blog4
第四次作业:CNN实战
前言
本博客为OUC2022秋季软件工程第四周作业
学习记录
–叶鹏
使用VGG模型进行猫狗大战
练习部分
同 高峰老师激情线上教学
不再赘述
练习赛部分
准备部分
####### 材料下载与准备
在比赛页面下载需要的图片压缩包,为了对接summitgao的程序,对图片目录做一定的修改

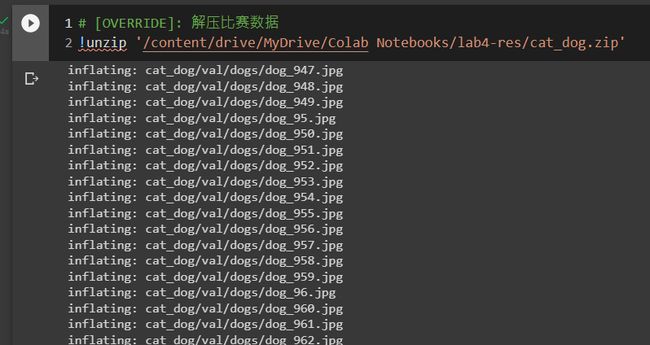
####### colab准备
在云端解压所需文件
模型训练部分
####### 数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224×224×3 的大小,同时还将进行归一化处理。

将处理后的数据载入到各自的DataLoader容器内
####### 创建vgg model
修改最后一层,冻结前面层的参数

####### 训练并测试全连接层
-
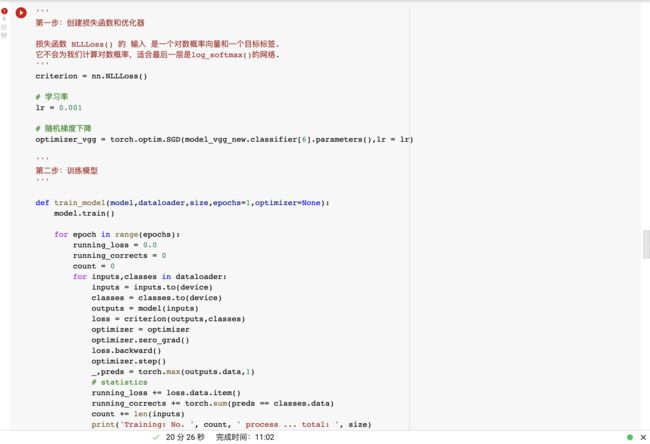
创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.

-
训练模型
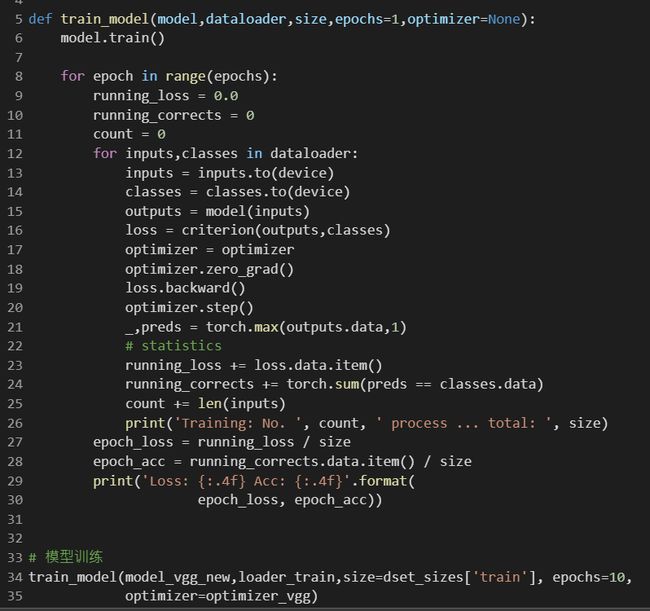

我这里设置
epochs = 10,训练了10次,每次20000个数据集,用时爆幹长,其实不用设置这么多 -
测试模型,生成所需的结果
csv文件
练习赛部分
-
将生成的
resule.csv上传到比赛评测器


-
获取对应分数

–王匀卓
下载数据

数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224×224×3 的大小,同时还将进行归一化处理。


数据处理完后,会生成上述以cat_dog为文件名的文件结构。
创建 VGG Model
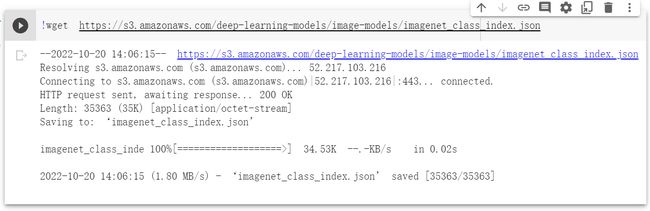
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型。


实验中遇到的问题
不知道如何生成需要提交的.csv文件
解决方案:找到了下列代码:
def result_model(model,dataloader,size):
model.eval()
predictions=np.zeros((size,2),dtype='int')
i = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
#_表示的就是具体的value,preds表示下标,1表示在行上操作取最大值,返回类别
_,preds = torch.max(outputs.data,1)
predictions[i:i+len(classes),1] = preds.to('cpu').numpy();
predictions[i:i+len(classes),0] = np.linspace(i,i+len(classes)-1,len(classes))
#可在过程中看到部分结果
print(predictions[i:i+len(classes),:])
i += len(classes)
print('creating: No. ', i, ' process ... total: ', size)
return predictions
result = result_model(model_vgg_new,loader_test,size=dset_sizes['test'])
np.savetxt("./cat_dog/result.csv",result,fmt="%d",delimiter=",")
这行代码需要根据自己的文件结构进行修改:
result = result_model(model_vgg_new,loader_test,size=dset_sizes['test'])```
–张丁月
一、实验步骤
1.代码环境配置
首先创建claboratory文件

然后测试是否需要GPU上

2.数据下载
可以下载的训练集,包含1800张图(猫的图片900张,狗的图片900张),测试集包含2000张图。为了之后的猫狗大战,我选择直接下载好猫狗大战比赛的官方数据集,上传谷歌云盘并解压

3.数据预处理
(1)图片将被整理成 224 × 224 × 3 224\times 224 \times 3224×224×3 的大小,同时还将进行归一化处理。
(2)其他的一些对数据的复杂的预处理/变换
(3)设置VGG的格式
(4)加载图像的数据。

(5)将数据拆分为训练集和有效集
(6)取一小部分数据用来做可视化

打印图片和对应结果:

打印取出的几张图片

由图可知:
(1)input_try是5张244x244x3(RGB三通道)的小图片;
(2)lable_try是这五张图片对应的标签,都是0,说明,这五张照片都是猫。
4.创建VGG
接下来的dic_imagenet是各种动物的标签。
来源自下载的模型中会对数据有一个分类的总概率分布,有5000种分类,dic_imagenet适合最终的分类概率有关的一个数。

打印出结果,观测可知:
- 结果为5行(因为一共是5张图片嘛),1000列的数据,每一列在不同dic_imagenet 目标识别的结果。
- 结果非常奇葩,有负数,有正数。
- 为了好看(至少让数据看起来像一个概率),我们把结果输入到 Softmax 函数。
5.修改最后一层网络,冻结前面层的参数
因为我们使用的模型是现成的、预训练好的模型,所以大部分的模型参数我们都不需要动,只需要动最后全连接层输出部分的参数就可以了(也就是修改最后一层网络)。
因此,
需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。


6.训练全连接层
虽然VGG大部分层数参数不需要更改,但是毕竟最后输出还是要靠全连接层,最后一层的参数是发生变动的(相当于前面99%的网络都别人训练好的,我就训练最后的1%),所以我们还是需要训练、并测试全连接层。


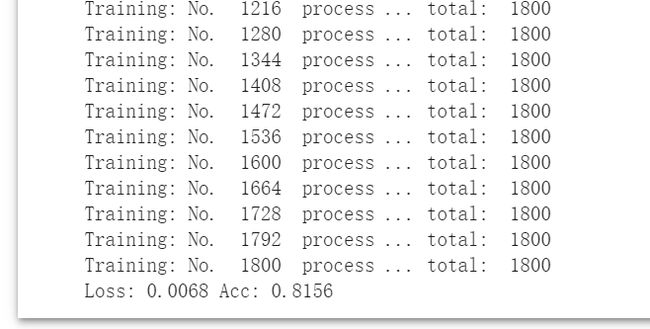
7.测试整个模型
现在整个模型都训练好了,那就理所应当的跑一跑,测试而已。
现在输入的是Valid集,因为它自带标签,可以用来统计一些误差数据。

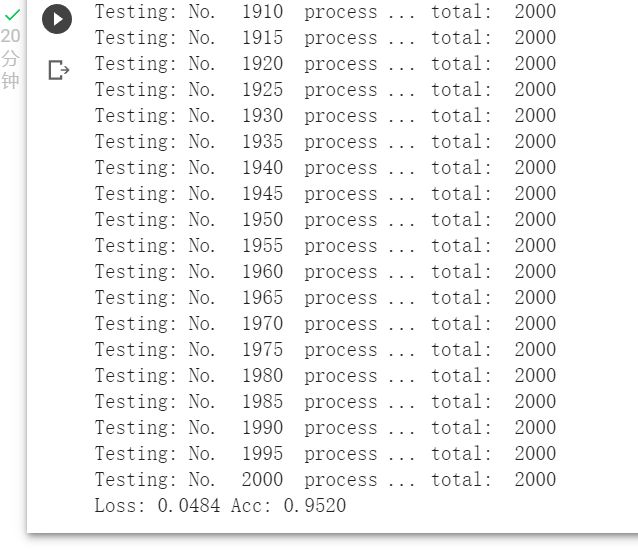
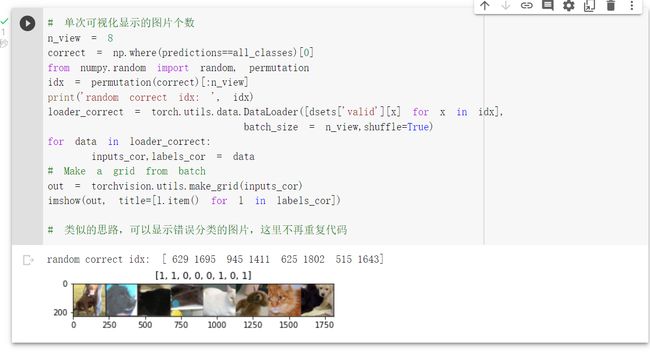
8.可视化输出结果
打印结果,其中0是猫;1是狗
9.输出csv
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VkmzyeFc-1666446273445)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/18.png)]

测试结果如下:

二、实验总结
这次实验还是遇到了很多问题,不过前面的解决起来都很容易,因为有老师发的教程,最难还是最后导出实验结果csv文件那里,最开始我仿照大佬的代码,发现最后导出格式错误,以为是前面训练测试模型的毛病,找了半天,最后又把代码改错了,总之绕了好大一个圈子,最后才醒悟是导出csv文件那一部分代码的锅。也算是长个教训吧,以后找错误时要动动脑子。
–杨淋云
一、在谷歌Colab上完成猫狗大战VGG模型的迁移学习
在本教程中,我们将建立一个模型来完成猫狗大战竞赛题目。在这个比赛中,有25000张标记好的猫和狗的图片用做训练,有12500张图片用做测试。

1.下载数据
一个新的数据集,训练集包含1800张图(猫的图片900张,狗的图片900张),测试集包含2000张图。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yu6f18Ue-1666446273446)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022163439.png)]
2.数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成224×224×3的大小,同时还将进行归一化处理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MeHMz89S-1666446273447)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022165250.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwZCAjel-1666446273447)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022170541.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BEotVFTY-1666446273448)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/S801_J4WR1B31G{B}UA%1UW.png)]
3.创建VCG模型
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Oy5wNEUm-1666446273448)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/BT158~_(BK5ZK1H4W_NK%)]J.png)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vWgpgSwK-1666446273448)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022170803.png)]
4.修改最后一层,冻结前面层的参数
我们的目标是使用预训练好的模型,因此,需要把最后的nn.Linear层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置required_grad = False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。

5.训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eq9wxUho-1666446273449)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022170923.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aGNHyKGm-1666446273449)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022170958.png)]
6.可视化模型预测结果
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
- 随机查看一些预测正确的图片
- 随机查看一些预测错误的图片
- 预测正确,同时具有较大的probability的图片
- 预测错误,同时具有较大的probability的图片
- 最不确定的图片,比如说预测概率接近0.5的图片
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-torHOkxI-1666446273449)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022171027.png)]
二、AI研习社“猫狗大战”比赛,上传结果在线评测
1.导出csv文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CuZfJ8dT-1666446273450)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022173920.png)]
2.进入AI研习社上传结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SSspxnLO-1666446273450)(https://1yly1.oss-cn-hangzhou.aliyuncs.com/images/QQ%E5%9B%BE%E7%89%8720221022173234.png)]
3.分析使用哪些技术可以进一步提高分类准确率
1)采集更多数据;2)添加更多层;3)更改图像大小;4)增加训练轮次;5)减少颜色通道;6)迁移学习。
预测正确,同时具有较大的probability的图片
- 预测错误,同时具有较大的probability的图片
- 最不确定的图片,比如说预测概率接近0.5的图片
[外链图片转存中…(img-torHOkxI-1666446273449)]
二、AI研习社“猫狗大战”比赛,上传结果在线评测
1.导出csv文件
[外链图片转存中…(img-CuZfJ8dT-1666446273450)]
2.进入AI研习社上传结果
[外链图片转存中…(img-SSspxnLO-1666446273450)]
3.分析使用哪些技术可以进一步提高分类准确率
1)采集更多数据;2)添加更多层;3)更改图像大小;4)增加训练轮次;5)减少颜色通道;6)迁移学习。