【隐私计算技术】开发者必看:隐语框架的分层拆解和使用
一、“隐语”架构设计全貌
1.隐语框架设计思想
隐私计算是一个新兴的跨学科领域,涉及密码学、机器学习、数据库、硬件等多个领域。根据过去几年的实践经验,我们发现
-
隐私计算技术方向多样,不同场景下有其各自更为合适的技术解决方案
-
隐私计算学习曲线很高,非隐私计算背景的用户使用困难
-
隐私计算涉及领域众多,需要领域专家共同协作
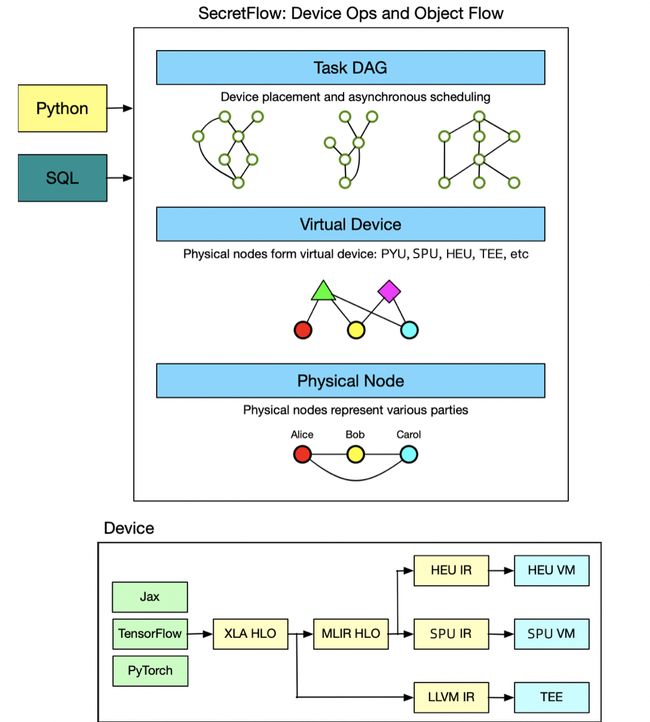
隐语的设计目标是使得数据科学家和机器学习开发者可以非常容易地使用隐私计算技术进行数据分析和机器学习建模,而无需了解底层技术细节。
为达到这个目标,隐语提供了一层设备抽象将多方安全计算(MPC)、同态加密(HE)和可信执行环境(TEE)等隐私计算技术抽象为密文设备, 将单方计算抽象为明文设备。
基于这层抽象,数据分析和机器学习工作流可以表示为一张计算图,其中节点表示某个设备上的计算,边表示设备之间的数据流动,不同类型设备之间的数据流动会自动进行协议转换。在这一点上,隐语借鉴了主流的深度学习框架,后者将神经网络表示为一张由设备上的算子和设备间的张量流动构成的计算图。
隐语框架围绕开放这一核心思想,提供了不同层次的设计抽象,希望为不同类型的开发者都提供良好的开发体验。
在设备层,隐语提供了良好的设备接口和协议接口,支持更多的设备和协议插拔式的接入,我们希望与密码学、可信硬件、硬件加速等领域专家通力合作,不断扩展密态计算的类型和功能,不断提升协议的安全性和计算性能。
同时,隐语提供了良好的设备接口,第三方隐私计算协议可作为设备插拔式接入。在算法层,为机器学习提供了灵活的编程接口,算法开发者可以很容易定义自己的算法。
2.架构分层总览
隐语总体架构自底向上一共分为五层:
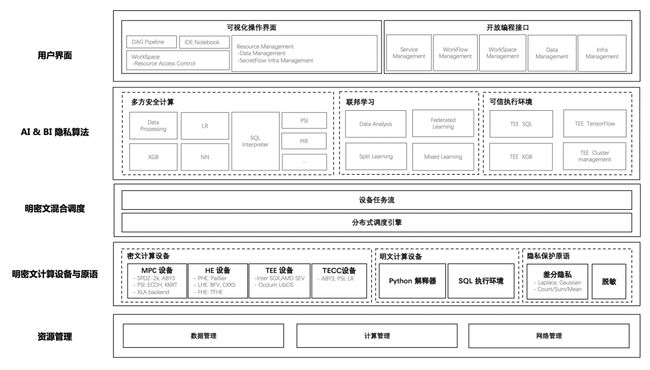
资源管理层:主要承担了两方面的职责。第一是面向业务交付团队,可以屏蔽不同机构底层基础设施的差异,降低业务交付团队的部署运维成本。另一方面,通过对不同机构的资源进行集中式管理,构建出一个高效协作的数据协同网络。
明密文计算设备与原语层:提供了统一的可编程设备抽象,将多方安全计算(MPC)、同态加密(HE)、可信硬件(TEE)等隐私计算技术抽象为密态设备,将单方本地计算抽象为明文设备。同时,提供了一些不适合作为设备抽象的基础算法,如差分隐私(DP)、安全聚合(Secure Aggregation)等。
明密文混合调度层:提供了统一的设备调度抽象,将上层算法描述为一张有向无环图,其中节点表示某个设备上的计算,边表示设备之间的数据流动,即逻辑计算图。逻辑计算图由分布式框架进一步拆分并调度至物理节点。
AI & BI 隐私算法层:这一层的目的是屏蔽掉隐私计算技术细节,但保留隐私计算的概念,其目的是降低隐私计算算法的开发门槛,提升开发效率。有隐私计算算法开发诉求的同学,可以根据自身场景和业务的特点,设计出一些特化的隐私计算算法,**来满足自身业务和场景对安全性、计算性能和计算精度的平衡。**在这一层上,隐语本身也会提供一些通用的算法能力,比如MPC的LR/XGB/NN,联邦学习算法,SQL能力等。
用户界面层:隐语的目标并不是做一个端到端的产品,而是为了让不同的业务都能够通过快速集成隐语而具备全面的隐私计算能力。因此我们会在最上层去提供一层比较薄的产品API,以及一些SDK,去降低业务方集成隐语的成本。
3.架构细节拆解
设备与原语层
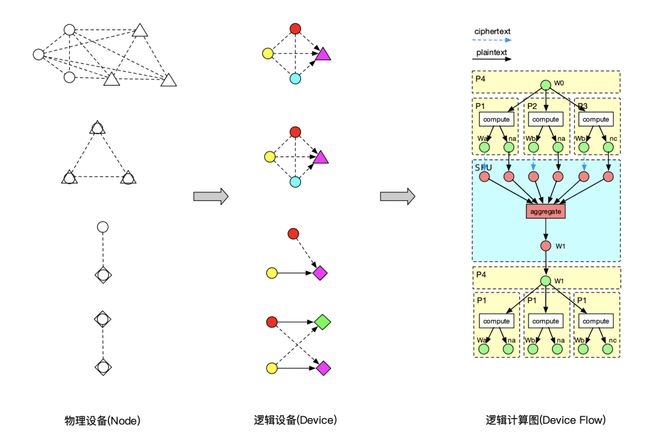
隐语的设备分为物理设备和逻辑设备,其中,物理设备是隐私计算各个参与方的物理机器,逻辑设备则由一个或多个物理设备构成。逻辑设备支持一组 特定的计算算子(Device Ops),有自己特定的数据表示(Device Object)。逻辑设备分为明文和密文两种类型,前者执行单方本地计算,后者执行多方参与的隐私计算。
逻辑设备的运行时负责内存管理、数据传输、算子调度等职责,运行在一个或多个物理设备上。逻辑设备和物理设备不是一对一的关系,一个物理设备可能同时属于多个逻辑设备。在同一组物理设备上,可以根据不同的隐私协议和参与组合虚拟出不同的逻辑设备。
下表是隐语目前暂定支持的设备列表:
设备 |
类型 |
运行时 |
算子 |
协议 |
前端 |
状态 |
PYU |
明文 |
Python Interpreter |
— |
— |
Python |
Release |
SPU |
密文 |
SPU VM |
PSI, XLA HLO |
SPDZ-2k, ABY3 |
JAX, TensorFlow, PyTorch |
Alpha |
HEU |
密文 |
HEU Runtime |
Add, XLA HLO |
Paillier, OU, TFHE |
Numpy, JAX |
Alpha |
TEE |
密文 |
TEE Runtime |
XLA HLO |
Intel SGX |
JAX, TensorFlow, PyTorch |
WIP |
可编程性
逻辑设备具备可编程性,即用户可以在设备上自定义计算逻辑,每个设备对用户提供了协议无关的编程接口。在一个设备上,用户可以定义从简单的矩阵运算, 到完整的深度模型训练。当然,这一切取决于设备提供的计算能力。
对于明文设备PYU,它的前端为python,用户可以通过@device将一段预定义python函数调度至其上执行。
对于密文设备SPU、HEU、TEE,它们的前端可以是任何支持XLA 的框架, 如JAX, TensorFlow,PyTorch等。同样的,用户也可以通过@device将基于这些前端自定义的函数调度至指定的设备执行。
import jax.numpy as jnp
dev = Device() # maybe PYU, SPU, HEU, TEE
@device(dev)
def selu(x, alpha=1.67, lmbda=1.05):
return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha)
res = selu(x) # res is a DeviceObject
用户自定义函数首先转换成XLA HLO Computation,由XLA进行设备无关的代码优化和分析,并发往后端设备。后端设备进一步执行代码优化和分析,并生成最终 的可执行代码。可执行代码或由设备的虚拟机解释执行(SPU, HEU),或由硬件直接执行(TEE)。使用XLA HLO作为IR,使得我们可以复用XLA前端和设备无关 代码优化,同时使得后端实现更加简洁干净。
对于密文设备(半同态)HEU,它仅支持一组有限的计算,因此提供了一组预定义算子如__add__, __mul__等,用户不能通过@device进行自定义编程。
x, y = HEUObject(), PYUObject()
z = x + y # add
z = x * y # mul
z = x @ y # matmul
协议转换
用户在逻辑设备上进行编程,构建逻辑计算图,其节点表示设备上的一段函数或算子,边表示设备对象的流动。逻辑计算图被设备进一步分割为子图,两个子图间的 边表示跨设备的对象流动,此时需要进行协议转换。设备对象的DeviceObject.to接口用于转换至目标设备对象,任何新增的设备都应该提供相应的转换函数并 插入对象转换表中。
下表是各个逻辑设备对象的转换表:
PYU |
SPU |
HEU |
TEE |
|
PYU |
share |
encrypt |
encrypt |
|
SPU |
reconstruct |
encrypt+add |
reconstruct+encrypt |
|
HEU |
decrypt |
minus+decrypt |
decrypt+encrypt |
|
TEE |
decrypt |
decrypt+share |
decrypt+encrypt |
分布式引擎
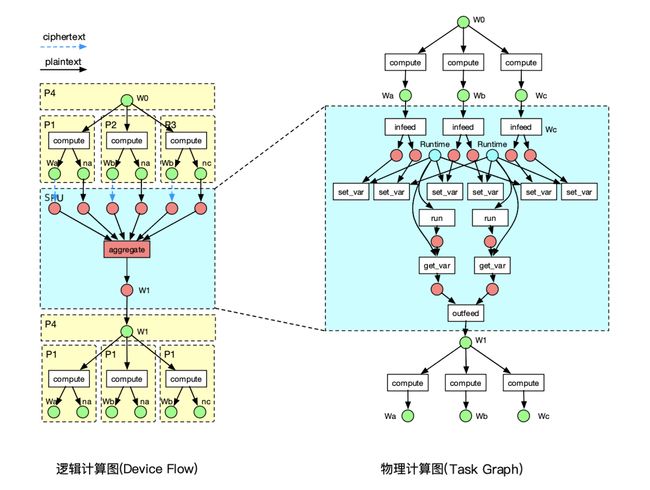
用户基于设备构建了一张逻辑计算图,那么我们如何执行这张计算图?由于逻辑设备映射到一个或多个物理设备,因此我们需要将逻辑设备上的算子正确调度到其对应的物理设备,同时处理好这些物理设备间的数据传输关系。毫无疑问,我们需要一个分布式图执行引擎来解决这些问题。
那么我们需要一个怎样的分布式图执行引擎?以下是隐语对它的要求
细粒度的异构计算:在一张逻辑计算图中,具有不同粒度的计算任务,既有简单的数据处理(秒级),也有复杂的多方训练(几个小时至几十小时)。同时,物理节点具有不同的硬件环境,CPU, GPU, TEE, FPGA等。
灵活的计算模型:在水平、垂直场景下,针对数据处理和模型训练等不同工作流,支持多种并行模型,如数据并行、模型并行、混合并行。
动态执行:在联邦学习场景下,不同机构的数据规模、带宽延迟、机器性能可能有较大差异,这导致同步模式的效率受限于最慢的工作节点。因此,我们希望支持 异步训练模式,这要求图执行引擎具有动态执行能力。
隐语针对隐私计算场景,已经对框架进行了一些安全加固工作:通过身份认证、代码预装、代码存证等手段对框架做了整体加固。未来,还将探索沙箱隔离、访问控制、静态图等机制以进一步提升安全水位。在环境适配方面,为了适配跨机构网络通信的特点,推进了GCS gRPC通信、域名支持、弱网断线处理等相关功能的开发。
AI & BI 隐私算法
这一层的目的是其目的是降低隐私计算算法的开发门槛,提升开发效率。有隐私计算算法开发诉求的同学,可以根据自身场景和业务的特点,设计出一些特化的隐私计算算法,来满足自身业务和场景对安全性、计算性能和计算精度的平衡。在这一层上,隐语本身也会提供一些通用的算法能力,比如MPC的LR/XGB/NN,联邦学习算法,SQL能力等。
二、“隐语”框架的使用使用隐语构建隐私计算算法
逻辑设备抽象为算法开发者提供了极大的灵活性,他们可以像积木一样自由组合这些设备,在设备上自定义计算,从而构建自己的隐私计算算法。接下来,我们通过一个具体的算法来展示隐语框架的通用编程能力。
联邦学习算法
联邦机器学习又名联邦学习,联合学习,联盟学习,是一种机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。
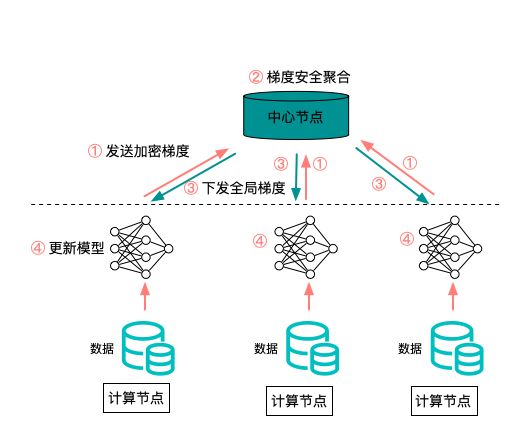
联邦学习的算法流程如上图所示,大致分为以下四个步骤1、机构节点在本地进行多轮训练,得到模型参数2、机构节点使用加密协议,将模型参数上传至聚合节点3、聚合节点使用加密协议,对模型参数进行聚合,得到全局模型4、机构节点从聚合节点获取最新的全局模型,进入下一轮训练
节点本地训练
机构节点运行在机构本地,隐语提供了一个逻辑设备PYU,执行本地的明文计算。下面的BaseTFModel定义了本地模型训练逻辑,用户可以选择自己喜好的机器学习框架,如TensorFlow, PyTorch等。隐语提供了@proxy装饰器,对一个普通的类进行了初始设置,以便后续在逻辑设备上对其实例化。@proxy(PYUObject)表明该类需要在PYU设备上实例化。
@proxy(PYUObject)
class BaseTFModel:
def train_step(self, weights, cur_steps, train_steps) -> Tuple[np.ndarray, int]:
self.model.set_weights(weights)
num_sample = 0
for _ in range(train_steps):
x, y = next(self.train_set)
num_sample += x.shape[0]
self.model.fit(x, y)
return self.model.get_weights(), num_sample
模型安全聚合
模型聚合对各个机构节点的模型参数进行加权平均,如下面_average所示。隐语逻辑设备的最大特点在于可编程性,用户可以将一段函数调度到多种设备执行,以达到使用不同隐私计算技术的目的。目前,DeviceAggregator可以支持PYU明文聚合,也可以支持SPU MPC协议聚合,后续我们还将支持TEE, HEU等多种密文设备。
@dataclass
class DeviceAggregator(Aggregator):
device: Union[PYU, SPU]
def average(self, data: List[DeviceObject], axis=0, weights=None):
# 2. 机构节点使用加密协议,将模型参数上传至聚合节点
data = [d.to(self.device) for d in data]
if isinstance(weights, (list, tuple)):
weights = [w.to(self.device) if isinstance(w, DeviceObject) else w for w in weights]
def _average(data, axis, weights):
return [jnp.average(element, axis=axis, weights=weights) for element in zip(*data)]
# 3. 聚合节点使用加密协议,对模型参数进行聚合,得到全局模型
return self.device(_average, static_argnames='axis')(data, axis=axis, weights=weights)
训练流程整合
有了节点本地训练、模型安全聚合,我们就可以将其整合起来形成完整的训练流程。首先,我们在每个PYU设备(代表机构节点)创建BaseTFModel实例。同时,初始化聚合器,可以是PYU, SPU, TEE, Secure Aggregation。然后,按照上述描述的联邦学习算法流程进行迭代训练。
class FedTFModel:
def __init__(self, device_list: List[PYU] = [], model: Callable[[], tf.keras.Model] = None, aggregator=None):
# 在每个机构节点(PYU)创建一个BaseTFModel实例
self._workers = {device: BaseTFModel(
model, device=device) for device in device_list}
# 聚合器,可以是PYU, SPUPPU, TEE, Secure Aggregation
self._aggregator = aggregator
def fit(self, x: Union[HDataFrame, FedNdarray], y: Union[HDataFrame, FedNdarray], batch_size=32, epochs=1, verbose='auto',
callbacks=None, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, validation_freq=1, aggregate_freq=1):
self.handle_data(train_x, train_y, batch_size=batch_size,
shuffle=shuffle, epochs=epochs)
# 初始化模型参数
current_weights = {
device: worker.get_weights() for device, worker in self._workers.items()}
for epoch in range(epochs):
for step in range(0, self.steps_per_epoch, aggregate_freq):
weights, sample_nums = [], []
for device, worker in self._workers.items():
# 1. 机构节点在本地进行多轮训练,得到模型参数
weight, sample_num = worker.train_step(current_weights[device], epoch*self.steps_per_epoch+step, aggregate_freq)
weights.append(weight)
sample_nums.append(sample_num)
# 模型参数聚合,可以是:PYU, SPU, TEE, Secure Aggregation
current_weight = self._aggregator.average(
weights, weights=sample_nums)
# 4. 机构节点从聚合节点获取最新的全局模型,进入下一轮训练
current_weights = {device: current_weight.to(device) for device, worker in self._workers.items()}
更多算法:
通过以上联邦学习算法的例子,我们展示了隐语作为隐私计算框架的可编程性、可扩展性。期待您基于隐语探索更多有趣的用法!更多详情请参考我们的教程和实现。
https://secretflow.readthedocs.io/zh/latest/tutorial/index.html#
-
在SPU进行PSI对齐,逻辑回归、神经网络训练
-
使用SPU HEU的组合构建HESS-LR, HESS-XGB算法
-
横向联邦学习,在PYU进行本地训练,使用SPU、TEE、Secure Aggregation进行梯度、权重聚合
-
纵向拆分学习,将一个模型拆分至多个PYU,使用PYU聚合隐层,使用差分隐私保护前向隐层和反向梯度
关注微信公众号:隐语小剧场
