【目标检测】CenterNet
论文地址:https://arxiv.org/pdf/1904.07850.pdf
代码地址:CenterNet: Object detection, 3D detection, and pose estimation using center point detection
CenterNet 是2019年4月发布的,是一种基于关键点估计的目标检测方法。
目标作为点
Abstract
exhaustive:adj. 详尽的; orientation:方向; differentiable:可微的
competitively:adv. 竞争性地;sophisticated:复杂的
检测将对象识别为图像中轴对齐的框。大多数成功的目标检测器都能列举出可能的物体位置,并对每个位置进行分类。这是浪费、低效的,并且需要额外的后处理。在本文中,我们采用了一种不同的方法。我们将一个目标建模为一个单点,即其 bounding box的中心点。我们的检测器使用关键点估计来找到中心点,并回归到所有其他目标属性,如大小、3D定位、方向,甚至姿态。我们基于中心点的方法,CenterNet是端到端可微的,比相应的基于 bounding box 的检测器更简单、更快、更精确。CenterNet在MS COCO数据集上实现了最佳的速度-精度权衡,在142 FPS下有28.1%的AP,在52 FPS下有37.4%的AP,在multi-scale测试中在1.4 FPS下有45.1%的AP。我们使用相同的方法来估计KITTI基准中的 3D bounding box 和COCO关键点数据集上的人体姿态。我们的方法与复杂的多阶段方法相比具有竞争力,并且是实时运行的。
理解:
基于bounding box的目标检测: 浪费、低效和需要加入后处理;
本文把目标建模为bounding box的中心点,使用关键点估计的方法找到中心点,然后回归出目标其他属性,如大小等。
7. Conclusion
总之,我们提出了一种新的目标表示方法: 以点表示。我们的CenterNet目标检测器建立在成功的关键点估计网络之上,找到目标中心,然后回归到它们的大小。该算法具有简单、快速、准确、端到端可微分等特点,无需任何 NMS 后处理。这个想法是通用的,并且在简单的二维检测之外有广泛的应用。CenterNet可以在一次前向传播中估计一系列额外的目标属性,如姿态、3D方向、深度和范围。我们最初的实验是令人鼓舞的,并为实时目标识别和相关任务开辟了一个新的方向。
1. Introduction
down-stream:下游; surveillance :监控;tightly encompasses:紧紧包围;extensive :大量的; specifying :说明
目标检测为许多视觉任务提供了动力,比如实例分割、姿态估计、跟踪和动作识别。它的下游应用有监控、自动驾驶、视觉答疑。当前的目标检测器通过一个紧密包围目标的轴对齐的 bounding box 来表示每个目标。然后将目标检测简化为大量潜在目标边界框的图像分类。对于每个边界框,分类器确定图像内容是特定的目标还是背景。One-stage 检测器在图像上滑动可能的bounding box(称为 anchors )的复杂排列,并直接对它们进行分类,而不指定box的内容。Two-stage 检测器重新计算每个潜在 box 的图像特征,然后对这些特征进行分类。后处理,即非极大值抑制,通过计算bounding box IoU消除对同一实例的重复检测。这种后处理很难求微分和训练,因此目前大多数检测器都不能端到端训练。尽管如此,在过去的五年中,这个想法已经取得了很好的实验上的成功。然而,基于滑动窗口的目标检测器有点浪费,因为它们需要枚举所有可能的目标定位和大小。 
在本文中,我们提供了一种更简单、更有效的替代方案。我们用bounding box中心的一个点表示目标(见图2)。其他属性,如目标的大小、尺寸、3D范围、方向和姿态,然后直接从中心定位的图像特征回归得到。然后,目标检测成为一个标准的关键点估计问题。我们只需将输入图像输入到一个全卷积网络,它就会生成一张热图。这张热图中的峰值对应的是目标的中心。每个峰值处的图像特征预测目标的bounding box高度和宽度。该模型使用标准的密集监督学习进行训练。推理是一个单个网络前向传播,对后处理没有NMS。
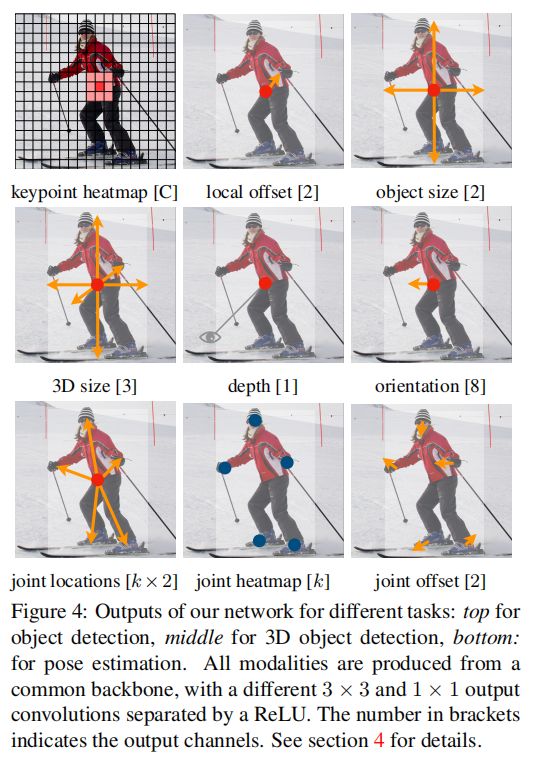
我们的方法是通用的,可以扩展到其他任务,只需少量的努力。我们通过预测每个中心点的额外输出(见图4),提供了3D目标检测和多人人体姿态估计的实验。对于3D bounding box 的估计,我们回归到目标绝对深度、3D bounding box 大小和目标方向。对于人体的姿态估计,我们将 2D joint locations 作为离中心点的偏移量,在中心点位置直接回归到该偏移量。
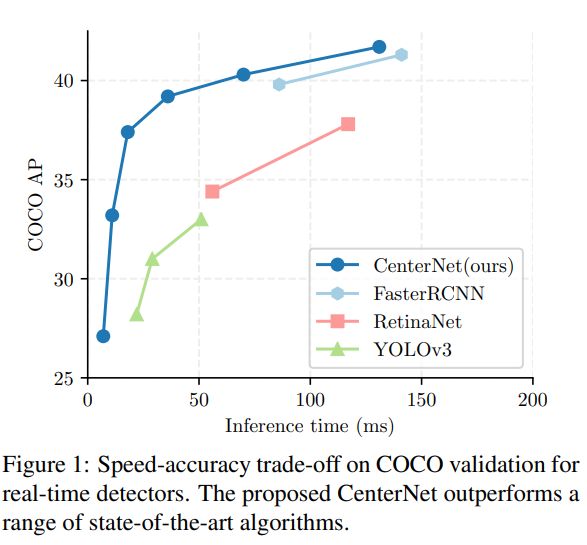
我们的方法CenterNet的简单性使它能够以非常高的速度运行(图1)。用一个简单的Resnet-18和up-convolutional层, 我们的网络运行在142 FPS与28.1%的COCO bounding box AP。使用精心设计的关键点检测网络,DLA-34,我们的网络以52 FPS达到37.4% COCO AP。我们的网络配备了最先进的关键点估计网络Hourglass-104和多尺度测试,在1.4 FPS下实现了45.1%的COCO AP。在3D bounding box 估计和人体姿态估计上,我们以更高的推理速度与最先进的技术进行竞争。有关代码在:https://github. com/xingyizhou/CenterNet.
2. Related work
基于区域分类的目标检测:RCNN[是最早成功的深度目标检测器之一,它从一个大的区域候选集合中枚举目标位置,对其进行裁减,并使用深度网络对每个目标进行分类。Fast-RCNN裁减图像特征代替裁减图像区域,以节省计算。然而,这两种方法都依赖于缓慢的低水平建议区域方法。
基于隐式anchors的目标检测:Faster RCNN 在检测网络内生成建议区域。它对低分辨率图像网格周围的固定形状的bounding boxes(anchors)进行采样,并将它们分类为前景或背景。当一个 anchor 与任何真实框的IOU>0.7,那么被标记为前景;当一个 anchor 与任何真实框的IOU<0.3,那么被标记为前景;否则忽略。对每个生成的建议区域再次进行分类。将建议分类器改为多类分类形成了one-stage 检测器的基础。对one-stage 检测器的改进包括 anchor 形状先验(k-means),不同的特征分辨率(SSD),以及不同样本之间的损失重加权(Focal loss)。
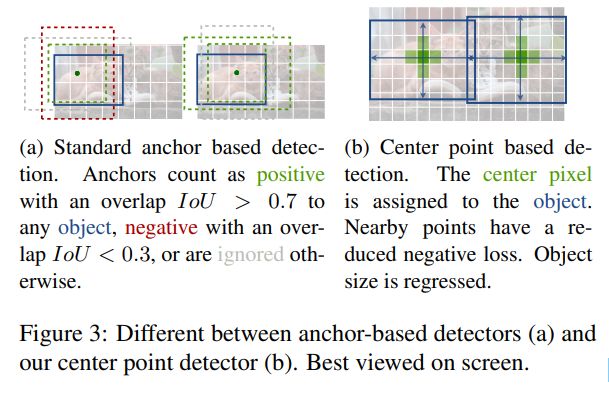
我们的方法与anchor-based one-stage方法密切相关。一个中心点可以看作是一个形状未知的anchor (参见图3)。然而,它们之间有一些重要的区别。首先,我们的CenterNet只根据位置分配“anchor”,而不是框重合度(IOU)。我们没有手动阈值的前景和背景分类。其次,每个目标只有一个正“anchor”,因此不需要Non-Maximum Suppression (NMS)。我们简单地提取关键点热图中的局部峰值。第三,与传统的目标检测器(输出步幅为16)相比,CenterNet使用了更大的输出分辨率(输出步幅为4)。这消除了对多个anchors 的需要。
基于关键点估计的目标检测:我们不是第一个使用关键点估计进行目标检测的。CornerNet 检测两个bounding box作为关键点,而ExtremeNet 检测所有目标的e top-, left-, bottom-, right- most, and center points。这两种方法都建立在与我们的CenterNet相同的稳健的关键点估计网络上。但是,它们在关键点检测后需要一个组合分组阶段,这大大降低了算法的速度。另一方面,我们的CenterNet只对每个目标提取一个中心点,而不需要分组或后期处理。
单目三维目标检测:3Dbounding box估计为自动驾驶提供动力。Deep3Dbox 使用slow-RCNN风格的框架,首先检测2D目标,然后将每个目标输入3D估计网络。3D RCNN增加了一个额外的头到Faster-RCNN ,跟着一个3D投影。Deep Manta 使用粗到细的Faster-RCNN 训练在许多任务。我们的方法类似于Deep3Dbox 或3DRCNN 的 one-stage 版本。因此,CenterNet比竞争对手的方法更简单、更快。
3. 准备工作(Preliminary)
设![]() 是一张宽为W和高为H的输入图像。我们的目标是产生一个关键点热图
是一张宽为W和高为H的输入图像。我们的目标是产生一个关键点热图 ![]() ,这里R是输出的stride,C是关键点类型的数目。关键点类型包括 在人体姿态估计中C = 17 人体连接点, 或 在目标检测中 C = 80 目标类别。我们使用默认输出R = 4的 stride。输出 stride 通过一个因数R下采样输出预测。对于检测到的一个关键点,一个预测
,这里R是输出的stride,C是关键点类型的数目。关键点类型包括 在人体姿态估计中C = 17 人体连接点, 或 在目标检测中 C = 80 目标类别。我们使用默认输出R = 4的 stride。输出 stride 通过一个因数R下采样输出预测。对于检测到的一个关键点,一个预测 ![]() ,而对于背景
,而对于背景 ![]() 。我们使用几个不同的fully-convolutional encoder-decoder networks从一张图像
。我们使用几个不同的fully-convolutional encoder-decoder networks从一张图像 中预测
中预测  。有:A stacked hourglass network,upconvolutional residual networks (ResNet) 和 deep layer aggregation (DLA)。
。有:A stacked hourglass network,upconvolutional residual networks (ResNet) 和 deep layer aggregation (DLA)。
我们跟随Cornernet 训练关键点预测网络。对于class c的每个ground truth 关键点 ![]() ,我们计算一个低分辨率等价的
,我们计算一个低分辨率等价的 ![]() 。然后,我们使用Gaussian kernel
。然后,我们使用Gaussian kernel ![]() 把所有的ground truth的关键点放在一个热图
把所有的ground truth的关键点放在一个热图 ![]() 上,这里
上,这里 ![]() 是一个目标 自适应尺寸的标准差。如果同一类的两个高斯函数重叠,我们取 element-wise 的最大值。训练目标是带有focal loss 的 a penalty-reduced pixelwise logistic regression:
是一个目标 自适应尺寸的标准差。如果同一类的两个高斯函数重叠,我们取 element-wise 的最大值。训练目标是带有focal loss 的 a penalty-reduced pixelwise logistic regression:
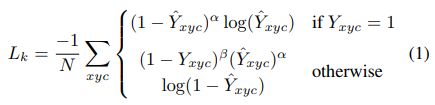
这里, 和
和 是focal loss的超参数,N是图像的关键点的数目。选择N的 malization 将所有positive focal loss 实例 normalize 为1。??不懂 。我们在所有实验中使用=2和=4。
是focal loss的超参数,N是图像的关键点的数目。选择N的 malization 将所有positive focal loss 实例 normalize 为1。??不懂 。我们在所有实验中使用=2和=4。
为了恢复输出stride引起的离散化误差,我们对于每个中心点另外预测了一个局部偏移![]() 。所有classes c 共享相同的偏移量预测。用一个 L1 loss来训练偏移量。
。所有classes c 共享相同的偏移量预测。用一个 L1 loss来训练偏移量。
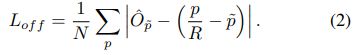
监督只在关键点定位 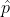 起作用,其他所有定位都被忽略。
起作用,其他所有定位都被忽略。
在下一节中,我们将展示如何将这个关键点估计器扩展到通用目标检测器。
4. 目标作为点
设 ![]() 是类别
是类别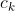 的目标 k的 bounding box。它的中心点在
的目标 k的 bounding box。它的中心点在 ![]() 。我们使用我们的关键点估计器来预测所有中心点。此外, 对于每个目标k,我们回归出目标的尺寸
。我们使用我们的关键点估计器来预测所有中心点。此外, 对于每个目标k,我们回归出目标的尺寸 ![]() 。为了限制计算负担, 对于所有目标类别,我们使用一个单尺寸预测
。为了限制计算负担, 对于所有目标类别,我们使用一个单尺寸预测 ![]() 。我们在中心点类似于公式2 使用一个 L1 loss :
。我们在中心点类似于公式2 使用一个 L1 loss :
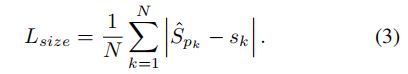
我们没有normalize 尺寸,直接使用原来的像素坐标。我们使用![]() 替换尺寸的loss 。总的训练目标是:
替换尺寸的loss 。总的训练目标是:
![]()
除非另有说明,在我们所有的实验中,我们设置 ![]() 和
和 ![]() 。我们使用了一个单网络来预测关键点 ,偏移
。我们使用了一个单网络来预测关键点 ,偏移 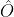 和尺寸
和尺寸  。网络在每个位置预测了 C + 4 输出的全部。所有的输出共享一个通用的全卷积backbone网络。对于每个模态, backbone的特征然后通过一个 3x3分离卷积,ReLU和另一个 1x1 卷积。图4 展示了网络输出的概览。第五部分和支撑材料包含额外的架构细节。
。网络在每个位置预测了 C + 4 输出的全部。所有的输出共享一个通用的全卷积backbone网络。对于每个模态, backbone的特征然后通过一个 3x3分离卷积,ReLU和另一个 1x1 卷积。图4 展示了网络输出的概览。第五部分和支撑材料包含额外的架构细节。
从点到bounding boxes 在推理时,我们首先在热图中对于每个类别独立地提取峰值。我们检测所有值大于或等于它的8邻域的响应,并保留前100的峰值。设 ![]() 是类别 c 的n 个检测中心点
是类别 c 的n 个检测中心点 ![]() 的集合。通过一个整数坐标
的集合。通过一个整数坐标  得到每个关键点定位。我们使用关键点值
得到每个关键点定位。我们使用关键点值 ![]() 作为它的检测置信度的度量,并且产生在定位处产生一个 bounding box。
作为它的检测置信度的度量,并且产生在定位处产生一个 bounding box。

这里 ![]() 是预测的偏移,
是预测的偏移, ![]() 是预测的尺寸。所有的输出直接由关键点估计产生,不需要使用NMS和其他后处理。峰值关键点提取作为一个充分的NMS替代方案,可以在设备上使用3 × 3 max pooling操作有效地实现。
是预测的尺寸。所有的输出直接由关键点估计产生,不需要使用NMS和其他后处理。峰值关键点提取作为一个充分的NMS替代方案,可以在设备上使用3 × 3 max pooling操作有效地实现。
4.1. 3D 检测
3D 检测每个目标估计一个3D bounding box 并且每个中心点要求3个额外属性:深度,3D范围和方向。对于它们的每个,我们加入一个分离head 。每个中心点的深度d是一个数。然而深度是难以直接回归的。我们替代的使用(Depth map prediction from a single image using a multi-scale deep network)中提到的 输出变换和 ![]() ,这里
,这里  是sigmoid函数。我们计算深度作为我们关键点估计器的一个额外的输出通道
是sigmoid函数。我们计算深度作为我们关键点估计器的一个额外的输出通道  。它再次使用了由ReLU分隔的两个卷积层。与以前的模式不同,它在输出层使用反 sigmoidal 变换。在进行sigmoidal 变换后,我们在原始深度域中使用L1 loss 来训练深度估计器。
。它再次使用了由ReLU分隔的两个卷积层。与以前的模式不同,它在输出层使用反 sigmoidal 变换。在进行sigmoidal 变换后,我们在原始深度域中使用L1 loss 来训练深度估计器。
物体的三维尺寸是三个标量。我们使用一个separate head ![]() 和一个L1 loss ,直接回归到它们的绝对值以米为刻度。
和一个L1 loss ,直接回归到它们的绝对值以米为刻度。
默认情况下,方向是单个标量。然而,它可能很难回归到。我们遵循Mousavian等人的工作,并将方向表示为两个 bins ,采用 in-bin 回归。具体来说,方向使用8个标量编码,每个bin 有4个标量。对于一个bin,,两个标量用于softmax,其余两个标量回归到每个bin内的一个角度。这些损失的详细情况请见补充。
4.2. Human pose estimation
人体姿态估计的目的是为图像中的每个人体i实例估计k个2D人体关节位置(k = 17 for COCO).我们将 pose 看作中心点的 k*2 维属性,并通过中心点的偏移量对每个关键点进行参数化。我们直接回归到关节偏移(以像素为单位) 使用一个L1 loss。通过掩码这个损失,我们忽略了不可见的关键点。这就产生了一种基于回归的one-stage多人 人体姿态估计器,类似于Toshev等人和Sun等人的slow-RCNN版本。
使用一个L1 loss。通过掩码这个损失,我们忽略了不可见的关键点。这就产生了一种基于回归的one-stage多人 人体姿态估计器,类似于Toshev等人和Sun等人的slow-RCNN版本。
为了细化关键点,我们使用标准的自底向上多人体姿态估计方法进一步估计了k张人体关节热图
![]() 。我们训练具有focal loss 和局部像素偏移的人体关节热图,类似于第3节讨论的中心检测。
。我们训练具有focal loss 和局部像素偏移的人体关节热图,类似于第3节讨论的中心检测。
然后,我们将最初的预测调整到这张热图上最近检测到的关键点。在这里,我们的中心偏移作为一个分组提示,将单个关键点检测分配给它们最近的人实例。具体来说,设![]() 为被检测的中心点。我们首先回归到所有关节位置
为被检测的中心点。我们首先回归到所有关节位置![]() 。我们还从对应的热图
。我们还从对应的热图![]() 中的每个连接点 j 的置信度 > 0.1, 提取所有关键点位置
中的每个连接点 j 的置信度 > 0.1, 提取所有关键点位置![]() 。然后,我们将每个回归位置
。然后,我们将每个回归位置![]() 分配给其最近的检测关键点
分配给其最近的检测关键点 ![]() ,只考虑检测目标的bounding box内的连接检测点。
,只考虑检测目标的bounding box内的连接检测点。
5. Implementation details
我们用ResNet-18、ResNet-101、DLA-34和Hourglass-104四种架构进行了实验。我们使用可变卷积修改ResNets和DLA-34,并使用Hourglass网络。
Hourglass 堆叠的Hourglass网络通过 4x 下采样输入,然后是两个顺序的hourglass模块。每个hourglass 模块都是一个带有skip connections的对称的5层down- and up-convolutional网络。这个网络是相当大的,但通常产生最好的关键点估计性能。
ResNet Xiao等人使用三个up-convolutional网络增强了标准residual network,以实现更高分辨率的输出(输出步幅4)。我们首先分别改变3个上采样层的通道数为 256,128,64 来节省计算。然后,我们分别在每个有256,128,64通道的up-convolution增加一个 3*3 分离卷积层。这个up-convolution 核是被初始化为 双线形插值。更详细的架构图清看支撑材料。
DLA Deep Layer Aggregation (DLA) 是一个具有skip connections的图像分类网络。我们利用全卷积上采样版本的DLA进行密集预测,该算法利用迭代深度聚合对称地提高特征图分辨率。我们用可变形卷积从下层到输出增强skip connections。具体地说,我们在每个上采样层用3个可变形卷积替换原来的卷积。详细的架构图请参见附录。
我们在每个输出头前增加一个256通道的3 * 3卷积层。最后的1*1卷积就产生了想要的输出。我们在补充材料中提供了更多的细节 。
Training
我们在512 * 512的输入分辨率上训练。这将为所有模型产生128*128的输出分辨率。我们使用随机翻转、随机缩放(0.6 - 1.3)、裁剪和颜色抖动作为数据增强,并使用Adam来优化总体目标。我们不使用增强来训练3D估计分支,因为裁剪或缩放会改变3D测量值。对于残差网络和DLA-34,我们以128个 batch-size (在8个gpu上)训练,140个epoch的学习速率为5e-4, 90和120个epoch的学习速率分别下降了10X。对于Hourglass-104,我们遵循ExtremeNet,使用 batch-size 29(在5个GPU上,使用master GPU batch-size 4)和在50个epoch上学习率2.5e-4,在40epoch上有10X学习速率下降。对于检测,我们微调了ExtremeNet中的Hourglass-104以节省计算。Resnet- 101和DLA-34的下采样层用ImageNet预训练进行初始化,上采样层随机初始化。Resnet-101和DLA-34在8个TITAN-V GPUs上训练需要2.5天,而Hourglass-104需要5天。
Inference
我们使用三种水平的测试增强:无增强、翻转扩增、翻转和多尺度(0.5、0.75、1,1.25、1.5)。对于翻转,我们在解码bounding boxes之前平均网络输出。对于多尺度,我们使用NMS来合并结果。这些增强会产生不同的速度-精度权衡,如下一节所示。

6. Experiments
我们在MS COCO数据集上评估我们的目标检测性能,该数据集包含118k训练图像(train2017)、5k验证图像(val2017)和20k hold-out 测试图像(test-dev)。我们报告了所有IOU阈值(AP)的平均精度,在0.5(AP 50)和0.75 (AP 75) IOU阈值处的AP。补充材料含有Pascal VOC的附加实验。

表1显示了我们在不同backbones和测试选项下对COCO验证的结果,而图1比较了CenterNet和其他实时检测器。运行时间是在我们的本地机器上测试的,Intel Core i7-8086K CPU, Titan Xp GPU, Pytorch 0.4.1, CUDA 9.0, and CUDNN 7.1.。我们下载代码和预训练的模型,在同一台机器上测试每个模型的运行时间。
Hourglass-104以相对较好的速度获得了最好的精度,在7.8 FPS下有42.2%的AP。在这个基础上,CenterNet在速度和精度上都优于CornerNet(40.6% AP在4.1 FPS)和ExtremeNet (40.3% AP在3.1 FPS)。运行时间的改进来自于更少的输出头和更简单的box解码方案。中心点比角点和极值点更容易检测到。
使用ResNet-101,在相同的网络backbone 条件下,我们的表现优于RetinaNet 。我们只在上采样层中使用可变形的卷积,这对 RetinaNet没啥用。在相同的accuracy下,我们的速度是前者的两倍多(CenterNet 34.8%AP在45帧每秒(输入512*512),而RetinaNet 34.4%AP在18帧每秒(输入500 *800))。我们最快的ResNet-18模型在142 FPS下也达到了28.1%的性能。
DLA-34提供了最好的速度/精度权衡。它以52.fps和37.4%的AP运行。这是YOLOv3的两倍以上的速度和4.4%AP更多精度。通过翻转测试,我们的模型仍然比YOLOv3更快,并达到了Faster-RCNN-FPN 的accuracy水平(CenterNet 39.2% AP 28 FPS, fast - rcnn 39.8% AP 11 FPS)。
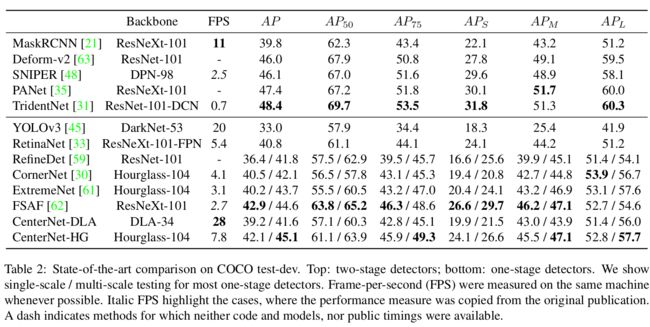
State-of-the-art comparison 我们在表2中比较了COCOtest-dev中其他最先进的检测器。在多尺度评估中,使用Hourglass-104的CenterNet检测器获得了45.1%的AP,优于现有的所有单级探测器。复杂的两级探测器更精确,但也更慢。对于不同的物体尺寸或IOU阈值,CenterNet和滑动窗口检测器之间没有显著差异。CenterNet的行为就像一个普通的检测器,只是更快。
6.1.1 Additional experiments
在不幸的情况下,两个不同的物体可能共享同一个中心,如果他们完全对齐。在这个场景中,CenterNet只会检测其中一个。我们首先研究这种情况在实践中发生的频率,并将其与竞争方法的漏检联系起来。
Center point collision(冲突)
在COCO训练集中,有614对目标在stride 4时碰撞到同一中心点。总共有860001个物体,因此由于中心点的碰撞,CenterNet无法预测小于0.1%的物体。这比slow- or fast-RCNN错过由于不完美的区域建议2% 更少并且少于由于无效anchor 放置((20.0% for Faster-RCNN with 15 anchors at 0.5 IOU threshold))的 anchor-based 方法的缺失。此外,715对物体的边界框IoU > 0.7,将被分配给两个anchors,因此基于中心的分配导致较少的碰撞。
NMS
为了验证CenterNet不需要基于IoU的NMS,我们将其作为预测的后处理步骤运行。对于DLA-34(翻转测试),AP从39.2%提高到39.7%。对于Hourglass-104,AP保持在42.2%。考虑到轻微的影响,我们不使用它。
接下来,我们消融模型的新超参数。所有的实验都是在DLA-34上进行的。
Training and Testing resolution
在训练过程中,我们将输入分辨率固定为512*512。在测试过程中,我们遵循CornerNet,以保持原始图像分辨率和zero-pad输入到网络的最大步幅。对于ResNet和DLA,我们用32个像素填充图像,而对于HourglassNet,我们用128个像素。如表3a所示,保持原始分辨率略好于固定测试分辨率。在较低分辨率(384*384)下进行训练和测试的速度要快1.7倍,但会降低3AP。

Regression loss
我们比较了普通L1 loss和Smooth L1的大小回归。我们在表3c中的实验表明,L1比Smooth L1要好得多。
该方法在精细尺度上具有较好的精度,而COCO评价指标对精细尺度较为敏感。这是在关键点回归中独立观察到的。
Bounding box size weight
我们分析了我们的方法的灵敏度对于损失权重![]() 。表3b显示0.1给出了一个很好的结果。对于较大的值,由于损失范围从0到输出大小w/R或h/R,而不是0到1, AP显著降低。但是,对于较低的权重,该值不会显著降低。
。表3b显示0.1给出了一个很好的结果。对于较大的值,由于损失范围从0到输出大小w/R或h/R,而不是0到1, AP显著降低。但是,对于较低的权重,该值不会显著降低。
Training schedule
缺省情况下,我们训练140个epoch的关键点估计网络,90epoch的学习率下降。如果我们在降低学习率之前将训练时间加倍,性能将进一步增加1.1 AP(表3d),但代价是更长的训练计划。为了节省计算资源(和polar bears),我们在消融实验中使用了140个epoch,但与其他方法相比,DLA坚持使用230个epoch。最后,通过回归到多个目标大小,我们尝试了Center- Net的多个“anchor”版本。这些实验没有取得任何成功。见补充。
6.2. 3D detection
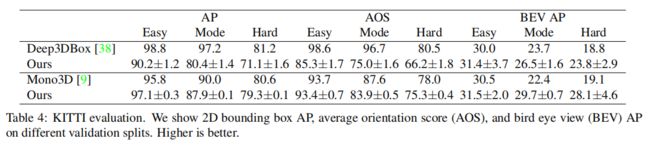
我们在KITTI数据集上进行了3D bounding box估计实验,该数据集包含一个驾驶场景中车辆的仔细标注的3D bounding box。KITTI包含7841幅训练图像,我们遵循文献[10,54]中的标准训练和验证分割。评估指标是在IOU阈值0.5时,在11 recalls 时汽车的average precision(0.0到1.0,增量为0.1),如对象检测[14]。我们基于2D bounding box(AP)、方向(AOP)和Bird-eye-view bounding box(BEV AP)评估IOUs。对于训练和测试,我们保持了原始图像分辨率和pad到1280*384。训练在70 epochs收敛,分别在45和60 epochs 学习率下降。我们使用DLA-34 backbone,并将深度、方向和大小的loss weight设置为1。其他超参数与检测实验一致。
由于召回阈值的数量非常小,验证AP的波动幅度最高可达10% AP。因此,我们训练5个模型,并报告带有标准差的平均值。
我们在它们具体的验证集中,对比了基于slow-RCNN的Deep3DBox[38]和基于Faster-RCNN的Mono3D[9]方法。如表4所示,我们的方法在AP和AOS中的性能与其他方法相当,在BEV中的性能略好。我们的CenterNet比这两种方法都快两个数量级。
 6.3. Pose estimation
6.3. Pose estimation
最后,我们在MS COCO数据集[34]中评估CenterNet对人体姿态的估计。我们评估关键点AP,它类似于bounding box AP,但用类似的带目标关键点的bounding box IoU替换了bounding box AP。在COCO测试开发中进行了测试,并与其他方法进行了比较。
我们对DLA-34和Hourglass-104进行了实验,它们都是经过中心点检测微调的。DLA-34在320个epoch(在8 gpu上大约3天)收敛,Hourglass-104在150个epoch(在5 gpu上8天)收敛。所有附加损失权重设置为1。所有其他超参数与目标检测相同。
结果如表5所示。直接回归到关键点性能合理,但不是最先进的。特别是在高的IOU下的表现挣扎。将我们的输出投影到最接近的联合检测中,可以改善整个结果,并与最先进的多人姿态估计器进行竞争[4,21,39,41]。这验证了CenterNet是通用的,容易适应新任务。
图5显示了所有任务的定性示例。
附录
附录A:模型架构

附录B:3D BBox 估计细节
我们网络输出图的深度 ![]() ,3d 维度
,3d 维度 ![]() ,方向编码
,方向编码 ![]() 。对于每个目标实例 k,我们在ground truth中心点位置从3个输出图(
。对于每个目标实例 k,我们在ground truth中心点位置从3个输出图(![]() )中提取输出值。将输出转换到绝对深度域后,用L1 loss训练深度:
)中提取输出值。将输出转换到绝对深度域后,用L1 loss训练深度:

其中 为groud truth绝对深度(单位:米)。同样,用绝对值度量L1 Loss训练3D尺寸:
为groud truth绝对深度(单位:米)。同样,用绝对值度量L1 Loss训练3D尺寸:

其中 是物体的高度,宽度和长度,单位为米。
是物体的高度,宽度和长度,单位为米。
方向θ默认是单标量。根据Mousavian等人[24,38]的研究,我们使用8标量编码来简化学习。这8个标量被分成两组,每组对应一个angular bin。一个bin对于角度在 ![]() ,另一个对于角度在
,另一个对于角度在 ![]() 。然后我们对于每个 bin 使用4 标量。在每个bin中,2个标量
。然后我们对于每个 bin 使用4 标量。在每个bin中,2个标量 ![]() 用于softmax分类(如果方向落在这个 bin i 中)。剩下的2个标量
用于softmax分类(如果方向落在这个 bin i 中)。剩下的2个标量 用于bin偏移(到 bin中心
用于bin偏移(到 bin中心 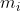 )的sin和cos值。即
)的sin和cos值。即 ![]() 用softmax进行分类训练,用L1 loss进行角度值训练:
用softmax进行分类训练,用L1 loss进行角度值训练:
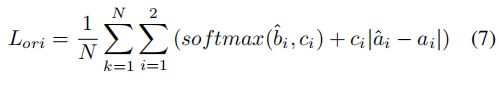
这里 ![]() 。1 是标志函数。预测方向 θ 由8个标量编码解码得到。
。1 是标志函数。预测方向 θ 由8个标量编码解码得到。

其中 j 为分类得分较大的 bin index。