这使得整个网络偏向于大中型物体。
过采样和增强(Oversampling and Augmentation)
我们通过明确解决上一节中概述的MS COCO数据集的小对象相关问题,提高了对象检测器在小对象上的性能。 特别是,我们对包含小对象的图像进行过度采样并执行小对象增强,以鼓励模型更多地关注小对象。 虽然我们使用Mask R-CNN评估所提出的方法,但它通常可用于任何其他对象检测网络或框架,因为过采样和增强都是作为数据预处理完成的。
Oversampling(过采样)
我们通过在训练期间对这些图像进行过采样来解决包含小对象的相对较少图像的问题[4]。 这是一种轻松而直接的方法,可以缓解MS COCO数据集的这一问题并提高小对象检测的性能。 在实验中,我们改变过采样率并研究过采样的影响,不仅对小对象检测,而且对检测中大对象。
Augmentation(增强)
除了过采样之外,我们还引入了专注于小对象的数据集扩充。 MS COCO数据集中提供的实例分割掩码允许我们从其原始位置复制任何对象。 然后将副本粘贴到不同的位置。 通过增加每个图像中的小对象的数量,匹配的锚的数量增加。 这反过来又改善了小对象在训练期间计算RPN的损失函数的贡献。
在将对象粘贴到新位置之前,我们对其应用随机转换。 我们通过将对象大小改变±20%并将其旋转±15°来缩放对象。 我们只考虑非遮挡对象,因为粘贴不相交的分割遮罩与中间不可见的部分通常会导致不太逼真的图像。 我们确保新粘贴的对象不与任何现有对象重叠,并且距图像边界至少五个像素。
在图4中,我们以图形方式说明了所提出的增强策略以及它如何在训练期间增加匹配锚点的数量,从而更好地检测小物体。
Experimental Setup(实验参数设置)
- Oversampling
在第一组实验中,我们研究了包含小物体的过采样图像的影响。 我们改变了两个,三个和四个之间的过采样率。 我们创建了多个图像副本,而不是实际的随机过采样,这些图像与小对象脱机以提高效率。
- Augmentation
在第二组实验中,我们研究了使用增强对小物体检测和分割的影响。 我们复制并粘贴每个图像中的所有小对象一次。 我们还用小物体对图像进行过采样,以研究过采样和增强策略之间的相互作用。
我们测试了三种设置。 在第一个设置中,我们用带有复制粘贴的小对象的小对象替换每个图像。 在第二个设置中,我们复制这些增强图像以模拟过采样。 在最终设置中,我们保留原始图像和增强图像,这相当于用小对象对图像进行过采样两倍,同时用更小的对象扩充复制的副本。
- Copy-Pasting Strategies
有不同的方法来复制粘贴小对象。 我们考虑三种不同的策略。 首先,我们在图像中选择一个小对象,并在随机位置复制粘贴多次。 其次,我们选择了许多小物体,并在任意位置复制粘贴这些物体一次。 最后,我们在随机位置多次复制粘贴每个图像中的所有小对象。 在所有情况下,我们使用上面第三个增强设置; 也就是说,我们保留原始图像和增强副本。
Pasting Algorithms
粘贴小对象的副本时,有两件事需要考虑。 首先,我们必须确定粘贴的对象是否会与任何其他对象重叠。 虽然我们选择不引入任何重叠,但我们通过实验验证它是否是一个好策略。 其次,是否执行额外的过程来平滑粘贴对象的边缘是一种设计选择。 我们试验具有不同滤波器尺寸的边界的高斯模糊与没有进一步处理相比是否有帮助。
Result and Analysis
- Oversampling
通过在训练期间更频繁地对小物体图像进行采样(参见表3),可以改善小物体分割和检测上的AP。 通过3倍过采样观察到最大增益,这使小物体的AP增加1%(相当于8.85%的相对改善)。 虽然中等对象尺度上的性能受影响较小,但是大对象检测和分割性能始终受到过采样的影响,这意味着必须基于小对象和大对象之间的相对重要性来选择该比率。

- Augmentation
在表4中,我们使用所提出的增强和过采样策略的不同组合来呈现结果。当我们用包含更多小对象(第二行)的副本用小对象替换每个图像时,性能显着下降。当我们将这些增强图像过采样2倍时,小物体的分割和检测性能重新获得了损失,尽管总体性能仍然比基线差。当我们在增强验证集上而不是原始验证集上评估此模型时,我们看到小对象增强性能(0.161)增加了38%,这表明训练有素的模型有效地过度拟合“粘贴”小物体但是不一定是原来的小物件。我们认为这是由于粘贴的伪影,例如不完美的对象遮罩和与背景的亮度差异,这些神经网络相对容易发现。通过将过采样和增强与p = 0.5(original+aug)的概率相结合来实现最佳结果,原始对象与增强小对象的比率为2:1。这种设置比单独过采样产生了更好的结果,证实了所提出的粘贴小物体策略的有效性。
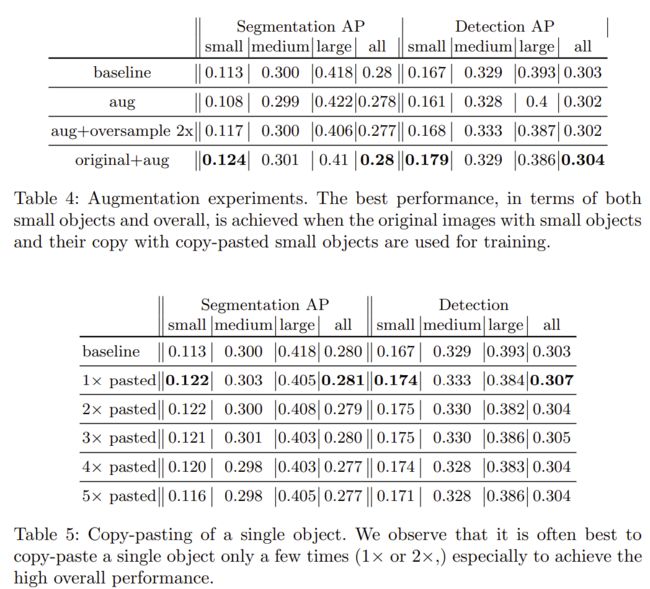


表8证明了我们的设计选择是为了避免粘贴对象和现有对象之间的任何重叠。此外,高斯模糊的边缘粘贴对象没有显示出任何改善,这表明更好的粘贴对象是它的本来面目,除非在对象中有一个更复杂的策略融合。
3.Small-Object Detection in Remote Sensing Images with End-to-End Edge-Enhanced GAN and Object Detector Network

摘要:与大目标相比,遥感图像中的小目标检测性能一直不能令人满意,特别是在低分辨率和噪声图像中。基于生成对抗网络(GAN)的增强超分辨率GAN (enhanced super-resolution GAN, ESRGAN)模型具有显著的图像增强性能,但重建图像通常会遗漏高频边缘信息。因此,在恢复的噪声和低分辨率遥感图像上,对小物体的检测性能下降。受边缘增强GAN (EEGAN)和ESRGAN成功的启发,我们应用了一种新的边缘增强超分辨率GAN (EESRGAN)来提高遥感图像的质量,并以端到端方式使用不同的检测器网络,将检测器损耗反向传播到EESRGAN以提高检测性能。我们提出了一个包含三个组成部分的架构:ESRGAN、EEN和检测网络。对于ESRGAN和EEN,我们都使用了RRDB,对于检测器网络,我们使用了更快的基于区域的卷积网络(FRCNN)(两级检测器)和单次多盒检测器(SSD)(一级检测器)。在公共数据集(带有上下文的汽车头顶)和另一个自组装(石油和天然气储罐)卫星数据集上的大量实验表明,与独立的最先进的物体探测器相比,我们的方法具有更好的性能。
4.Extended Feature Pyramid Network for Small Object Detection

(paper:https://arxiv.org/pdf/2003.07021v1.pdf, code: https://github.com/gene-chou/EFPN-detectron2)
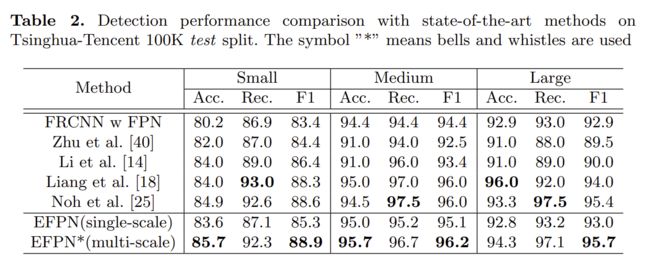
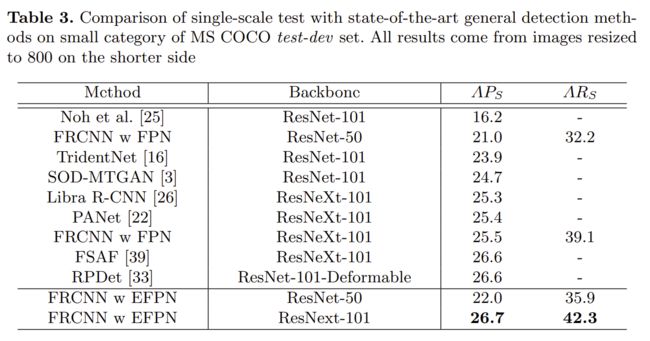
摘要:小目标检测仍然是一个尚未解决的挑战,因为很难仅提取几个像素大小的小目标信息。尽管在特征金字塔网络中进行尺度级别的相应检测可以缓解此问题,但各种尺度的特征耦合仍然会损害小目标检测的性能。本文提出了扩展特征金字塔网络(EFPN,extended feature pyramid network),它具有专门用于小目标检测的超高分辨率金字塔层。具体来说,其设计了一个模块,称为特征纹理迁移(FTT,feature texture transfer),该模块用于超分辨率特征并同时提取可信的区域细节。此外,还设计了前景-背景之间平衡(foreground-background-balanced)的损失函数来减轻前景和背景的面积不平衡问题。在实验中,所提出的EFPN在计算和存储上都是高效的,并且在清华-腾讯的小型交通标志数据集Tsinghua-Tencent 100K和微软小型常规目标检测数据集MS COCO上产生了最好的结果。
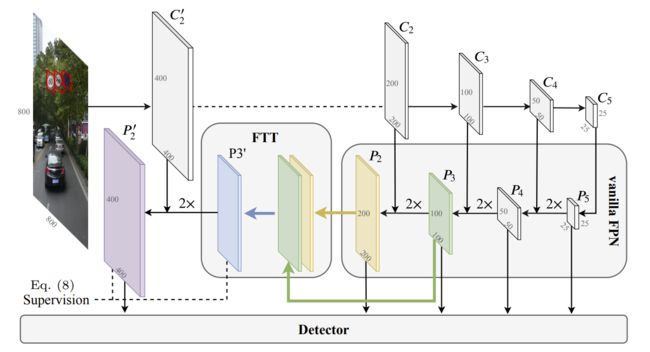
如图所示,是扩展特征金字塔网络(EFPN)的框架。 这里Ci表示CNN骨干网第i阶段的特征图,Pi表示EFPN上的相应金字塔层。 EFPN的前4层是vanilla FPN层。 特征纹理迁移(FTT)模块集成了P3中的语义内容和P2的区域纹理。 然后,类似FPN的自顶向下(top-down)路径将FTT模块输出向下传递,形成最终的扩展金字塔层P'2。 扩展的特征金字塔(P'2,P2,P3,P4,P5)被馈送到后续的检测器,以进行进一步的目标定位和分类。
顶部4层金字塔自顶向下构成,用于中型和大型目标检测。 EFPN的底部扩展在图中包含一个FTT模块,一个自上而下的路径和一个紫色金字塔层,旨在捕获小目标的区域细节。更具体地讲,在扩展中,特征超分辨率(SR)模块FTT将图中绿色-黄色层表示的EFPN第三层-第四层金字塔混合,产生具有所选区域信息的中间特征P'3,图中用蓝色菱形表示。然后,自上而下的路径将P'3与定制的高分辨率CNN特征图C'2合并,生成最终的扩展金字塔层P'2。

如表所示,在ResNet / ResNeXt 第二步(stage 2)删除了一个最大池化层,并将C'2作为第二步的输出。C'2与原始C2具有相同的表示级别,但是由于分辨率较高,因此包含更多的区域细节。 C'2中较小的接收场也有助于更好地定位小目标。从数学上讲,在提议的EFPN中扩展的操作可以描述为 (上箭头表示上采样操作)
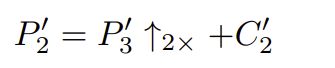

如图所示,是特征纹理迁移(FTT)模块的框架。 输入特征P3的主要语义内容首先由内容提取器(content extractor)提取。 然后,通过亚像素卷积将内容特征的分辨率提高一倍。 纹理提取器( texture extractor)从主流特征和参考特征的组合中选择可靠的区域纹理用于小目标检测。 最后,残差连接(residual connection)有助于将纹理与超分辨的内容特征融合在一起,为扩展特征金字塔生成P'3层。
FTT模块的主要输入是EFPN第三层特征图P3,参考是EFPN第四层特征图P2。 输出P'3可定义为 (Et操作符表示纹理提取器,Ec操作符表示内容提取器)

在训练模型中,正样本损失函数定义为(特征图误差):
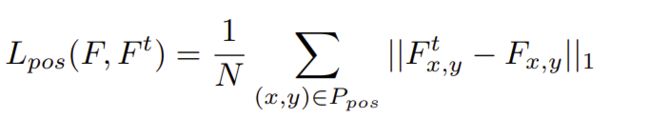
全局重建损失函数是(特征图误差):
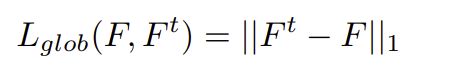
而前景-背景平衡损失函数:

最后,总损失函数(分别来自P'2-P2层特征图差和P'3-P3层特征图差)是:

下面给出一些实验结果对比:
小评:小目标检测的难度在于目标很小,其特征比较浅(如亮度/边缘信息等),语义信息较少;另外小目标和背景之间尺寸不均衡,用较小的感受野去关注其特征的话,很难提取全局语义信息;用较大感受野去关注背景信息的话,那么小目标的特征会丢失信息。
以前的方法主要是基于以下思路:
->数据增强
->特征融合
->利用上下文信息,或者目标之间建立联系
->GAN
->提升图像分辨率
->小技巧:ROI pooling被ROI align替换
->多尺度空间融合
->锚点设计
->匹配策略,不用IoU
本文算是超分辨率和多尺度特征融合的修正,集中在特征纹理迁移模块(FTT)。
5. QueryDet:Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
(paer:https://arxiv.org/abs/2103.09136, code:https://github.com/ChenhongyiYang/QueryDet-PyTorch)
- 1.研究背景
当使用现有的通用目标检测器在常规目标检测数据集上进行检测时,中等尺度和大尺度目标可以获得的结果远高于小目标。本文认为,小目标检测中出现性能衰减主要由三方面因素所导致:
- 小目标的特征随着网络的多次下采样而逐渐消失或者被背景特征淹没。
- 低分辨率特征对应的感受野无法与小目标的尺度相匹配。
- 定位小物体比大物体更困难,因为边界框的小扰动可能会导致对联合交集(IoU)度量的显著干扰。
现有的小目标检测方法通常通过放大输入图像尺寸或减少降采样率来维持较大分辨率的特征,进而提升小目标检测的性能。引入FPN可以在一定程度上缓解高分辨率引入大量计算的问题,但其在low-level特征上检测的计算复杂度仍很高。
QueryDet的目标是在引入更浅层高分辨率的特征助力小目标检测的同时,保证计算的轻量化。
本文提出的QueryDet的出发点来自于观察到的两个事实:
- low-level特征层上的计算中,有很大部分是冗余的。
- FPN结构中,即使低分辨率(high-level)的特征层无法精确的检测出小目标,但也能以较高的置信度来粗略判断出小目标是否存在以及对应的区域。
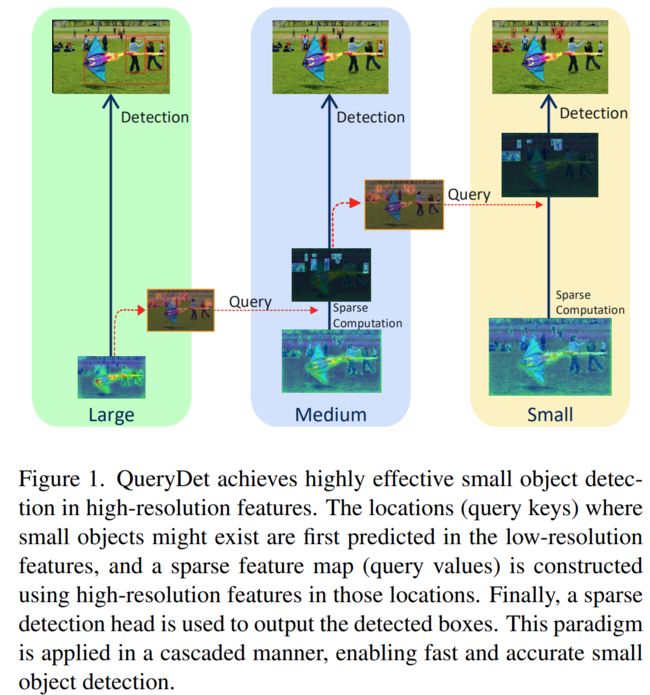
基于以上出发点,QueryDet提出了Cascade Sparse Query(CSQ)机制,其中Query代表使用前一层(higher-level feature with lower resolution)中传递过来的query来指导本层的小目标检测,再预测出本层的query进一步传递给下一层,对下一层的小目标检测进行指导,Cascade传递了这种级联的思想。Sparse表示通过使用sparse convolution(稀疏卷积)来显著减少low-level特征层上检测头的计算开销。
总体上,higher-level feature with lower resolution负责对小目标的初筛,higher-resolution feature再进行精找,这种“glance and focus”的two-stage结构可以有效的进行动态推理,检测出最终结果。
-
2 模型方法
2.1 计算量开销比较

可以看出原版RetinaNet中,最低层P3就占据了总计算量的很大部分;引入更高分辨率的P2助力小目标检测后,P2的计算开销占到了总开销的一半以上;加入最终模型QueryDet进行比较,可以看出QueryDet在减小高分辨率上的计算开销同时提高了推理速度。
2.2 使用Sparse Query加速推理
本节对文中的核心模块Query进行介绍。Query总体是一个由粗到细的过程:在粗(low-resolution)的特征图上对小目标进行粗略定位,再到细(high-resolution)特征图的对应位置上进行计算(使用sparse convolution)。在这个query过程中,粗糙定位可以看作query keys,而对应用于小目标检测的high-resolution特征图可被视为query values。
QueryDet在detection head中额外添加了用于产生小目标coarse location的,平行于classification和localization head,的query head。模型的总体结构如下图所示:

query head的input为 Pl (对应的stride为 2l ),输出热力图 Vl 。使用 o 表示一个中心坐标位于 (xo,yo) 的object,如果 o 的大小小于指定阈值,那么其中心坐标在 Vl 的对应位置 qlo=(xo,yo) 上的GT就设置为1,否则为0。
获得 Pl 对应的 Vl 后,其上的 qlo 需要被分配到下一层 Pl−1 上,具体为 qlo 会被分配到其最近的四个点上作为key的位置:
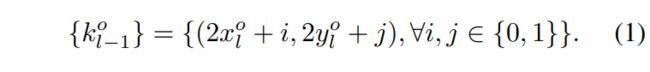
接下来, Pl−1 上对应的三个head只会在key位置集中对应的位置上计算head和用于下一层的queries。这个计算过程通过sparse convolution实现,极大的节剩了计算量。sparse convolution的提出主要是为了解决3D场景下进行运算的特征中存在很多零的情况,对稀疏卷积感兴趣的话,可以通过这篇博文简单学习一下,Rulebook构建中的Getoffset指的是kernel中每个weight对应其kernel中心位置的偏移坐标量。
Cascade Sparse Query结构保证每层生成的query并不是来自单一的P,可以通过stride的不断降低扩张对应key position的尺度。
QueryDet的pipeline。 图像被送到主干和特征金字塔网络(FPN)中,生成一系列具有不同分辨率的特征图。 从查询起始层(此图像中的P5)开始,每个层从上一层接收一组关键位置,并应用查询操作来生成稀疏值特征图。 然后,稀疏检测头和稀疏查询头会预测所检测到的下一层相应的比例和关键位置的框。
- 实验结果
本文做了如下实验:
- 在COCO mini-val上比较RetinaNet & QueryDet
- 在Visdrone上比较RetinaNet & QueryDet
- 在COCO mini-val上进行消融实验,比较HR(hight-resolution feature),RB(loss re-balance,就是给不同层加权重),QH(额外的Query Head)
- 在COCO和Visdrone 2018上使用不同的query threshold比较AP、AR、FPS的trade off
- 在COCO mini-val上比较不使用query方法和使用三种不同query的方法:CSQ最优
- 在COCO mini-val上比较从不同层开始query,对应的AP和FPS
- 换用不同的backbone(MobileNet V2 & ShuffleNet V2)测试结果
- 在COCO mini-val上使用嵌入QueryDet的FCOS,比较结果
- 在COCO test-dev & VisDrone validation上比较不用的methods
在COCO数据集上,该方法将检测mAP提高了1.0,将小mAP提高了2.0,高分辨率推理速度平均提高到3.0倍。相较于其他方案亦有明显提升。
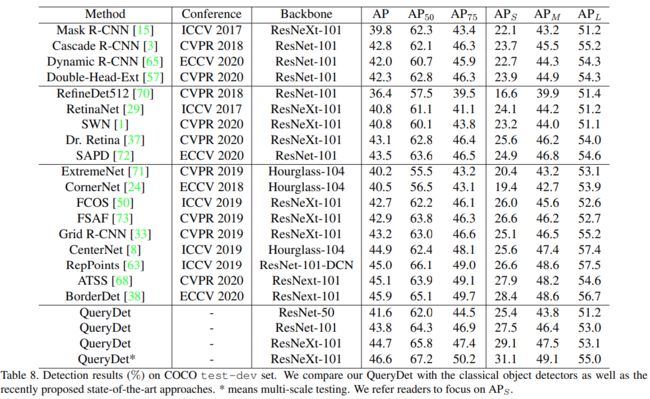
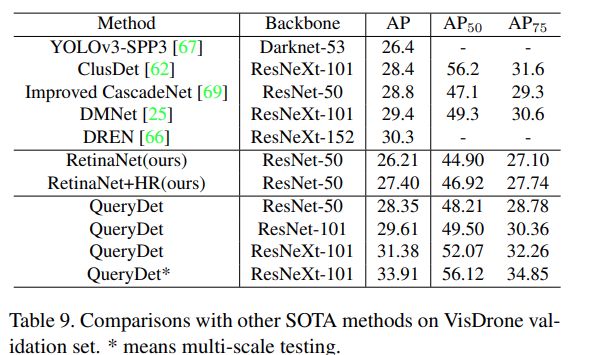
注意:上面的结果在论文版本v1中列出,最新版看不到。
- 总结
QueryDet利用high-resolution feature来提升小目标检测性能的同时,通过CSQ机制,利用高层低分辨率特征初筛含有小目标的区域,在高分辨特征层上利用初筛获得的位置,使用sparse convolution,极大地节约了计算消耗。
6. 小目标检测研究进展
(paper:http://sjcj.nuaa.edu.cn/sjcjycl/article/html/202103001)

1 小目标定义及难点分析
1.1 小目标定义
不同场景对于小目标的定义各不相同,目前尚未形成统一的标准。现有的小目标定义方式主要分为以下两类,即基于相对尺度的定义与基于绝对尺度的定义。
(1)基于相对尺度定义。即从目标与图像的相对比例这一角度考虑来对小目标进行定义。Chen等[11]提出一个针对小目标的数据集,并对小目标做了如下定义:同一类别中所有目标实例的相对面积,即边界框面积与图像面积之比的中位数在0.08%~0.58%之间。文中对小目标的定义也给出了更具体的说法,如在640像素×480像素分辨率图像中,16像素×16像素到42像素×42像素的目标应考虑为小目标。除了Chen等对小目标的定义方式以外,较为常见的还有以下几种:(1)目标边界框的宽高与图像的宽高比例小于一定值,较为通用的比例值为0.1;(2)目标边界框面积与图像面积的比值开方小于一定值,较为通用的值为0.03;(3)根据目标实际覆盖像素与图像总像素之间比例来对小目标进行定义。
但是,这些基于相对尺度的定义存在诸多问题,如这种定义方式难以有效评估模型对不同尺度目标的检测性能。此外,这种定义方式易受到数据预处理与模型结构的影响。
(2)基于绝对尺度定义。则从目标绝对像素大小这一角度考虑来对小目标进行定义。目前最为通用的定义来自于目标检测领域的通用数据集——MS COCO数据集[1],将小目标定义为分辨率小于32像素×32像素的目标。对于为什么是32像素×32像素,本文从两个方向进行了思考。一种思路来自于Torralba等[12]的研究,人类在图像上对于场景能有效识别需要的彩色图像像素大小为32像素×32像素,即小于32像素×32像素的目标人类都难以识别。另一种思路来源于深度学习中卷积神经网络本身的结构,以与MS COCO数据集第一部分同年发布的经典网络结构VGG‑Net[13]为例,从输入图像到全连接层的特征向量经过了5个最大池化层,这导致最终特征向量上的“一点”对应到输入图像上的像素大小为32像素×32像素。于是,从特征提取的难度不同这一角度考虑,可以将32像素×32像素作为区分小目标与常规目标的一个界定标准。除了MS COCO之外,还有其他基于绝对尺度的定义,如在航空图像数据集DOTA[14]与人脸检测数据集WIDER FACE[15]中都将像素值范围在[10, 50]之间的目标定义为小目标。在行人识别数据集CityPersons[16]中,针对行人这一具有特殊比例的目标,将小目标定义为了高度小于75像素的目标。基于航空图像的小行人数据集TinyPerson[17]则将小目标定义为像素值范围在[20, 32]之间的目标,而且近一步将像素值范围在[2, 20]之间的目标定义为微小目标。
1.2 小目标检测面临的挑战
前文中已简要阐述小目标的主流定义,通过这些定义可以发现小目标像素占比少,存在覆盖面积小、包含信息少等基本特点。这些特点在以往综述或论文中也多有提及,但是少有对小目标检测难点进行分析与总结。接下来本文将试图对造成小目标检测难度高的原因以及其面临的挑战进行分析与总结。
(1) 可利用特征少
无论是从基于绝对尺度还是基于相对尺度的定义,小目标相对于大/中尺度尺寸目标都存在分辨率低的问题。低分辨率的小目标可视化信息少,难以提取到具有鉴别力的特征,并且极易受到环境因素的干扰,进而导致了检测模型难以精准定位和识别小目标。
(2) 定位精度要求高
小目标由于在图像中覆盖面积小,因此其边界框的定位相对于大/中尺度尺寸目标具有更大的挑战性。在预测过程中,预测边界框框偏移一个像素点,对小目标的误差影响远高于大/中尺度目标。此外,现在基于锚框的检测器依旧占据绝大多数,在训练过程中,匹配小目标的锚框数量远低于大/中尺度目标,如图1所示,这进一步地导致了检测模型更侧重于大/中尺度目标的检测,难以检测小目标。图中IoU(Intersection over union)为交并比。
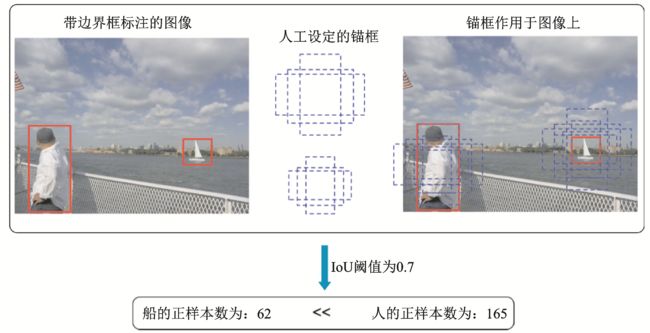
图1 小目标匹配的锚框数量相对大/中尺度的目标更少
Fig.1 Small‑size objects match with fewer anchors than large/medium objects
(3) 现有数据集中小目标占比少
在目标检测领域中,现有数据集大多针对大/中尺度尺寸目标,较少关注小目标这一特别的类型。MS COCO中虽然小目标占比较高,达31.62%,但是每幅图像包含的实例过多,小目标分布并不均匀。同时,小目标不易标注,一方面来源于小目标在图像中不易被人类关注,很难标全;另一方面是小目标对于标注误差更为敏感。另外,现有的小目标数据集往往针对特定场景,例如文献[14]针对空中视野下的图像、文献[15]针对人脸、文献[16‑17]针对行人、文献[18]针对交通灯、文献[19]针对乐谱音符,使用这些数据集训练的网络不适用于通用的小目标检测。总的来说,大规模的通用小目标数据集尚处于缺乏状态,现有的算法没有足够的先验信息进行学习,导致了小目标检测性能不足。
(4) 样本不均衡问题
为了定位目标在图像中的位置,现有的方法大多是预先在图像的每个位置生成一系列的锚框。在训练的过程中,通过设定固定的阈值来判断锚框属于正样本还是负样本。这种方式导致了模型训练过程中不同尺寸目标的正样本不均衡问题。当人工设定的锚框与小目标的真实边界框差异较大时,小目标的训练正样本将远远小于大/中尺度目标的正样本,这将导致训练的模型更加关注大/中尺度目标的检测,而忽略小目标的检测。如何解决锚框机制导致的小目标和大/中尺度目标样本不均衡问题也是当前面临的一大挑战。
(5) 小目标聚集问题
相对于大/中尺度目标,小目标具有更大概率产生聚集现象。当小目标聚集出现时,聚集区域相邻的小目标通过多次降采样后,反应到深层特征图上将聚合成一个点,导致检测模型无法区分。当同类小目标密集出现时,预测的边界框还可能会因后处理的非极大值抑制操作将大量正确预测的边界框过滤,从而导致漏检情况。另外,聚集区域的小目标之间边界框距离过近,还将导致边界框难以回归,模型难以收敛。
(6) 网络结构原因
在目标检测领域,现有算法的设计往往更为关注大/中尺度目标的检测性能。针对小目标特性的优化设计并不多,加之小目标自身特性所带来的难度,导致现有算法在小目标检测上普遍表现不佳。虽然无锚框的检测器设计是一个新的发展趋势,但是现有网络依旧是基于锚框的检测器占据主流,而锚框这一设计恰恰对小目标极不友好。此外,在现有网络的训练过程中,小目标由于训练样本占比少,对于损失函数的贡献少,从而进一步减弱了网络对于小目标的学习能力。
2 小目标检测研究思路
2.1 数据增强
数据增强是一种提升小目标检测性能的最简单和有效的方法,通过不同的数据增强策略可以扩充训练数据集的规模,丰富数据集的多样性,从而增强检测模型的鲁棒性和泛化能力。在相对早期的研究中,Yaeger等[20]通过使用扭曲变形、旋转和缩放等数据增强方法显著提升了手写体识别的精度。之后,数据增强中又衍生出了弹性变形[21]、随机裁剪[22]和平移[23]等策略。目前,这些数据增强策略已被广泛应用于目标检测中。
近些年来,基于深度学习的卷积神经网络在处理计算机视觉任务中获得了巨大的成功。深度学习的成功很大程度上归功于数据集的规模和质量,大规模和高质量的数据能够大幅度提升模型的泛化能力。数据增强策略在目标检测领域有着广泛应用,例如Fast R‑CNN[24]、Cascade R‑CNN[25]中使用的水平翻转,YOLO[26]、YOLO9000[27]中使用的调整图像曝光和饱和度,还有常被使用的CutOut[28]、MixUp[29]、CutMix[30]等方法。最近,更是有诸如马赛克增强(YOLOv4[31])、保持增强[32]等创新策略提出,但是这些数据增强策略主要是针对常规目标检测。
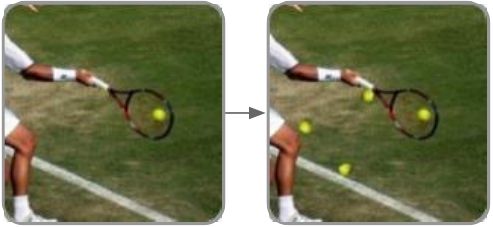
聚焦到小目标检测领域,小目标面临着分辨率低、可提取特征少、样本数量匮乏及分布不均匀等诸多挑战,数据增强的重要性愈发显著。近些年来,出现了一些适用于小目标的数据增强方法(表 1)。Yu等[17]在对数据的处理中,提出了尺度匹配策略,根据不同目标尺寸进行裁剪,缩小不同大小目标之间的差距,从而避免常规缩放操作中小目标信息易丢失的情形。Kisantal等[33]针对小目标覆盖的面积小、出现位置缺乏多样性、检测框与真值框之间的交并比远小于期望的阈值等问题,提出了一种复制增强的方法,通过在图像中多次复制粘贴小目标的方式来增加小目标的训练样本数,从而提升了小目标的检测性能。在Kisantal等的基础上,Chen等[34]在RRNet中提出了一种自适应重采样策略进行数据增强,这种策略基于预训练的语义分割网络对目标图像进行考虑上下文信息的复制,以解决简单复制过程中可能出现的背景不匹配和尺度不匹配问题,从而达到较好的数据增强效果。Chen等[35]则从小目标数量占比小、自身包含信息少等问题出发,在训练过程中对图像进行缩放与拼接,将数据集中的大尺寸目标转换为中等尺寸目标,中等尺寸目标转换为小尺寸目标,并在提高中/小尺寸目标的数量与质量的同时也兼顾考虑了计算成本。在针对小目标的特性设计对应的数据增强策略之外,Zoph等[36]超越了目标特性限制,提出了一种通过自适应学习方法例如强化学习选择最佳的数据增强策略,在小目标检测上获得了一定的性能提升。
表1 适用于小目标的5种数据增强方法
Table 1 Five data augmentation methods for small objects
| 编号 | 增强策略 | 主要内容 | 年份 | 发表 | 引用量 | |
|---|---|---|---|---|---|---|
| 1 | 复制增强[33] Artificial augmentation by copy pasting the small objects |
|
通过对图像中的小目标的复制与粘贴操作进行数据增强 | 2019 | arXiv | 68 |
| 2 | 自适应采样[34] AdaResampling |
|
在文献[33]的基础上,考虑上下文信息进行复制,避免出现尺度不匹配和背景不匹配的问题 | 2019 | ICCV | 10 |
| 3 | 尺度匹配[17] Scale match |
通过尺度匹配策略对图像进行尺度变换,用作额外的数据补充 |
2020 | WACV | 14 | |
| 4 | 缩放与拼接[35] Component stitching |
通过缩放拼接操作增加中/小尺寸目标的数量与质量 |
2020 | arXiv | 6 | |
| 5 | 自学习数据增强[36] Learning data augmentation strategies |
|
通过强化学习选择最佳数据增强策略 | 2020 | ECCV | 105 |



数据增强这一策略虽然在一定程度上解决了小目标信息量少、缺乏外貌特征和纹理等问题,有效提高了网络的泛化能力,在最终检测性能上获得了较好的效果,但同时带来了计算成本的增加。而且在实际应用中,往往需要针对目标特性做出优化,设计不当的数据增强策略可能会引入新的噪声,损害特征提取的性能,这也给算法的设计带来了挑战。
2.2 多尺度学习
小目标与常规目标相比可利用的像素较少,难以提取到较好的特征,而且随着网络层数的增加,小目标的特征信息与位置信息也逐渐丢失,难以被网络检测。这些特性导致小目标同时需要深层语义信息与浅层表征信息,而多尺度学习将这两种相结合,是一种提升小目标检测性能的有效策略。
早期的多尺度检测有两个思路。一种是使用不同大小的卷积核通过不同的感受野大小来获取不同尺度的信息,但这种方法计算成本很高,而且感受野的尺度范围有限,Simonyan和Zisserman[13]提出使用多个小卷积核代替大卷积核具备巨大优势后,使用不同大小卷积核的方法逐渐被弃用。之后,Yu等[37]提出的空洞卷积和Dai等[38]提出的可变卷积又为这种通过不同感受野大小获取不同尺度信息的方法开拓了新的思路。另一种来自于图像处理领域的思路——图像金字塔[39],通过输入不同尺度的图像,对不同尺度大小的目标进行检测,这种方法在早期的目标检测中有所应用[40‑41](见图2(a))。但是,基于图像金字塔训练卷积神经网络模型对计算机算力和内存都有极高的要求。近些年来,图像金字塔在实际研究应用中较少被使用,仅有文献[42‑43]等方法针对数据集目标尺度差异过大等问题而使用。
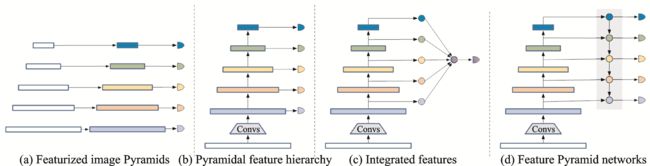
图2 多尺度学习的4种方式
Fig.2 Four ways of multi‑scale learning
目标检测中的经典网络如Fast R‑CNN[24]、Faster R‑CNN[44]、SPPNet[45]和R‑FCN[46]等大多只是利用了深度神经网络的最后层来进行预测。然而,由于空间和细节特征信息的丢失,难以在深层特征图中检测小目标。在深度神经网络中,浅层的感受野更小,语义信息弱,上下文信息缺乏,但是可以获得更多空间和细节特征信息。从这一思路出发,Liu等[47]提出一种多尺度目标检测算法SSD(Single shot multibox detector),利用较浅层的特征图来检测较小的目标,而利用较深层的特征图来检测较大的目标,如图2(b)所示。Cai等[48]针对小目标信息少,难以匹配常规网络的问题,提出统一多尺度深度卷积神经网络,通过使用反卷积层来提高特征图的分辨率,在减少内存和计算成本的同时显著提升了小目标的检测性能。
针对小目标易受环境干扰问题,Bell等[49]为提出了ION(Inside‑outside network)目标检测方法,通过从不同尺度特征图中裁剪出同一感兴趣区域的特征,然后综合这些多尺特征来预测,以达到提升检测性能的目的。与ION的思想相似,Kong等[50]提出了一种有效的多尺度融合网络,即HyperNet,通过综合浅层的高分辨率特征和深层的语义特征以及中间层特征的信息显著提高了召回率,进而提高了小目标检测的性能(见图2(c))。这些方法能有效利用不同尺度的信息,是提升小目标特征表达的一种有效手段。但是,不同尺度之间存在大量重复计算,对于内存和计算成本的开销较大。
为节省计算资源并获得更好的特征融合效果,Lin等[51]结合单一特征映射、金字塔特征层次和综合特征的优点,提出了特征金字塔FPN(Feature Pyramid network)。FPN是目前最流行的多尺度网络,它引入了一种自底向上、自顶向下的网络结构,通过将相邻层的特征融合以达到特征增强的目的(见图2(d))。在FPN的基础上,Liang等[52]提出了一种深度特征金字塔网络,使用具有横向连接的特征金字塔结构加强小目标的语义特征,并辅以特别设计的锚框和损失函数训练网络。为了提高小目标的检测速度,Cao等[53]提出一种多层次特征融合算法,即特征融合SSD,在SSD的基础上引入上下文信息,较好地平衡了小目标检测的速度与精度。但是基于SSD的特征金字塔方法需要从网络的不同层中抽取不同尺度的特征图进行预测,难以充分融合不同尺度的特征。针对这一问题,Li和Zhou[54]提出一种特征融合单次多箱探测器,使用一个轻量级的特征融合模块,联系并融合各层特征到一个较大的尺度,然后在得到的特征图上构造特征金字塔用于检测,在牺牲较少速度的情形下提高了对小目标的检测性能。针对机场视频监控中的小目标识别准确率较低的问题,韩松臣等[55]提出了一种结合多尺度特征融合与在线难例挖掘的机场路面小目标检测方法,该方法采用ResNet‑101作为特征提取网络,并在该网络基础上建立了一个带有上采样的“自顶向下”的特征融合模块,以生成语义信息更加丰富的高分辨率特征图。
最近,多尺度特征融合这一方法又有了新的拓展,如Nayan等[56]针对小目标经过多层网络特征信息易丢失这一问题,提出了一种新的实时检测算法,该算法使用上采样和跳跃连接在训练过程中提取不同网络深度的多尺度特征,显著提高了小目标检测的检测精度与速度。Liu等[57]为了降低高分辨率图像的计算成本,提出了一种高分辨率检测网络,通过使用浅层网络处理高分辨率图像和深层网络处理低分辨率图像,在保留小目标尽可能多的位置信息同时提取了更多的语义信息,在降低计算成本的情形下提升了小目标的检测性能。Deng等[58]发现虽然多尺度融合可以有效提升小目标检测性能,但是不同尺度的特征耦合仍然会影响性能,于是提出了一种扩展特征金字塔网络,使用额外的高分辨率金字塔级专门用于小目标检测。
总体来说,多尺度特征融合同时考虑了浅层的表征信息和深层的语义信息,有利于小目标的特征提取,能够有效地提升小目标检测性能。然而,现有多尺度学习方法在提高检测性能的同时也增加了额外的计算量,并且在特征融合过程中难以避免干扰噪声的影响,这些问题导致了基于多尺度学习的小目标检测性能难以得到进一步提升。
2.3 上下文学习
在真实世界中,“目标与场景”和“目标与目标”之间通常存在一种共存关系,通过利用这种关系将有助于提升小目标的检测性能。在深度学习之前,已有研究[59]证明通过对上下文进行适当的建模可以提升目标检测性能,尤其是对于小目标这种外观特征不明显的目标。随着深度神经网络的广泛应用,一些研究也试图将目标周围的上下文集成到深度神经网络中,并取得了一定的成效。以下将从基于隐式上下文特征学习和基于显式上下文推理的目标检测两个方面对国内外研究现状及发展动态进行简要综述。
(1)基于隐式上下文特征学习的目标检测。隐式上下文特征是指目标区域周围的背景特征或者全局的场景特征。事实上,卷积神经网络中的卷积操作在一定程度上已经考虑了目标区域周围的隐式上下文特征。为了利用目标周围的上下文特征,Li等[60]提出一种基于多尺度上下文特征增强的目标检测方法,该方法首先在图像中生成一系列的目标候选区域,然后在目标周围生成不同尺度的上下文窗口,最后利用这些窗口中的特征来增强目标的特征表示(见图3(a))。随后,Zeng等[61]提出一种门控双向卷积神经网络,该网络同样在目标候选区域的基础上生成包含不同尺度上下文的支撑区域,不同之处在于该网络让不同尺度和分辨率的信息在生成的支撑区域之间相互传递,从而综合学习到最优的特征。为了更好地检测复杂环境下的微小人脸,Tang等[62]提出一种基于上下文的单阶段人脸检测方法,该方法设计了一种新的上下文锚框,在提取人脸特征的同时考虑了其周围的上下文信息,例如头部信息和身体信息。郑晨斌等[63]提出一种强化上下文模型网络,该网络利用双空洞卷积结构来节省参数量的同时,通过扩大有效感受野来强化浅层上下文信息,并在较少破坏原始目标检测网络的基础上灵活作用于网络中浅预测层。然而,这些方法大多依赖于上下文窗口的设计或受限于感受野的大小,可能会导致重要上下文信息的丢失。
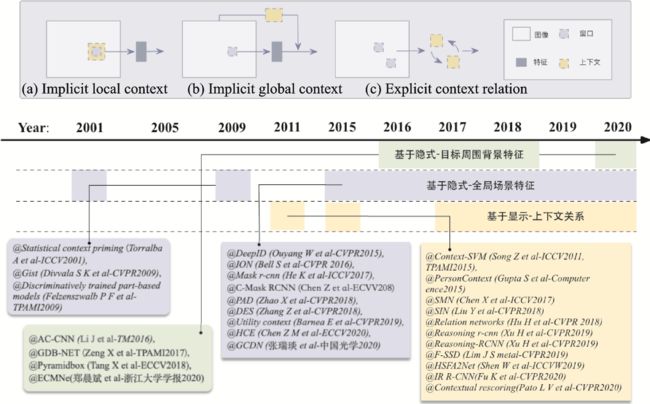
图3 上下文在目标检测中的探索历程
Fig.3 Exploration of context in object detection
为了更加充分地利用上下文信息,一些方法尝试将全局的上下文信息融入到目标检测模型中(见 图3(b))。对于早期的目标检测算法,一种常用的集成全局上下文方法是通过构成场景元素的统计汇总,例如Gist[64]。Torralba等[65]提出通过计算全局场景的低级特征和目标的特征描述符的统计相关性来对视觉上下文建模。随后,Felzenszwalb等[66]提出一种基于混合多尺度可变形部件模型的目标检测方法。该方法通过引入上下文来对检测结果进行二次评分,从而进一步提升检测结果的可靠性。对于目前的基于深度学习的目标检测算法,主要通过较大的感受野、卷积特征的全局池化或把全局上下文看作一种序列信息3种方式来感知全局上下文。Bell等[49]提出基于循环神经网络的上下文传递方法,该方法利用循环神经网络从4个方向对整个图像中的上下文信息进行编码,并将得到的4个特征图进行串联,从而实现对全局上下文的感知。然而,该方法使模型变得复杂,并且模型的训练严重依赖于初始化参数的设置。Ouyang等[67]通过学习图像的分类得分,并将该得分作为补充的上下文特征来提升目标检测性能。为了提升候选区域的特征表示,Chen等[68]提出一种上下文微调网络,该网络首先通过计算相似度找到与目标区域相关的上下文区域,然后利用这些上下文区域的特征来增强目标区域特征。随后,Barnea等[69]将上下文的利用视为一个优化问题,讨论了上下文或其他类型的附加信息可以将检测分数提高到什么程度,并表明简单的共现性关系是最有效的上下文信息。此外,Chen等[70]提出一种层次上下文嵌入框架,该框架可以作为一个即插即用的组件,通过挖掘上下文线索来增强候选区域的特征表达,从而提升最终的检测性能。最近,张瑞琰等[71]提出了面向光学遥感目标的全局上下文检测模型,该模型通过全局上下文特征与目标中心点局部特征相结合的方式生成高分辨率热点图,并利用全局特征实现目标的预分类。此外,一些方法通过语义分割来利用全局上下文信息。He等[72]提出一种统一的实例分割框架,利用像素级的监督来优化检测器,并通过多任务的方式联合优化目标检测和实例分割模型。尽管通过语义分割可以显著提高检测性能,但是像素级的标注是非常昂贵的。鉴于此,Zhao等[73]提出一种生成伪分割标签的方法,通过利用伪分割标签来于优化检测器,并取得了不错的效果。进一步地,Zhang等[74]提出一种无监督的分割方法,在无像素级的标注下通过联合优化目标检测和分割来增强用于目标检测的特征图。目前,基于全局上下文的方法在目标检测上已经取得了较大的进展,但如何从全局场景中找到有利于提升小目标检测性能的上下文信息仍然是当前的研究难点。
(2)基于显式上下文推理的目标检测。显示上下文推理是指利用场景中明确的上下文信息来辅助推断目标的位置或类别,例如利用场景中天空区域与目标的上下文关系来推断目标的类别。上下文关系通常指场景中目标与场景或者目标与目标之间的约束和依赖关系(见图3(c))。为了利用上下文关系,Chen等[75]提出一种自适应上下文建模和迭代提升的方法,通过将一个任务的输出作为另一个任务的上下文来提升目标分类和检测性能。此后,Gupta等[76]提出一种基于空间上下文的目标检测方法。该方法能够准确地捕捉到上下文和感兴趣目标之间的空间关系,并且有效地利用了上下文区域的外观特征。进一步地,Liu等[77]提出一种结构推理网络,通过充分考虑场景上下文和目标之间的关系来提升目标的检测性能。为了利用先验知识,Xu等[78]在Faster R‑CNN[44]的基础上提出了一种Reasoning‑RCNN,通过构建知识图谱来编码上下文关系,并利用先验的上下文关系来影响目标检测。Chen等[79]提出了一种空间记忆网络,空间记忆实质上是将目标实例重新组合成一个伪图像表示,并将伪图像表示输入到卷积神经网络中进行目标关系推理,从而形成一种顺序推理体系结构。在注意力机制的基础上,Hu等[80]提出一种轻量级目标关系网络,通过引入不同物体之间的外观和几何结构关系来做约束,实现物体之间的关系建模。该网络无需额外的监督,并且易于嵌入到现有的网络中,可以有效地过滤冗余框,从而提升目标的检测性能。
近年来,基于上下文学习的方法得到了进一步发展。Lim等[81]提出一种利用上下文连接多尺度特征的方法,该方法中使用网络不同深度层级中的附加特征作为上下文,辅以注意力机制聚焦于图像中的目标,充分利用了目标的上下文信息,进而提升了实际场景中的小目标检测精度。针对室内小尺度人群检测面临的目标特征与背景特征重叠且边界难以区分的问题,Shen等[82]提出了一种室内人群检测网络框架,使用一种特征聚合模块(Feature aggregation module, FAM)通过融合和分解的操作来聚合上下文特征信息,为小尺度人群检测提供更多细节信息,进而显著提升了对于室内小尺度人群的检测性能。Fu等[83]提出了一种新颖的上下文推理方法,该方法对目标之间的固有语义和空间布局关系进行建模和推断,在提取小目标语义特征的同时尽可能保留其空间信息,有效解决了小目标的误检与漏检问题。为了提升目标的分类结果,Pato等[84]提出一种基于上下文的检测结果重打分方法,该方法通过循环神经网络和自注意力机制来传递候选区域之间的信息并生成上下文表示,然后利用得到的上下文来对检测结果进行二次评估。
基于上下文学习的方法充分利用了图像中与目标相关的信息,能够有效提升小目标检测的性能。但是,已有方法没有考虑到场景中的上下文信息可能匮乏的问题,同时没有针对性地利用场景中易于检测的结果来辅助小目标的检测。鉴于此,未来的研究方向可以从以下两个角度出发考虑:(1)构建基于类别语义池的上下文记忆模型,通过利用历史记忆的上下文来缓解当前图像中上下文信息匮乏的问题;(2)基于图推理的小目标检测,通过图模型和目标检测模型的结合来针对性地提升小目标的检测性能。
2.4 生成对抗学习
生成对抗学习的方法旨在通过将低分辨率小目标的特征映射成与高分辨率目标等价的特征,从而达到与尺寸较大目标同等的检测性能。前文所提到的数据增强、特征融合和上下文学习等方法虽然可以有效地提升小目标检测性能,但是这些方法带来的性能增益往往受限于计算成本。针对小目标分辨率低问题,Haris等[85]提出一种端到端的联合训练超分辨率和检测模型的方法,该方法一定程度上提升了低分辨率目标的检测性能。但是,这种方法对于训练数据集要求较高,并且对小目标检测性能的提升不足。
目前,一种有效的方法是通过结合生成对抗网络(Generative adversarial network, GAN)[86]来提高小目标的分辨率,缩小小目标与大/中尺度目标之间的特征差异,增强小目标的特征表达,进而提高小目标检测的性能。在Radford等[87]提出了DCGAN(Deep convolutional GAN)后,计算视觉的诸多任务开始利用生成对抗模型来解决具体任务中面临的问题。针对训练样本不足的问题,Sixt等[88]提出了RenderGAN,该网络通过对抗学习来生成更多的图像,从而达到数据增强的目的。为了增强检测模型的鲁棒性,Wang等[89]通过自动生成包含遮挡和变形特征的样本,以此提高对困难目标的检测性能。随后,Li等[90]提出了一种专门针对小目标检测的感知GAN方法,该方法通过生成器和鉴别器相互对抗的方式来学习小目标的高分辨率特征表示。在感知GAN中,生成器将小目标表征转换为与真实大目标足够相似的超分辨表征。同时,判别器与生成器对抗以识别生成的表征,并对生成器施加条件要求。该方法通过生成器和鉴别器相互对抗的方式来学习小目标的高分辨率特征表示。这项工作将小目标的表征提升为“超分辨”表征,实现了与大目标相似的特性,获得了更好的小目标检测性能。
近年来,基于GAN对小目标进行超分辨率重建的研究有所发展,Bai等[91]提出了一种针对小目标的多任务生成对抗网络(Multi‑task generative adversarial network, MTGAN)。在MTGAN中,生成器是一个超分辨率网络,可以将小模糊图像上采样到精细图像中,并恢复详细信息以便更准确地检测。判别器是多任务网络,区分真实图像与超分辨率图像并输出类别得分和边界框回归偏移量。此外,为了使生成器恢复更多细节以便于检测,判别器中的分类和回归损失在训练期间反向传播到生成器中。MTGAN由于能够从模糊的小目标中恢复清晰的超分辨目标,因此大幅度提升了小目标的检测性能。进一步地,针对现有的用于小目标检测的超分辨率模型存在缺乏直接的监督问题,Noh等[92]提出一种新的特征级别的超分辨率方法,该方法通过空洞卷积的方式使生成的高分辨率目标特征与特征提取器生成的低分辨率特征保持相同的感受野大小,从而避免了因感受野不匹配而生成错误超分特征的问题。此外,Deng等[58]设计了一种扩展特征金字塔网络,该网络通过设计的特征纹理模块生成超高分辨率的金字塔层,从而丰富了小目标的特征信息。
基于生成对抗模型的目标检测算法通过增强小目标的特征信息,可以显著提升检测性能。同时,利用生成对抗模型来超分小目标这一步骤无需任何特别的结构设计,能够轻易地将已有的生成对抗模型和检测模型相结合。但是,目前依旧面临两个无法避免的问题:(1)生成对抗网络难以训练,不易在生成器和鉴别器之间取得好的平衡;(2)生成器在训练过程中产生样本的多样性有限,训练到一定程度后对于性能的提升有限。
2.5 无锚机制
锚框机制在目标检测中扮演着重要的角色。许多先进的目标检测方法都是基于锚框机制而设计的,但是锚框这一设计对于小目标的检测极不友好。现有的锚框设计难以获得平衡小目标召回率与计算成本之间的矛盾,而且这种方式导致了小目标的正样本与大目标的正样本极度不均衡,使得模型更加关注于大目标的检测性能,从而忽视了小目标的检测。极端情况下,设计的锚框如果远远大于小目标,那么小目标将会出现无正样本的情况。小目标正样本的缺失,将使得算法只能学习到适用于较大目标的检测模型。此外,锚框的使用引入了大量的超参,比如锚框的数量、宽高比和大小等,使得网络难以训练,不易提升小目标的检测性能。近些年无锚机制的方法成为了研究热点,并在小目标检测上取得了较好效果。
一种摆脱锚框机制的思路是将目标检测任务转换为关键点的估计,即基于关键点的目标检测方法。基于关键点的目标检测方法主要包含两个大类:基于角点的检测和基于中心的检测。基于角点的检测器通过对从卷积特征图中学习到的角点分组来预测目标边界框。DeNet[93]将目标检测定义为估计目标4个角点的概率分布,包括左上角、右上角、左下角和右下角(见图4(a))。首先利用标注数据来训练卷积神经网络,然后利用该网络来预测角点分布。之后,利用角点分布和朴素贝叶斯分类器来确定每个角点对应的候选区域是否包含目标。在DeNet之后,Wang等[94]提出了一种新的使用角点和中心点之间的连接来表示目标的方法,命名为PLN(Point linking network)。PLN首先回归与DeNet相似的4个角点和目标的中心点,同时通过全卷积网络预测关键点两两之间是否相连,然后将角点及其相连的中心点组合起来生成目标边界框。PLN对于稠密目标和具有极端宽高比率目标表现良好。但是,当角点周围没有目标像素时,PLN由于感受野的限制将很难检测到角点。继PLN之后,Law等[95]提出了一种新的基于角点的检测算法,命名为CornerNet。CornerNet将目标检测问题转换为角点检测问题,首先预测所有目标的左上和右下的角点,然后将这些角点进行两两匹配,最后利用配对的角点生成目标的边界框。CornetNet的改进版本——CornerNet‑Lite[96],从减少处理的像素数量和减少在每个像素上进行的计算数量两个角度出发进行改进,有效解决了目标检测中的两个关键用例:在不牺牲精度的情况下提高效率以及实时效率的准确性。与基于锚框的检测器相比,CornerNet系列具有更简洁的检测框架,在提高检测效率的同时获得了更高的检测精度。但是,该系列仍然会因为错误的角点匹配预测出大量不正确的目标边界框。
图4 无锚机制的4种形式
Fig.4 Four ways of anchor‑free methods
为了进一步提高目标检测性能,Duan等[97]提出了一种基于中心预测的目标检测框架,称为CenterNet(见图4(b))。CenterNet首先预左上角和右下角的角点以及中心关键点,然后通过角点匹配确定边界框,最后利用预测的中心点消除角点不匹配引起的不正确的边界框。与CenterNet类似,Zhou等[98]通过对极值点和中心点进行匹配,提出了一种自下而上的目标检测网络,称为ExtremeNet。ExtremeNet首先使用一个标准的关键点估计网络来预测最上面、最下面、最左边、最右边的4个极值点和中心点,然后在5个点几何对齐的情况下对它们进行分组以生成边界框。但是ExtremeNet和CornerNet等基于关键点的检测网络都需要经过一个关键点分组阶段,这降低了算法整体的速度。针对这一问题,Zhou等[99]将目标建模为其一个单点,即边界框中心点,无需对构建点进行分组或其他后处理操作。然后在探测器使用关键点估计来查找中心点,并回归到所有其他对象属性,如大小、位置等。这一方法很好地平衡了检测的精度与速度。
近年来,基于关键点的目标检测方法又有了新的扩展。Yang等[100]提出了一种名为代表点(RepPoints)的检测方法,提供了更细粒度的表示方式,使得目标可以被更精细地界定。同时,这种方法能够自动学习目标的空间信息和局部语义特征,一定程度上提升了小目标检测的精度(见图4(c))。更进一步地,Kong等[101]受到人眼的中央凹(视网膜中央区域,集中了绝大多数的视锥细胞,负责视力的高清成像)启发,提出了一种直接预测目标存在的可能性和边界框坐标的方法,该方法首先预测目标存在的可能性,并生成类别敏感语义图,然后为每一个可能包含目标的位置生成未知类别的边界框。由于摆脱了锚框的限制,FoveaBox对于小目标等具有任意横纵比的目标具备良好的鲁棒性和泛化能力,并在检测精度上也得到了较大提升。与FoveaBox相似,Tian等[102]使用语义分割的思想来解决目标检测问题,提出了一种基于全卷积的单级目标检测器FCOS(Fully convolutional one‑stage),避免了基于锚框机制的方法中超参过多、难以训练的问题(见图4(d))。此外,实验表明将两阶段检测器的第一阶段任务换成FCOS来实现,也能有效提升检测性能。而后,Zhu等[103]将无锚机制用于改进特征金字塔中的特征分配问题,根据目标语义信息而不是锚框来为目标选择相应特征,同时提高了小目标检测的精度与速度。Zhang等[104]则从基于锚框机制与无锚机制的本质区别出发,即训练过程中对于正负样本的定义不同,提出了一种自适应训练样本选择策略,根据对象的统计特征自动选择正反样本。针对复杂的场景下小型船舶难以检测的问题,Fu等[105]提出了一种新的检测方法——特征平衡与细化网络,采用直接学习编码边界框的一般无锚策略,消除锚框对于检测性能的负面影响,并使用基于语义信息的注意力机制平衡不同层次的多个特征,达到了最先进的性能。为了更有效地处理无锚框架下的多尺度检测,Yang等[106]提出了一种基于特殊注意力机制的特征金字塔网络,该网络能够根据不同大小目标的特征生成特征金字塔,进而更好地处理多尺度目标检测问题,显著提升了小目标的检测性能。
2.6 其他优化策略
在小目标检测这一领域,除了前文所总结的几个大类外,还有诸多优秀的方法。针对小目标训练样本少的问题,Kisantal等[33]提出了一种过采样策略,通过增加小目标对于损失函数的贡献,以此提升小目标检测的性能。除了增加小目标样本权重这一思路之外,另一种思路则是通过增加专用于小目标的锚框数量来提高检测性能。Zhang等[107]提出了一种密集锚框策略,通过在一个感受野中心设计多个锚框来提升小目标的召回率。与密集锚框策略相近,Zhang等[108]设计了一种基于有效感受野和等比例区间界定锚框尺度的方法,并提出一种尺度补偿锚框匹配策略来提高小人脸目标的召回率。增加锚框数量对于提升小目标检测精度十分有效,同时也额外增加了巨大的计算成本。Eggert等[109]从锚框尺度的优化这一角度入手,通过推导小目标尺寸之间的联系,为小目标选择合适的锚框尺度,在商标检测上获得了较好的检测效果。之后,Wang等[110]提出了一种基于语义特征的引导锚定策略,通过同时预测目标中心可能存在的位置及目标的的尺度和纵横比,提高了小目标检测的性能。此外,这种策略可以集成到任何基于锚框的方法中。但是,这些改进没有实质性地平衡检测精度与计算成本之间的矛盾。
近些年来,随着计算资源的增加,越来越多的网络使用级联思想来平衡目标漏检率与误检率。级联这一思想来源已久[111],并在目标检测领域得到了广泛的应用。它采用了从粗到细的检测理念:用简单的计算过滤掉大多数简单的背景窗口,然后用复杂的窗口来处理那些更困难的窗口。随着深度学习时代的到来,Cai等[25]提出了经典网络Cascade R‑CNN,通过级联几个基于不同IoU阈值的检测网络达到不断优化预测结果的目的。之后,Li等[112]在Cascade R‑CNN的基础上进行了扩展,进一步提升了小目标检测性能。受到级联这一思想的启发,Liu等[113]提出了一种渐近定位策略,通过不断增加IoU阈值来提升行人检测的检测精度。另外,文献[114‑116]展现了级联网络在困难目标检测上的应用,也一定程度上提升了小目标的检测性能。
另外一种思路则是分阶段检测,通过不同层级之间的配合平衡漏检与误检之间的矛盾。Chen等[117]提出一种双重探测器,其中第一尺度探测器最大限度地检测小目标,第二尺度探测器则检测第一尺度探测器无法识别的物体。进一步地,Drenkow等[118]设计了一种更加高效的目标检测方法,该方法首先在低分辨率下检查整个场景,然后使用前一阶段生成的显著性地图指导后续高分辨率下的目标检测。这种方式很好地权衡了检测精度和检测速度。此外,文献[119‑121]针对空中视野图像中的困难目标识别进行了前后景的分割,区分出重要区域与非重要区域,在提高检测性能的同时也减少了计算成本。
优化损失函数也是一种提升小目标检测性能的有效方法。Redmon等[26]发现,在网络的训练过程中,小目标更容易受到随机误差的影响。随后,他们针对这一问题进行了改进[27],提出一种依据目标尺寸设定不同权重的损失函数,实现了小目标检测性能的提升。Lin等[122]则针对类别不均衡问题,在RetinaNet中提出了焦距损失,有效解决了训练过程中存在的前景‑背景类不平衡问题。进一步地,Zhang等[123]将级联思想与焦距损失相结合,提出了Cascade RetinaNet,进一步提高了小目标检测的精度。针对小目标容易出现的前景与背景不均衡问题,Deng等[58]则提出了一种考虑前景‑背景之间平衡的损失函数,通过全局重建损失和正样本块损失提高前景与背景的特征质量,进而提升了小目标检测的性能。
为了权衡考虑小目标的检测精度和速度,Sun等[124]提出了一种多接受域和小目标聚焦弱监督分割网络,通过使用多个接收域块来关注目标及其相邻背景,并依据不同空间位置设置权重,以达到增强特征可辨识性的目的。此外,Yoo等[125]将多目标检测任务重新表述为边界框的密度估计问题,提出了一种混合密度目标检测器,通过问题的转换避免了真值框与预测框匹配以及启发式锚框设计等繁琐过程,也一定程度上解决了前景与背景不平衡的问题。
相关推荐与参考:
小目标检测的一些问题,思路和方案 (英文原文:https://medium.datadriveninvestor.com)
小目标检测研究进展:http://sjcj.nuaa.edu.cn/sjcjycl/article/html/202103001