Machine Learning and AI has continued to be a growing and expanding field of interest and work for several years. It has continued to gain a lot of attention and has seen an influx of many undergraduates / working professionals to join and explore. So, if you are a beginner and need help with Decision Trees and their family of Ensemble methods, this story is for you.
多年来,机器学习和AI一直是一个不断增长和扩展的兴趣和工作领域。 它继续引起了很多关注,并且吸引了许多大学生/在职专业人员的加入和探索。 因此,如果您是初学者,并且需要决策树及其Ensemble方法系列的帮助,那么本故事适合您。
介绍 : (Introduction :)
The aim is to correctly classify the types of Glass, based on the number of elements (like Ca, Mg, etc.) they contain and their Refractive Index.
目的是根据玻璃中所含元素的数量(例如Ca,Mg等)及其折射率正确分类玻璃。
As you can see above, we have 214 rows and 10 columns. The first nine columns are the Features / Independent Variable. And the last column ‘Type’ is our target variable and describe what is the kind (class) of the glass
如您在上面看到的,我们有214行和10列。 前九列是功能/自变量。 最后一列“类型”是我们的目标变量 ,它描述了什么是玻璃的种类( 类 )
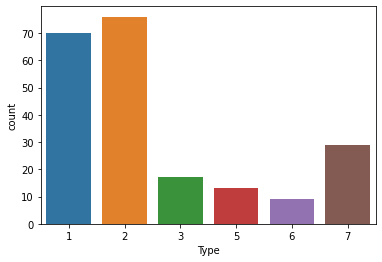
We have six classes in our Data-set. Also, it can be seen that there is a high class-imbalance, i.e. the number of examples we have isn’t the same. This could lead to some loss in accuracy for our model, as our model might be biased towards one class.
我们的数据集中有六个类。 此外,可以看出存在很高的类不平衡 ,即我们拥有的示例数不相同。 这可能会导致我们模型的准确性有所下降,因为我们的模型可能偏向一个类别。
In cases where we have more than two classes, it is better to use a Classifier that has a non-linear decision boundary so that we can have more accurate predictions. Some examples of Non-Linear Classification Algorithms are Kernelised — Support Vector Machines, Decision Trees, and even a Logistic Regression model with Polynomial Features.
如果我们有两个以上的类,则最好使用具有非线性决策边界的分类器,以便我们可以进行更准确的预测。 非线性分类算法的一些示例已内核化-支持向量机,决策树,甚至是具有多项式特征的Logistic回归模型。
After some data-preprocessing and train-test split, we will be creating our Models. We will be using the same training and test set for each of the models.
经过一些数据预处理和火车测试拆分后,我们将创建模型。 我们将对每个模型使用相同的训练和测试集。
第一部分:决策树 (Part I: Decision Trees)
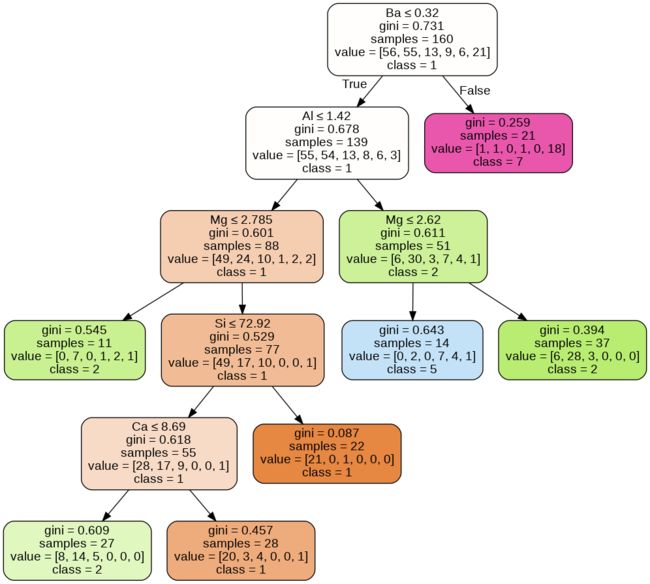
Decision Trees, as mentioned in the CS-229 class is a greedy, top-down, and recursive partitioning algorithm. Its advantages are — Non-linearity, support for Categorical Variables, and high interpretability.
如CS-229类别中所述,决策树是一种贪婪,自上而下和递归的分区算法。 它的优点是-非线性,支持分类变量和高解释性。
We use sci-kit-learn and create our model. The values of the parameters used were found after a comprehensive grid-search cross-validation.
我们使用sci-kit-learn并创建我们的模型。 经过全面的网格搜索交叉验证后,可以找到所用参数的值。

第二部分:随机森林 (Part II: Random Forest)
Random Forest is an example of Ensemble Learning.
随机森林就是合奏学习的一个例子。
Ensemble Learning as described by the SuperDataScience Team is when you take multiple Machine Learning Algorithms and put them together to create a bigger algorithm in such a way that the algorithm created is using & leveraging from the ones used to create it. In the case of Random Forest many Decision Trees are used.
SuperDataScience团队描述的集成学习是指您采用多种机器学习算法并将它们放在一起以创建更大的算法时,所创建的算法会利用和利用创建算法的方式。 在随机森林的情况下,使用许多决策树。
This is how a Random Forest works :
这是随机森林的工作方式:
STEP 1: Pick at random ’N’ data points from the training set
步骤1 :从训练集中随机选取“ N”个数据点
STEP 2: Build Decision Trees associated with those ’N’ data points.
步骤2 :建立与那些“ N”个数据点相关的决策树。
STEP 3: Choose the number of trees you want to build and repeat steps 1&2.
步骤3 :选择您要构建的树木数量,然后重复步骤1&2。
STEP 4: For a new data point, make each one of the trees predict the category which the data points belong to and assign the new data point to the category that wins the majority vote.
步骤4 :对于一个新的数据点,使每个树都预测该数据点所属的类别,然后将新数据点分配给赢得多数票的类别。

We use Scikit-Learn to create our Random Forest Model. The values of the parameters applied were found after a comprehensive grid search cross-validation, to boost accuracy.
我们使用Scikit-Learn创建我们的随机森林模型。 经过全面的网格搜索交叉验证后,可以找到应用的参数值,以提高准确性。

As you can see, the Random Forest has a score of 81.5% as compared to Decision Tree’s score of 72.2%. This improvement in Accuracy is a result of several aspects such as bootstrap aggregation and since only a subset of features is to be used at each split, this helps decrease correlation and reduce over-fitting.
如您所见,“随机森林”的得分为81.5%,而决策树的得分为72.2%。 准确性的提高是自举聚合等多个方面的结果,并且由于每次拆分仅使用要素的子集,因此有助于减少相关性并减少过度拟合。
Also, Random Forests helps with missing values.
此外,“随机森林”有助于减少值。
第三部分:XGBoost (Part III: XGBoost)
XGBoost stands for Extreme Gradient Boosting and is another example of Ensemble Learning. We take the derivative of loss & perform gradient descent. As told in the CS-229 class, in Gradient Boosting we compute the gradient at each training point w.r.t the current predictor.
XGBoost代表极限梯度增强,是Ensemble Learning的另一个示例。 我们采用损失的导数并执行梯度下降。 至于说在CS-229级,梯度推进,我们计算在每个培训点WRT当前预测的梯度。
In the case of Boosting, we make Decision Trees into weak learners by allowing each tree to only make one decision before making a prediction, this is called a Decision Stump.
在Boosting的情况下,我们允许决策树在做出预测之前只做出一个决策,从而使决策树成为弱学习者,这称为决策树桩 。
This is how Boosting works:-
这是Boosting的工作方式:-
STEP 1: Start with a data-set and allow only one decision stump to be trained.
步骤1 :从数据集开始,只允许训练一个决策树桩。
STEP 2: Track which examples the classifier got wrong and increase their relative weight compared to correctly classified examples
第2步 :与正确分类的示例相比,跟踪分类器出错的示例并增加其相对权重
STEP 3: Train a new decision stump which will be more incentivized to correctly classify these ‘hard negatives’, we then repeat these steps.
步骤3 :训练一个新的决策树桩,该树桩将被激励以正确地对这些“硬底片 ”进行分类,然后重复这些步骤。
There are two types of Boosting that can be applied to Decision Trees — AdaBoost and XGBoost.
可以将两种类型的Boosting应用于决策树-AdaBoost和XGBoost。

We use the XGBoost library. The values of the parameters applied were found after a comprehensive grid search cross-validation, to boost accuracy.
我们使用XGBoost库。 经过全面的网格搜索交叉验证后,可以找到应用的参数值,以提高准确性。

The XGBoost even outperformed the Random Forest and has a score of 83.34%. This happens as this is a summation of all weak learners, weighted by negative log-odds of error.
XGBoost甚至胜过了随机森林,得分为83.34%。 之所以发生这种情况,是因为这是所有弱学习者的总和,并由错误的对数负数加权。

第四部分:与神经网络的比较 (Part IV: Comparison with a Neural Network)
XGBoost and Random Forest are two of the most powerful classification algorithms. XGBoost has had a lot of buzz on Kaggle and is Data-Scientist’s favorite for classification problems. Although, a little computationally expensive they both make-up for it for the accuracy they have and run smoothly on GPU powered computers.
XGBoost和随机森林是最强大的两种分类算法。 XGBoost在Kaggle上引起了很多关注,是Data-Scientist在分类问题上的最爱。 尽管它们在计算上有点昂贵,但它们都弥补了它们的准确性,并且可以在GPU驱动的计算机上平稳运行。
I used a Neural Network, for this same data-set. I used Scikit-learn’s Multi-Layer Perceptron Classifier.
对于相同的数据集,我使用了神经网络。 我使用了Scikit-learn的多层感知器分类器。

You will notice that MLP underperformed in comparison to RandomForest and XGBoost. Even after having 50–100 nodes in its layers, and a time-taking grid search, we only had an accuracy of 77.78%. This could be because of two reasons — the small size of the data-set, and the high-class imbalance.
您会注意到,与RandomForest和XGBoost相比,MLP的表现不佳。 即使在其层中有50-100个节点并进行了耗时的网格搜索之后,我们的准确率也仅为77.78%。 这可能是由于两个原因-数据集的大小小和严重的不平衡。
结论: (Conclusion :)
Even in a small data-set with high-class imbalance, Random Forest and XGBoost were able to do well. If more parameter tuning is done, they might have even more accuracy.
即使在具有高级不平衡的小型数据集中,Random Forest和XGBoost仍然能够做到出色。 如果进行更多的参数调整,则它们可能具有更高的准确性。
As for the comparison between XGBoost and RandomForest, both of these work on different approaches. RandomForest works on Bagging & Aggregation and uses fully grown trees, while XGBoost works on Boosting and uses weak learners. RandomForest is faster and less computationally expensive, and also requires fewer parameters to tune.
至于XGBoost和RandomForest之间的比较,这两种方法都采用不同的方法。 RandomForest从事袋装和聚合,并使用完全生长的树木,而XGBoost从事Boosting,并使用弱者。 RandomForest更快,计算量更少,并且需要的参数也更少。
The Data-set and the code can be found here.
数据集和代码可在此处找到。
翻译自: https://medium.com/codepth/a-comparative-analysis-on-decision-trees-random-forest-and-xgboost-f74b8fb716c7