【Milvus的以文搜图】
0. 介绍
以文搜图指的是,根据文本描述,从图像数据库中检索与文本内容相似的图像数据并返回。通过在CSDN中搜索以文搜图,找到了如下两篇文章:
- 从零到一,教你搭建「以文搜图」搜索服务(一)_Zilliz Planet的博客-CSDN博客_以文搜图 搜索引擎技术
- 从零到一,教你搭建「CLIP 以文搜图」搜索服务(二):5 分钟实现原型_Zilliz Planet的博客-CSDN博客
这两篇文章的内容介绍了以文搜图的原理,以及如何使用Faiss来搭建以文搜图的应用。
与上述两篇文章不同,本文主要讲述如何基于Chinese-CLIP和Milvus来搭建一个以文搜图应用。
1. Chinese-CLIP
CLIP是OpenAI在2021年提出的多模态神经网络模型,该模型基于OpenAI 收集到的 4 亿对图像文本对进行训练,分别将文本和图像进行编码,之后使用 metric learning 进行权重,其目标是将图像与文本的相似性提高,大致如下图所示。具体内容不在本文赘述。
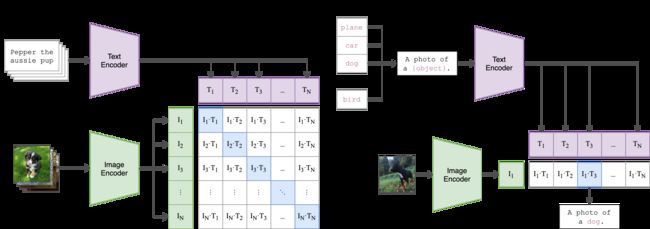
Chinese-CLIP是CLIP模型的中文版本,使用大规模的图文对进行训练得到,针对中文领域数据能够实现更好的效果。本文的以文搜图应用使用中文CLIP作为文本和图像的特征提取器,提取数据集中所有图像的特征作为数据库,用于检索。
1.1 安装中文CLIP
中文CLIP的README文件详细描述了如何安装、跨模态检索的Finetune、预测和评估,以及零样本分类等内容,本文主要基于该文件,进行相关实验。
依赖环境
安装中文CLIP库之前,需要满足如下环境配置:
- python >= 3.6.4
- pytorch >= 1.8.0 (with torchvision >= 0.9.0)
- CUDA Version >= 10.2
pip安装
# 通过pip安装
pip install cn_clip功能测试
通过下面的代码,可以验证中文CLIP库是否安装正确,主要内容是提取给定的图像和文本特征,并计算它们之间的相似度。
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
model, preprocess = load_from_name("RN50", \
device=device,
download_root="./")
model.eval()
# image preprocess
image_data = Image.open("examples/pokemon.jpeg")
infer_data = preprocess(image_data).unsqueeze(0).to(device)
# text data
text_data = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
# image_features = model.encode_image(infer_data)
# text_features = model.encode_text(text_data)
# # 对特征进行归一化,请使用归一化后的图文特征用于下游任务
# image_features /= image_features.norm(dim=-1, keepdim=True)
# text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(infer_data, text_data)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
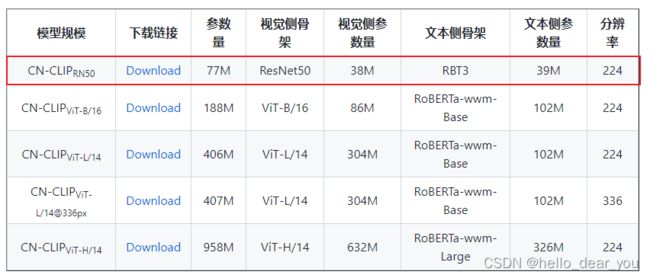
print("Label probs:", probs) 现阶段,中文CLIP提供5种不同规模的模型,如下图所示,上述例子使用了RN50,probs输出pookemon图像与4个文本之间的相似性。
1.2 提取图文特征
在README文件中,跨模态检索部分介绍了如何在下游数据集中对模型进行finetune、预测和评估模型性能。
本节中,主要内容是基于中文clip如何提取图文特征,即使用现有的预训练模型,不做finetune,对数据集进行推理,得到数据集图文特征文件。
准备数据集
按照介绍,为了提高效率,需要将数据集转换为tsv和jsonl格式的文件,然后将其转换为内存索引的LMDB数据库文件。为了简化实验的步骤,本文直接使用项目中提供的已经转换好的数据集,进行后续的实验,如下图所示,下载文件放到对应文件目录下。本文以Flickr30K-CN数据集进行实验。

文件结构如下所示:

图文特征提取
通过执行如下命令,能够完成对数据集中图像和文本的特征提取。
#!/bin/bash
# Usage: extract image and text features
# only supports single-GPU inference
export CUDA_VISIBLE_DEVICES=${1}
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
SPLIT=${2}
DATAPATH=${3}
RESUME=${DATAPATH}/pretrained_weights/clip_cn_rn50.pt
DATASET_NAME=Flickr30k-CN
python -u cn_clip/eval/extract_features.py \
--extract-image-feats \
--extract-text-feats \
--image-data="${DATAPATH}/datasets/${DATASET_NAME}/lmdb/${SPLIT}/imgs" \
--text-data="${DATAPATH}/datasets/${DATASET_NAME}/${SPLIT}_texts.jsonl" \
--img-batch-size=32 \
--text-batch-size=32 \
--context-length=52 \
--resume=${RESUME} \
--vision-model=RN50 \
--text-model=RBT3-chinese其中第一个参数是用于推理的GPU ID,第二参数DATAPATH指的数据存放的目录,split指的是train、test或者valid。图片特征保存于${split}_imgs.img_feat.jsonl文件,文本特征则保存于${split}_texts.txt_feat.jsonl。
KNN检索
在中文CLIP项目中,提供了一个简单的KNN检索,用来计算文到图、图到文检索的top-k召回结果,本文主要计算从文到图的检索结果,与后续使用Milvus进行检索的结果对比。
#!/bin/bash
# Usage: topK search
# only supports single-GPU inference
export CUDA_VISIBLE_DEVICES=${1}
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
SPLIT=${2}
DATAPATH=${3}
RESUME=${DATAPATH}/pretrained_weights/clip_cn_rn50.pt
DATASET_NAME=Flickr30k-CN
python -u cn_clip/eval/make_topk_predictions.py \
--image-feats="${DATAPATH}/datasets/${DATASET_NAME}/${SPLIT}_imgs.img_feat.jsonl" \
--text-feats="${DATAPATH}/datasets/${DATASET_NAME}/${SPLIT}_texts.txt_feat.jsonl" \
--top-k=10 \
--eval-batch-size=32768 \
--output="${DATAPATH}/datasets/${DATASET_NAME}/${SPLIT}_predictions.jsonl"结果保存到${split}_predictions.jsonl文件中,每行表示一个文本召回的top-k图片id,格式如下:
{"text_id": 153915, "image_ids": [5791244, 1009692167, 7454547004, 3564007203, 38130571, 2525270674, 2195419145, 2503091968, 4966265765, 3690431163]}至此,对于中文CLIP如何提取图像和文本特征有了大致的了解,接下来,将中文CLIP提取的图像特征存储到Milvus中,然后输入文本,CLIP提取文本特征,在图像数据库中检索得到topK个内容与文本相似的图像结果。
2. Milvus
如前面文章介绍,Milvus是一个向量数据库,基于深度学习网络提取的特征进行对象之间相似度计算,返回topK个相似的结果。
不同的检索任务,需要对milvus和mysql的数据内容进行设计,以及如何提取对象的特征是十分重要的。
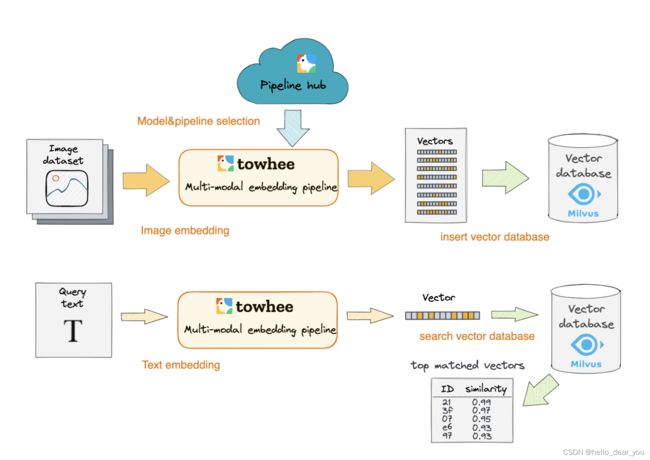
以文搜图的整体流程如上图所示,图片来自链接:
1. 构建图像特征库
图像数据集通过多模态模型提取特征,本文中使用中文CLIP多模态模型,然后将特征存储到Milvus中,用于后续的检索。
2. 文本检索
请求文本通过多模态模型提取特征,得到文本特征,然后从Milvus数据库中进行检索,得到topK个相似的内容。
2.1 构建特征提取网络
如下方的代码所示,基于中文CLIP构建一个特征提取类,使用extract_image_featuresh和extract_text_features提取图像和文本特征。
build_Flickr30kCN_image_db函数用于从第一部分生成的图像特征文件中提取图像ID和特征来构建图像数据库,用于后续的检索任务。
load_images函数用于提取图像ID和以base64编码的二进制图像数据,后续插入到MySQL中,检索时,返回相应的图像内容。
import torch
from PIL import Image
import os
import json
from tqdm import tqdm
import cn_clip.clip as clip
from cn_clip.clip import available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']
class Chinese_CLIP:
def __init__(self) -> None:
self.device = "cpu"
if torch.cuda.is_available():
self.device = "cuda"
self.splits = ["valid"]
self.model, self.preprocess = clip.load_from_name( "RN50", \
device=self.device,
download_root="./")
self.model.eval()
def extract_image_features(self, img_name): # for upload
image_data = Image.open(img_name).convert("RGB")
infer_data = self.preprocess(image_data)
infer_data = infer_data.unsqueeze(0).to(self.device)
with torch.no_grad():
image_features = self.model.encode_image(infer_data)
image_features /= image_features.norm(dim=-1, keepdim=True)
return image_features.cpu().numpy()[0] # [1, 1024]
def extract_text_features(self, text): # for search
text_data = clip.tokenize([text]).to(self.device)
with torch.no_grad():
text_features = self.model.encode_text(text_data)
text_features /= text_features.norm(dim=-1, keepdim=True)
return text_features.cpu().numpy()[0] # [1, 1024]
def build_Flickr30kCN_image_db(self, data_path): # for load
image_ids = list()
image_feats = list()
for split in self.splits:
image_path = os.path.join(data_path, split + "_imgs.img_feat.jsonl")
if not os.path.isfile(image_path):
print("error, file {} is not exist.".format(image_path))
continue
with open(image_path, "r") as fin:
for line in tqdm(fin, desc="build image {} part: ".format(split)):
obj = json.loads(line.strip())
image_ids.append(obj['image_id'])
image_feats.append(obj['feature'])
return image_ids, image_feats
def load_images(self, data_path): # for mysql
image_dicts = dict()
for split in self.splits:
file_path = os.path.join(data_path, split + "_imgs.tsv")
if not os.path.isfile(file_path):
print("error, file {} is not exist.".format(file_path))
with open(file_path, "r") as fin_imgs:
for line in tqdm(fin_imgs):
line = line.strip()
image_id, b64 = line.split("\t")
image_dicts[image_id] = b64.encode()
return image_dicts 2.2 设计collection
和其他任务一样,以文搜图任务的collection内容设计如下,milvus index是milvus生成的索引index,embedding是图像的特征。

def create_collection(self, collection_name): # 创建collection对象
# Create milvus collection if not exists
try:
if not self.has_collection(collection_name):
field1 = FieldSchema(name="id", dtype=DataType.INT64, descrition="int64", is_primary=True, auto_id=True)
field2 = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, descrition="float vector",
dim=VECTOR_DIMENSION, is_primary=False)
schema = CollectionSchema(fields=[field1, field2], description="collection description")
self.collection = Collection(name=collection_name, schema=schema)
LOGGER.debug(f"Create Milvus collection: {collection_name}")
else:
# utility.drop_collection(collection_name)
# self.create_collection(collection_name)
self.set_collection(collection_name)
return "OK"
except Exception as e:
LOGGER.error(f"Failed to create collection to Milvus: {e}")
sys.exit(1)2.3 设计MySQL表
与Milvus对应的,MySQL table的设计如下,milvus index是milvus生成的索引index,image id是图像对应的图像名,image data是base64编码后的二进制图像数据。

def create_mysql_table(self, table_name):
# Create mysql table if not exists
self.test_connection()
sql = "create table if not exists " + table_name + "(milvus_id TEXT, image_id TEXT, image_data MEDIUMBLOB not null );"
try:
self.cursor.execute(sql)
LOGGER.debug(f"MYSQL create table: {table_name} with sql: {sql}")
except Exception as e:
LOGGER.error(f"MYSQL ERROR: {e} with sql: {sql}")
sys.exit(1)
def load_data_to_mysql(self, table_name, data):
# Batch insert (Milvus_ids, img_path) to mysql
self.test_connection()
sql = "insert into " + table_name + " (milvus_id,image_id, image_data) values (%s,%s, %s);"
try:
self.cursor.executemany(sql, data)
self.conn.commit()
LOGGER.debug(f"MYSQL loads data to table: {table_name} successfully")
except Exception as e:
LOGGER.error(f"MYSQL ERROR: {e} with sql: {sql}")
sys.exit(1)2.4 构建图像数据库
在operations目录下的load文件的功能是构建图像特征库,本文是从第一部分的文件中解析得到图像ID和图像特征,并将其插入到milvus中,将图像id和图像数据插入MySQL中。
# Get the vector of images
def extract_features(data_path, model):
try:
image_ids, image_feats = model.build_Flickr30kCN_image_db(data_path)
print(f"Extracting feature from {len(image_ids)} images in total")
return image_ids, image_feats
except Exception as e:
LOGGER.error(f"Error with extracting feature from image {e}")
sys.exit(1)
# Combine the id of the vector and the name of the image into a list
def format_data(ids, image_ids, image_dicts):
data = []
for i in range(len(ids)):
value = (str(ids[i]), str(image_ids[i]), image_dicts[str(image_ids[i])])
data.append(value)
return data
# Import vectors to Milvus and data to Mysql respectively
def do_load(table_name, image_dir, model, milvus_client, mysql_cli):
if not table_name:
table_name = DEFAULT_TABLE
# 利用模型提取图像特征得到特征向量
image_ids, vectors = extract_features(image_dir, model)
ids = milvus_client.insert(table_name, vectors)
milvus_client.create_index(table_name)
image_dicts = model.load_images(image_dir)
mysql_cli.create_mysql_table(table_name)
mysql_cli.load_data_to_mysql(table_name, format_data(ids, image_ids, image_dicts))
return len(ids)2.5 文本检索
在operations目录下的search文件功能是根据给定的文本内容,执行图像检索,具体实现如下:
def do_search(table_name, text_content, top_k, model, milvus_client, mysql_cli):
try:
if not table_name:
table_name = DEFAULT_TABLE
features = model.extract_text_features(text_content)
vectors = milvus_client.search_vectors(table_name, [features], top_k)
vids = [str(x.id) for x in vectors[0]]
paths = mysql_cli.search_by_milvus_ids(vids, table_name)
distances = [x.distance for x in vectors[0]]
return paths, distances
except Exception as e:
LOGGER.error(f"Error with search : {e}")
sys.exit(1)2.6 配置文件
同样,需要修改config文件中collection名称和特征的维度。

3. FastApi服务端
在main文件中,由于任务发生了变化,因此需要对search条目的函数进行修改,输入文本内容,将输出的base64编码的图像数据解码保存下来。
@app.post('/img/search')
async def search_images( table_name: str = None, content: str = None, topk: int = Form(TOP_K)):
# Search the upload image in Milvus/MySQL
try:
shutil.rmtree(UPLOAD_PATH)
os.mkdir(UPLOAD_PATH)
paths, distances = do_search(table_name, content, topk, MODEL, MILVUS_CLI, MYSQL_CLI)
res = list()
for data, dist in zip(paths, distances):
image_path = os.path.join(UPLOAD_PATH, data["image_id"] + ".jpg")
with open(image_path, "wb") as f:
img_data = base64.b64decode(data["image_data"])
f.write(img_data)
res.append({
"distance": dist,
"image_id": image_path,
# "image_data": data["image_data"]
})
# res = sorted(res.items(), key=lambda item: item[1])
res.sort(key=lambda item: item["distance"])
LOGGER.info("Successfully searched similar images!")
return res
except Exception as e:
LOGGER.error(e)
return {'status': False, 'msg': e}, 400同样,使用uvicorn main:app --reload命令启动fastapi服务,在浏览器中进入docs页面。
3.1 构建图像数据库
进入/img/load条目,输入collection名称和图像特征文件存放的目录,执行。
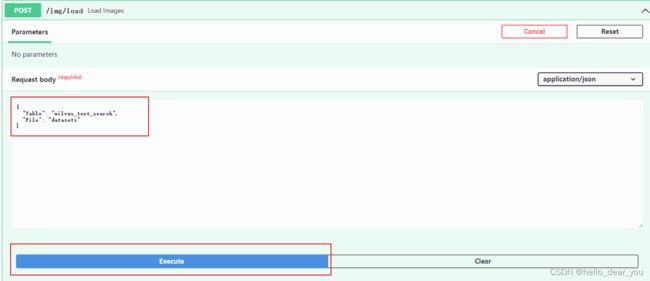
后台返回日志如下:

数据文件目录结果如下:

3.2 执行文本检索
本文以Flickr30k-CN数据集中valid子集作为实验,其中的一些文本描述如下:
{"text_id": 148915, "text": "这个小女孩穿着古怪的有条纹的裤子是图,你必须要问,这是更大的,她的脚和她的疲倦的微笑。", "image_ids": [104816788]}
{"text_id": 148916, "text": "一个熟睡的婴儿是在某人的手臂上,穿着一件粉红色条纹的衣服。", "image_ids": [104816788]}
{"text_id": 148917, "text": "一个熟睡的婴儿在一个粉红色的条纹衣服。", "image_ids": [104816788]}
{"text_id": 148918, "text": "在某人的怀里抱着一个小婴儿。", "image_ids": [104816788]}
{"text_id": 148919, "text": "一个小宝宝穿着紫色的裤子。", "image_ids": [104816788]}
{"text_id": 148920, "text": "一个穿着蓝色游泳裤的男孩在水里滑了一个黄色的幻灯片,在水里漂浮着充气玩具。", "image_ids": [1077546505]}
{"text_id": 148921, "text": "一个孩子正从一个漂浮在水面上的彩色气球上掉下来。", "image_ids": [1077546505]}
{"text_id": 148922, "text": "一个男孩在一个池塘里滑了一个彩色的管子。", "image_ids": [1077546505]}
{"text_id": 148923, "text": "一个穿着蓝色短裤的男孩在一个游泳池里滑了一个幻灯片。", "image_ids": [1077546505]}
{"text_id": 148924, "text": "一个男孩骑到一个小后院游泳池。", "image_ids": [1077546505]}
{"text_id": 148925, "text": "两家人正在厨房准备食物。", "image_ids": [1079013716]}
{"text_id": 148926, "text": "厨师为顾客准备汉堡。", "image_ids": [1079013716]}
{"text_id": 148927, "text": "两家厨师在餐厅厨房准备汉堡。", "image_ids": [1079013716]}
{"text_id": 148928, "text": "两家人在厨房准备食物。", "image_ids": [1079013716]}
{"text_id": 148929, "text": "厨房烹饪中的2个厨师。", "image_ids": [1079013716]}在search条目中,使用如上的一个描述进行检索
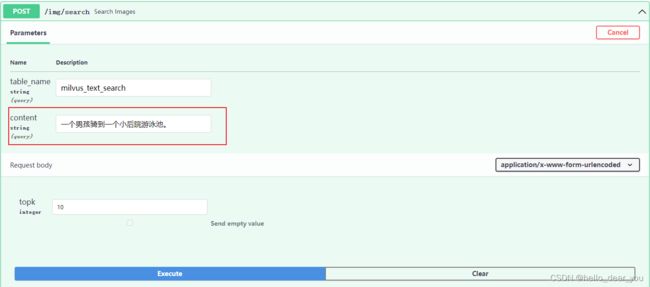
返回的topK结果如下:
![]()
3.3 结果对比
通过对比milvus返回的结果和中文CLIP项目中KNN检索的结果,来判断检索的正确性。找到上述文本对应的text ID,在valid_predictions.jsonl文件中,找到对应的topK个Image ID。
KNN 检索结果:
{"text_id": 148924, "image_ids": [989754491, 2508918369, 1077546505, 154094533, 4637950362, 1131340021, 3621652774, 1100214449, 811663364, 2687539673]}Milvus返回的结果:
[
{
"distance": 0.8329496383666992,
"image_id": "tmp/search-images/989754491.jpg"
},
{
"distance": 0.8518763780593872,
"image_id": "tmp/search-images/2508918369.jpg"
},
{
"distance": 0.8582218885421753,
"image_id": "tmp/search-images/1077546505.jpg"
},
{
"distance": 0.8794834613800049,
"image_id": "tmp/search-images/154094533.jpg"
},
{
"distance": 0.8805474638938904,
"image_id": "tmp/search-images/4637950362.jpg"
},
{
"distance": 0.8876401782035828,
"image_id": "tmp/search-images/1131340021.jpg"
},
{
"distance": 0.8878381848335266,
"image_id": "tmp/search-images/3621652774.jpg"
},
{
"distance": 0.8895268440246582,
"image_id": "tmp/search-images/1100214449.jpg"
},
{
"distance": 0.8895866870880127,
"image_id": "tmp/search-images/811663364.jpg"
},
{
"distance": 0.9175957441329956,
"image_id": "tmp/search-images/2687539673.jpg"
}
]通过对比,可以发现两者之间的结果一致。
4. 总结
本文,基于中文CLIP和Milvus简单实现以文搜图应用,使用Flickr30k-CN数据集中valid子集作为实验,FastAPI构建可交互的接口,完成小规模的文本检索图像功能。