【研究报告】从单目深度估计到单目三维场景重建-沈春华老师-VALSE Webinar 22-13(总第279期)
从单目深度估计到单目三维场景重建-沈春华老师-VALSE Webinar 22-13(总第279期)
- 报告总结 & 相关论文
- 论文代码
- 相关术语
- 前言
- 研究问题
-
- 单目深度估计
- 单目三维场景重建
- 难点 & 解决方案
-
- Low Generalizability
-
- 如何提升单目深度估计模型的泛化能力?- 解决方案:DCNF-FCSP
- 如何保证单目深度估计模型泛化能力?- 解决方案:超大数据集
- 如何收集超大数据集?- 解决方案:Relative Depth
- 如何收集超大相对深度数据集?- 解决方案:Stereo Data + Video
- 如何得到更准确的三维点云?- 解决方案:估计 Scale 和 Shift
- Low-quality 3D Geometry
-
- 如何在模型训练过程中使用 3d Geometry 信息?- 解决方案:Virtual Normal
-
- surface normal Vs virtual normal
- Scale 一致性问题
-
- 如何保证 Scale 一致性?- 解决方案:SC-DepthV1 (Geometry Consistency Loss)
-
- SC-DepthV2 针对室内 video 对 SC-DepthV1 的改进
- 如何解决单目深度估计中小目标被忽略问题?- 解决方案:Anctor Points
- Q&A
-
- NeRF与您研究方向的相关性及其前景探讨
- 构建数据集时depth数据是如何得到的?
- 自监督是否可以做单目深度估计?
- 自监督对比全监督差异多大?
- MVSNet与模型泛化研究有关联吗?
- 6d pose 与单目深度估计相关性?
报告总结 & 相关论文
沈春华老师讨论的研究方向:单目深度估计模型泛化能力及单目重建更正确的三维点云。

注:因为只有单张图片,恢复出的三维点云形状是正确的,但不是metric的三维点云,恢复不出 scale。
1 如何解决单目深度估计的泛化能力低的问题?
① 深度估计模型:将单目深度估计问题转换为连续条件随机场。
② 数据集:使用超大规模相对深度数据集,覆盖尽可能多的场景。
提出 DCNF-FCSP模型(CNN+CRF + full convolutional superpixel pooling)的论文:Learning depth from single monocular images using deep convolutional neural fields, F. Liu, C. Shen, G. Lin, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2016.
提出 将单目深度估计问题转换为连续条件随机场 的论文:Deep convolutional neural fields for depth estimation from a single image.F. Liu, C. Shen, G. Lin. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15), 2015.
提出 Diverse Scene Depth dataset (DiverseDepth) 数据集的论文:Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction,W. Yin, Y. Liu, C. Shen. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
2 如何收集训练单目深度估计模型的超大数据集?
因为采集绝对深度数据很困难,所以选择收集相对深度数据集。
3 如何收集相对深度数据集?
方案一:从双目图片中恢复出 depth。双目匹配得到左右图间的 correspondence 后恢复出 affine-invariant relative depth 。
方案二:从视频中恢复出 depth。估计出相机的pose,可以得到跟双目一样的 affine transform depth maps。
该数据集缺点:数据集质量不同,需要使用不同的 loss function。
提出 基于立体图进行单目相对深度估计 的论文:Monocular relative depth perception with web stereo data supervision,K. Xian, C. Shen, Z. Cao, H. Lu, Y. Xiao, R. Li, Z. Luo. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’18).
提出 SC-DepthV1 (视频深度估计(室外视频))的论文:Unsupervised scale-consistent depth and ego-motion learning from monocular video,J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M. Cheng, I. Reid. Proc. Advances in Neural Information Processing Systems (NeurIPS’19), 2019.
提出 SC-DepthV2(视频深度估计(针对室内视频改进))的论文:Auto-rectify network for unsupervised indoor depth estimation,J. Bian, H. Zhan, N. Wang, T. Chin, C. Shen, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
4 如何在质量不同的相对深度超大数据集上训练出较好模型?
① 数据集质量不同,需要使用不同的 loss function。
② 在训练过程中使用 3D Geometry Information。如果有视频数据,将视频数据进行ORB-SLAM得到稀疏点(Anctor Points)的深度作为单目深度估计的 ground-truth。
提出 利用 Anctor Points 校准单目深度估计的输出 论文:Towards 3D Scene Reconstruction from Locally Scale-Aligned Monocular Video Depth. Guangkai Xu, Wei Yin, Hao Chen, Kai Cheng, Feng Zhao, Chunhua Shen. Computer Vision and Pattern Recognition (cs.CV)
5 如何在训练过程中使用 3D Geometry Information?
虚拟法线(virtual normal)。理论上在重建出的三维点云中任意取三个点确定出一个平面,计算出该平面的法线应该跟真实标签中这三个点确定出的平面的法线方向相同。
提出 Virtual Normal 的论文:Enforcing geometric constraints of virtual normal for depth prediction, Wei Yin, Yifan Liu, Chunhua Shen, Youliang Yan, Computer Vision and Pattern Recognition (cs.CV). 2019
提出 affine-invariant relative depth 的论文:Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction,W. Yin, Y. Liu, C. Shen. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
6 如何保证视频中Scale一致性?
使用几何一致性损失 Geometry Consistency Loss 对 Scale 一致性约束,估计出 camera pose,两帧之间做一次Wrapping得到点与点之间的对应关系,进而计算出 photo metic loss。如果 scale 是一致的,那么 wrapping 之后对应的点的 depth 应该是一模一样的。
提出 SC-DepthV1 (Geometry Consistency Loss + Self-Discovered Mask)的论文:Unsupervised scale-consistent depth and ego-motion learning from monocular video,J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M. Cheng, I. Reid. Proc. Advances in Neural Information Processing Systems (NeurIPS’19), 2019.
提出 SC-DepthV2(分析相机运动与深度估计的关系 + 提出 Auto-Rectify Network)的论文:Auto-rectify network for unsupervised indoor depth estimation,J. Bian, H. Zhan, N. Wang, T. Chin, C. Shen, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
7 如何解决室内场景相机运动不规律导致SC-DepthV1效果不好的问题?
SC-DepthV2,是SC-DepthV1的改进版,从相机运动的角度去分析两种场景的差异,并且分析了相机运动与深度估计的关系。最终提出自校准网络(Auto-Rectify Network)来克服室内场景相机运动不规律的难题。将ARN嵌入到现有框架SC-Depth中可以实现端到端训练,并在多个数据集上大幅超过现有算法。
随着无监督单目深度估计算法在自动驾驶场景精准的逐步提升,研究者们开始探索其在室内VR/AR场景中的应用。然后后者相比前者更为困难。本文从相机运动的角度去分析两种场景的差异,并且分析了相机运动与深度估计的关系。最终提出自校准网络(Auto-Rectify Network)来克服室内场景相机运动不规律的难题。将ARN嵌入到现有框架SC-Depth中可以实现端到端训练,并在多个数据集上大幅超过现有算法。
SC-DepthV2(分析相机运动与深度估计的关系 + 提出 Auto-Rectify Network)的论文:Auto-rectify network for unsupervised indoor depth estimation,J. Bian, H. Zhan, N. Wang, T. Chin, C. Shen, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
8 如何更准确的重建三维点云?
估计出 focal length(对应 Affine Tranformation 中的 Scale A)和 shift(对应 Affine Tranformation 中的 shift b),重建出来的三维点云更准确。
提出 估计 Scale + Shift 的论文:Learning to recover 3D scene shape from a single image. W. Yin, J. Zhang, O. Wang, S. Niklaus, L. Mai, S. Chen, C. Shen. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’21), 2021.
论文代码
http://github.com/aim-uofa/AdelaiDepth
相关术语
Multi-view Geometry(Multiple View Geometry):多视图几何。
SfM(Structure from motion) :一种三维重建的方法,用于从motion中实现3D重建。也就是从时间系列的2D图像中推算3D信息。输入:一段motion或者一时间系列的2D图群。输出: 每一张图像对应的相机位置和朝向, 场景中的3D点云。
参考:基于SfM(Structure from motion)的三维重建详解 - 爱看小说的科研狗的文章 - 知乎
参考:三维重建——Structure from motion
SLAM(Simultaneous Localization And Mapping):同步定位与地图构建的缩写,最早由Hugh Durrant-Whyte 和 John J.Leonard提出。SLAM主要用于解决移动机器人在未知环境中运行时定位导航与地图构建的问题。SLAM通常包括如下几个部分,特征提取,数据关联,状态估计,状态更新以及特征更新等。对于其中每个部分,均存在多种方法。SLAM既可以用于2D运动领域,也可以应用于3D运动领域。
参考:基于SfM(Structure from motion)的三维重建详解 - 爱看小说的科研狗的文章 - 知乎
ill-posed problem :不适定问题。经典的数学物理方程定解问题中,人们只研究适定问题。适定问题是指定解满足下面三个要求的问题:① 解是存在的;② 解是唯一的;③ 解连续依赖于定解条件,即解是稳定的。这三个要求中,只要有一个不满足,则称之为不适定问题。
Open Set/Word Prediction :在如今计算机视觉算法大都采用闭集(closed set)识别,即是测试(testing)时候的种类完全在训练(training)时遇见过。而开集(open set)识别,则需要在测试时候遇见未知的种类(class),这就需要强大的泛化能力的算法来实现。
Open Set:训练集知识不完整,测试集中存在未知类别。
Open World:训练集包括已知类与未知类。
论文:Towards Open World Object Detection
论文:Toward Open Set Recognition
参考:Open set/world learning 笔记2:Toward Open Set Recognition - 浮云向晚
Few-shot Learning(FSL) (Small Sample Training):人类非常擅长通过极少量的样本识别一个新物体,比如小孩子只需要书中的一些图片就可以认识什么是“斑马”,什么是“犀牛”。在人类的快速学习能力的启发下,研究人员希望机器学习模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是 Few-shot Learning 要解决的问题。
Few-shot Learning 是 Meta Learning 在监督学习领域的应用。Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
Few-shot Learning 在机器学习领域具有重大意义和挑战性,是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点。
参考:小样本学习(Few-shot Learning)综述 - PaperWeekly的文章 - 知乎
参考:Few-shot learning(少样本学习)入门 - Reset的文章 - 知乎
参考:小样本学习——概念、原理与方法简介(Few-shot learning) - Serendipity的文章 - 知乎
Metric Depth:绝对深度,利用激光雷达等设备获取的相机与物体之间的距离。用绝对深度图作为训练数据得到的模型是可以预测绝对深度的,David E等人一系列的算法都是这一类型的。
Relative Depth:相对深度,哪些点离摄像机更近,哪些点离摄像机更远。使用相对深度图作为训练数据训练出来的模型只能预测相对深度(比如这篇论文:Learning Ordinal Relationships for Mid-Level Vision),其与真实深度之间差了一个基准值,这个值是不知道的。
参考:相对深度与绝对深度,深度图与真实距离
Affine Transformation:仿射变换,定义为一个线性变换加上平移变换。
线性变换从几何直观有三个要点:① 变换前是直线的,变换后依然是直线。② 直线比例保持不变。> ③ 变换前是原点的,变换后依然是原点。
仿射变换从几何直观只有两个要点(少了原点保持不变):① 变换前是直线的,变换后依然是直线。② 直线比例保持不变。
参考:如何通俗地讲解「仿射变换」这个概念? - 马同学的回答 - 知乎
参考:仿射变换 - 异次元的归来的文章 - 知乎
Surface Normal:表面法线
参考:Normal (geometry) - wikipedia
Intrinsics:相机内参矩阵,相机内参矩阵中的参数一般都是相机出厂就定下来的,可以通过相机标定的方式人为计算出来。
Extrinsics:相机外参。
从相机坐标系转换到像素坐标系中,相机内参(Intrinsics)的作用
从世界坐标系转换到相机坐标系中,相机外参(Extrinsics)的作用
参考:一文带你搞懂相机内参外参(Intrinsics & Extrinsics) - Last的文章 - 知乎
参考:相机的内参和外参分别是什么意思? - 大黑的回答 - 知乎
Stereo Match:立体匹配也称 视差估计、 双目深度估计。
输入:一对在同一时刻捕捉的,经过 极线校正 的左右图像 I l Il Il和 I r Ir Ir
输出:参考图像(一般选为左图)每个像素对应的视差值对应的视差图 d
根据公式 z = b ∗ f / d z = b*f / d z=b∗f/d 可获得深度图
b: 两相机光心距离
f: 相机光心到成像平面的焦距
d: 两相机的视差
参考:立体匹配|Stereo Matching - doubleZ的文章 - 知乎
Optical Flow:光流法。
目的:通过连续的图像序列来检测图像序列中运动物体微小的动作变化。光流在图像中的含义就是动作向量(motion vector)(u,v),其> 中u,v分别表示位移在x和y方向上的变化率,也就是某个位置的x分量和y分量的速度。
原理:在通用亮度假设的条件下,通过对邻帧之间的像素点进行建模,推导当前帧某个像素点在之后时间的运动方向,也就是一种预测当> 前像素点未来运动信息的方法。
SLAM (Simultaneous Localization and Mapping):又称CML (Concurrent Mapping and Localization),即时定位与地图构建,或并发建图与定位。
Zero-Shot Learning:对某(些)类别完全不提供训练样本的迁移任务被称为零次学习。
指的是训练集中没有这个类别的训练样本。但是可以学习到一个映射X->Y。如果这个映射足够好的话,就可以处理没有看到的类了。比如,在训练时没有看见过狮子的图像,但是可以用学习到的映射得到狮子的特征。一个好的狮子特征,可能就和猫,老虎等等比较接近,和汽车,飞机比较远离。
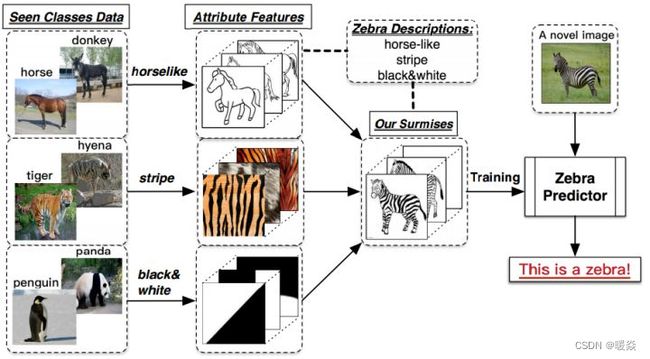
假设斑马是未见过的类别,但根据描述和过去知识的印象即马(和马相似)、老虎(有条纹)、熊猫(颜色)相似进行推理出斑马的具体形态,从而能对新对象进行辨认。(如下图所示)零次学习就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
从见过的类别(第一列)中提取特征(如:外形像马、条纹、黑白),然后根据对未知类别特征的描述,测试未见过的类别。
论文:Zero-Shot Learning with Semantic Output Codes
参考:什么是 One/zero-shot learning? - 郑哲东的回答 - 知乎
参考:zero-shot基础入门
参考:初探zero-shot/one-shot learning
One-Shot Learning:对某(些)类别只提供一个或者少量的训练样本的迁移任务被称为一次学习。
论文:One-Shot Learning of Object Categories
Newral Radiance Fields(NeRF):神经辐射场。
NeRF 所要做的 task 是 Novel View Synthesis,一般翻译为新视角合成任务,定义是:在已知视角下对场景进行一系列的捕获 (包括拍摄到的图像,以及每张图像对应的内外参),合成新视角下的图像。传统方法使用 IBR (Image Based Rendering) 方法的较多,也有一些使用深度学习和 IBR 结合的方法,这些我们不过多介绍。
NeRF 想做这样一件事,不需要中间三维重建的过程,仅根据位姿内参和图像,直接合成新视角下的图像。
NeRF大致可以分为三步:
1 通过分析照相视角射线,从一组图片来生成一组采样点;
2 将获得的采样点以及与之对应的2D视角方向作为输入,来输出一组颜色和密度(原文中使用的是densities,我的理解应该就是体素表示的一个参数);
3 利用体素渲染技术,利用之前得到的颜色和密度生成希望看到的任意视角照片。
论文:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
参考:神经辐射场简介 - 闫钊的文章 - 知乎
参考:Neural Radiance Fields (NeRF) - 谷溢的文章 - 知乎
参考:火爆科研圈的三维重建技术:Neural radiance fields (NeRF) - 程序猿老甘 - CSDN
前言
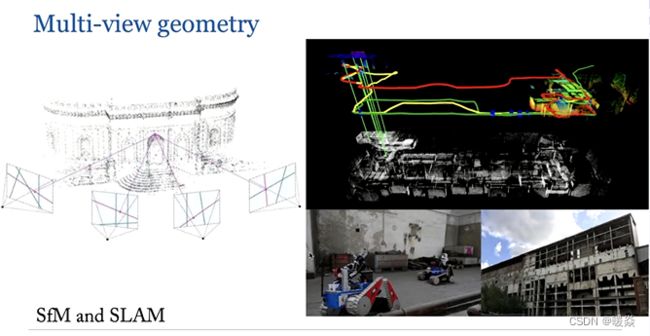
多视角几何中,需要两张或者两张以上图片进行深度估计或者三维点云估计,这是一个非常经典的计算机视觉问题,可能计算机视觉刚开始的时候就是研究多视角几何。
图 1 左边,从多张图片找到图与图之间对应关键点的对应关系之后,在小孔成像假设下可以推导出一系列公式,然后重构出三维点云。
图 1 右边,展示的是slam,在传统的 Multi-view geometry 中研究问题。 slam其实可以看成是 structure from motion 的一个应用。一般做单目的slam时,输入一个视频和输入多帧图片没有本质区别。
研究问题
估计单张图片中每个像素的深度信息,如果每个像素的 depth 信息估计的很准,并且知道相机模型和参数,那么理论上也可以估计出三维点云完成三维重建。
从单张图片估计每个像素深度,因为没有多视图关键点(Multi-view key point)的对应关系(correspondence),从数学优化角度来看,这是一个不适定问题(ill-posed problem)。
单目深度估计
单目深度估计问题的研究,最早可以追溯到2010年左右,当时使用 machine learning 的算法实现,因为这是一个不适定问题,并且只有单张图片,所以需要大量的 Prior Information,即 machine learning 算法需要大量的训练数据,用 Regression 或者 Classification 从大量的训练数据中进行 depth estimation。

图2,展示了 Depth Estimation 的一个例子。
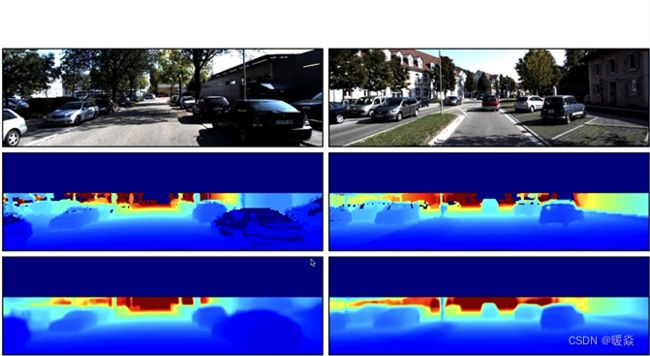
图3,展示了 KITTI 自动驾驶数据集上的例子。中间一行是雷达采集到的真实标签(ground-truth),最下面一层是模型的输出。
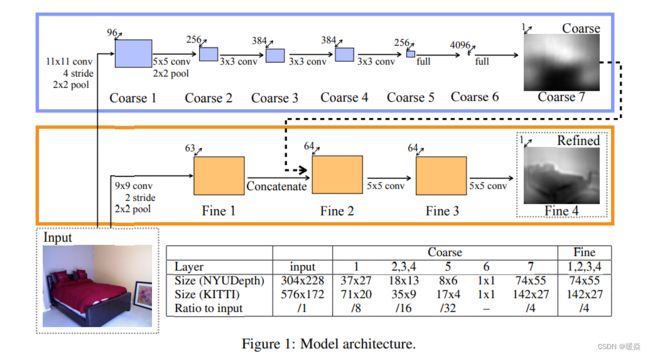
利用深度学习实现单目深度估计,最早可以追溯到2014年12月份纽约大学 Eigen 等人发表的论文 Depth Map Prediction from a Single Image using a Multi-Scale Deep Network。论文中的 Model Architecture 如图 4 所示。
单目三维场景重建

参考:基于单目视觉的三维重建算法综述 - SIGAI_csdn
尽管单眼深度估计在野外场景取得了重大突破,但是最新的方法不能够用于准确恢复的3D场景形状,原因是未知的深度位移和未知的相机焦距。

CVPR 2021,沈春华老师团队发表了论文 Learning to recover 3D scene shape from a single image. W. Yin, J. Zhang, O. Wang, S. Niklaus, L. Mai, S. Chen, C. Shen. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’21), 2021. ,提出一种两阶段架构。① 预测图像深度(单眼图像未知比例及偏移);② 利用3D点云编码器预测缺失的深度位移和焦距(帮助恢复一个真实的3D场景形状)。
难点 & 解决方案

Low Generalizability
使用深度学习模型进行单目深度估计,都面临 Low Generalizability 问题,即使用训练集训练完成后在测试集上运行不太好,沈春华老师团队的 idea 就是希望提高模型 Generalization Capability,解决模型 Low Generalizability 问题, 甚至是希望模型在所有场景都能工作(Open Set prediction 和 Open World prediction)。
不仅深度估计存在 Generalization 问题,image classification 也存在 Generalization 问题。
目前,Few-shot Learning(或 Small Sample Training ) 仍然没有新的突破,针对 Generalization 问题,比较有效的方法是收集超大训练集(足以 cover 所有测试集可能遇到的情况)。
但是,收集超大训练集成本很高,很难收集一个足以 cover 所有测试集可能情况的训练集。理论上来可能需要用 RGB 相机再加上一个 scanner 同时采集数据,之后再做校准(alignment)。若想要训练数据覆盖所有的室,工作量会比较大。
如何提升单目深度估计模型的泛化能力?- 解决方案:DCNF-FCSP
之前的模型仅限于对特定场景结构建模,不适用于一般场景深度估计,针对单目深度估计模型泛化能力低的问题,沈春华老师团队也是从2014年开始研究单目深度估计,发表了两篇论文:第一篇论文主要工作是将单目深度估计问题转为连续条件随机场 CRF,第二篇论文主要工作是提出 DCNF-FCSP 模型,模型在室内和室外数据集上效果都很好。
【论文1】 提出 CRF 的论文: Deep convolutional neural fields for depth estimation from a single image.F. Liu, C. Shen, G. Lin. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15), 2015.
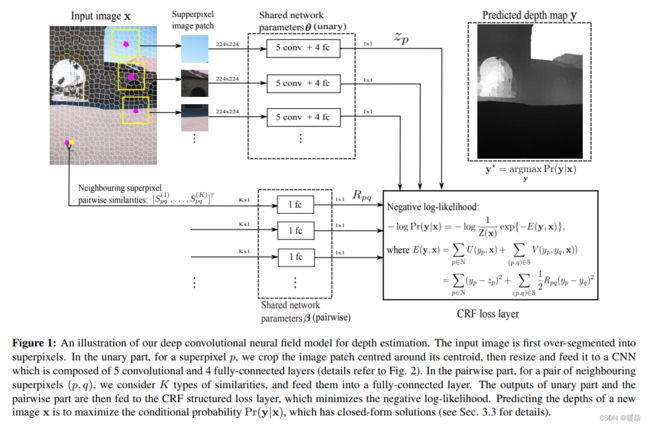
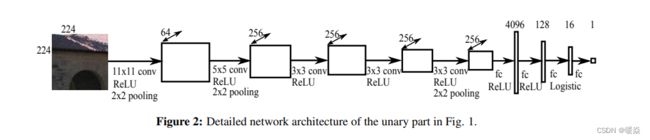
论文中的网络结构如图 7 所示,整个网络由一元部分(a unary part),二元部分(a pairwise part)和CRF损失层组成。如图 8 所示,一元部分由5个卷积层和4全连接层组成。
主要思想是将单目深度估计问题转换为连续条件随机场(Conditional Random Field,CRF),思想来源是理论上像素与像素之间存在相关性,利用CRF model pairwise 的信息。如果使用 regression 输出的 depth 是连续的,假设数据服从 gauss distribution,那么 CRF Inference 模型存在封闭解(closed form)。因为CRF存在封闭形式的解决方案,那么CNN的整个 object function 是可导的,可以直接将梯度显式计算出来。将CRF与卷积神经网络结合比较友好,如果是 discrete 就会比较麻烦,因为CRF做 Inference 在 discrete 情况下比较慢。
这项工作的主要贡献如下:
- 我们通过探索CNN和连续CRF,提出了深度卷积神经场模型用于深度估计。考虑到深度值的连续性质,可以解析计算概率密度函数中的分区函数,因此我们可以直接求解对数似然优化而无需任何近似。可以在反向传播训练中精确计算梯度。而且,由于存在封闭形式的解决方案,解决用于预测新图像深度的MAP问题是非常有效的。
- 我们在统一的深度CNN框架中共同学习CRF的一元势函数和二元势函数,并使用反向传播对其进行了训练。
- 我们证明了所提出的方法在室内和室外场景数据集上都优于深度估计的最新结果。
本篇论文优势:
①我们不采用任何这些启发式方法改进我们的结果,但我们就相对误差而言取得了更好的结果。
②为了克服过拟合,其他方法必须收集数以百万计的带有附加标签的图像训练他们的模型。一个可能的原因是,他们的方法捕捉到绝对像素的位置信息,他们可能需要一个非常大的训练集覆盖所有可能的像素布局。相比之下,我们只使用没有任何额外数据标准的训练集,但我们获得相媲美,甚至更好的性能。
③我们的模型只有一元项的时候,相当于带有模糊边界的粗糙预测。通过加入平滑项,我们的模型产生了更好的可视化,接近ground-truth。
【论文2】 提出 DCNF-FCSP 的论文:Learning depth from single monocular images using deep convolutional neural fields, F. Liu, C. Shen, G. Lin, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2016.
论文工作的主要贡献如下:
- 我们通过探索CNN和连续CRF,提出了深度卷积神经场(DCNF)模型用于深度估计。考虑到深度值的连续性质,可以解析计算概率密度函数中的分区函数,因此我们可以直接求解对数似然优化而无需任何近似。可以在反向传播训练中精确计算梯度。而且,由于存在封闭形式的解决方案,解决用于预测新图像深度的MAP问题是非常有效的。
- 我们在统一的深度CNN框架中共同学习CRF的一元势能和二元势能,并使用反向传播对其进行了训练。
- 我们提出了一种基于全卷积网络和新颖的超像素池化方法的更快模型,该模型可将速度提高约10倍,同时产生相似的预测精度。使用这个更有效的模型(我们称为DCNF-FCSP),我们能够设计非常深的网络以获得更好的性能。
- 我们证明了所提出的方法在室内和室外场景数据集上都优于深度估计的最新结果。
如何保证单目深度估计模型泛化能力?- 解决方案:超大数据集
想要保证模型 Generalization Capability ,需要训练集 cover 尽可能多的场景。所以,沈春华老师团队在2018年CVPR构建了一个比较大的数据集,并且在训练的时候使用能找到的所有开源数据集,不同的数据集的标注质量不同,其中包含最弱的数据集 depth in the wild(每张图片只标注了两个点及其前后关系)。也包含使用Lidar Scanner得到的高质量数据集(含有精确的 metric depth )。


如何收集超大数据集?- 解决方案:Relative Depth
收集 metric depth 超大训练集很困难,相比之下,收集 relative depth 超大训练集更容易,当然也可以是 对 metric depth 的 Affine Transformation(在很多场景下也比较容易得到)。

当然,因为没有绝对深度,相对深度图的信息比较粗糙,重建三维点云会比较困难。如图 9 所示,一张大象的相对深度图,重建出来的三维信息很不准确。

对 metric depth 进行 Affine Transformation 的数据作为训练数据,Affine 实际上是 Ax+b 线性变换加平移,Scale A 和 shift b 对三维重建非常重要,如果使用不准确的 A 和 b 估计出的 relative depth 进行三维重建,重建出的三维点云非常不准确。如图 10 所示,三维点云出现扭曲(distortion)。
如何收集超大相对深度数据集?- 解决方案:Stereo Data + Video
传统采集 metric depth 的办法是 rgb + laser scanner ,该方法最直接且精度最高,但是很难收集到覆盖各种场景的大规模数据集。
18年,沈春华老师团队提出了一种方案,从双目图片中恢复出 depth,从网上可以爬取到很多双目图片,再进行双目匹配得到左图和右图两张图片之间的 correspondence ,之后恢复出 depth 。因为没有相机的参数,所以不能得出 metric depth 。用上述方法恢复出的 depth 是 affine-invariant relative depth 。
提出 基于立体图进行单目相对深度估计 的论文:Monocular relative depth perception with web stereo data supervision,K. Xian, C. Shen, Z. Cao, H. Lu, Y. Xiao, R. Li, Z. Luo. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’18).
本文主要贡献是:
1 提出一种简单有效的方式从网络立体图片中自动获取图片密集相对深度标注,并提出新的数据集 “Relative Depth from Web”(ReDWeb);
2 提出改进 ranking loss,使网络能够关注难以判断相对深度关系的点对;
3 将方法应用于 DIW 和 NYUDv2 数据集并获得了最佳性能,同时将预训练的网络用于其他基于像素点预测的任务,如绝对深度预测和语义分割,能够有效提高性能。
参考:该论文精读笔记 - _Suraimu_ - CSDN

使用的是 Optical Flow,而不是传统的 Stereo Match ,因为爬取到的很多图片水平基线不对齐,所以使用传统的 Stereo Match 方法会有问题。

天空的分割:天空对应无穷远,将天空的像素单独分割出来赋值为无穷远。


下面图片展示该数据集的应用。


假设已知左图,可以推出右图,由左右两张图片即可得到 3d 信息,这种方法也可以应用于将 2d 电影转换为 3d 电影。
得到 depth map 还可以应用于 模拟大光圈效果。

不同质量的训练数据,需要使用不同的 loss function。

如何得到更准确的三维点云?- 解决方案:估计 Scale 和 Shift




如上述图片所示,如果不知道 focal length(对应 Affine Tranformation 中的 Scale A),会造成三维点云的 distortion;如果不知道 shift(对应 Affine Tranformation 中的 shift b),也会造成三维点云的 distortion。所以要将这两个值估计出来。

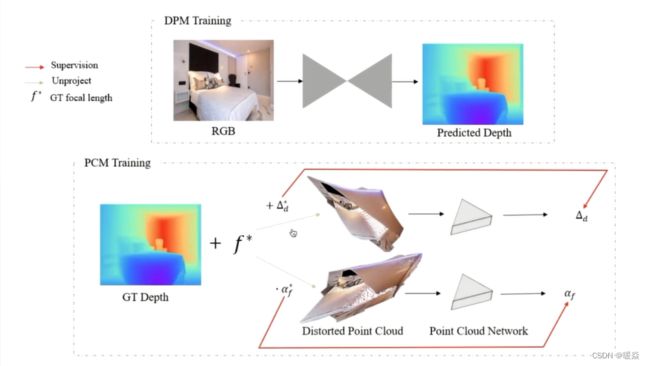
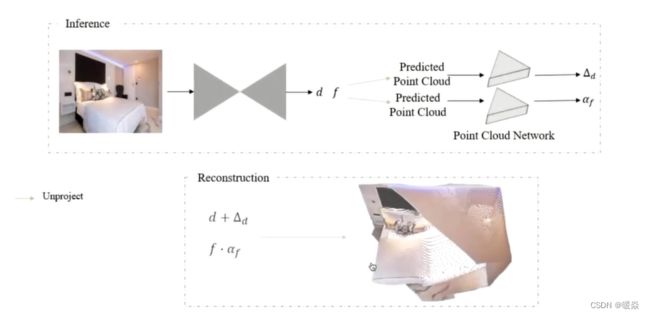
CVPR 2021,沈春华老师团队提出了一种两阶段架构方案,① 预测图像深度(单眼图像未知比例及偏移);② 利用3D点云编码器预测缺失的深度位移和焦距(分别对应 shift 和 scale )(帮助恢复一个真实的3D场景形状)。如图 11 所示。





Two-stage单张图像3D形状估计 pipeline,由深度预测模块(DPM)和点云模块(PCM)组成。
DPM和PCM两模块不同数据源上分别训练,在推理过程中相结合。
DPM模块:输入RGB图像→depth map (与真实的绝对深度图的比例和位移未知)
PCM模块:输入扭曲的点云 →利用预测的深度图 d 和焦距的初始估计 f 计算 →输出对深度图和焦距的位移调整,以提高重建的3D场景形状的几何形状。
使用数据集训练得到模型之后,将 depth 经过 Unprojection 从 2.5D 提升到 3D ,affine 过程中的 scale 和 shift 参数会对三维点云造成比较大的影响,所以,如果想要得到准确的三维点云,必须估计出 scale 和 shift 。
注意:使用点云网络分别预测位移和焦距比例因子。
depth shift -> ∆d , focal length -> f∙ α_f
精确的场景形状重建
提出 估计Scale+Shift 的论文:Learning to recover 3D scene shape from a single image. W. Yin, J. Zhang, O. Wang, S. Niklaus, L. Mai, S. Chen, C. Shen. Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR’21), 2021.
参考:Learning to Recover 3D Scene Shape from a Single Image - MengYa_Dream - CSDN




以下图片展示模型效果。





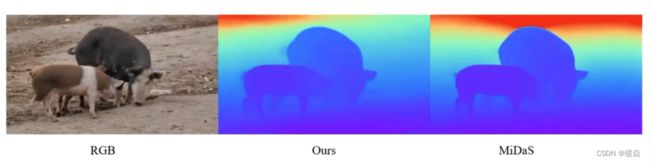
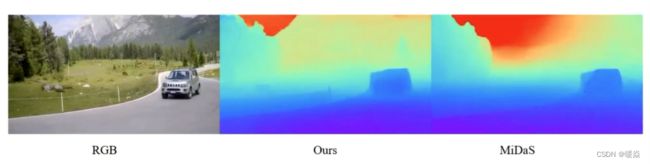
以下图片展示论文模型 depth map 的输出也有提升。




local 和 global 的信息都有用,都应该用上。

Low-quality 3D Geometry
迄今为止,depth estimation 算法都是在 minimize regression loss ,都是图像 RGB 再加上 depth在空间里面去做 fitting,没有真正考虑 3d 信息。但理论上只有在模型训练过程中使用 3d Geometry 信息,才能准确的重建 3d Geometry,之前很少有研究涉及这个问题。
如何在模型训练过程中使用 3d Geometry 信息?- 解决方案:Virtual Normal
之前的工作都没有在三维点云空间中计算Loss,几乎所有的 paper 都是 pointwise 的 regression 或者 discrete classification(两者得到的结果差不多)。
沈春华老师团队的目标是准确的恢复三维点云,所以要在模型训练过程中使用 3d Geometry 信息。

最简单的一种 3d Geometry 信息是表面法线(surface normal),沈春华老师团队提出了虚拟法线(Virtual normal)的概念,在模型训练过程中使用 3d Geometry 信息。
思路:如果重建出的三维点云跟真实标签(ground-truth)一致,那么理论上在重建出的三维点云中任意取三个点确定出一个平面,计算出该平面的法线应该跟真实标签中这三个点确定出的平面的法线方向相同。这是 surface normal 的一种扩展,因为任意取的三个点确定出的平面不一定是物体或场景的 surface 。
注:因为没有 metric depth ,训练集的 depth 是 metric depth 的 Affine Transformation,但 Affine 过程中的线性变换加平移操作并不会改变平面法线的方向。
论文:Enforcing geometric constraints of virtual normal for depth prediction, Wei Yin, Yifan Liu, Chunhua Shen, Youliang Yan, Computer Vision and Pattern Recognition (cs.CV). 2019
介绍了一种有监督单目深度估计的方法.首先提出了问题——现有的很多方法大多采用pixel-wise的损失函数和评价指标,而忽略了3D空间中的几何约束。对于一些考虑了几何约束的方法,几乎所有的都是从2D或3D的小邻域中提取的意义上的“局部”。例如,表面法线本质上是“局部”的,因为它是由局部切线平面定义的。我们能够得到的深度的gt通常是包含噪声的,不可避免地影响这些局部约束的有效性。此外,在小邻域上计算出的局部约束还没有完全利用场景的几何结构信息,但而这些信息可能能够提高性能。
为了解决这些问题,从全局角度提出一个更稳定的几何约束,考虑了大范围内的几何关系,称为虚拟法线。
具体做法,在重建的点云中,随机采样3个距离较远的,并且不共线的点,这3个点可以形成一个虚拟平面(不要去深究这个虚拟平面的物理意义实际上它可能不具有任何的物理意义),这个平面的法线向量即为虚拟法线(VN)。gt和预测的虚拟法向量之间的差异就可以作为高阶的3D几何损失.由于该方法是对点云进行的远距离采样,与在局部尺寸的表面法线相比,噪声的影响大大降低,从而计算得到的虚拟法向量会更加精确。
论文:Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction,W. Yin, Y. Liu, C. Shen. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
单眼深度预测在理解三维场景几何过程中起着至关重要的作用。虽然最近的方法在 pixel-wise 相对误差等评价指标方面取得了令人印象深刻的进展,但大多数方法忽略了三维空间中的几何约束。在这项工作中,我们展示了高阶三维几何约束对深度预测的重要性。通过设计一个具有简单几何约束的损失项,即由重建的三维空间中随机采样的三个点确定的虚法线方向,我们显著提高了单眼深度估计的精度和鲁棒性。
重要的是,虚拟法线损失不仅可以提高学习绝对深度的性能,还可以解出 Scale 信息,以更好的形状信息丰富模型。因此,当无法获得绝对深度训练数据时,我们可以使用虚拟法线来学习在不同场景上生成的鲁棒仿射不变深度(affine-invariant depth)。在NYU Depth-V2和KITTI上,我们的实验是学习绝对深度效果最好的。从高质量的预测深度中,我们现在能够直接恢复出良好的三维场景结构,如点云和表面法线,从而消除了依赖额外模型的必要性。为了证明在虚拟法线损失的不同数据上学习仿射不变深度的优秀泛化能力,我们构建了一个大规模的、多样化的训练仿射不变深度数据集,称为 Diverse Scene Depth dataset (DiverseDepth),并在5个 the zero-shot test setting 的数据集上进行了测试。
surface normal Vs virtual normal
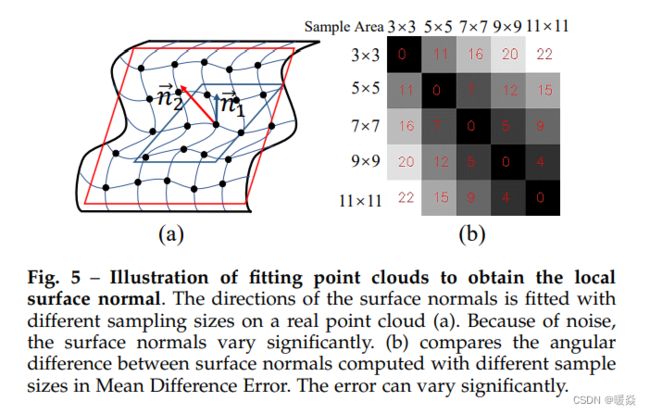
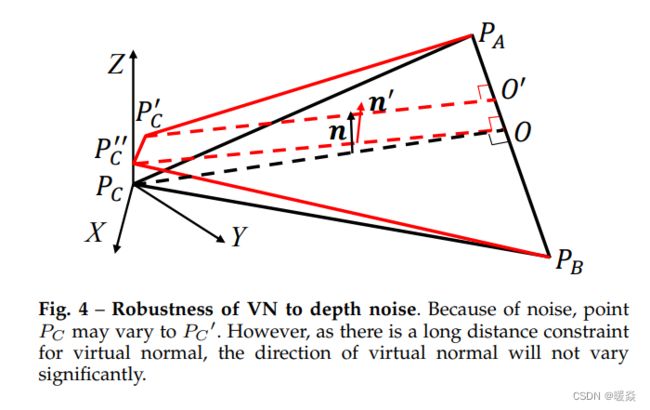
如图 14 所示,suface normal 只是 fit 一个非常 local 的平面,稍微的扰动就会对法线方向造成的误差比较大,法线方向会对像素的 depth 值的噪声比较敏感。
如图 15 所示,引入 virtual normal 概念,任意取的三个点可以距离很远,构成的平面并不是 local 的平面,稍微的扰动对法线方向造成的误差比较小,法线方向对像素的 depth 值的噪声不太敏感。
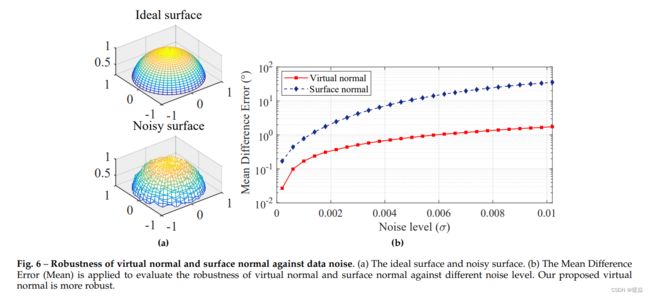
如图 16 所示,应用平均差分误差(平均误差)来评估 virtual normal 和 suface normal 对不同噪声水平的鲁棒性。可以看出 virtual normal 更稳健。
3D Shape / Geometry Information 与相机参数无关,相机参数的变化并不会造成 3D 场景形状的改变,所以相机参数的变化也不会影响到 virtual normal 的计算。
当然,给定一对点,哪个点在前哪个点在后,这样的 ranking loss 也可以用上,虽然 ranking loss 比较弱,但如果有大量这样的数据,使用 ranking loss 也会有一定的帮助。
如果数据集是 metirc depth 的 Affine transformation(Y=Ax+b)之后的 relative depth 情况下,也可以使用 affine-invariant loss , affine-invariant loss function 与 A和b 无关。
19年有一篇论文提出了scale and shift invariant loss (SSIL) ,论文说明了affine-invariant如何实现。
论文:Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. Katrin Lasinger, Rene Ranftl, Konrad Schindler, and Vladlen Koltun. abs/1907.01341,2019.
论文精读:Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. - MengYa_Dream - CSDN
DCNN模型在不同尺度数据集上学习仿射不变深度,确保模型高泛化能力和高质量的场景几何形状。
论文:DiverseDepth: Affine-invariant Depth Prediction Using Diverse Data, Wei Yin, Xinlong Wang, Chunhua Shen, Yifan Liu, Zhi Tian, Songcen Xu, Changming Sun, Dou Renyin, Computer Vision and Pattern Recognition (cs.CV) 2020

使用 relative depth 训练时,可以使用多种 loss,virtual normal loss,affine-invariant loss,ranking loss,使用 metric depth 训练时,可以使用 L1 regression loss。

Scale 一致性问题
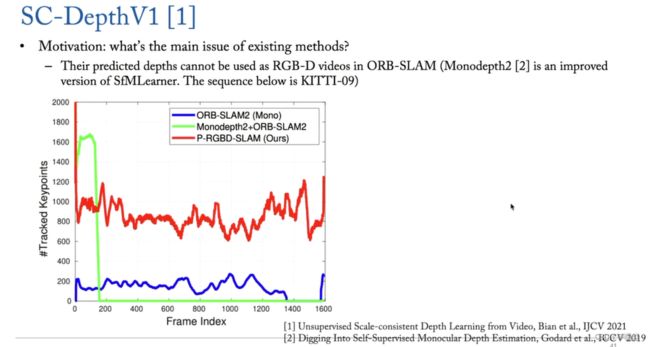
因为单目深度估计中输入只有一张图片,单张图片没有 scale 信息,所以使用没有标签的 video 数据训练 depth estimation模型预测到的 depth 在 SLAM 任务中没有任何用途。
如果单目深度估计模型输出的 depth 在 video 的时间轴上面 scale 是一致的,该 depth 在 SLAM 任务中才有用。例如:ORB-SLAM 任务中,输入为 RGB 或者 RGB + depth ,如果有 Scale-consistence depth ,SLAM 的输出才会更加准确。
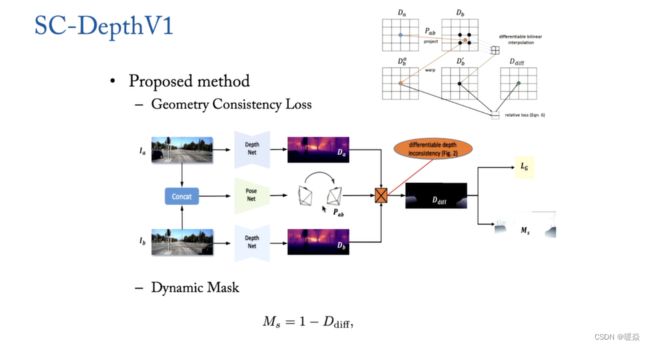
如何保证 Scale 一致性?- 解决方案:SC-DepthV1 (Geometry Consistency Loss)
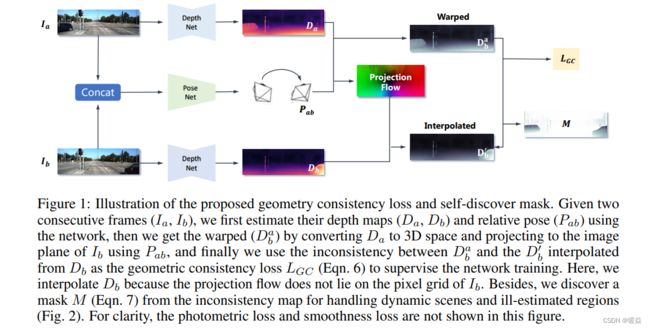
因为输入数据是video,没有 depth 信息,所以需要估计出 camera pose,两帧之间做一次Wrapping得到点与点之间的对应关系,进而计算出 photo metric loss。如果 scale 是一致的,那么 wrapping 之后对应的点的 depth 应该是一模一样的。如果video中有移动的目标,不能将这些移动的目标考虑进去。
本文提出了几何一致性损失Geometry Consistency Loss 用于尺度一致性约束。提出用 self-discover mask M 解决移动物体和遮挡。
给定两个连续的帧 ( I a , I b ) (I_a,I_b) (Ia,Ib),首先使用网络估计他们的深度地图 ( D a , D b ) (D_a,D_b) (Da,Db)和相对姿态 ( P a b ) (P_{ab}) (Pab),然后我们通过转换 D a D_a Da到3D空间得到 warped ( D b a ) (D_b^a) (Dba),并且使用 ( P a b ) (P_{ab}) (Pab)投影到 I b I_b Ib的图像平面,最后我们使用 ( D b a ) (D_b^a) (Dba)和从 ( D b ) (D_b) (Db)插值得到的 ( D b ′ ) (D_b^{'}) (Db′)之间的不一致性作为 geometric consistency loss LGC 监督网络的训练。
提出 SC-DepthV1(Geometry Consistency Loss + Self-Discovered Mask)的论文:Unsupervised scale-consistent depth and ego-motion learning from monocular video,J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M. Cheng, I. Reid. Proc. Advances in Neural Information Processing Systems (NeurIPS’19), 2019.
论文精读1:关于该论文的精读笔记 - kebijuelun - CSDN
论文精读2:关于该论文的精读笔记 - skycrygg - CSDN

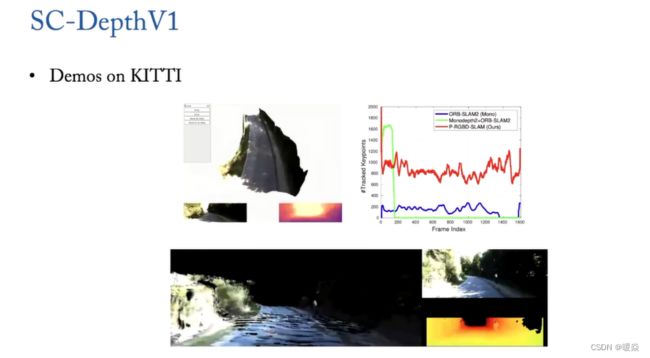
以下图片展示 SC-DepthV1 效果。

SC-DepthV2 针对室内 video 对 SC-DepthV1 的改进
SC-DepthV1 只对室外 video 有用,在室内 video 上效果很差,因为很多室内 video 只有 rotation 没有translation,在 SLAM 任务中,如果只有 rotation ,SLAM 任务就会退化为一个退化(degenerated)的 case,这种情况下是优化不好的,所以要对 rotation 运动数据进行处理。

针对 rotation 数据的处理,沈春华老师团队提出了两种方案,方案一:直接对训练数据进行预处理;方案二:在网络中设计专门的模块处理 rotation 数据。
论文认为,虽然低纹理等因素会使得算法更难在室内场景训练,但是复杂的相机运动才是更关键的原因。比如,在自动驾驶场景中相机一般被固定在车上稳定前行,而在室内VR/AR场景中相机会随着人(或手)无规律运动。基于这一假设,论文方法如下:
首先,对相机运动与深度估计的联系作出理论分析;
然后,提出数据预处理的方法进行实验验证;
最后,提出自校准网络实现可以端到端训练的无监督深度估计算法。
提出 SC-DepthV2(分析相机运动与深度估计的关系 + 提出 Auto-Rectify Network)的论文:Auto-rectify network for unsupervised indoor depth estimation,J. Bian, H. Zhan, N. Wang, T. Chin, C. Shen, I. Reid. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
参考:TPAMI|用于室内无监督深度估计的自校准网络(SC-DepthV2)


以下图片展示 SC-DepthV2 输入单张图片,三维重建出的效果。

如何解决单目深度估计中小目标被忽略问题?- 解决方案:Anctor Points
输入一段视频,输出三维重建场景。一种方法是使用传统的 SfM ,但是因为 SfM 中点是稀疏的,所以 SfM 只能得到 Sparse 3D Reconstruction 或 Semi-Dense 3D Reconstruction ,得不到稠密重建(Dense 3D reconstruction)。
为什么在SFM中不能得到密集点云?
因为,SFM中用来做重建的点是由特征匹配提供的!这些匹配点天生不密集!而使用计算机来进行三维点云重建,必须认识到,点云的密集程度是由人为进行编程进行获取的。SFM获得点的方式决定了它不可能直接生成密集点云。
运动重构(SFM与MVS的区别)学习笔记三
在某些场景中进行单目深度估计时小目标可能会被忽视。针对这个问题,沈春华老师团队提出了一种方案,首先输入视频进行 ORB-SLAM 得到稀疏的点的 depth estimation 或者 点云的重建,将 SLAM 得到的点中可以作为 ground-truth 的很准确的点称为 Anctor Points ,利用 Anctor Points 校准单目深度估计的输出,会得到比较准确的 depth maps 或 三维点云。
提出 利用 Anctor Points 校准单目深度估计的输出 论文:Towards 3D Scene Reconstruction from Locally Scale-Aligned Monocular Video Depth. Guangkai Xu, Wei Yin, Hao Chen, Kai Cheng, Feng Zhao, Chunhua Shen. Computer Vision and Pattern Recognition (cs.CV)

Q&A
NeRF与您研究方向的相关性及其前景探讨
ECCV2020第一篇NeRF,NeRF是 overfit 一个场景,没有 generalization capability ,不能 generalize 到另一个场景,每个场景都要训练一个对应的模型。沈春华老师团队的目标是训练处拥有 generalization capability 的模型。2020年NeRF论文发表后,有很多研究在做如何使得NeRF拥有 generalization capability ,这是一个很有前景的方向。
构建数据集时depth数据是如何得到的?
NYU室内数据集是用微软的 Kinect 相机,Kinect 一代相机是 rgb 的相机 + 结构光,Kinect 一代相机是 rgb 的相机 + Timeof flight,同时采集同一个场景之后对点与点之间进行校准,每个点都有 metric depth ,能知道该像素与相机的距离。
激光雷达测距则采用TOF 技术(Timeof flight,飞行时间),它通过记录光源投射到每个像 素点的光线发射与反射间的相位变化来计算光线飞行时间,进而计算光源到每个像素点的距离。
同样的,Kitti 数据集也是用 laser scanner 得到的。
NYU 数据集 和 Kitti 数据集 的采集方式是最标准的做法,但是采集的代价很大。
针对 metic depth 采集代价很大的问题,沈春华老师团队提出 relative depth 的方案,具体方案如下:
方案一:双目图,虽然不知道相机参数,但是可得到左图和右图点之间的匹配关系后计算出 affine transform depth maps。
方案二:视频,估计出相机的pose,可以得到跟双目一样的 affine transform depth maps。
可以直接用双目图片或者直接用视频来训练单目深度估计的模型,相当于把相机参数和双目图片点与点间匹配关系一起放在网络里面训练,几年前就有一些论文在做这个事情。
自监督是否可以做单目深度估计?
可以,例如最近的何凯明MAE自监督或微软MIM自监督,用 ImageNet 无标签数据训练一个MAE或者MIM自监督模型作为初始,在NYU或者KITTI数据集上 fine-tune,结果有所提升,但这只能作为初始,还是需要少量的训练数据。
在video上无监督单目深度估计和双目深度估计方向的研究都有团队在做。
自监督对比全监督差异多大?
目前来看,在训练集大小相差不大的情况下,全监督效果较好。
MVSNet与模型泛化研究有关联吗?
MVSNet 目标是预测图片上每个像素的深度信息。没有讨论模型泛化能力。
MVSNet: Depth Inference for Unstructured Multi-view Stereo
MVSNet 本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
过程:
1 输入一张reference image(为主) 和几张source images(辅助);
2 分别用网络提取出下采样四分之一的32通道的特征图;
3 采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换(homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
4 利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
5 利用多张图片之间的重建约束(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。
参考:基于深度学习的三维重建算法:MVSNet、RMVSNet、PointMVSNet、Cascade系列 - 闵称的文章 - 知乎
6d pose 与单目深度估计相关性?
**6d pose 针对目标(object)**不是针对场景,沈春华老师团队到目前为止的模型做不到 object level,针对 object level做出的三维点云很不准确,只能做到三维场景重建(3d scene reconstruction),针对 object level 只考虑训练数据还不够,还需要考虑其他因素。