Mybatis 缓存
⼀级缓存
①、在⼀个sqlSession中,对User表根据id进⾏两次查询,查看他们发出sql语句的情况
@Test
public void test1(){
//根据 sqlSessionFactory 产⽣ session
SqlSession sqlSession = sessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第⼀次查询,发出sql语句,并将查询出来的结果放进缓存中
User u1 = userMapper.selectUserByUserId(1);
System.out.println(u1);
//第⼆次查询,由于是同⼀个sqlSession,会在缓存中查询结果
//如果有,则直接从缓存中取出来,不和数据库进⾏交互
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2);
sqlSession.close();
}查看控制台打印情况:

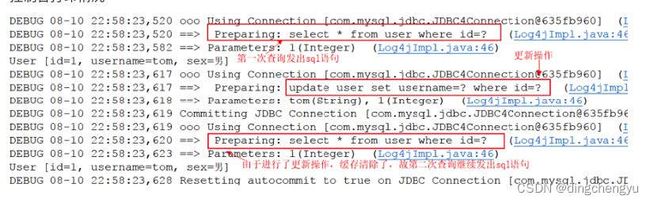
② 、同样是对user表进⾏两次查询,只不过两次查询之间进⾏了⼀次update操作。
@Test
public void test2(){
//根据 sqlSessionFactory 产⽣ session
SqlSession sqlSession = sessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第⼀次查询,发出sql语句,并将查询的结果放⼊缓存中
User u1 = userMapper.selectUserByUserId( 1 );
System.out.println(u1);
//第⼆步进⾏了⼀次更新操作,sqlSession.commit()
u1.setSex("⼥");
userMapper.updateUserByUserId(u1);
sqlSession.commit();
//第⼆次查询,由于是同⼀个sqlSession.commit(),会清空缓存信息
//则此次查询也会发出sql语句
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2);
sqlSession.close();
}查看控制台打印情况:
③、总结
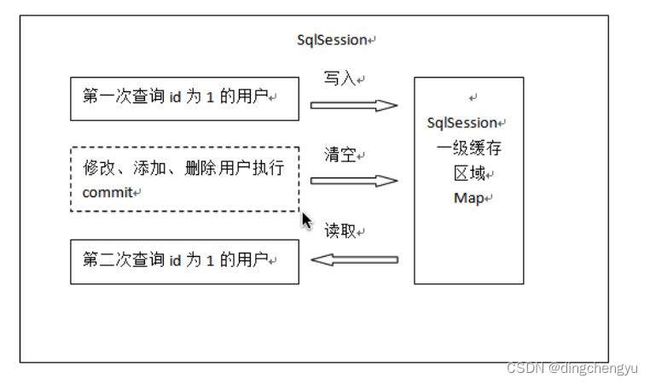
1、第⼀次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,如果没有,从 数据库查询⽤户信息。得到⽤户信息,将⽤户信息存储到⼀级缓存中。
2、 如果中间sqlSession去执⾏commit操作(执⾏插⼊、更新、删除),则会清空SqlSession中的⼀级缓存,这样做的⽬的为了让缓存中存储的是最新的信息,避免脏读。
3、 第⼆次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,缓存中有,直接从缓存中获取⽤户信息
⼆级缓存
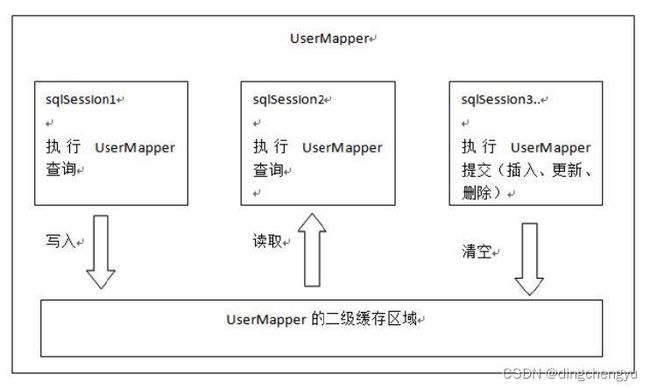
⼆级缓存的原理和⼀级缓存原理⼀样,第⼀次查询,会将数据放⼊缓存中,然后第⼆次查询则会直接去缓存中取。但是⼀级缓存是基于sqlSession的,⽽⼆级缓存是基于mapper⽂件的namespace的,也就是说多个sqlSession可以共享⼀个mapper中的⼆级缓存区域,并且如果两个mapper的namespace 相同,即使是两个mapper,那么这两个mapper中执⾏sql查询到的数据也将存在相同的⼆级缓存区域 中
如何使⽤⼆级缓存
① 、开启⼆级缓存
和⼀级缓存默认开启不⼀样,⼆级缓存需要我们⼿动开启
⾸先在全局配置⽂件sqlMapConfig.xml⽂件中加⼊如下代码:
其次在UserMapper.xml⽂件中开启缓存
我们可以看到mapper.xml⽂件中就这么⼀个空标签,其实这⾥可以配置,PerpetualCache这个类是
mybatis默认实现缓存功能的类。我们不写type就使⽤mybatis默认的缓存,也可以去实现Cache接⼝来⾃定义缓存。

public class PerpetualCache implements Cache {
private final String id;
private MapcObject, Object> cache = new HashMapC);
public PerpetualCache(String id) { this.id = id;}
}我们可以看到⼆级缓存底层还是HashMap结构
public class User implements Serializable(
//⽤户ID
private int id;
//⽤户姓名
private String username;
//⽤户性别
private String sex;
}开启了⼆级缓存后,还需要将要缓存的pojo实现Serializable接⼝,为了将缓存数据取出执⾏反序列化操作,因为⼆级缓存数据存储介质多种多样,不⼀定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接⼝
③、测试
⼀、测试⼆级缓存和sqlSession⽆关
@Test
public void testTwoCache(){
//根据 sqlSessionFactory 产⽣ session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper. class );
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper. class );
//第⼀次查询,发出sql语句,并将查询的结果放⼊缓存中
User u1 = userMapper1.selectUserByUserId(1);
System.out.println(u1);
sqlSession1.close(); //第⼀次查询完后关闭 sqlSession
//第⼆次查询,即使sqlSession1已经关闭了,这次查询依然不发出sql语句
User u2 = userMapper2.selectUserByUserId(1);
System.out.println(u2);
sqlSession2.close();
}可以看出上⾯两个不同的sqlSession,第⼀个关闭了,第⼆次查询依然不发出sql查询语句
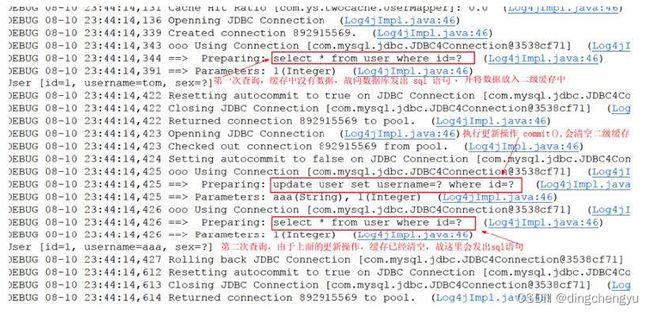
⼆、测试执⾏commit()操作,⼆级缓存数据清空
@Test
public void testTwoCache(){
//根据 sqlSessionFactory 产⽣ session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
SqlSession sqlSession3 = sessionFactory.openSession();
String statement = "com.lagou.pojo.UserMapper.selectUserByUserld" ;
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper. class );
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper. class );
UserMapper userMapper3 = sqlSession2.getMapper(UserMapper. class );
//第⼀次查询,发出sql语句,并将查询的结果放⼊缓存中
User u1 = userMapperl.selectUserByUserId( 1 );
System.out.println(u1);
sqlSessionl .close(); //第⼀次查询完后关闭sqlSession
//执⾏更新操作,commit()
u1.setUsername( "aaa" );
userMapper3.updateUserByUserId(u1);
sqlSession3.commit();
//第⼆次查询,由于上次更新操作,缓存数据已经清空(防⽌数据脏读),这⾥必须再次发出sql语
User u2 = userMapper2.selectUserByUserId( 1 );
System.out.println(u2);
sqlSession2.close();
}查看控制台情况:
④、useCache和flushCache
mybatis中还可以配置userCache和flushCache等配置项,userCache是⽤来设置是否禁⽤⼆级缓 存的,在statement中设置useCache=false可以禁⽤当前select语句的⼆级缓存,即每次查询都会发出 sql去查询,默认情况是true,即该sql使⽤⼆级缓存
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁⽤⼆级缓存,直接从数 据库中获取。
在mapper的同⼀个namespace中,如果有其它insert、update, delete操作数据后需要刷新缓存,如果不执⾏刷新缓存会出现脏读。
设置statement配置中的flushCache="true”属性,默认情况下为true,即刷新缓存,如果改成false则 不会刷新。使⽤缓存时如果⼿动修改数据库表中的查询数据会出现脏读。
⼀般下执⾏完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不⽤设置,默认即可
⼆级缓存整合redis
上⾯我们介绍了 mybatis⾃带的⼆级缓存,但是这个缓存是单服务器⼯作,⽆法实现分布式缓存。 那么什么是分布式缓存呢?假设现在有两个服务器1和2,⽤户访问的时候访问了 1服务器,查询后的缓 存就会放在1服务器上,假设现在有个⽤户访问的是2服务器,那么他在2服务器上就⽆法获取刚刚那个 缓存,如下图所示:
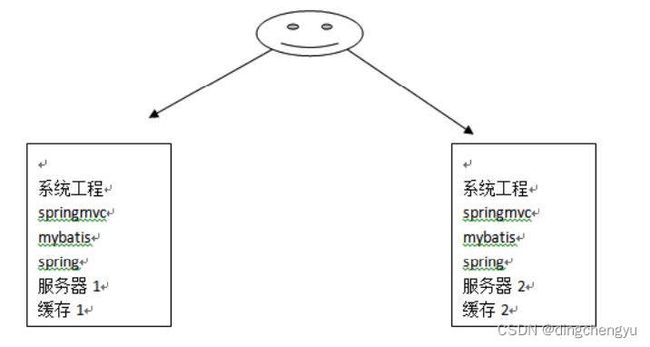
为了解决这个问题,就得找⼀个分布式的缓存,专⻔⽤来存储缓存数据的,这样不同的服务器要缓存数据都往它那⾥存,取缓存数据也从它那⾥取,如下图所示:
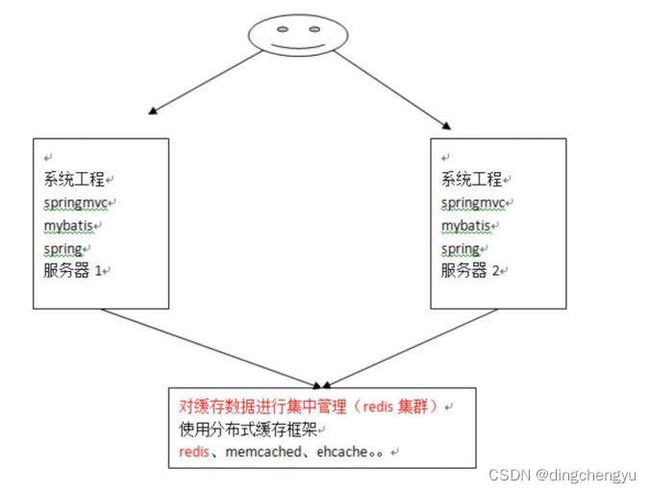
如上图所示,在⼏个不同的服务器之间,我们使⽤第三⽅缓存框架,将缓存都放在这个第三⽅框架中,然后⽆论有多少台服务器,我们都能从缓存中获取数据。
这⾥我们介绍mybatis与redis的整合。
刚刚提到过,mybatis提供了⼀个eache接⼝,如果要实现⾃⼰的缓存逻辑,实现cache接⼝开发即可。mybatis本身默认实现了⼀个,但是这个缓存的实现⽆法实现分布式缓存,所以我们要⾃⼰来实现。redis分布式缓存就可以,mybatis提供了⼀个针对cache接⼝的redis实现类,该类存在mybatis-redis包中
实现:
1. pom⽂件
org.mybatis.caches
mybatis-redis
1.0.0-beta2
2.配置⽂件
Mapper.xml
3.redis.properties
redis.host=localhost
redis.port=6379
redis.connectionTimeout=5000
redis.password=
redis.database=04.测试
@Test
public void SecondLevelCache(){
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
IUserMapper mapper1 = sqlSession1.getMapper(IUserMapper.class);
lUserMapper mapper2 = sqlSession2.getMapper(lUserMapper.class);
lUserMapper mapper3 = sqlSession3.getMapper(IUserMapper.class);
User user1 = mapper1.findUserById(1);
sqlSession1.close(); //清空⼀级缓存
User user = new User();
user.setId(1);
user.setUsername("lisi");
mapper3.updateUser(user);
sqlSession3.commit();
User user2 = mapper2.findUserById(1);
System.out.println(user1==user2);
}源码分析:
RedisCache和⼤家普遍实现Mybatis的缓存⽅案⼤同⼩异,⽆⾮是实现Cache接⼝,并使⽤jedis操作缓存;不过该项⽬在设计细节上有⼀些区别;
public final class RedisCache implements Cache {
public RedisCache(final String id) {
if (id == null) {
throw new IllegalArgumentException("Cache instances require anID");
}
}
this.id = id;
RedisConfig redisConfig =
RedisConfigurationBuilder.getInstance().parseConfiguration();
pool = new JedisPool(redisConfig, redisConfig.getHost(),
redisConfig.getPort(),
redisConfig.getConnectionTimeout(),
redisConfig.getSoTimeout(), redisConfig.getPassword(),
redisConfig.getDatabase(), redisConfig.getClientName());
}RedisCache在mybatis启动的时候,由MyBatis的CacheBuilder创建,创建的⽅式很简单,就是调⽤RedisCache的带有String参数的构造⽅法,即RedisCache(String id);⽽在RedisCache的构造⽅法中,调⽤了 RedisConfigu rationBuilder 来创建 RedisConfig 对象,并使⽤ RedisConfig 来创建JedisPool。
RedisConfig类继承了 JedisPoolConfig,并提供了 host,port等属性的包装,简单看⼀下RedisConfig的属性:
public class RedisConfig extends JedisPoolConfig {
private String host = Protocol.DEFAULT_HOST;
private int port = Protocol.DEFAULT_PORT;
private int connectionTimeout = Protocol.DEFAULT_TIMEOUT;
private int soTimeout = Protocol.DEFAULT_TIMEOUT;
private String password;
private int database = Protocol.DEFAULT_DATABASE;
private String clientName;RedisConfig对象是由RedisConfigurationBuilder创建的,简单看下这个类的主要⽅法:
public RedisConfig parseConfiguration(ClassLoader classLoader) {
Properties config = new Properties();
InputStream input = classLoader.getResourceAsStream(redisPropertiesFilename);
if (input != null) {
try {
config.load(input);
} catch (IOException e) {
throw new RuntimeException("An error occurred while reading classpath property'"+ redisPropertiesFilename + "', see nested exceptions", e);
} finally {
try {
input.close();
} catch (IOException e) {
// close quietly
}
}
}
RedisConfig jedisConfig = new RedisConfig();
setConfigProperties(config, jedisConfig);
return jedisConfig;
}核⼼的⽅法就是parseConfiguration⽅法,该⽅法从classpath中读取⼀个redis.properties⽂件:
host=localhost
port=6379
connectionTimeout=5000
soTimeout=5000
password= database=0 clientName=并将该配置⽂件中的内容设置到RedisConfig对象中,并返回;接下来,就是RedisCache使⽤
RedisConfig类创建完成edisPool;在RedisCache中实现了⼀个简单的模板⽅法,⽤来操作Redis:
private Object execute(RedisCallback callback) {
Jedis jedis = pool.getResource();
try {
return callback.doWithRedis(jedis);
} finally {
jedis.close();
}
}模板接⼝为RedisCallback,这个接⼝中就只需要实现了⼀个doWithRedis⽅法⽽已:
public interface RedisCallback {
Object doWithRedis(Jedis jedis);
}接下来看看Cache中最重要的两个⽅法:putObject和getObject,通过这两个⽅法来查看mybatis-redis储存数据的格式:
@Override
public void putObject(final Object key, final Object value) {
execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
jedis.hset(id.toString().getBytes(), key.toString().getBytes(),SerializeUtil.serialize(value));
return null;
}
});
}
@Override
public Object getObject(final Object key) {
return execute(new RedisCallback() {
@Override
public Object doWithRedis(Jedis jedis) {
return SerializeUtil.unserialize(jedis.hget(id.toString().getBytes(),key.toString().getBytes()));
}
});
}可以很清楚的看到,mybatis-redis在存储数据的时候,是使⽤的hash结构,把cache的id作为这个hash的key (cache的id在mybatis中就是mapper的namespace);这个mapper中的查询缓存数据作为 hash的field,需要缓存的内容直接使⽤SerializeUtil存储,SerializeUtil和其他的序列化类差不多,负责 对象的序列化和反序列化;