使用LightGCN实现推荐系统(手撕代码+分析)
目录
1. 简介
2. 导包
3. 加载并处理数据
3.1 数据集
3.2 映射数据集的索引
3.3 得到用户电影交互图
3.4 划分数据集
3.5 随机抽取正样本和负样本
4. 定义LightGCN模型
4.1 Light Graph Convolution (LGC)
4.2 Layer Combination andModel Prediction
4.3 Matrix Form
5. 损失函数
6. 评价指标
6.1 获取正采样
6.2 前K个电影的Recall值和Precision值
6.3 前K个电影的NDCG值
6.4 获取评价指标
6.5 整合loss值和评价指标
7. 训练模型
7.1 设置相应参数
7.2 选择用GPU还是CPU
7.3 划分训练、测试、验证边索引,训练模型,加入优化器和学习率训练模型
7.4 训练模型
7.5 可视化
1. 简介
由于推荐的特性,直接将GCN用在推荐系统中的效果并没有很好,因此提出了LightGCN模型。LightGCN简化了GCN,去掉了GCN中的非线性激活和特征变化,只保留邻居聚合和消息传递。
文章地址:https://arxiv.org/abs/2002.02126
2. 导包
导入相关的包,我用的配套环境是:python3.7+cuda10.1+pytorch1.4.0+pytorch_geometric2.0.1+pytorch_sparse0.6.0,其他包可自行选择合适版本。
import random
from tqdm import tqdm
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import torch
from torch import nn, optim, Tensor
from torch_sparse import SparseTensor, matmul
from torch_geometric.utils import structured_negative_sampling
from torch_geometric.data import download_url, extract_zip
from torch_geometric.nn.conv.gcn_conv import gcn_norm
from torch_geometric.nn.conv import MessagePassing
from torch_geometric.typing import Adj
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)3. 加载并处理数据
3.1 数据集
使用movielens数据集进行实验。具体数据集看电脑配置,配置好有显卡的可以使用大点的数据集,链接:MovieLens 25M Dataset | GroupLens ,里面是62,000个movies和162,000个users交互;没有显卡的可以使用小点的数据集,链接:https://files.grouplens.org/datasets/movielens/ml-latest-small.zip,里面是9,000个movies和600个 users交互。
movie_path = '数据集里movie_path的路径'
rating_path = 'D:数据集里rating_path的路径'3.2 映射数据集的索引
def load_node_csv(path, index_col):
"""
Args:
path (str): 数据集路径
index_col (str): 数据集文件里的列索引
Returns:
dict: 列号和用户ID的索引、列好和电影ID的索引
"""
df = pd.read_csv(path, index_col=index_col)
mapping = {index: i for i, index in enumerate(df.index.unique())} # enumerate()索引函数,默认索引从0开始
return mapping实例化用户的索引和电影的索引,得到两个一维矩阵。
user_mapping = load_node_csv(rating_path, index_col='userId')
movie_mapping = load_node_csv(movie_path, index_col='movieId')得到结果:user_mapping:{1: 0, 2: 1, 3: 2, 4: 3, 5: 4, 6: 5, 7: 6, 8: 7, 9: 8, 10: 9, 11: 10, 12: 11, ... , 610: 609}
movie_mapping:{1: 0, 2: 1, 3: 2, 4: 3, 5: 4, 6: 5, 7: 6, 8: 7, 9: 8, 10: 9, 11: 10, 12: 11, ... ,193609: 9741}
3.3 得到用户电影交互图
def load_edge_csv(path, src_index_col, src_mapping, dst_index_col, dst_mapping, link_index_col, rating_threshold=4):
"""
Args:
path (str): 数据集路径
src_index_col (str): 用户列名
src_mapping (dict): 行号和用户ID的映射
dst_index_col (str): 电影列名
dst_mapping (dict): 行号和电影ID的映射
link_index_col (str): 交互的列名
rating_threshold (int, optional): 决定选取多少评分交互的阈值,设置为4分
Returns:
torch.Tensor: 2*N的用户电影交互节点图
"""
df = pd.read_csv(path)
edge_index = None
src = [src_mapping[index] for index in df[src_index_col]]
dst = [dst_mapping[index] for index in df[dst_index_col]]
edge_attr = torch.from_numpy(df[link_index_col].values).view(-1, 1).to(torch.long) >= rating_threshold # 将数组转化为tensor张量
edge_index = [[], []]
for i in range(edge_attr.shape[0]):
if edge_attr[i]:
edge_index[0].append(src[i])
edge_index[1].append(dst[i])
return torch.tensor(edge_index)实例化交互图的索引,得到一个2*N的tensor张量
edge_index = load_edge_csv(
rating_path,
src_index_col='userId',
src_mapping=user_mapping,
dst_index_col='movieId',
dst_mapping=movie_mapping,
link_index_col='rating',
rating_threshold=4,
)得到结果:tensor([[ 0, 0, 0, ..., 609, 609, 609],
[ 0, 2, 5, ..., 9461, 9462, 9463]])
3.4 划分数据集
将数据集划分成训练集、测试集、验证集,比例为8:1:1.
num_users, num_movies = len(user_mapping), len(movie_mapping)
num_interactions = edge_index.shape[1]
all_indices = [i for i in range(num_interactions)] # 所有索引
train_indices, test_indices = train_test_split(
all_indices, test_size=0.2, random_state=1) # 将数据集划分成80:10的训练集:测试集
val_indices, test_indices = train_test_split(
test_indices, test_size=0.5, random_state=1) # 将测试集划分成10:10的验证集:测试集,最后的比例就是80:10:10
train_edge_index = edge_index[:, train_indices]
val_edge_index = edge_index[:, val_indices]
test_edge_index = edge_index[:, test_indices]得到结果:train_edge_index tensor([[ 605, 110, 442, ..., 65, 161, 427],
[1111, 9637, 1284, ..., 4648, 443, 828]])val_edge_index tensor([[ 111, 491, 582, ..., 176, 478, 413],
[1073, 656, 314, ..., 5374, 450, 7010]])test_edge_index tensor([[ 559, 266, 57, ..., 278, 201, 67],
[5350, 899, 443, ..., 8990, 1579, 1154]])
3.5 随机抽取正样本和负样本
def sample_mini_batch(batch_size, edge_index):
"""
Args:
batch_size (int): 批大小
edge_index (torch.Tensor): 2*N的边列表
Returns:
tuple: user indices, positive item indices, negative item indices
"""
edges = structured_negative_sampling(edge_index)
edges = torch.stack(edges, dim=0)
indices = random.choices(
[i for i in range(edges[0].shape[0])], k=batch_size)
batch = edges[:, indices]
user_indices, pos_item_indices, neg_item_indices = batch[0], batch[1], batch[2]
return user_indices, pos_item_indices, neg_item_indices4. 定义LightGCN模型
4.1 Light Graph Convolution (LGC)
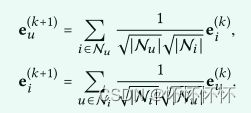
4.2 Layer Combination andModel Prediction

4.3 Matrix Form
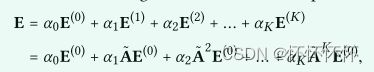
class LightGCN(MessagePassing):
def __init__(self, num_users, num_items, embedding_dim=64, K=3, add_self_loops=False, **kwargs):
"""
Args:
num_users (int): 用户数量
num_items (int): 电影数量
embedding_dim (int, optional): 嵌入维度,设置为64,后续可以调整观察效果
K (int, optional): 传递层数,设置为3,后续可以调整观察效果
add_self_loops (bool, optional): 传递时加不加自身节点,设置为不加
"""
kwargs.setdefault('aggr', 'add')
super().__init__(**kwargs)
self.num_users, self.num_items = num_users, num_items
self.embedding_dim, self.K = embedding_dim, K
self.add_self_loops = add_self_loops
self.users_emb = nn.Embedding(
num_embeddings=self.num_users, embedding_dim=self.embedding_dim) # e_u^0
self.items_emb = nn.Embedding(
num_embeddings=self.num_items, embedding_dim=self.embedding_dim) # e_i^0
nn.init.normal_(self.users_emb.weight, std=0.1) # 从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
nn.init.normal_(self.items_emb.weight, std=0.1)
def forward(self, edge_index: SparseTensor):
"""
Args:
edge_index (SparseTensor): 邻接矩阵
Returns:
tuple (Tensor): e_u%^k, e_u^0, e_i^k, e_i^0
"""
# compute \tilde{A}: symmetrically normalized adjacency matrix
edge_index_norm = gcn_norm(
edge_index, add_self_loops=self.add_self_loops)
emb_0 = torch.cat([self.users_emb.weight, self.items_emb.weight]) # E^0
embs = [emb_0]
emb_k = emb_0
# 多尺度扩散
for i in range(self.K):
emb_k = self.propagate(edge_index_norm, x=emb_k)
embs.append(emb_k)
embs = torch.stack(embs, dim=1)
emb_final = torch.mean(embs, dim=1) # E^K
users_emb_final, items_emb_final = torch.split(
emb_final, [self.num_users, self.num_items]) # splits into e_u^K and e_i^K
# returns e_u^K, e_u^0, e_i^K, e_i^0
return users_emb_final, self.users_emb.weight, items_emb_final, self.items_emb.weight
def message(self, x_j: Tensor) -> Tensor:
return x_j
def message_and_aggregate(self, adj_t: SparseTensor, x: Tensor) -> Tensor:
# computes \tilde{A} @ x
return matmul(adj_t, x)实例化模型
model = LightGCN(num_users, num_movies)得到结果:LightGCN(
(users_emb): Embedding(610, 64)
(items_emb): Embedding(9742, 64)
)
5. 损失函数
采用BPR损失函数
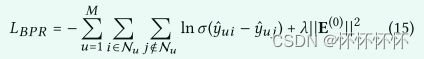
def bpr_loss(users_emb_final, users_emb_0, pos_items_emb_final, pos_items_emb_0, neg_items_emb_final, neg_items_emb_0, lambda_val):
"""
Args:
users_emb_final (torch.Tensor): e_u^k
users_emb_0 (torch.Tensor): e_u^0
pos_items_emb_final (torch.Tensor): positive e_i^k
pos_items_emb_0 (torch.Tensor): positive e_i^0
neg_items_emb_final (torch.Tensor): negative e_i^k
neg_items_emb_0 (torch.Tensor): negative e_i^0
lambda_val (float): λ的值
Returns:
torch.Tensor: loss值
"""
reg_loss = lambda_val * (users_emb_0.norm(2).pow(2) +
pos_items_emb_0.norm(2).pow(2) +
neg_items_emb_0.norm(2).pow(2)) # L2 loss L2范数是指向量各元素的平方和然后求平方根
pos_scores = torch.mul(users_emb_final, pos_items_emb_final)
pos_scores = torch.sum(pos_scores, dim=-1) # 正采样预测分数
neg_scores = torch.mul(users_emb_final, neg_items_emb_final)
neg_scores = torch.sum(neg_scores, dim=-1) # 负采样预测分数
loss = -torch.mean(torch.nn.functional.softplus(pos_scores - neg_scores)) + reg_loss
return loss6. 评价指标
采用Recall、Precision和NDCG 三个评价指标判断模型的优劣。
6.1 获取正采样
def get_user_positive_items(edge_index):
"""为每个用户生成正采样字典
Args:
edge_index (torch.Tensor): 2*N的边列表
Returns:
dict: 每个用户的正采样字典
"""
user_pos_items = {}
for i in range(edge_index.shape[1]):
user = edge_index[0][i].item()
item = edge_index[1][i].item()
if user not in user_pos_items:
user_pos_items[user] = []
user_pos_items[user].append(item)
return user_pos_items6.2 前K个电影的Recall值和Precision值
def RecallPrecision_ATk(groundTruth, r, k):
"""
Args:
groundTruth (list): 每个用户对应电影列表的高评分项
r (list): 是否向每个用户推荐了前k个电影的列表
k (intg): 确定要计算精度和召回率的前k个电影
Returns:
tuple: recall @ k, precision @ k
"""
num_correct_pred = torch.sum(r, dim=-1) # number of correctly predicted items per user
# number of items liked by each user in the test set
user_num_liked = torch.Tensor([len(groundTruth[i])
for i in range(len(groundTruth))])
recall = torch.mean(num_correct_pred / user_num_liked)
precision = torch.mean(num_correct_pred) / k
return recall.item(), precision.item()6.3 前K个电影的NDCG值
def NDCGatK_r(groundTruth, r, k):
"""Computes Normalized Discounted Cumulative Gain (NDCG) @ k
Args:
groundTruth (list): 同上一个函数
r (list): 同上一个函数
k (int): 同上一个函数
Returns:
float: ndcg @ k
"""
assert len(r) == len(groundTruth)
test_matrix = torch.zeros((len(r), k))
for i, items in enumerate(groundTruth):
length = min(len(items), k)
test_matrix[i, :length] = 1
max_r = test_matrix
idcg = torch.sum(max_r * 1. / torch.log2(torch.arange(2, k + 2)), axis=1)
dcg = r * (1. / torch.log2(torch.arange(2, k + 2)))
dcg = torch.sum(dcg, axis=1)
idcg[idcg == 0.] = 1.
ndcg = dcg / idcg
ndcg[torch.isnan(ndcg)] = 0.
return torch.mean(ndcg).item()6.4 获取评价指标
这部分是为了方便训练,所以用一个函数封装。也可以不用这个函数,将这个函数里的功能写在训练里也行。
def get_metrics(model, edge_index, exclude_edge_indices, k):
"""
Args:
model (LighGCN): lightgcn model
edge_index (torch.Tensor): 2*N列表
exclude_edge_indices ([type]): 2*N列表
k (int): 前多少个电影
Returns:
tuple: recall @ k, precision @ k, ndcg @ k
"""
user_embedding = model.users_emb.weight
item_embedding = model.items_emb.weight
# get ratings between every user and item - shape is num users x num movies
rating = torch.matmul(user_embedding, item_embedding.T)
for exclude_edge_index in exclude_edge_indices:
# gets all the positive items for each user from the edge index
user_pos_items = get_user_positive_items(exclude_edge_index)
# get coordinates of all edges to exclude
exclude_users = []
exclude_items = []
for user, items in user_pos_items.items():
exclude_users.extend([user] * len(items))
exclude_items.extend(items)
# set ratings of excluded edges to large negative value
rating[exclude_users, exclude_items] = -(1 << 10)
# get the top k recommended items for each user
_, top_K_items = torch.topk(rating, k=k)
# get all unique users in evaluated split
users = edge_index[0].unique()
test_user_pos_items = get_user_positive_items(edge_index)
# convert test user pos items dictionary into a list
test_user_pos_items_list = [
test_user_pos_items[user.item()] for user in users]
# determine the correctness of topk predictions
r = []
for user in users:
ground_truth_items = test_user_pos_items[user.item()]
label = list(map(lambda x: x in ground_truth_items, top_K_items[user]))
r.append(label)
r = torch.Tensor(np.array(r).astype('float'))
recall, precision = RecallPrecision_ATk(test_user_pos_items_list, r, k)
ndcg = NDCGatK_r(test_user_pos_items_list, r, k)
return recall, precision, ndcg6.5 整合loss值和评价指标
同6.4,这部分是为了方便训练,所以用一个函数封装。也可以不用这个函数,将这个函数里的功能写在训练里也行。
def evaluation(model, edge_index, sparse_edge_index, exclude_edge_indices, k, lambda_val):
# get embeddings
users_emb_final, users_emb_0, items_emb_final, items_emb_0 = model.forward(
sparse_edge_index)
edges = structured_negative_sampling(
edge_index, contains_neg_self_loops=False)
user_indices, pos_item_indices, neg_item_indices = edges[0], edges[1], edges[2]
users_emb_final, users_emb_0 = users_emb_final[user_indices], users_emb_0[user_indices]
pos_items_emb_final, pos_items_emb_0 = items_emb_final[
pos_item_indices], items_emb_0[pos_item_indices]
neg_items_emb_final, neg_items_emb_0 = items_emb_final[
neg_item_indices], items_emb_0[neg_item_indices]
loss = bpr_loss(users_emb_final, users_emb_0, pos_items_emb_final, pos_items_emb_0,
neg_items_emb_final, neg_items_emb_0, lambda_val).item()
recall, precision, ndcg = get_metrics(
model, edge_index, exclude_edge_indices, k)
return loss, recall, precision, ndcg7. 训练模型
7.1 设置相应参数
ITERATIONS = 10000
BATCH_SIZE = 1024
LR = 1e-3
ITERS_PER_EVAL = 200
ITERS_PER_LR_DECAY = 200
K = 20
LAMBDA = 1e-67.2 选择用GPU还是CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')7.3 划分训练、测试、验证边索引,训练模型,加入优化器和学习率训练模型
model = model.to(device)
model.train()
optimizer = optim.Adam(model.parameters(), lr=LR)
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
edge_index = edge_index.to(device)
train_edge_index = train_edge_index.to(device)
train_sparse_edge_index = train_sparse_edge_index.to(device)
val_edge_index = val_edge_index.to(device)
val_sparse_edge_index = val_sparse_edge_index.to(device)7.4 训练模型
train_losses = []
val_losses = []
for iter in range(ITERATIONS):
# forward propagation
users_emb_final, users_emb_0, items_emb_final, items_emb_0 = model.forward(
train_sparse_edge_index)
# mini batching
user_indices, pos_item_indices, neg_item_indices = sample_mini_batch(
BATCH_SIZE, train_edge_index)
user_indices, pos_item_indices, neg_item_indices = user_indices.to(
device), pos_item_indices.to(device), neg_item_indices.to(device)
users_emb_final, users_emb_0 = users_emb_final[user_indices], users_emb_0[user_indices]
pos_items_emb_final, pos_items_emb_0 = items_emb_final[
pos_item_indices], items_emb_0[pos_item_indices]
neg_items_emb_final, neg_items_emb_0 = items_emb_final[
neg_item_indices], items_emb_0[neg_item_indices]
# loss computation
train_loss = bpr_loss(users_emb_final, users_emb_0, pos_items_emb_final,
pos_items_emb_0, neg_items_emb_final, neg_items_emb_0, LAMBDA)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if iter % ITERS_PER_EVAL == 0:
model.eval()
val_loss, recall, precision, ndcg = evaluation(
model, val_edge_index, val_sparse_edge_index, [train_edge_index], K, LAMBDA)
print(f"[Iteration {iter}/{ITERATIONS}] train_loss: {round(train_loss.item(), 5)}, val_loss: {round(val_loss, 5)}, val_recall@{K}: {round(recall, 5)}, val_precision@{K}: {round(precision, 5)}, val_ndcg@{K}: {round(ndcg, 5)}")
train_losses.append(train_loss.item())
val_losses.append(val_loss)
model.train()
if iter % ITERS_PER_LR_DECAY == 0 and iter != 0:
scheduler.step()得到结果:
[Iteration 0/10000] train_loss: -0.69112, val_loss: -0.68374, val_recall@20: 0.00161, val_precision@20: 0.0009, val_ndcg@20: 0.00125 [Iteration 200/10000] train_loss: -0.70072, val_loss: -0.6902, val_recall@20: 0.05163, val_precision@20: 0.01618, val_ndcg@20: 0.03836 [Iteration 400/10000] train_loss: -0.89317, val_loss: -0.82984, val_recall@20: 0.14365, val_precision@20: 0.04005, val_ndcg@20: 0.10178 [Iteration 600/10000] train_loss: -1.79995, val_loss: -1.54339, val_recall@20: 0.14435, val_precision@20: 0.04259, val_ndcg@20: 0.10322 ... [Iteration 9800/10000] train_loss: -69.44392, val_loss: -57.50562, val_recall@20: 0.14933, val_precision@20: 0.04611, val_ndcg@20: 0.10598
7.5 可视化
iters = [iter * ITERS_PER_EVAL for iter in range(len(train_losses))]
plt.plot(iters, train_losses, label='train')
plt.plot(iters, val_losses, label='validation')
plt.xlabel('iteration')
plt.ylabel('loss')
plt.title('training and validation loss curves')
plt.legend()
plt.show()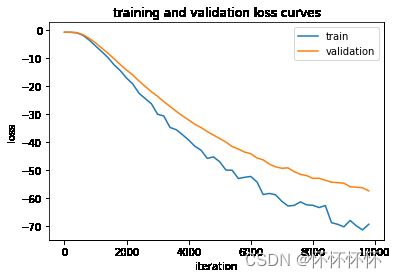

对推荐系统和图神经网络感兴趣的网友可以关注我的微信公众号“BoH工作室”,以后会陆续分享一些推荐系统和图神经网络的学习心得,欢迎大家关注并一起探讨。