PyTorch深度学习实践概论笔记1-概况
关于pytorch深度学习框架的学习,课程名称《PyTorch深度学习实践概论》,视频来源B站up主“刘二大人”。
课程封面

看看前言。

1 前言
深度学习框架学习的实践课程。第一讲介绍深度学习的概况,明确这是一个实践课,不会讲太多的数学知识,主要是讲怎么做出来。
PyTorch版本:0.4,目前最新1.10,跟着课程可以用1.0,1.2,1.5的应该也行(重点:要会看文档)大学学的课程总不是最新的(有的说法说高校课程落后于企业的实际需求,其实不是这样),最主要的原因是任何一项技术的发展曲线会是这样的:发展期-下降期-冰河期-应用期。
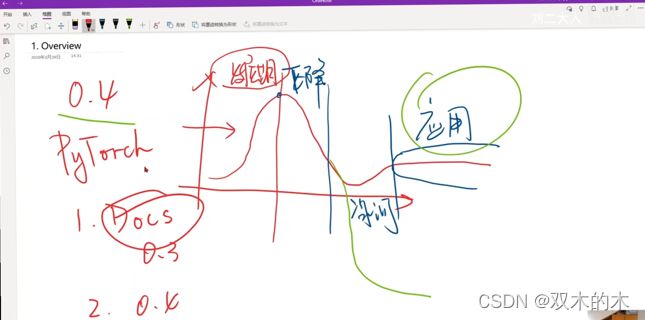
技术处于发展期,内部迭代会很快。如上图,一门技术需要经历发展期,下降期,冰河期,应用期,一门技术的出现在使用过程中,会出现个各种各样的问题和缺陷,就会陷入下降期。之后冰河期,很多技术在冰河期就会死掉,而熬过了冰河期,就是一门成熟的技术,达到了应用期,我们在大学所学的技术都是处于应用期的技术,已经非常稳定、实用,如果去学处于发展期的技术,这门技术如果在冰河期就死掉,这样学的东西就会真的没用。进入应用期的技术变化会非常平缓。
像C语言、Java都已经进入应用期。对于发展期的技术,不是这样的。前期还需要翻译英文文档。这就是为什么大学的课程不会像企业一样,去使用最新的技术。当然对于老师来说,可以研究一些新的框架。
2 课程目标(Goal of the tutorial)
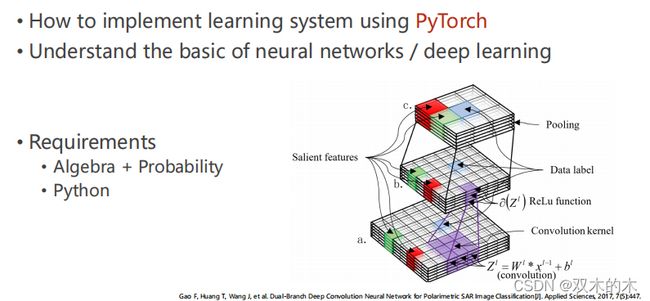
目标:
用pytorch实现一个学习系统
理解神经网络/深度学习的基本概念
要求:
线代+概率论数理统计(分布)
Python
3 人工智能(Human Intelligence)
下面先看几个人工智能的例子。例如,中午吃什么?
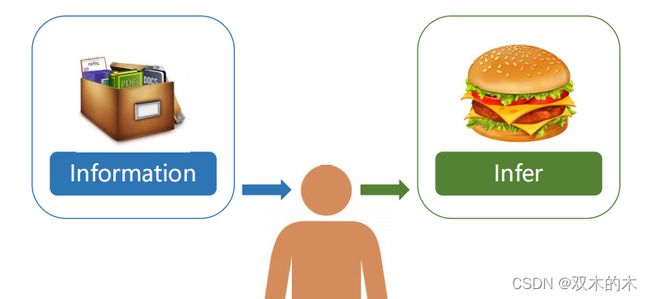
我们需要做决策。根据已经有的信息(information),来进行推理(infer)。例如,输入一张猫的图片(image),如何跟抽象的概念联系起来,“猫”,这是预测(prediction)。
3.1 机器学习(Machine learning)

把之前用来推理的大脑变成算法,用算法进行推理(外卖软件根据用户订餐习惯推送)。现在用的基本是监督学习(课程是之前的课程,现在不仅仅是监督学习)。
3.1.1 传统算法的思维方式:
- 穷举法:把所有的选择都列出来,看哪个符合条件
- 贪心法:每一步只选择从当前看来最好的选择(梯度下降就是用的贪心算法)
- 分治法:一分为二,快速排序就是用的分治算法
- 动态规划:把原问题分解成相对简单的子问题来求解复杂问题的方法
在机器学习里面,算法不是人为设计出来的,是首先有了数据集,我们要做的是从数据集里面把我们想要的算法找出来(机器学习算法来自于数据)。①建立模型②用数据验证,如果好用,就可以部署这个模型了。
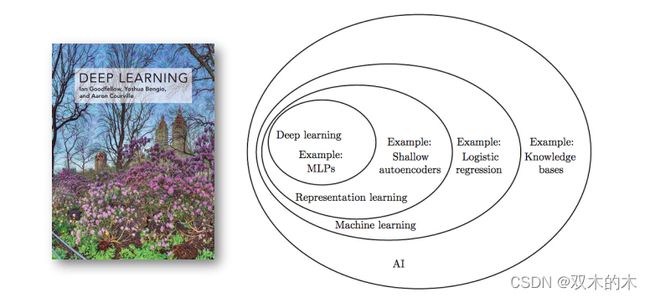
人工智能分支图
人工智能包括机器学习、机器视觉、自然语言处理等。深度学习属于表示学习(Representation learning)。深度学习仅仅是人工智能领域非常小的一个部分,深度学习从2012年开始变得越来越热门。
3.1.2 How to develop learning system?
老师讲解版:
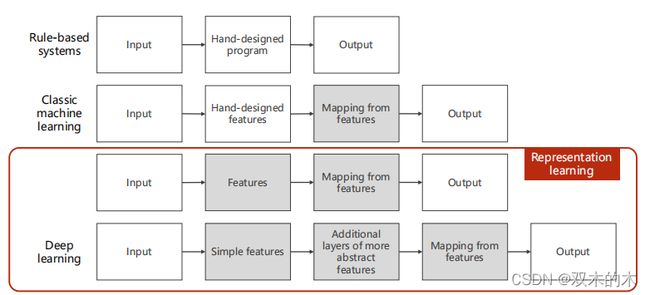
(1)基于规则的系统:获得输入,手工编写规则,获得输出(Ex:求导)。规则到后面会越来越多。
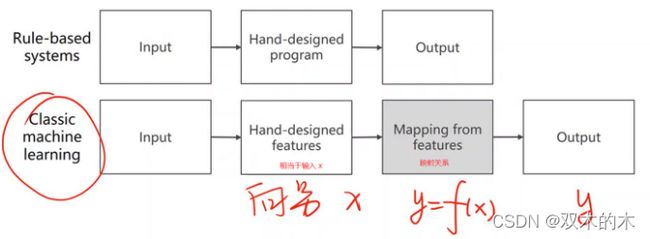
(2)经典机器学习算法:获得输入,手工提取特征(不管输入是什么,声音、文字、图片,我们把输入变成一个向量或者张量),然后把这个向量和输出之间建立一个映射的关系(线性模型,感知机,神经网络实际上都是在做这个工作)。
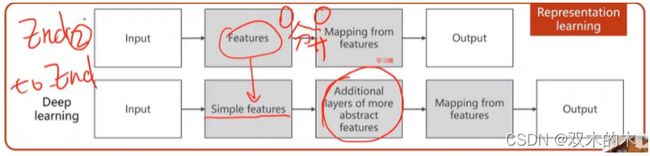
(3)表示学习算法:提取特征也由学习得到。早期的时候feature提取也是单独的算法。
维度诅咒(维度灾难):如果输入的每一个样本的特征越多,对整个样本的数量需求越多,假如数据只有一个feature,在对数据进行采样时(采样越多,和数据的真实分布越贴近),就是在一个一维空间采样,假设采10个样本,相当于采10个点,如果数据有2个特征,就是在二维空间采样,这时采10个样本就需要采100个点。如果在三维空间,需要1000个点。维度非常高时,对数据需求越大,但是收集数据本身工作量很大。
数据的需求越大,但是数据集的成本是很高的,尤其是打了标签的数据集,于是我们想到降低这个维度,但是我们想要在降低维度的同时保持高维空间的度量信息。比如把3维曲面的点投影到二维平面,降维最主要的原因是学习器面临着维度的诅咒,维度(特征)越多,对数据的需求越大,数据量越大,花钱越多。(Manifold流形)
(4)深度学习系统:直接把原始性的特征拿进来,比如输入是一张图片,那就把图片的像素值变成张量拿进来。如果输入是一段语音,那就把语音波形的序列拿进来,然后设计一层额外的层用于提取特征,然后接入学习器(多层神经网络),最后输出。
传统的方法里面feature和学习器是分开训练的,深度学习里面训练过程是统一的,因此深度学习的过程也叫做EndToEnd(端到端)的训练过程(从输入到输出构建一个非常大的模型,然后对整个模型进行训练)。
基于规则的系统和表示学习算法比较(Rule-based system VS Representation learning)

基于规则的系统的一些算法也是我们之前分析时学过的算法,或者改进。表示学习算法是从数据进行training。这是两者的差距。
3.1.3 传统的机器学习策略(Traditional machine learning strategy)
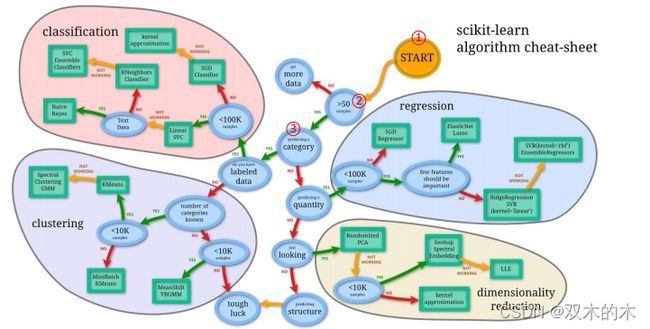
先判断样本数量,如果大于50接着进行;看是回归还是分类。
3.1.4 SVM的新挑战(New challenge)
下图柱状图上方的数字表示模型的错误率,越低表示模型效果越好。
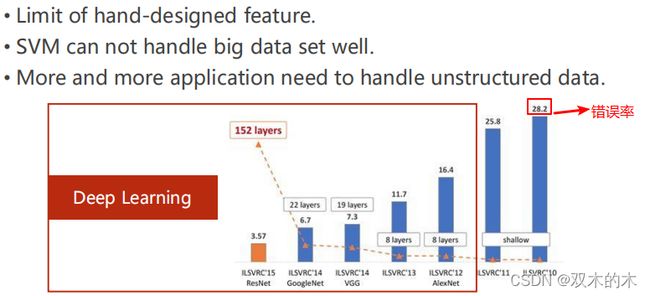
SVM(支持向量机)出现了如下一些挑战:
(1)人工设置特征有很多限制
(2)SVM处理大数据集时效果不好
(3)越来越多应用需要处理无结构数据
无结构数据:图像、声音、文本(对于这些无结构数据想要用SVM还得先做特征提取器)
IMAGENET Large Scale Visual Recognition Challenge(ILSVRC):大规模视觉识别竞赛
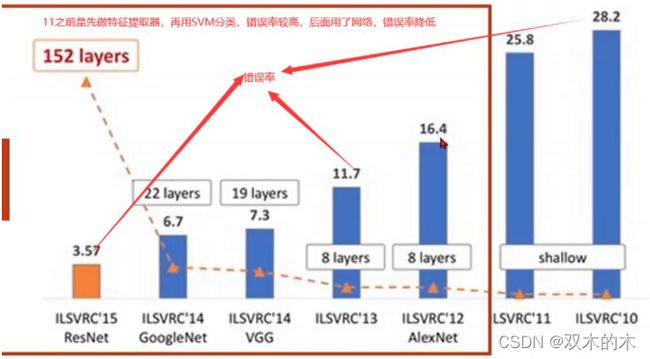
2012年也是深度学习神经网络绽放异彩的头一年,ResNet的3.57的错误率是什么概念呢,就是首次超过了人类的识别率,人类的识别错误率是5%。后来这个大赛再举办了几年就不再举办了,因为这个问题被视为已经解决的问题。
3.2 神经网络
3.2.1 Brief history of neural networks

下面简要介绍神经网络。神经网络来源是神经科学,现在的深度学习来自于数学与工程。(From neuroscience to mathematic & engineering)

(1)如上图所示,回到543million years以前,是Cambrain period(寒武纪)。寒武纪之前都是浮游生物,寒武纪的时候大部分生物进化出了类似眼睛的结构,具有了趋光性或者避光性,在物种进化中拥有更好的优势,激发了物种爆发。
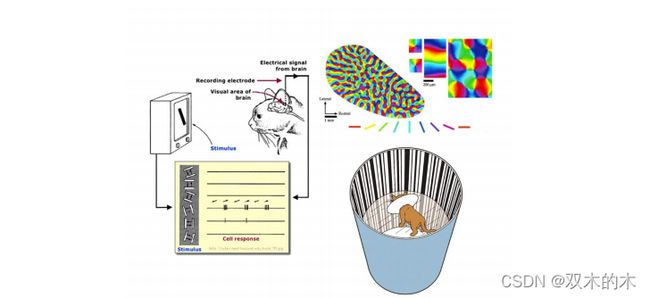
(2)如上图所示,1959年,做的猫的实验。Receptive fields of single neurones in the cat's striate cortex。发现神经元是分层的,这对神经网络影响非常深远。
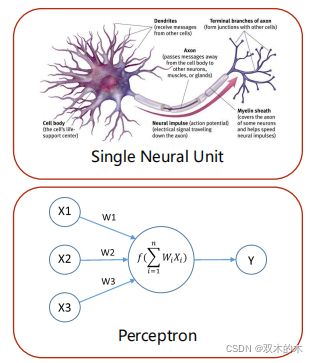
(3)如上图所示,感知机(Perceptron)就是用仿生学的方法构建一个神经元模型。
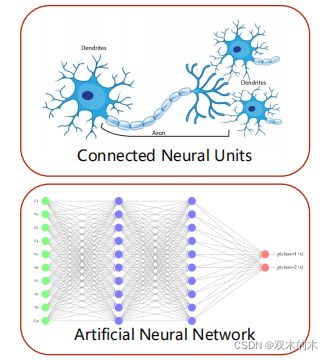
(4)如上图所示,后来,随着分层感知神经元的发现,开始把神经元连起来,得到人工神经网络(Artificial Neural Network)。
神经网络最重要的一个算法,让神经网络工作起来的算法:反向传播。
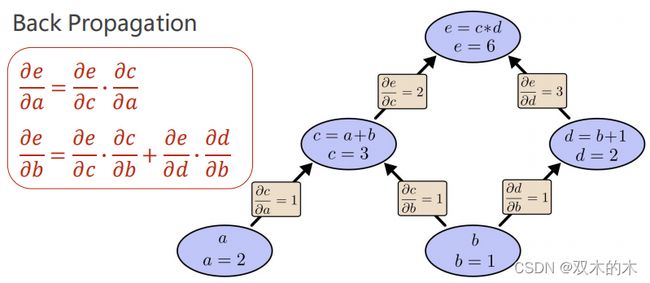
反向传播实际上是求偏导数,随着网络层数的增加,写解析式是很麻烦的,所以用反向传播求导数。反向传播的核心是:计算图(前向计算),a、b是输入(可以看做权重)。
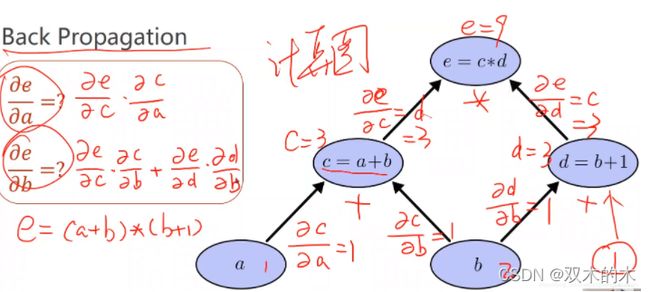
在前馈过程就可以先求出一些偏导。(主要是求导,链式法则)
(5)最早的深度学习模型:LeNet(1998)
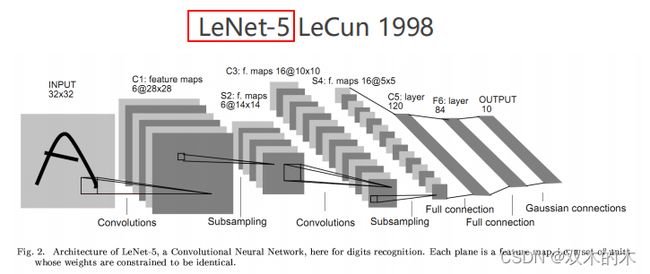
LeNet用来识别手写数字。

接着,AlexNet(2012)、Google&VGG(2014)、ResNet(2015)等。
神经网络模型非常多,关键不是要把所有的模型都学会,关键是学会构造模型的套路,然后构造自己的模型,学会基本快的实现,然后针对你的任务把他们组装起来,就像写代码一样,if语句,for循环。
3.2.2 深度学习的进展原因

①算法(Algorithm):深度学习算法越来越多
②数据(Data):数据集越来越丰富,数据量越来越大
③计算力提升(Computation):主要算力是英伟达的显卡
3.2.3 Good news

关于深度学习有一些好消息:
(1)深度学习并不难
(2)深度学习框架很多
(3)一些受欢迎的框架:Theano、TensorFlow、Caffe、Torch、PyTorch
这么课主要讲PyTorch。讲解PyTorch的原因?PyTorch出现的时候主打动态图,动态图就是计算的时候把图计算出来,计算完就把图释放,所以每一次可以构造出不同的图,对于写神经网络非常方便。学术界主打PyTorch,工业界用TensorFlow比较多,TensorFlow最新的版本现在也是动态图了。
3.3 PyTorch
3.3.1 What is PyTorch
pic-PyTorch是一个python包,自行下载安装。官网地址:PyTorch。
注意一下安装的时候没有显卡CUDA选None。如果有显卡,就先装CUDA,去英伟达的官网看该显卡支持的CUDA版本。如果安装CUDA之前装过visual studio,可能安装会出错,安装CUDA要选择自定义模板,同时要把visual studio支持去掉。
安装完成之后检查版本的代码:
import torch
print(torch.__version__)3.3.2 Why PyTorch

PyTorch的特点:
- 动态图
- 更多的网络模板
说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。