大数据应用技术(Spark)中级
一、Spark MLib
1、常见的机器学习流程

2、机器学习的分类

sklearn是机器学习中最常见的一个第三方模块,里边封装了大量特征处理的方法。
3、监督学习的分类

常见的分类算法: 朴素贝叶斯模型、K近邻、支持向量机、决策树、逻辑回归(二分类问题)。
常见的回归算法:线性回归、逻辑回归、岭回归、Lasso。

4、无监督学习

常见的聚类算法:K-Means(K均值)聚类、MeanShift、层次聚类。

常见的关联学习规则算法:Apriori、FP-Tree、Eclat算法、灰色关联法。

5、Spark MLlib简介
MLlib是Apache Spark可扩展的机器学习库。
Spark 机器学习库从1.2 版本以后被分为两个包:spark.mllib 包含基于RDD的原始算法API。Spark MLlib 历史比较长,提供的算法实现都是基于原始的 RDD。
spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件。
从 Spark 2.0 开始,RDD-based API 已经进入维护模式,不再增加新的功能,并可能在 Spark 3.0 中移除。
6、ML——基于DataFrame的API库
ML API包含三个主要的抽象类:Transformer(转换器),Estimator(预测器)和Pipline(管道)。
转换器是一种算法,可以将一个DataFrame转换成另一个DataFrame。

例:一个特征变换器是输入一个DataFrame,读取一列(比如 text),将其映射成一个新列(比如,特征向量),然后输出一个新的包含这个映射列的DataFrame
预测器是一种算法,可以基于DataFrame产生一个转换器,是学习算法或者其他算法的抽象,用来训练数据。

例:一个机器学习算法是一个Estimator模型学习器,比如这个算法是LogisticRegression,调用fit()方法训练出一个LogisticRegressionModel,是一个Model,也是一个Transformer。
管道链接多个转换器和预测器生成一个机器学习工作流。管道被指定为一系列阶段,每个阶段是一个转换器或一个预测器。

上一步骤得到一个文档的模型,用测试数据经过相应处理变成特征向量后输入到模型中,通过预测的准确率来评估一个模型。
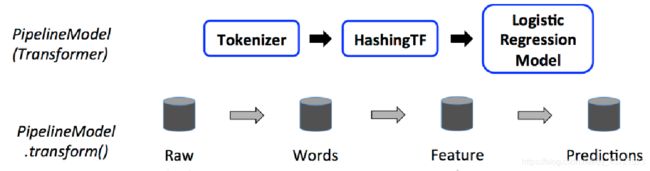
7、案例:基于逻辑回归算法的机器学习
# 1.训练数据集(含标签)
training = spark.createDataFrame([
(0, "a b c d e spark", 1.0),
(1, "b d", 0.0),
(2, "spark f g h", 1.0),
(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])
# 2.配置一个pipeline管道,包括转换器和评估器
from pyspark.ml.feature import Tokenizer
from pyspark.ml.feature import HashingTF
from pyspark.ml.classification import LogisticRegression
from pyspark.ml import Pipeline
tokenizer = Tokenizer(inputCol="text", outputCol="words") #分词
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") #hash分桶及词频率统计
lr = LogisticRegression(maxIter=10, regParam=0.001) #逻辑回归算法
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
# 3.用管道训练出模型
model = pipeline.fit(training)
# 4.测试数据(不含label标签)
test = spark.createDataFrame([
(4, "spark i j k"),
(5, "l m n"),
(6, "spark hadoop spark"),
(7, "apache hadoop")
], ["id", "text"])
# 5.用测试数据来预测
prediction = model.transform(test)
# 6.打印出感兴趣的列
selected = prediction.select("id", "text", "prediction")
for row in selected.collect():
rid, text, prediction = row
print("(%d, %s) --> prediction=%f" % (rid, text, prediction))
运行结果:

二、图计算 GraphX
1、图的定义
图(Graph)是由顶点的非空有限集和边的有限集构成的,记作G=
度(degree):对于无向图,顶点的度是指邻接于该顶点的边的总和
出度(out-degree): 以顶点v为起点的有向边数目
入度(in-degree): 以顶点v为终点的有向边数目

2、Spark GraphX
Spark平台下,面向大规模图计算的组件,通过引入属性图,构建图计算基础模型。使用RDD来存储图数据,并提供了实用的图操作方法。由于RDD的与生俱来的特性,GraphX高效地实现了图的分布式存储和处理,可以应用于社交网络等大规模的图计算场景。
目前Spark GraphX支持Scala和JavaAPI,还不支持PythonAPI。
3、GraphFrames库
4、GraphFrames介绍
GraphFrame 是GraphFrames API的核心抽象编程模型,是图的抽象,逻辑上可看作两部分:顶点DataFrame和边DataFrame。
- 顶点DataFrame必须包含列名“id”,作为顶点的唯一标识。
- 边DataFrame必须包含列名为“src”和“dst”,用来保存头和尾的唯一标识id。
我们通过以下例子来进行GraphFrames编程。
顶点:

边:
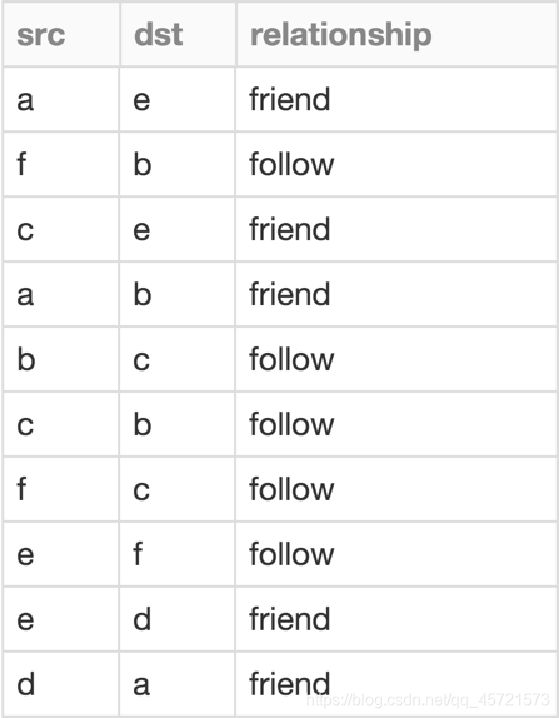

创建顶点DataFrame
v = sqlContext.createDataFrame([
(“a”, “Alice”, 34),
(“b”, “Bob”, 36),
(“c”, “Charlie”, 30),
(“d”, “David”, 29),
(“e”, “Esther”, 32),
(“f”, “Fanny”, 36)
], [“id”, “name”, “age”])
创建边DataFrame
e = sqlContext.createDataFrame([
(“a”, “e”, “friend”),
(“f”, “b”, “follow”),
(“c”, “e”, “friend”),
(“a”, “b”, “friend”),
(“b”, “c”, “follow”),
(“c”, “b”, “follow”),
(“f”, “c”, “follow”),
(“e”, “f”, “follow”),
(“e”, “d”, “friend”),
(“d”, “a”, “friend”)
], [“src”, “dst”, “relationship”])
根据顶点DataFrame和边DataFrame, 创建GraphFrame对象
from graphframes import GraphFrame
g = GraphFrame(v,e)
### 5、GraphFrames基本操作
GraphFrame提供四种视图:顶点表视图、边表视图、三元组(Triplet)视图以及模式(Pattern)视图。四个视图返回类型都是DataFrame。
* 顶点表视图
```python
>>> g.vertices.show()
+---+-------+---+
| id| name|age|
+---+-------+---+
| a| Alice| 34|
| b| Bob| 36|
| c|Charlie| 30|
| d| David| 29|
| e| Esther| 32|
| f| Fanny| 36|
+---+-------+---+
-
边表视图
>>> g.edges.show() +---+---+------------+ |src|dst|relationship| +---+---+------------+ | a| e| friend| | f| b| follow| | c| e| friend| | a| b| friend| | b| c| follow| | c| b| follow| | f| c| follow| | e| f| follow| | e| d| friend| | d| a| friend| +---+---+------------+ -
三元组视图
>>> g.triplets.show()
+--------------+------------+--------------+
| src| edge| dst|
+--------------+------------+--------------+
| [e,Esther,32]|[e,f,follow]| [f,Fanny,36]|
|[c,Charlie,30]|[c,e,friend]| [e,Esther,32]|
| [a,Alice,34]|[a,e,friend]| [e,Esther,32]|
| [e,Esther,32]|[e,d,friend]| [d,David,29]|
| [f,Fanny,36]|[f,c,follow]|[c,Charlie,30]|
| [b,Bob,36]|[b,c,follow]|[c,Charlie,30]|
| [f,Fanny,36]|[f,b,follow]| [b,Bob,36]|
|[c,Charlie,30]|[c,b,follow]| [b,Bob,36]|
| [a,Alice,34]|[a,b,friend]| [b,Bob,36]|
| [d,David,29]|[d,a,friend]| [a,Alice,34]|
+--------------+------------+--------------+
-
模式视图
-
采用形如“(m)-[e]->(n)”的模式描述有向边
-
模式中有多条边时,需要用分号(“;”)拼接
>>> motifs = g.find("(m)-[e]->(n); (n)-[e2]->(m)") >>> motifs.show() +----------------+--------------+----------------+--------------+ | m| e| n| e2| +----------------+--------------+----------------+--------------+ |[c, Charlie, 30]|[c, b, follow]| [b, Bob, 36]|[b, c, follow]| | [b, Bob, 36]|[b, c, follow]|[c, Charlie, 30]|[c, b, follow]| +----------------+--------------+----------------+--------------+>>> motifs = g.find("(m)-[e]->(n); (n)-[e2]->(k)") >>> motifs.show() +----------------+--------------+----------------+--------------+----------------+ | m| e| n| e2| k| +----------------+--------------+----------------+--------------+----------------+ |[c, Charlie, 30]|[c, e, friend]| [e, Esther, 32]|[e, f, follow]| [f, Fanny, 36]| | [a, Alice, 34]|[a, e, friend]| [e, Esther, 32]|[e, f, follow]| [f, Fanny, 36]| | [f, Fanny, 36]|[f, c, follow]|[c, Charlie, 30]|[c, e, friend]| [e, Esther, 32]| | [b, Bob, 36]|[b, c, follow]|[c, Charlie, 30]|[c, e, friend]| [e, Esther, 32]| ....... +----------------+--------------+----------------+--------------+----------------+
-
-
基本操作—顶点的度
>>> g.degrees.show() +---+------+ | id|degree| +---+------+ | f| 3| | e| 4| | d| 2| | c| 4| | b| 4| | a| 3| +---+------+ -
基本操作—入度
>>> g.inDegrees.show() +---+--------+ | id|inDegree| +---+--------+ | f| 1| | e| 2| | d| 1| | c| 2| | b| 3| | a| 1| +---+--------+ -
基本操作—出度
>>> g.outDegrees.show() +---+---------+ | id|outDegree| +---+---------+ | f| 2| | e| 2| | d| 1| | c| 2| | b| 1| | a| 2| +---+---------+ -
基本操作—图保存
>>> g.vertices.write.parquet("/home/test/vertices") >>> g.edges.write.parquet("/home/test/edges") -
基本操作—图加载
>>> v = spark.read.parquet("/home/test/vertices") >>> e = spark.read.parquet("/home/test/edges") >>> newGraph=GraphFrame(v, e)
6、GraphFrames实现的算法
-
广度优先搜索
bfs(fromExpr, toExpr, edgeFilter=None, maxPathLength=10)
参数:fromExpr表示Spark SQL表达式,指定搜索起点
toExpr表示Spark SQL表达式,指定搜索终点
edgeFilter指定搜索过程需要忽略的边,也是Spark SQL表达式
maxPathLength表示路径的最大长度,若搜索结果路径长度超过该值,则算法终止
>>> paths = g.bfs("id = 'a' ","id = 'f' ") >>> paths.show() +--------------+--------------+---------------+--------------+--------------+ | from| e0| v1| e1| to| +--------------+--------------+---------------+--------------+--------------+ |[a, Alice, 34]|[a, e, friend]|[e, Esther, 32]|[e, f, follow]|[f, Fanny, 36]| +--------------+--------------+---------------+--------------+--------------+ -
最短路径
最短路径算法计算图中的每一个顶点到目标顶点的最短距离
shortestPaths(landmarks)
参数:landmarks表示要计算的目标顶点集
注意:该方法返回的是所有点到目标顶点集的最短路径,返回结果只是距离值,并不会返回完整的路径。
>>>results = g.shortestPaths(landmarks=["a", "d"]) >>>results.show() +---+-------+---+----------------+ | id| name|age| distances| +---+-------+---+----------------+ | b| Bob| 36|[d -> 3, a -> 4]| | e| Esther| 32|[d -> 1, a -> 2]| | a| Alice| 34|[a -> 0, d -> 2]| | f| Fanny| 36|[d -> 3, a -> 4]| | d| David| 29|[d -> 0, a -> 1]| | c|Charlie| 30|[d -> 2, a -> 3]| +---+-------+---+----------------+ -
PageRank算法
-
算法来源
最早的搜索引擎采用的是分类目录的方法,即通过人工进行网页分类并整理出高质量的网站。那时Yahoo 和国内的hao123就是使用的这种方法。
后来网页越来越多,人工分类已经不现实了。搜索引擎进入了文本检索的时代,即计算用户查询关键词与网页内容的相关程度来返回搜索结果。这种方法突破了数量的限制,但是搜索结果不是很好。因为总有某些网页来回地倒腾某些关键词使自己的搜索排名靠前。
谷歌的两位创始人,当时还是美国斯坦福大学 (Stanford University) 研究生的拉里·佩奇(Larry Page) 和谢尔盖·布林 (Sergey Brin) 开始了对网页排序问题的研究。他们的借鉴了学术界评判学术论文重要性的通用方法,那就是看论文的引用次数。由此想到网页的重要性也可以根据这种方法来评价。于是PageRank的核心思想就诞生了,非常简单:
(1)如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高。(2)如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
-
算法原理
假设一个由4个网页组成的群体:A,B,C和D。如果所有页面都只链接至A,那么A的PR(PageRank)值将是B,C及D的Pagerank总和。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LU778LOu-1622810063598)(pic\1597211419307.png)]
重新假设B链接到A和C,C只链接到A,并且D链接到全部其他的3个页面。因而B会给A和C每个页面半票,D投出的票只有三分之一算到了A的PageRank上。

对于一个页面A,那么它的PR值为:

(1)PR(A) 是页面A的PR值。
(2)PR(Ti)是页面Ti的PR值,在这里,页面Ti是指向A的所有页面中的某个页面。
(3)C(Ti)是页面Ti的出度,也就是Ti指向其他页面的边的个数。
(4)d为阻尼系数,其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。该数值是根据上网者使用浏览器书签的平均频率估算而得,通常d=0.85。
-
算法实例—基于 GraphFrames 的网页排名
#定义文件路径变量 filePath,其值为 web-Google 数据集路径 filePath="/home/test/web-Google.txt" #定义文件的模式(schema),后加载数据集创建边 DataFrame from pyspark.sql.types import * schema=StructType([StructField("src",LongType(),True) ,StructField("dst",LongType(),True)]) edgesDF = spark.read.load(filePath,format='csv',schema=schema,delimiter='\t',mode='DROPMALFORMED') edgesDF.cache() #分别取出‘src’和‘dst’列,去重后合并为一个 DataFrames srcDF=edgesDF.select(edgesDF.src).distinct() distDF=edgesDF.select(edgesDF.dst).distinct() verticesDF=srcDF.union(distDF).distinct().withColumnRenamed('src','id') verticesDF.cache() #两个 DataFrame 准备好之后,可以使用GraphFrame 命令创建一个 GraphFrame from graphframes import GraphFrame graph = GraphFrame(verticesDF,edgesDF) #使用 PageRank 算法进行网页排名 ranks = graph.pageRank(resetProbability=0.15, maxIter=5) #展示效果 ranks.vertices.select("id","pagerank").show(5) +------+------------------+ | id| pagerank| +------+------------------+ | 0|0.9443297702668855| |552600|0.9507998487484948| |904600|0.8124074386753581| | 1|0.8449414153303386| |247201|0.7162841433044718| +------+------------------+ #查看每个页面所占的比重 ranks.edges.select("src","dst","weight").show(5) +-----+------+-------------------+ | src| dst| weight| +-----+------+-------------------+ | 0| 11342| 0.25| | 0|824020| 0.25| | 0|867923| 0.25| | 0|891835| 0.25| | 1| 53051| 0.1| +-----+------+-------------------+
-
-
三角形计数算法
用于确定通过图数据集中每个顶点的三角形数量。当计算三角形个数时,图都被作为无向图处理,平行边仅计算一次,自环则会被忽略;
API:triangleCount()
-
标签传播算法
最早是针对社区发现问题时提出的一种解决方案。社区是一个模糊的概念,一般来说,社区是指一个子图,其内部顶点间连接紧密,而与其他社区之间连接稀疏, 根据各社区顶点有无交集, 又可分为非重叠型社区(disjoint communities)和重叠型社区(overlapping communities);
API:labelPropagation(maxIter)
-
最短路径
计算图中的每一个顶点到目标顶点的最短距离
API:shortestPaths(landmarks)
-
广度优先搜索
最常用的图搜索算法之一
API:bfs(fromExpr, toExpr, edgeFilter=None, maxPathLength=10)
-
连通分量
可用于发现网络中环,经常用于社交网络,发现社交圈子,算法使用顶点 ID 标注图中每个连通体,将连通体中序号最小的顶点的 ID 作为连通体的 ID。
API:.connectedComponents()
三、补充
1、数据预处理的任务包括去除重复数据、处理缺失值、处理离群值和敏感数据的转换等。
2、准备数据任务主要包括数据的采集、数据预处理和数据探索。
3、梯度是一个向量,有方向有大小,求梯度就是对梯度向量的各个元素求偏导t
4、算法复杂度主要包括时间复杂度和空间复杂度
5、线性回归能完成的任务是预测连续值
6、辅导视频重点看7.1,7.2,8.1, 8.2