第一次软工:individual_project_word_frequency 也是第一次cnblogs
先说说工程预计完成时间和实际用时吧。
大二的时候跟刘超老师学习“面向对象建模”这门课,然后有一个小作业时要写一个词频统计器。当时的要求是给了一个单词表,然后统计单词表中的单词在文中出现的频率,并打印。当时是第一次按照OO的思想和模式进行写的,而且也得到了老师的表扬,被当作一个比较好的例子,在他上课的时候通过PPT展示了出来。语言使用Java写的。
看到这次作业,我觉得我貌似可以偷一下懒。本来Java和C#很像,两个语言我也都熟悉,而且两个工程的需求很相似,我预计在4-5小时之内就能完成了。包括对代码移植过程中得一些修修补补,对文件的读取和对一些具体规则的重新定义。但是后来发现我太天真了。不包括扩展模式和文件IO,确实用了差不多4个小时,也就是一晚上搞定。但是之后包括对需求的仔细分析后进行规则的精确定义,包括对效率的更高要求以至于采用新的数据结构等等一系列各种各种的问题实际花费的时间真的很难计算了,但是至少在2倍左右也就是9-10小时!
再说说这次工程本身的一些东西
首先,虽然自己以前用C#完成过一个大作业,是大二下的一门专业选修课,“C++”,有点讽刺,学了一学期C++,做了一学期C++的各种小作业,然后期末的时候讲了一节课的C#,最后大作业用C#写的真是惭愧。是一个PMS——工程管理系统。基本是熟悉了一下C#的语法规范。
但是在写这次的Project:word_frequency的时候,几乎每一个方法都要查MSDN(再次吐槽MSDN真是好东西),要的基本方法都有,直接调用就行了。所以要说学习到了什么,那么对于MSDN库的使用是一点,对于C#的很多常用的包括字符串处理啊,数组的各种使用啊,还有一些常用的数据结构的使用啊有了新的认识和了解。
一开始,自己使用的单词的数据结构是 Word类 有两个属性包括 wordname(String类型 单词的字符串)和 frequency(int类型 记录单词的频率)。然后储存单词的数据结构是 arrayList,用了一段时间发现,arrayList每次都要强制类型转换,很麻烦。就看到介绍说有个泛型动态数组 List<Word>, 这样就让代码简洁很多。然后自己试着跑了一下自己一个4GB的文件,发现只用了90s,貌似速度还行啊。班里流传了一个133M的纯.txt格式的文件夹。(里面都是英文原版小说)。我信心满满的跑了一下,我操机子跑了快一个小时还没出结果,然后被我中止了。大家都是只用了30-60s啊。废话不多说,上图:
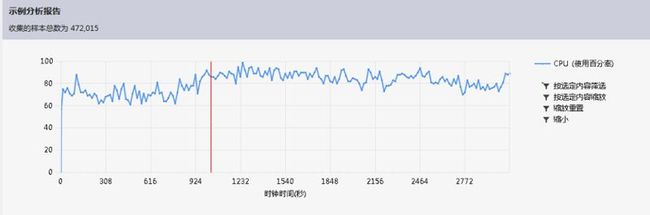
一脸泪有木有!!!!
这个时候才开始我软件工程的真正的第一步。
List<Word>是一种类似链表形式的,在我向其中放入单词的时候 List.Add(word),只是简单的底部插入。这个复杂度虽然是O(1),但是在下次查找的时候,只能顺序遍历,这样就会巨慢无比!超级慢!慢死了!!!!问了问大神。大神说,这是你的数据结构不够好的原因。C#中有一个叫做SortedDictionary的东西,这个东西在每次存入的时候,是构建了一棵平衡二叉树。在查找的时候复杂度就能达到nlogn,对于大数据来说,效果就会很明显。
我想重点讲一下我存单词的数据结构。感谢我的队友王翔对我帮助!
SortedDictionary<String, Word> Wordlist;这个Wordlist里 TKey在扩展模式里存的是单词的非数字前缀,TValue存的是Word(自定义的类),然后,只要新单词的非数字前缀在SortedDictionary中找到了,则TValue里的Word.frequency++;而且Word.wordname进行更改,替换为字典序(AaBb)更小的那个,以便之后输出。
出来的时间差不多是50s左右,我又想可能是我处理字符串的时候比较慢。原来是用一句
1 String[] list = line.Split(new char[]{',','.',' ','<','>','|' ,'[',']','{','!','@','#','$','%','^','&','*','(',')','+','=','-','}'}, StringSplitOptions.None);
但是大神说,这样因为符号很多,或许会影响速度,所以,我就重新写了一个MySplit来处理字符串,作用相同,不过是逆向思维,只要不是合法字符(子母和数字)则隔断。这样果然快了又差不多5-6s左右。
废话不多说,看疗效:
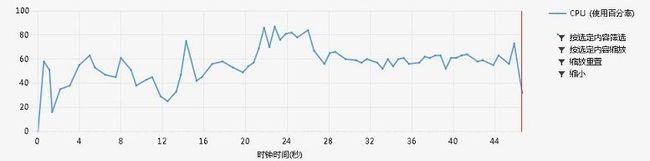
但是44s+的成绩还是不能令人满意,毕竟宿舍牛逼的人,跑相同的文件只用了10s。然后抽空看了看,同学的博客,发现了原来SortedDictionary是在插入时构建平衡二叉树,而另一种结构Dictionary,则是构建Hash表,那一想,必须Hash快啊!一试,果然是这样。上图:
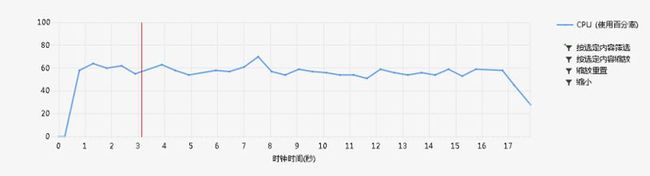
这差不多是一个好的结果了。
总结体会
正是这门课对我们的这些要求,比如“programs with incorrect result will get 0 points”,跟以前完全不一样,所以自己一遍一遍地在扣需求,在满足所有的要求。以达到没有一个错误。我觉得其实邹兴老师说的很好,一个错误跟十个错误是一样。我觉得在学习的时候被灌输这样的思想,在今后学习工作中的严谨性上会更好。
另外,这也是我第一次对程序的运行效率这么看重,原来只是在做一些包括ACM等等的算法题的时候,会卡一下时间,但是一旦在完成工程上,就大打折扣,这次从链表到平衡二叉树到HASH表,真的是对自己的一个更高的要求。看到程序在大数据处理上的效率改变这么明显,体会还是十分深刻的。
通过讨论,Hash表+QuickSort应该是这次工程能到达的最好数据结构了。储存时使用Hash表,排序时使用QuickSort,那么程序出来的时间就不会相差太多了。就是一些细节方面的修改了。
我最后排序是List的Sort,查资料上面说,List.Sort是调用的array的QuickSort,所以可能在这个上面会有一些效率损失,所以,要想更快,要自己写快拍才行。
最后一点体会,就是OO这种程序设计思想,确实是增加了编程的效率,但是同时也牺牲了部分程序运行的效率。他们10s的基本上没有写几个类。类似于面向过程的语言特点。这也是一个局限吧。