Reverse Attention的代码理解
目录
- 前言
- 1. REA模块的代码实现
- 2. REA模块在CFF模块中的调用
- 3. CFF模块在OSFormer中的调用
- 4.疑问分析
- 4. 下一步计划
- 参考
前言
通过溯源Reverse Attention的论文,对反向注意力机制有了初步的了解。但是,仅仅通过论文很多细节的东西是没办法看到的,还是有很多疑问,这就需要阅读代码去理解。
- 输入REA模块的不同层级的特征图(T4、T3、C2)是否和之前的Reverse Attention一样经过了上采样?
- REA模块的输出边缘特征图 F e F_e Fe最终输出到了哪里?是否和之前的Reverse Attention一样与不同层级的REA输出相加到了一起?
- 通过侵蚀实例掩码标签来获得边缘标签是怎么实现的?
- Edge loss是怎么进行计算的?原论文中3.5节提到, L e d g e = ∑ j = 1 J L d i c e ( j ) L_{edge}=\sum_{j=1}^{J}L_{dice}^{(j)} Ledge=∑j=1JLdice(j)。那么, L d i c e L_{dice} Ldice又是什么?是V-Net论文中提到的Dice loss吗?那Dice loss有什么特别之处呢?这与之前的Reverse Attention所用的损失函数有什么区别?
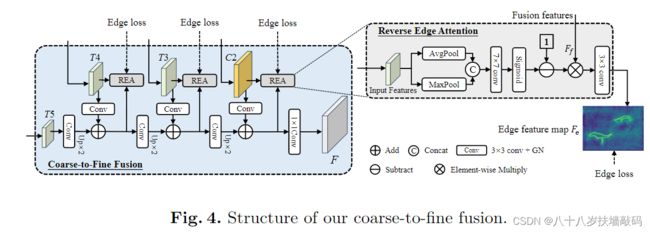
OSFormer模型的搭建代码一共由4个类组成:OSFormer()、CISTransformerHead()、C2FMaskHead()、ReverseEdgeSupervision()。其中,涉及到反向边缘注意力的主要是C2FMaskHead()和ReverseEdgeSupervision()。
1. REA模块的代码实现
class ReverseEdgeSupervision(nn.Module):
def __init__(self, chn):
super().__init__()
self.edge_pred = nn.Conv2d(
chn, 1,
kernel_size=3, stride=1,
padding=1, bias=False)
self.conv1 = nn.Conv2d(2, 1, kernel_size=7, padding=3, bias=False)
def forward(self, feat_fuse, feat_high):
avg_high = torch.mean(feat_high, dim=1, keepdim=True)
max_high, _ = torch.max(feat_high, dim=1, keepdim=True)
x = torch.cat([avg_high, max_high], dim=1)
x = 1 - self.conv1(x).sigmoid()
fuse = feat_fuse * x
return self.edge_pred(fuse)
通过forward()前向传播函数可以看到,参数feat_high代表输入的特征图Input Features。对于feat_high先按照行求平均值,返回形状(行数,1);再对feat_high按照行求最大值,返回形状(行数,1)。将二者通过torch.cat()函数按行拼接,得到形状(行数,2)的tensor向量。然后使用(输入通道数=2,输出通道数=1,卷积核大小= 7 × 7 7 \times 7 7×7,填充=3)的卷积核conv1进行卷积。然后通过sigmoid()函数后,进行翻转,得到x。将x与feat_fuse(也就是图中的Fusion Features)进行元素乘法,再通过一个(输入通道数=chn,输出通道数=1,卷积核大小= 3 × 3 3 \times 3 3×3,步距=1,填充=1)的卷积核edge_pred进行输出,也就是输出边缘特征图 F e F_e Fe。
ReverseEdgeSupervision()类中一共有三个输入参数:初始化调用的chn(卷积核conv1的输入通道数),前向传播时调用的feat_fuse和feat_high(feat是feature特征的简写)。有一个输出参数:edge_pred(fuse)。
2. REA模块在CFF模块中的调用
CFF模块主要通过C2FMaskHead()类实现,其中使用了Modulelist()的方法将ReverseEdgeSupervision()初始化到了名为edge_all_levels的module列表中。
self.sem_loss_on = cfg.MODEL.OSFormer.SEM_LOSS
self.single_sem = cfg.MODEL.OSFormer.SINGLE_SEM
if self.sem_loss_on:
self.edge_all_levels = nn.ModuleList()
if self.single_sem:
self.edge_all_levels.append(ReverseEdgeSupervision(self.mask_channels))
else:
for _ in range(self.num_levels - 1):
self.edge_all_levels.append(ReverseEdgeSupervision(self.mask_channels))
其中,传入参数self.mask_channels在是config配置文件中进行定义的。(?)
self.mask_channels = cfg.MODEL.OSFormer.MASK_CHANNELS
在C2FMaskHead()的前向传播过程中,对edge_all_levels模块列表中的第2-i个模块传入参数feature_add_all_level和feat_pre_level,分别对应ReverseEdgeSupervision()中的feat_fuse参数和feat_high参数。
feature_add_all_level和feat_pre_level都是Modulelist()类型的变量,feature_add_all_level等于所有feat_pre_level加起来,并进行了RELU激活。而在for循环中,feat_pre_level分别代表各个层级的特征图。
def forward(self, features):
assert len(features) == self.num_levels, \
print("The number of input features should be equal to the supposed level.")
mask_feat = features[-1] # 返回倒数第一个参数
feature_add_all_level = self.convs_all_sums[-1](mask_feat)
edge_preds = []
feat_pre_level = None
for i in range(self.num_levels - 2, -1, -1):
feat_pre_level = self.convs_all_levels[i](features[i])
feature_add_all_level += feat_pre_level
feature_add_all_level = F.relu(feature_add_all_level, inplace=True)
if self.sem_loss_on and not self.single_sem:
edge_preds.append(self.edge_all_levels[2 - i](
feature_add_all_level, feat_pre_level))
feature_add_all_level = self.convs_all_sums[i](feature_add_all_level)
feature_add_all_level = F.relu(feature_add_all_level, inplace=True)
if self.sem_loss_on and self.single_sem:
edge_preds.append(self.edge_all_levels[0](
feature_add_all_level, feat_pre_level))
mask_pred = self.conv_pred(feature_add_all_level)
if self.sem_loss_on:
return mask_pred, edge_preds
return mask_pred
C2FMaskHead()模块有三个输入参数:初始化使用的config配置cfg、列表变量input_shape;前向传播时调用的特征图features。输出参数:mask_pred;如果sem_loss_on为True,则输出edge_preds。
其中,mask_pred是将feature_add_all_level输入到conv_pred中得到的预测结果。conv_pred的实现如下。
self.conv_pred = nn.Sequential(
nn.Conv2d(
self.mask_channels, self.num_masks,
kernel_size=1, stride=1,
padding=0, bias=norm is None),
nn.GroupNorm(32, self.num_masks),
nn.ReLU(inplace=True)
)
sem_loss_on的值来自于cfg。
self.sem_loss_on = cfg.MODEL.OSFormer.SEM_LOSS
3. CFF模块在OSFormer中的调用
OSFormer()中对C2FMaskHead()的实例化如下。cfg是config配置信息,mask_shapes是ResNet中各层级的最后输出特征图。
mask_shapes = [backbone_shape['res' + f[-1]] for f in self.mask_in_features]
self.mask_head = C2FMaskHead(cfg, mask_shapes)
在OSFormer()类的前向传播中,mask_head被赋值给了mask_pred参数,通过if条件语句,将C2FMaskHead()的两个返回值mask_pred和edge_preds分别赋值给mask_pred和sem_pred,两者用来计算损失函数loss和计算推理结果results。
mask_in_feats = [features[f] for f in self.mask_in_features]
mask_pred = self.mask_head(mask_in_feats)
sem_pred = None
if self.sem_loss_on:
mask_pred, sem_pred = mask_pred
if self.training:
"""
get_ground_truth.
return loss and so on.
"""
mask_feat_size = mask_pred.size()[-2:]
sem_targets = None
if self.sem_loss_on:
sem_targets = self.get_sem_ground_truth(gt_instances, mask_feat_size)
targets = self.get_ground_truth(gt_instances, mask_feat_size)
losses = self.loss(cate_pred, kernel_pred, mask_pred, targets, sem_targets, sem_pred)
return losses
else:
# point nms.
cate_pred = [point_nms(cate_p.sigmoid(), kernel=2).permute(0, 2, 3, 1)
for cate_p in cate_pred]
# do inference for results.
results = self.inference(cate_pred, kernel_pred, mask_pred, images.image_sizes, batched_inputs, sem_pred)
return results
其中,mask_in_feats的参数是保存在cfg中的,代表了C2FMaskHead()前向传播中的输入参数特征图features。
self.mask_in_features = cfg.MODEL.OSFormer.MASK_IN_FEATURES
4.疑问分析
- 输入REA模块的不同层级的特征图(T4、T3、C2)是否和之前的Reverse Attention一样经过了上采样?
答:经过了2倍上采样。根据C2FMaskHead()中的代码可以看到,在与REA模块中的浅层特征图进行融合之前,深一层的特征图都使用双线性插值进行了2倍上采样。
if i != 0:
upsample_tower = nn.Upsample(
scale_factor=2, mode='bilinear', align_corners=False)
convs_per_level.add_module(
'upsample' + str(i), upsample_tower)
self.convs_all_sums.append(convs_per_level)
if i == self.num_levels - 1:
continue
···
feature_add_all_level = self.convs_all_sums[-1](mask_feat) # REA模块中的feat_fuse,也就是Fusion features
- REA模块的输出边缘特征图 F e F_e Fe最终输出到了哪里?是否和之前的Reverse Attention一样与不同层级的REA输出相加到了一起?
答:与之前的Reverse Attention一样,不同层级的REA输出feat_pre_level都会添加到feature_add_all_level中,进行相加。
feature_add_all_level += feat_pre_level
经过逐级的上采样和相加,最终得到C2FMaskHead()的返回值mask_pred和edge_preds。其中,mask_pred是feature_add_all_level经过卷积层的输出;edge_preds是ReverseEdgeSupervision()的返回值输出。
if self.sem_loss_on and self.single_sem:
edge_preds.append(self.edge_all_levels[0](
feature_add_all_level, feat_pre_level))
mask_pred = self.conv_pred(feature_add_all_level)
最后在OSFormer()中,C2FMaskHead()实例化为mask_pred,其中包含C2FMaskHead()的两个返回值mask_pred(赋值给mask_pred)、edge_preds(赋值给sem_pred)。一方面,mask_pred用来计算dice loss和cate loss,sem_pred用来计算loss_sem;另一方面,用来完成inference过程,得到最终的预测结果results,results是列表变量,其中包含对伪装实例的预测分数和对伪装实例边缘的预测分数。
- 通过侵蚀实例掩码标签来获得边缘标签是怎么实现的?
答:调用了kornia.morphology库中的erosion函数,使用了基本形态学滤波中的腐蚀操作,找到二值图像中像素值为0的点,将0值扩充到邻近像素。扩大黑色部分,减小白色部分。可用来提取骨干信息。
代码中使用了 5 × 5 5 \times 5 5×5的滤波器进行腐蚀滤波,然后将原始图像与经过腐蚀滤波后的图像做差分运算,得到边缘信息。
def map_to_edge(self, tensor):
tensor = tensor.float()
kernel = torch.ones((5, 5), device=tensor.device)
ero_map = erosion(tensor, kernel)
res = tensor - ero_map
return res
- Edge loss是怎么进行计算的?原论文中3.5节提到, L e d g e = ∑ j = 1 J L d i c e ( j ) L_{edge}=\sum_{j=1}^{J}L_{dice}^{(j)} Ledge=∑j=1JLdice(j)。那么, L d i c e L_{dice} Ldice又是什么?是V-Net论文中提到的Dice loss吗?那Dice loss有什么特别之处呢?这与之前的Reverse Attention所用的损失函数有什么区别?
答:在源码当中使用了列表变量loss_ins_edge来计算Edge loss。遍历输入的预测值和标签值,先分别计算边缘,再计算Dice loss,添加到loss_ins_edge列表中。将loss_ins_edge求取加权平均后,进行拼接合并,得到最终的loss_ins_edge。
# dice loss
loss_ins_edge = []
for input, target in zip(ins_pred_list, ins_labels):
···
if self.ins_edge_on:
input_edge = self.map_to_edge(input.unsqueeze(0)).squeeze(0)
target_edge = self.map_to_edge(target.unsqueeze(0)).squeeze(0)
loss_ins_edge.append(dice_loss(input_edge, target_edge))
loss_ins_edge = torch.cat(loss_ins_edge).mean() * self.ins_edge_weight if self.ins_edge_on else []
Dice loss最先在VNet论文中提出,而后被广泛应用在医学图像分割中。在语义分割中,训练模型时一般采用交叉熵作为损失函数,而评价模型的时候却用IOU作为评价指标。在GIOU这篇论文中提到,代理损失函数的最优选择就是评价指标本身。Dice loss就是这样一种类似IOU的损失函数,因而以Dice loss来训练分割模型可以得到更好的IOU效果。
但是Dice loss存在的问题在于训练误差曲线混乱,难以看出关于收敛的信息。
D i c e = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ Dice = \frac{2 \lvert X \cap Y \rvert}{\lvert X \rvert + \lvert Y \rvert} Dice=∣X∣+∣Y∣2∣X∩Y∣
D i c e L o s s = 1 − D i c e = 1 − 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DiceLoss=1-Dice=1- \frac{2 \lvert X \cap Y \rvert}{\lvert X \rvert + \lvert Y \rvert} DiceLoss=1−Dice=1−∣X∣+∣Y∣2∣X∩Y∣
代码实现如下:
def dice_loss(input, target):
input = input.contiguous().view(input.size()[0], -1)
target = target.contiguous().view(target.size()[0], -1).float()
a = torch.sum(input * target, 1)
b = torch.sum(input * input, 1) + 0.001
c = torch.sum(target * target, 1) + 0.001
d = (2 * a) / (b + c)
return 1 - d
4. 下一步计划
下一步计划
- 调研Dice Loss损失函数
- 进一步理解OSFormer源代码,例如DCIN的作用及实现等
- 通过代码理解deformable attention
参考
- python数字图像处理(13):基本形态学滤波
- 医学影像分割—Dice Loss