论文复现——MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
本次复现的论文是前几天谷歌团队开发出来的MOAT,目前还没有开源,我复现的代码可以在ImageNet或自己的数据集上训练,支持apex混合精度,各种图像增强技术等。
原论文:https://arxiv.org/pdf/2210.01820.pdf
复现的代码:https://github.com/RooKichenn/pytorch-MOAT
文章目录
- 一、MOAT整体结构
- 二、MBConv结构
-
- 导入需要的库
- 纯MBConv结构
- MOAT中的MBConv
- 三、MOAT中的attention结构
一、MOAT整体结构
MOAT Block:
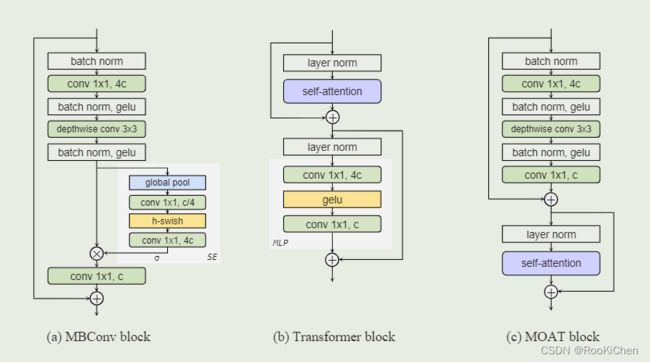
MOAT-1的整体架构
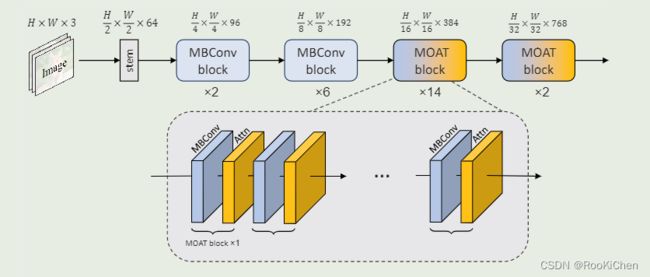
MOAT用MBconv代替了它的MLP,把MBconv放在self-attention前,去掉了MLP。MBconv不仅可以增强网络的特征表达能力,而且还能带来更好的下采样能力。由于MBconv在像素之间(从而跨窗口)有效地交换局部信息,因此MOAT不需要额外的window-shifting,并且原论文说明了并没有使用窗口注意力机制,也就是说不像Swing Transformer那样使用复杂的位移窗口机制来让每个窗口之间进行交互,但是不使用窗口注意力机制会增大计算量和训练速度,我认为这里是一个可以改进的点。作者在文中也说出了他们的期望:We hope our study will inspire future research on seamless integration of convolution and self-attention.(我们希望我们的研究能够启发未来关于卷积和自注意力无缝集成的研究) ,所以后续可以在MOAT的基础进行一些改进,水篇论文还是可以的(手动狗头)。
作者对MBConv和self-attention中的MPL进行了深度分析,提出了MOAT:
首先,Transformer中的MLP模块类似于MBConv,都采用了倒瓶颈设计。然而,MBConv是一种更强大的操作,通过使用额外的3×3深度卷积(以编码像素之间的局部交互),并且在卷积之间使用更多的激活和归一化。
其次,为了使用Transformer block提取多尺度特征,可以将AvgPool(步长为2)应用于自我关注层之前的输入特征。然而,AvgPool操作降低了self-attention的表征能力。
基于上述现象,提出了MOAT block,首先将MLP替换为MBConv,然后颠倒self-attention和MBConv的顺序。用MBConv替换MLP为网络带来了更多的特征表示能力,并且颠倒顺序(MBConv先于self-attention)将下采样任务交给MBConv内的depthwise,从而学习更好的下采样核。通过这种方式,MOAT不需要像 CoAtNet 中的平均池化这样的额外下采样层,也不需要 Swin Transformer和ConvNeXt 中的patch-embedding layers。
关于文中的MBConv和self-attntion就不再做过多的解释了,下面主要说一下自己实现每个模块的思路。
二、MBConv结构
MOAT中有两种MBConv结构,一种是带SE模块的纯MBConv和一种不带SE模块的MOAT结构,这里首先给出纯MBConv的实现代码:
导入需要的库
from typing import Type, Callable, Tuple, Optional, Set, List, Union
import torch
import torch.nn as nn
from timm.models.efficientnet_blocks import SqueezeExcite, DepthwiseSeparableConv
from timm.models.layers import drop_path, trunc_normal_, Mlp,
纯MBConv结构
class MBConvBlock(nn.Module):
"""
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of output channels.
downscale (bool, optional): If true downscale by a factor of two is performed. Default: False
act_layer (Type[nn.Module], optional): Type of activation layer to be utilized. Default: nn.GELU
norm_layer (Type[nn.Module], optional): Type of normalization layer to be utilized. Default: nn.BatchNorm2d
drop_path (float, optional): Dropout rate to be applied during training. Default 0.
"""
def __init__(
self,
in_channels: int,
out_channels: int,
downscale: bool = False,
act_layer: Type[nn.Module] = nn.GELU,
norm_layer: Type[nn.Module] = nn.BatchNorm2d,
drop_path: float = 0.,
expand_ratio: int = 4.,
use_se=False,
) -> None:
""" Constructor method """
# Call super constructor
super(MBConvBlock, self).__init__()
# Save parameter
self.drop_path_rate: float = drop_path
if not downscale:
assert in_channels == out_channels, "If downscaling is utilized input and output channels must be equal."
if act_layer == nn.GELU:
act_layer = _gelu_ignore_parameters
# Make main path
self.main_path = nn.Sequential(
norm_layer(in_channels),
DepthwiseSeparableConv(in_chs=in_channels,
out_chs=int(out_channels * expand_ratio // 2) if downscale else int(
out_channels * expand_ratio),
stride=2 if downscale else 1,
act_layer=act_layer, norm_layer=norm_layer, drop_path_rate=drop_path),
SqueezeExcite(
in_chs=int(out_channels * expand_ratio // 2) if downscale else int(out_channels * expand_ratio),
rd_ratio=0.25) if use_se else nn.Identity(),
nn.Conv2d(
in_channels=int(out_channels * expand_ratio // 2) if downscale else int(out_channels * expand_ratio),
out_channels=out_channels, kernel_size=(1, 1))
)
# Make skip path
self.skip_path = nn.Sequential(
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 1))
) if downscale else nn.Identity()
def forward(
self,
input: torch.Tensor
) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H (// 2), W (// 2)] (downscaling is optional).
"""
output = self.main_path(input)
if self.drop_path_rate > 0.:
output = drop_path(output, self.drop_path_rate, self.training)
output = output + self.skip_path(input)
return output
这里我直接使用了timm库中封装好的MBConv组件,没什么特别的地方。
MOAT中的MBConv
SqueezeExcite(
in_chs=int(out_channels * expand_ratio // 2) if downscale else int(out_channels * expand_ratio),
rd_ratio=0.25) if use_se else nn.Identity(),
在MBConv中我加入了use_se来判断是否需要SE模块。
三、MOAT中的attention结构
class MOATAttnetion(nn.Module):
def __init__(
self,
in_channels: int,
partition_function: Callable,
reverse_function: Callable,
img_size: Tuple[int, int] = (224, 224),
num_heads: int = 32,
window_size: Tuple[int, int] = (7, 7),
use_window: bool = False,
attn_drop: float = 0.,
drop: float = 0.,
drop_path: float = 0.,
norm_layer: Type[nn.Module] = nn.LayerNorm,
) -> None:
""" Constructor method """
super(MOATAttnetion, self).__init__()
# Save parameters
self.use_window = use_window
self.partition_function: Callable = partition_function
self.reverse_function: Callable = reverse_function
if self.use_window:
self.window_size: Tuple[int, int] = window_size
else:
self.window_size: Tuple[int, int] = img_size
# Init layers
self.norm_1 = norm_layer(in_channels)
self.attention = RelativeSelfAttention(
in_channels=in_channels,
num_heads=num_heads,
window_size=self.window_size,
attn_drop=attn_drop,
drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, input: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
input (torch.Tensor): Input tensor of the shape [B, C_in, H, W].
Returns:
output (torch.Tensor): Output tensor of the shape [B, C_out, H, W].
"""
# Save original shape
B, C, H, W = input.shape
if self.use_window:
# Perform partition
input_partitioned = self.partition_function(input, self.window_size)
input_partitioned = input_partitioned.view(-1, self.window_size[0] * self.window_size[1], C)
# Perform normalization, attention, and dropout
output = input_partitioned + self.drop_path(self.attention(self.norm_1(input_partitioned)))
# Reverse partition
output = self.reverse_function(output, (H, W), self.window_size)
else:
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
input_partitioned = input.flatten(2).transpose(1, 2).contiguous()
output = input_partitioned + self.drop_path(self.attention(self.norm_1(input_partitioned)))
output = output.transpose(1, 2).contiguous().view(B, C, H, W)
return
我在自注意力机制中加入了use_window来判断是否需要窗口注意力机制(原论文中为使用窗口注意力机制)
if self.use_window:
self.window_size: Tuple[int, int] = window_size
else:
self.window_size: Tuple[int, int] = img_size
MOAT中使用的是加了相对位置编码的注意力机制,具体可以去看看原论文给出的文献。
#四、训练策略
由于代码是纯复现,github中给出的参数都是我自己调的,可能不是最优参数,欢迎大家进行调参,给出最优参数。
论文中使用的总batch是4096,咱也没这条件,最大的总batch我用的是512,学习率是8e-4,训练300轮,具体参数可以去参考我复现的代码:https://github.com/RooKichenn/pytorch-MOAT,欢迎star!