Faster R-CNN 整体流程介绍
Faster R-CNN整体流程
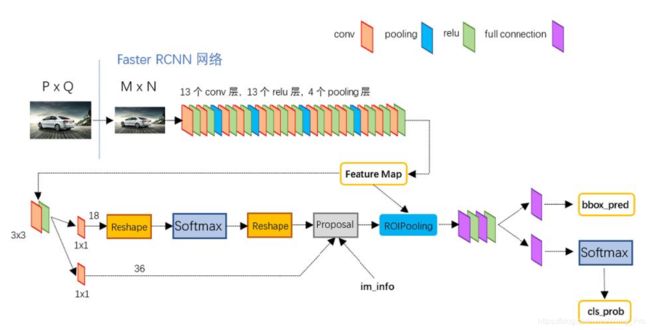
- 0.1 Faster R-CNN整体流程图
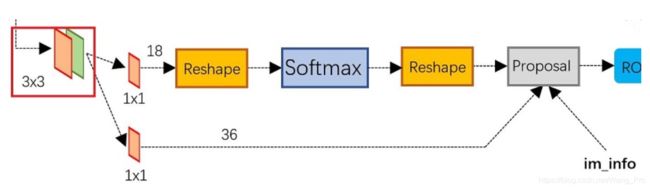
- 0.2 RPN层流程图
- 1 开始之前的关键词
-
-
- 1.1 分类与回归
- 1.2 进入RPN层之前的两个1x1卷积
- 1.3 Reshape layer
- 1.4 Softmax
- 1.5 Proposal layer
- 1.6 RoI Pooling
- 1.7 全连接层
- 1.8 激活函数
-
- 2 Faster R-CNN 大体流程
-
- 2.1 Conv Layers
- 2.2 RPN
- 2.3 RoI Pooling
- 2.4 Classification
- 3 总结
-
- 3.1 以Loss的角度观察Faster R-CNN
- 3.2 以anchor的角度观察Faster R-CNN
- 4 Faster RCNN 缺陷
-
- Faster RCNN 整数化过程
- 5 参考资料
0.1 Faster R-CNN整体流程图
0.2 RPN层流程图
1 开始之前的关键词
对于关键词,大可挑选自己不懂的地方看,并不需要全看所有的介绍。
1.1 分类与回归
分类是将检测出现的正样本进行归类的过程,而回归是在一张图片里预测出目标出现的具体位置,希望找到一种变换,将预测和真实的标定进行无限靠拢。
1.2 进入RPN层之前的两个1x1卷积

支路1: 1x1的卷积输出num_output=18,18的来源是feature map中,每一个点会生成9个anchor,对每个anchor进行positive与negative的判断,这些信息保存在9x2的矩阵内,所以输出为18,之后,softmax层将依照交并比(IoU),进行positive和negative的判断。

支路2: 1x1的卷积输出num_output=36,支路2是为proposal layer作准备,准备了9个anchor与4个对应的坐标信息,在proposal layer进行回归。
1.3 Reshape layer
Reshape layer 的作用是为了解决数据格式的问题,在softmax之间和之后都配备有了一个Reshape layer,解决了caffe先前的数据格式问题,并不是学习的重点内容。
1.4 Softmax
softmax的作用,softmax层可以将输入的数据映射为概率(0-1之间),保证之和为1;softmax层使用交叉熵作为损失函数,这样还有一个好处,就是在反向传播的过程中,只需要将正确分类的那一项概率值-1(具体的推导我参阅这篇博客https://blog.csdn.net/bitcarmanlee/article/details/82320853),就会得到了反向更新的梯度。
说了这么多,softmax在Faster R-CNN中出现了两次,第一次出现在RPN层中,进行anchor的P/N判断,第二次出现在classficaition中进行类别的判断。
在softmax 层里,可以使用交叉熵损失函数,也可以使用均方差损失函数,他们都可以达到良好效果。
1.5 Proposal layer
proposal layer 汇总了两条支路信息,
1)接收RPN层给出的建议框(P/N);
2)接收anchor的位置信息;
3)超参数im_info=[M,N,scale_factor],保存了图像的从开始到proposal layer的缩放信息,用来计算anchor的偏移量;
最后,proposal layer 负责综合P/N信息和对应的位置信息进行坐标回归(bounding box regression),获取精确的proposal。
1.6 RoI Pooling
RoI Pooling 层是出现在RPN层结束后,分类任务开始之前。
RoI Pooling层是为了解决Proposal layer 给出建议框大小不同的问题,将大小不同的建议框变成大小相同的特征图,之后进行分类。
下面会有更详细的解释。
1.7 全连接层
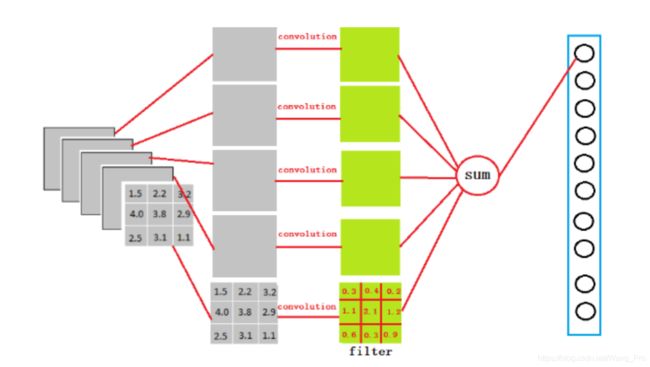
只看图,不说话,参考这一篇文章:https://zhuanlan.zhihu.com/p/33841176
结论就是:全连接层可以忽略空间结构特性,把众多的feature map整合为一个值,这个值大,则这个值经过softmax之后由获得很大概率的可能性要大得多。
全联接层对模型影响的三个参数:
1)全连接层的总层数
2)单个全连接层的神经元数
3)激活函数形式
1.8 激活函数
作用:增加模型的非线性表达能力,缓解梯度消失问题,将特征图映射到新的特征空间从而更加有利于训练。
内部定义:
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "conv5_3"
bottom: "rois"
top: "pool5"
roi_pooling_param {
pooled_w: 7 # 宽度被resize之后的大小
pooled_h: 7 # 高度被resize之后的大小
spatial_scale: 0.0625 # 1/16 记录缩放比例
}
}
2 Faster R-CNN 大体流程
2.1 Conv Layers
也叫做backbone,使用conv+relu+pooling三层的组合提取图像的特征图,得到的特征图被后续RPN层共享,也被RoI Pooling 层共享
2.2 RPN
RPN网络用于生成建议框,这一层使用softmax层分类器判断建议框positive或negative,之后进行bounding box regression 修正anchors获得精确的proposals,注意,并不是只对positive框进行回归,而是对所有框进行回归,这一点由训练时的代价函数可以断定
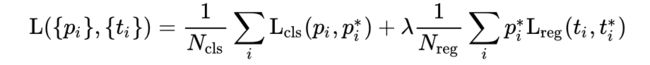
i表示anchors index
pi表示positive softmax probability
pi表示对应的GT predict 概率 (IoU>0.7,pi=1,IoU<0.3,pI=0)
t代表predict bounding box,t代表对应的positive anchor 对应的 GTbox
可以看到RPN层的Loss分为两部分:
- softmax loss,用来进行positive/negative分类时产生的loss
- bounding box regression loss,用来计算回归loss
而回归使用的是smooth L1 loss 计算公式为:
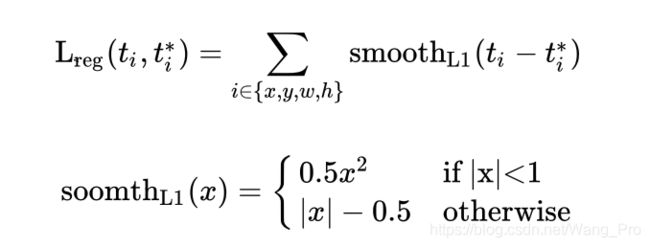
2.3 RoI Pooling
输入:1)经过conv+relu+pooling 之后的特征图;2)proposal layer的结果;综合信息后提取proposal feature maps ,将不同大小的proposal feature maps 大小归一化,送入后续识别
输出:一组向量,一个batch里向量的个数=建议框数量,向量大小=CxWxH,其中C为通道数,W=7,H=7(W,H是超参,论文里设定的);
具体的细节过程是:
RoI Pooling Layer 将上一步Proposal layer生成的建议框映射到输入图像对应的特征图(也就是CNN之后的特征图),映射过程需要进行取整(第一次取整),然后将取整后的建议框划分为WxH个区域,此处的区域划分也需要取整(第二次取整)
需要看代码解决
2.4 Classification
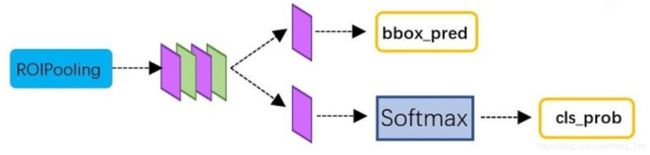
这一层计算proposal的类别,同时再进行一次细致回归,获得检测框的最终位置。
3 总结
3.1 以Loss的角度观察Faster R-CNN
关于整体Loss的计算实际分为两部分:
1)在RPN层中,Loss是由两部分组成,对proposal进行positive/negative分类误差;对proposal进行bounding box regression 回归误差
2)在Classification中,对proposal区域进行分类时得到的误差,与更精确的proposal回归时得到最终区域时得到的误差。
3.2 以anchor的角度观察Faster R-CNN
- 首先生成的base anchor数量为9个,即后面的K=9;
- backbone 输出50x38x512个特征,对应anchor设置50x38xK个anchors;
- RPN层输出50x38x2K的分类矩阵,为什么多2,是因为2代表softmax的分类结果为Positive还是negative。
- RPN层还输出了50x38x4K的坐标回归矩阵
过程中,每个点的2K个分类特征与4K回归特征,与K个anchor保持一一对应即可。
4 Faster RCNN 缺陷
Faster RCNN 整数化过程
(1)region proposal的xywh通常是小数,但是为了方便操作会把它整数化,所以anchor们都被整数化了。
(2)在ROI Pooling中,将整数化后的边界区域平均分割成 k x k 个单元,对每一个单元的边界进行整数化。
5 参考资料
Faster R-CNN详解:https://www.zhihu.com/people/george-zhang-84/posts
全连接层:https://zhuanlan.zhihu.com/p/33841176
softmax:https://blog.csdn.net/bitcarmanlee/article/details/82320853