torch.nn.Conv1d,torch.nn.Conv2d和torch.nn.Conv3d的应用和相关计算
0. CNN处理的一维、二维和三维数据
CNN最常用于处理二维的图片数据,但是也可以用于处理一维和三维的数据。
处理不同维度数据的输入输出形式如下所示:
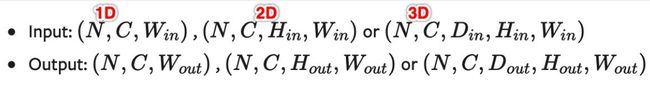
(1)一维数据
一维数据常见的是时序数据,如下图
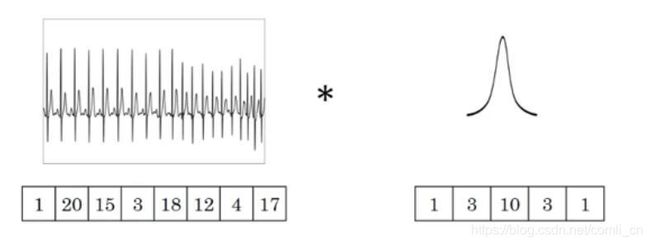 一维输入 ( N , C , W i n ) (N, C, W_{in}) (N,C,Win)中的 N N N代表batch size, C C C代表通道的数量, W W W代表信号序列的长度。
一维输入 ( N , C , W i n ) (N, C, W_{in}) (N,C,Win)中的 N N N代表batch size, C C C代表通道的数量, W W W代表信号序列的长度。
(2)二维数据
二维数据常见的是图片数据,如下图:
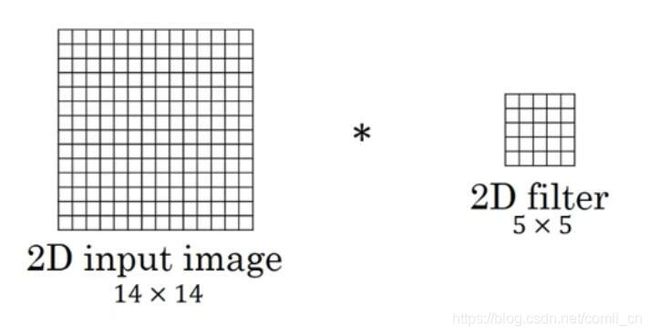 二维输入 ( N , C , H i n , W i n ) (N, C, H_{in}, W_{in}) (N,C,Hin,Win)中的 N N N代表batch size, C C C代表通道的数量, H i n H_{in} Hin是输入的二维数据的像素高度, W_{in}是输入的二维数据的像素宽度。
二维输入 ( N , C , H i n , W i n ) (N, C, H_{in}, W_{in}) (N,C,Hin,Win)中的 N N N代表batch size, C C C代表通道的数量, H i n H_{in} Hin是输入的二维数据的像素高度, W_{in}是输入的二维数据的像素宽度。
(3)三维数据
三维数据常见的是点云数据,如下图:
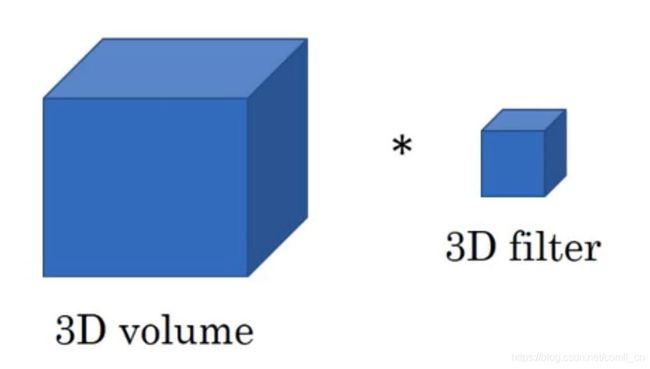 三维输入 ( N , C , D i n , H i n , W i n ) (N, C,D_{in}, H_{in}, W_{in}) (N,C,Din,Hin,Win)中的 N N N代表batch size, C C C代表通道的数量, D i n D_{in} Din代表三维数据的深度, H i n H_{in} Hin是输入的三维数据的高度, W_{in}是输入的三维数据的宽度。
三维输入 ( N , C , D i n , H i n , W i n ) (N, C,D_{in}, H_{in}, W_{in}) (N,C,Din,Hin,Win)中的 N N N代表batch size, C C C代表通道的数量, D i n D_{in} Din代表三维数据的深度, H i n H_{in} Hin是输入的三维数据的高度, W_{in}是输入的三维数据的宽度。
1. torch.nn.Conv1d和MaxPool1d
Conv1d()函数就是利用指定大小的一维卷积核对输入的多通道一维输入信号进行一维卷积操作的卷积层。
函数:
class torch.nn.Conv1d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True)
∙ \bullet ∙ in_channels (int) – 输入通道个数。
∙ \bullet ∙out_channels (int) – 输出通道个数 。有多少个out_channels,就需要多少个一维卷积(也就是卷积核的数量)
∙ \bullet ∙ kernel_size(int or tuple) – 卷积核的尺寸;卷积核的第二个维度由in_channels决定,所以实际上卷积核的大小为kernel_size * in_channels
∙ \bullet ∙stride (int or tuple, optional) – 卷积操作的步长。 默认:1
∙ \bullet ∙ padding (int or tuple, optional) – 输入数据各维度各边上要补齐0的层数。 默认: 0
∙ \bullet ∙ dilation (int or tuple, optional) – 卷积核各元素之间的距离。 默认: 1
∙ \bullet ∙groups (int, optional) – 输入通道与输出通道之间相互隔离的连接的个数。 默认:1
∙ \bullet ∙bias (bool, optional) – 如果被置为True,向输出增加一个偏差量,此偏差是可学习参数。 默认:True
torch.nn.Conv1d只对最后一维 W i n W_{in} Win进行卷积操作,具体的计算方法为:
W o u t = ( ( W i n − k e r n e l S i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 ) / p o o l K e r n e l S i z e W_{out}=((W_{in}-kernelSize+2*padding)/stride+1)/poolKernelSize Wout=((Win−kernelSize+2∗padding)/stride+1)/poolKernelSize
MaxPool1d只对输入的最后一维进行最大池化:
比如使用nn.MaxPool1d(kernel_size=2)会使得最后一维的输出维数减半。
2. torch.nn.Conv2d和MaxPool2d
该函数是利用指定大小的二维卷积核对输入的多通道二维输入信号进行二维卷积操作的卷积层。
class torch.nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True)
两个维度的计算方法一样:
W o u t = ( ( W i n − k e r n e l S i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 ) / p o o l K e r n e l S i z e W_{out}=((W_{in}-kernelSize+2*padding)/stride+1)/poolKernelSize Wout=((Win−kernelSize+2∗padding)/stride+1)/poolKernelSize
用MaxPool2d会对输入的最后两维都进行最大池化。
2. torch.nn.Conv3d和MaxPool3d
class torch.nn.Conv3d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True)
三个维度的计算方法一样:
W o u t = ( ( W i n − k e r n e l S i z e + 2 ∗ p a d d i n g ) / s t r i d e + 1 ) / p o o l K e r n e l S i z e W_{out}=((W_{in}-kernelSize+2*padding)/stride+1)/poolKernelSize Wout=((Win−kernelSize+2∗padding)/stride+1)/poolKernelSize
用MaxPool3d会对输入的最后三维都进行最大池化。