PyTorch深度学习实践概论笔记9-SoftMax分类器
上一讲PyTorch深度学习实践概论笔记8-加载数据集中,主要介绍了Dataset 和 DataLoader是加载数据的两个工具类。这一讲介绍多分类问题如何解决,一般会用到SoftMax分类器。

0 Revision
0.1 Revision: Diabetes dataset

在之前的糖尿病数据集中进行了二分类,只有输出P(y=1),另一个概率就等于1-P(y=1)。
0.2 Revision: MNIST Dataset

在MNIST数据集中,有10种不同的分类标签,我们如何用SoftMax分类器来实现分类?
2 Design Neural Network
2.1 Design 10 outputs using Sigmoid?

第一种设计方式是改变输出,变成10个输出,每一个输出代表样本属于对应类的概率。这样的方法相当于把每个类分别看成二分类,但是会出现一个问题,各个类别之间的概率没有直接的联系,不好给出明确的预测。我们更希望输出服从一个分布,满足:
- 输出的概率大于等于0
- 输出的概率之和等于1
2.2 Output a Distribution of prediction with Softmax
所以在处理多分类问题时,前面的层还是采用Sigmoid,最后一层输出的时候采用Softmax层。

多分类问题用SoftMax分类器要求输出的分类概率都大于0且总和为1,把输出经过sigmoid层就可以。
2.2.1 Softmax Layer
接下来看看Softmax层的定义。假设Z^l是最后一个线性层的输出,则Softmax函数为:

老师讲解版:

2.2.2 Softmax Layer-Example
看一个具体栗子。

经过线性变换之后有0.2,0.1和-0.1三个数值,用上述的公式进行计算,得到输出0.38,0.34和0.28(对应的是概率值)。
接下来看看用Softmax分类器,损失函数怎么求?
2.2.3 Loss function-Cross Entropy

对于多分类的损失函数是上面的公式,名称叫Negative Log Likelihood Loss。
那么要实现这个计算过程,该如何操作呢?
2.2.4 Cross Entropy in Numpy
先看在Numpy中如何计算。

代码如下:
import numpy as np
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum() #softmax
loss = (- y * np.log(y_pred)).sum()
print(loss) #0.97291891312565842.2.5 Cross Entropy in PyTorch
再看看在PyTorch中如何计算。
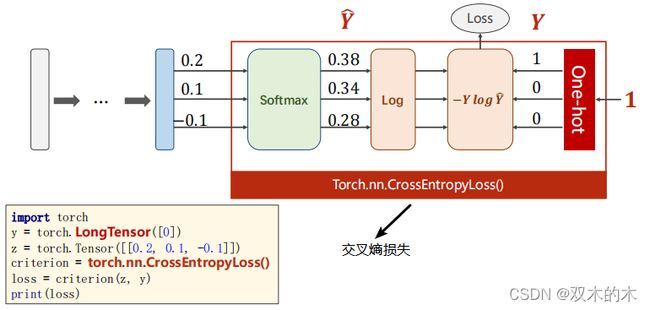
torch.nn.CrossEntropyLoss()相当于LogSoftmax+NLLLoss。代码如下:
import torch
y = torch.LongTensor([0])#长整型张量
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()#相当于LogSoftmax+NLLLoss
loss = criterion(z, y)
print(loss) #tensor(0.9729)上图的交叉熵损失就包含了softmax计算和右边的标签输入计算(即框起来的部分),所以在使用交叉熵损失的时候,神经网络的最后一层是不要做激活的,因为把它做成分布的激活是包含在交叉熵损失里面的,最后一层不要做非线性变换,直接交给交叉熵损失。
Mini-Batch: batch_size=3
结合mini-batch,当batch size=3时有如下操作:

代码分析:
import torch
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1]) #tensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.1]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
l1 = criterion(Y_pred1, Y)
l2 = criterion(Y_pred2, Y)
print("Batch Loss1 = ", l1.data, "\nBatch Loss2=", l2.data)输出结果:
Batch Loss1 = tensor(0.4966)
Batch Loss2= tensor(1.2389)3 Exercise 9-1: CrossEntropyLoss vs NLLLoss
练习:

ref:https://pytorch.org/docs/stable/nn.html#crossentropyloss
ref:https://pytorch.org/docs/stable/nn.html#nllloss
练习的解答之后会出(具体看评论)。
4 Back to MNIST Dataset
接下来我们回到MNIST数据集。

上述图像大小是28*28的,像素为784,图像对应右侧的28*28矩阵。
4.1 Implementation

接下来看代码如何实现,这里第4步加上测试。
4.1.0 Implementation – 0. Import Package

代码如下:
#0.导库
import torch
#构建DataLoader的库
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
#使用函数relu()的库
import torch.nn.functional as F
#构建优化器的库
import torch.optim as optim4.1.1 Implementation – 1. Prepare Dataset
第1步:准备数据集。

和之前相比,上述代码多了transform属性, transforms.ToTensor()是将PIL图像转化成Tensor。

如上图所示,transform代码将0-255压缩到0-1,将单通道变成多通道(1x28x28)。
代码如下:
#1.准备数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), #将PIL图像转化成Tensor
transforms.Normalize((0.1307, ), (0.3081, )) #正则化,归一化,0.1307是均值,0.3081是标准差,这两个值是根据所有数据集算出来的
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)4.1.2 Implementation – 2. Design Model
第2步:设计模型。这里激活层做了一些改变,改成ReLU,最后一层不做激活。输入是(N,1,28,28)4维的,但是需要转换,使用view()转变成一阶张量。

代码如下:
#2.设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) #注意最后一层不做激活
model = Net()4.1.3 Implementation – 3. Construct Loss and Optimizer
第3步:构造损失函数和优化器。

代码如下:
#3.构造损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)4.1.4 Implementation – 4. Train and Test
第4步:训练和测试过程。


代码如下:
#4.训练
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
# running_loss = 0.0
#4.测试
def test():
correct = 0
total = 0
with torch.no_grad():#测试时不会计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) #沿着维度1取最大值的下标
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()老师的输出结果:

我的输出结果:

可以看到test的准确率在上升,但是到一定程度之后不再上升。因为全连接层对图像处理不太友好,后续做特征提取效果会好一些(人工的方法:例如傅里叶变换FFT、小波变换;自动的提取:CNN等)。
这一段MNIST数据集的完整代码如下(可跑通):
#0.导库
import torch
#构建DataLoader的库
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
#使用函数relu()的库
import torch.nn.functional as F
#构建优化器的库
import torch.optim as optim
#1.准备数据集
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), #将PIL图像转化成Tensor
transforms.Normalize((0.1307, ), (0.3081, )) #正则化,归一化,0.1307是均值,0.3081是标准差,这两个值是根据所有数据集算出来的
])
train_dataset = datasets.MNIST(root='../datasets/data/',
train=True,
download=False,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../datasets/data/',
train=False,
download=False,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
#2.设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) #注意最后一层不做激活
model = Net()
#3.构造损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#4.训练过程
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
#4.测试过程
def test():
correct = 0
total = 0
with torch.no_grad():#测试时不会计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) #沿着维度1取最大值的下标
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()5 Exercise 9-2: Classifier Implementation
练习9-2:找到kaggle的这个数据集做多分类
Dataset ref:https://www.kaggle.com/c/otto-group-product-classification-challenge/data
(练习后续补上,请看评论。)
说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。