当 Apache DolphinScheduler 遇上 MLOps,机器学习模型部署到生产环境更快、更安全

作者 | 周捷光 白鲸开源 高级算法工程师
导读:MLOps,即机器学习模型运营化已经是一个成熟的概念了。可以将其理解为用于机器学习的 DevOps,这个概念让数据科学家和 IT 团队能够通过监控、验证和管理机器学习模型,来进行协作并提高模型开发和部署的速度。总之,MLOps 可以帮助用户更快地试验和开发模型,更快地将模型部署到生产环境,并进行质量保证。
“
本次演讲分为四个部分:
Apache DolphinScheduler 与 MLOps 的碰撞
Apache DolphinScheduler ⽬前⽀持的机器学习任务类型
Jupyter 组件和 MLflow 组件的使⽤
Apache DolphinScheduler 与 MLOps 结合的计划
Apache DolphinScheduler
01
Apache DolphinScheduler 与 MLOps 的碰撞
什么是 MLOps?
DS
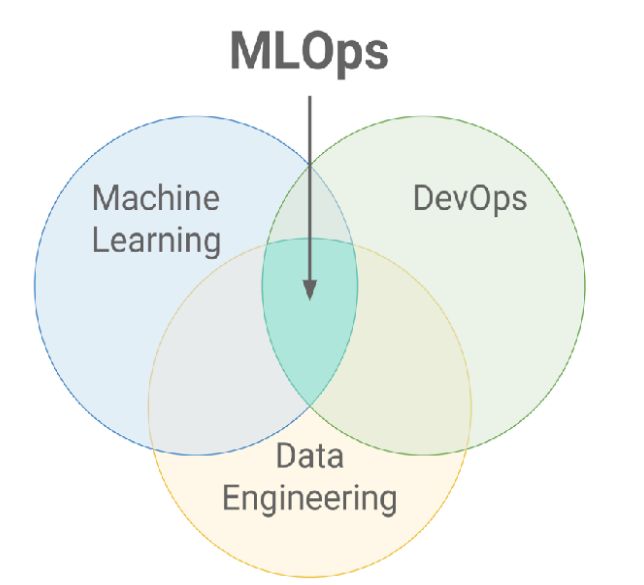
MLOps 是机器学习时代的 DevOps。它的主要作⽤就是连接模型构建团队和业务,运维团队,建⽴起⼀个标准化的模型开发、部署与运维流程,使得企业组织能更好地利⽤机器学习能⼒来促进业务增⻓。
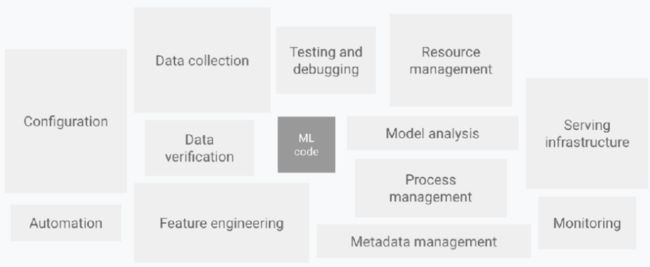
在实际⽣产中,ML代码可能只是整个系统的⼩部分代码,所需要的其他相关的元素是很庞⼤且很复杂的。
MLOps Landscape
DS

当前的MLops系统划分虽然不尽相同,但是核⼼是类似的,⼤致可以分成以下四个阶段的⼯作:
数据管理
建模
部署
监控
MLOps 案例
DS

DolphinScheduler在MLOps定位
DS
支持调度执行ML任务的能力
支持执行用户使用各种框架训练任务的特性
支持调度执行主流MLOps项目的能力
提供out-of-box的主流MLOps项目来让用户更方便的使用对应能力
支持编排各个模块搭建机器学习平台的能力
依据MLOps项目特性跟业务的适配程度,在不同的模块中可以使用不同项目的能力。
02
Apache DolphinScheduler 目前支持的 ML 任务类型
Jupyter Task Plugin
MLflow Task Plugin
OpenMLDB Task Plugin
Jupyter Task Plugin
DS
Jupyter Notebook 简介
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
Papermill 是一个可以参数化和执行Jupyter Notebook的工具。
组件介绍

Conda Env Name: Conda环境名称。
Input Note Path: 输入的jupyter note模板路径。
Output Note Path: 输出的jupyter note路径。
Parameters: 对接jupyter note参数化的JSON格式参数。
Kernel: Jupyter notebook 内核。
MLflow Task Plugin
DS
MLflow 简介
MLflow 是一个MLOps领域一个优秀的开源项目, 用于管理机器学习的生命周期,包括实验、可再现性、部署和中心模型注册。

组件介绍-MLflow Projects
✦
Custom projects
✦
Custom projects: 支持运行自己的
MLflow Projects项目
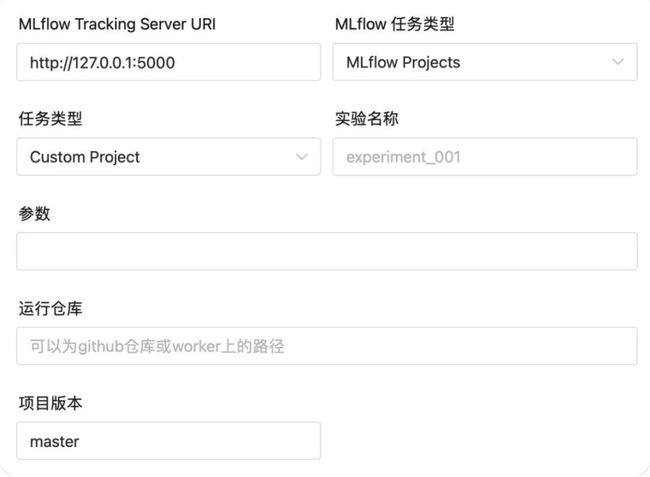
MLflow Tracking Server URI
实验名称 :任务运行时所在的实验
参数 : mlflow run中的 --param-list
运行仓库 : MLflow Project的仓库地址
项目版本 : 对应项目中git版本管理中的版本,默认 master
✦
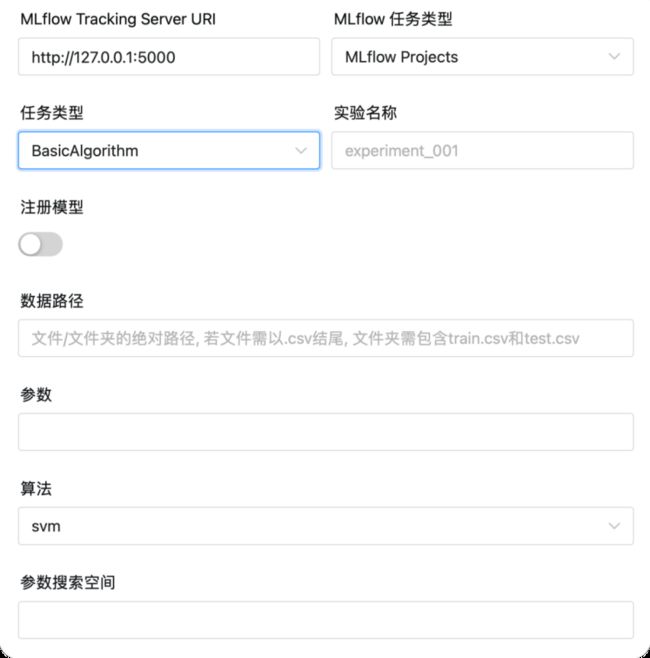
BasicAlgorithm
✦
BasicAlgorithm:包含LogisticRegression
svm, lightgbm, xgboost
MLflow Tracking Server URI
实验名称 :任务运行时所在的实验
注册模型 :是否注册模型
注册的模型名称 : 注册的模型名称
数据路径 : 文件/文件夹的绝对路径
参数 : 初始化模型时的参数
算法 :选择的算法,支持 LR, SVM, LightGBM, XGBoost.
参数搜索空间 : 运行对应算法的参数搜索空间
该功能预置算法实现由
https://github.com/apache/dolphinscheduler-mlflow 提供
✦
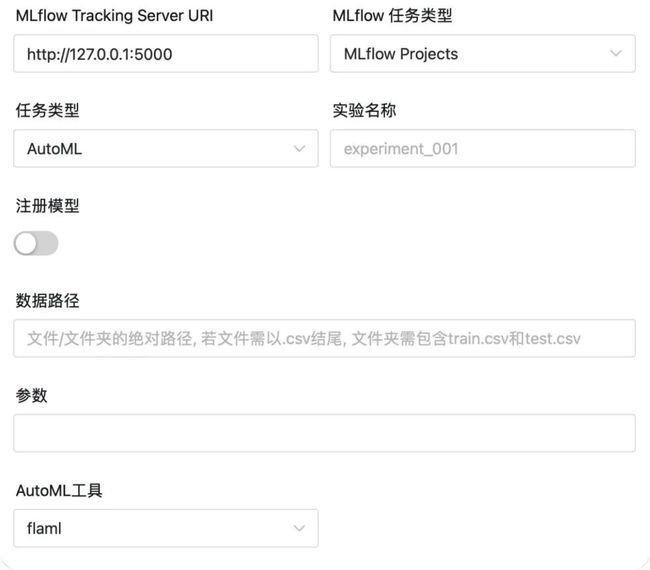
AutoML
✦
AutoML: AutoML工具,支持 autosklearn
flaml
MLflow Tracking Server URI
实验名称 :任务运行时所在的实验
注册模型 :是否注册模型
注册的模型名称 : 注册的模型名称
数据路径 : 文件/文件夹的绝对路径
参数 : 初始化AutoML训练器时的参数
AutoML工具 : 目前支持 autosklearn , flaml
该功能预置算法实现由 https://github.com/apache/dolphinscheduler-mlflow 提供
MLflow Models
MLFLOW: 直接读取模型地址,启动inference服务
MLflow Tracking Server URI
部署模型的URI :MLflow 服务里面模型对应的URI
部署端口 :部署服务时的端口
DOCKER: 将模型打包成DOCKER镜像后运行
MLflow Tracking Server URI
部署模型的URI :MLflow 服务里面模型对应的URI
部署端口 :部署服务时的端口
Docker Compose: 使用Docker Compose 部署模型
MLflow Tracking Server URI
部署模型的URI :mlflow 服务里面模型对应的uri
部署端口 :部署服务时的端口
最大cpu限制 :容器占用的最大CPU
最大内存限制 :容器占用的最大内存限制
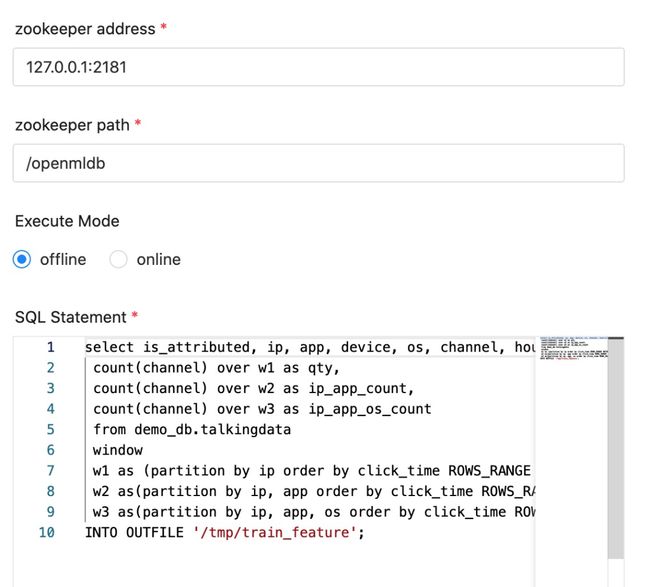
OpenMLDB Task Plugin
DS
03
Jupyter 组件和 MLflow 组件的使⽤
Jupyter 组件使用
DS
环境配置
在common.properties 中即可配置conda环境变量

创建一个conda环境,用于执行Jupyter Notebook:

如何调起 Jupyter 任务运行 Notebook?
准备一个Jupyter Notebook
使用DolphinScheduler创建Jupyter任务
运行工作流
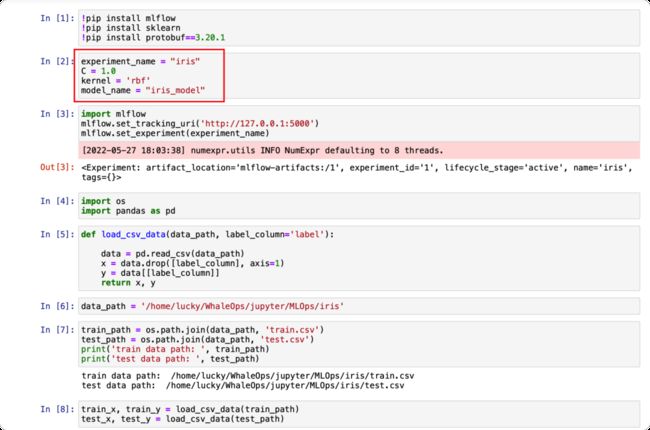
以下为一个使用SVM和iris数据集训练分类模型的Notebook
Notebook接收以下四个参数
experiment_name:记录到MLflow服务中心的实验名称
C:SVM参数
kernel:SVM参数
model_name:注册到MLflow模型中心的模型名字
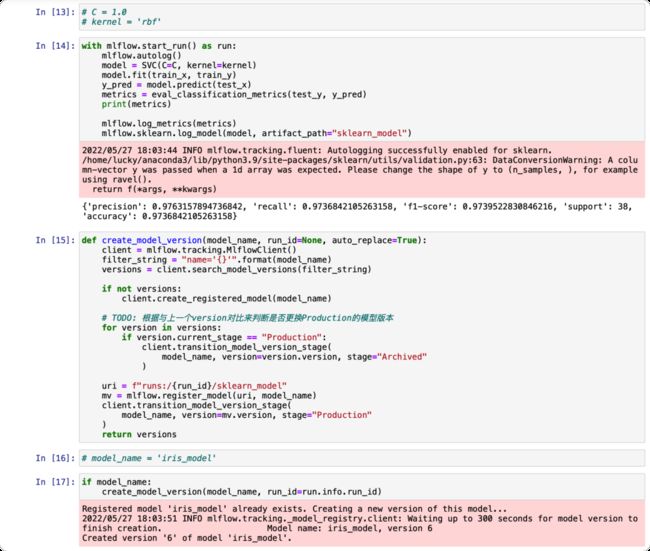
拖拽Jupyter任务组件到画布,创建一个任务,如下:
该任务会运行
Notebook: /home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm.ipynb,并将运行结果保留在路径 /home/lucky/WhaleOps/jupyter/MLOps/training_iris_svm/03.ipynb 中。
并且运行时参数 C 设置为"1.0", kernel 设置为 "linear",
运行的conda环境为kernel: "jupyter_test"。

我们可以再复制出两个相同的任务,并使用不同的参数。因此我们得到了三个不同参数的Jupyter任务,如下:
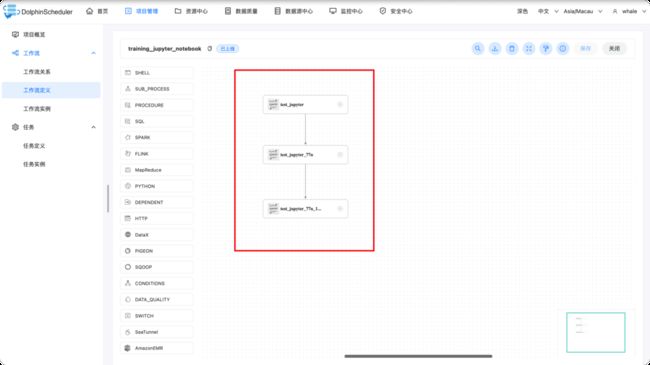
创建完成后,我们可以在工作流定义中看到我们新建的工作流(该工作流包含了3个Jupyter任务),点击红色箭头后,可以执行改工作流(也可以点击绿色箭头,设定定时任务满足实现定时运行工作流的需求)
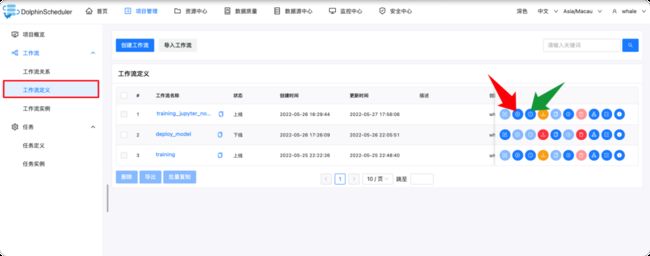
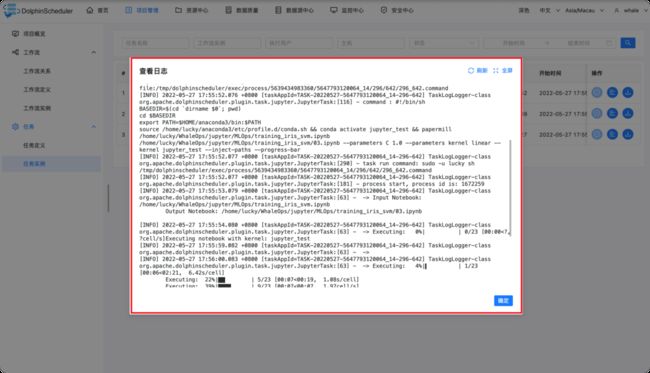
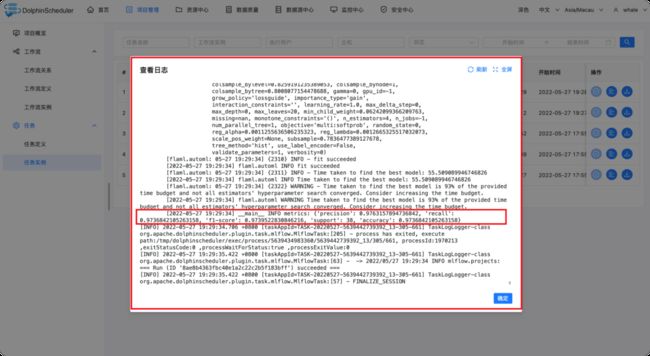
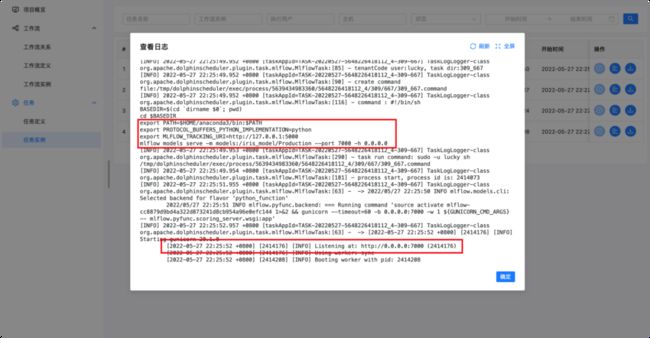
工作流运行后,可以点击任务实例查看每个任务的执行情况,点击红色箭头指向的按钮即可查看每个任务执行的日志。
使用场景
数据探索与分析
训练模型
定期线上数据监控
MLflow 组件使用
DS
环境配置
conda 环境配置
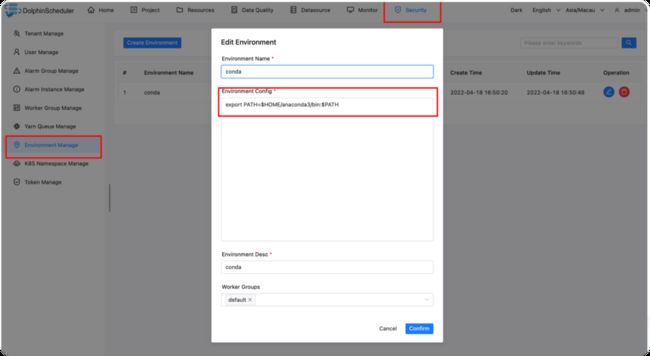
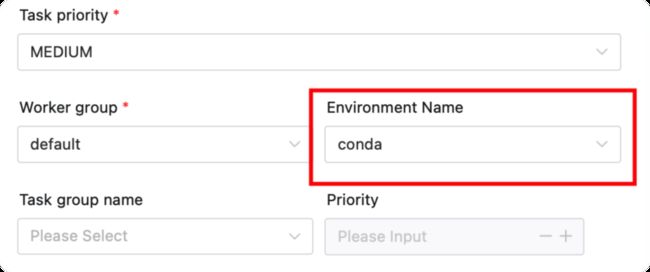
创建完环境后,后续每个任务都可以在Environment Name中选择我们刚创建的环境。
MLflow Service
安装MLflow, 使用 pip install mlflow 进行安装,即可启动 MLflow service。

更稳健的启动方式:
使用Docker Compose(如 https://github.com/Toumash/mlflow-docker)
使用helm (如 https://artifacthub.io/packages/helm/cetic/mlflow)
使用MLflow任务训练模型
DS
配置完环境后,如何使用MLflow训练任务?
准备一个数据集
使用DolphinScheduler创建MLflow训练任务
运行工作流
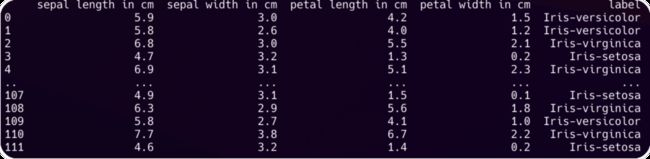
以下是一个iris的csv格式的数据集
举例创建工作流如下,包含两个MLflow任务
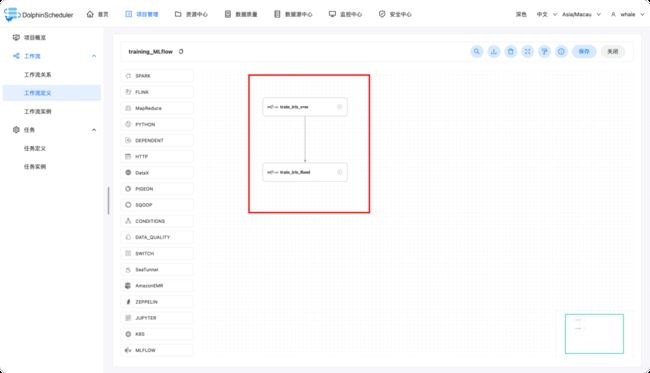
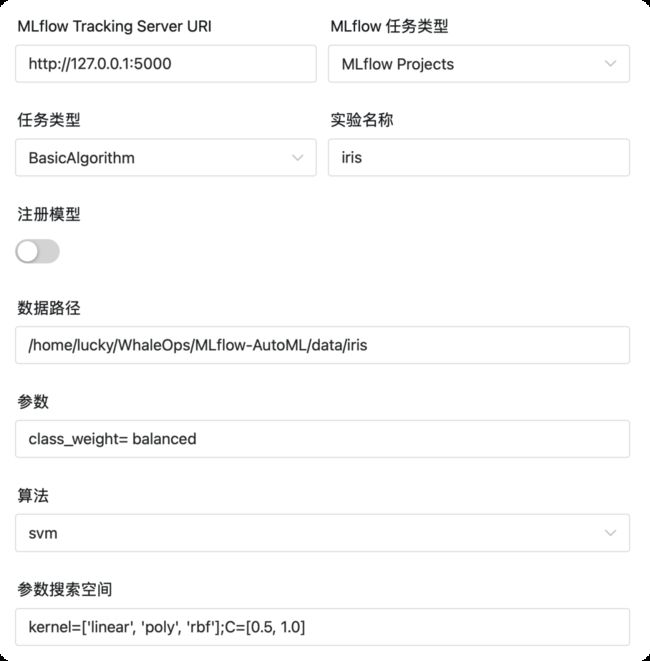
任务一: 使用svm训练iris分类模型,并设置如下参数,其中,超参数搜索空间用于调参使用,若不填,则不搜索超参数。
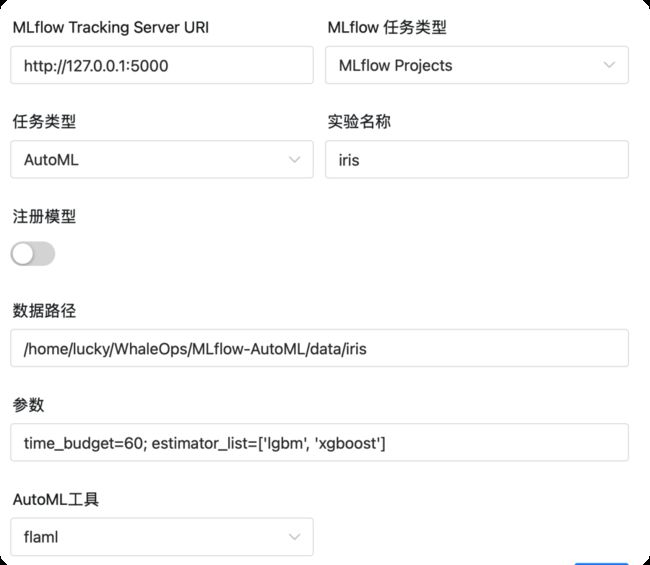
任务二:使用AutoML方法训练模型,AutoML工具使用flaml,并设置搜索时间为60秒,并只允许使用 lgbm, xgboost 作为estimator。
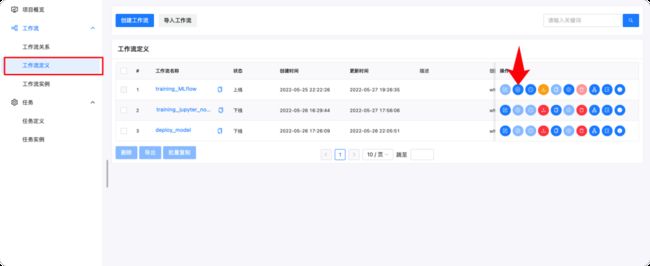
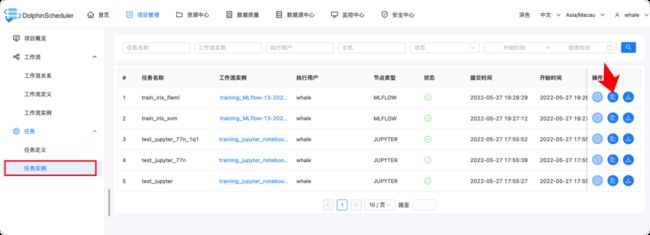
创建完工作流后,我们可以点击红色箭头指向的按钮来立即执行工作流。
✦
工作流中的任务实例
✦
✦
执行后的任务实例详情
✦
使用MLflow 部署任务
DS
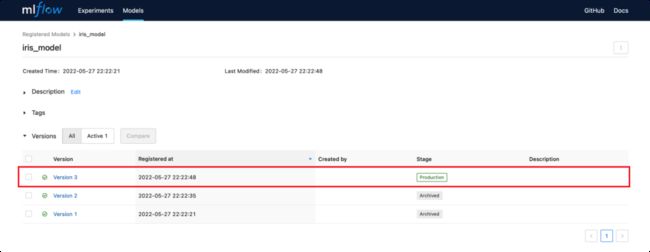
选择要部署的模型版本
使用DolphinScheduler创建MLflow部署任务
简单测试接口
上文中我们已经注册了在MLflow模型中心中注册了一些模型,我们可以打开 127.0.0.1:5000中看到模型的版本,如下
✦
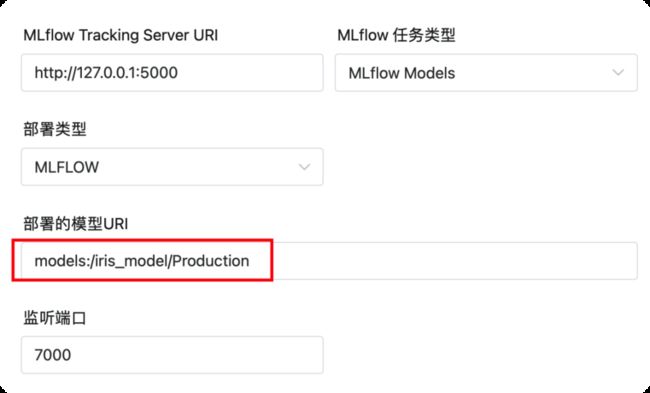
选择部署模型版本
✦
创建一个MLflow Models的任务,指定模型未 iris_model, 版本为 Production (生产版本),设置监听端口为7000
✦
确定模型URI和监听端口
✦
✦
具体运行机制
✦

✦
测试运行结果,可自定义
✦
Jupyter + MLflow 联合使用
DS
训练完模型后自动部署,以下为例子:
引用我们上面创建的工作流(Jupyter训练模型,MLflow部署模型)作为子工作流,并串联一起形成一个新的工作流即可。
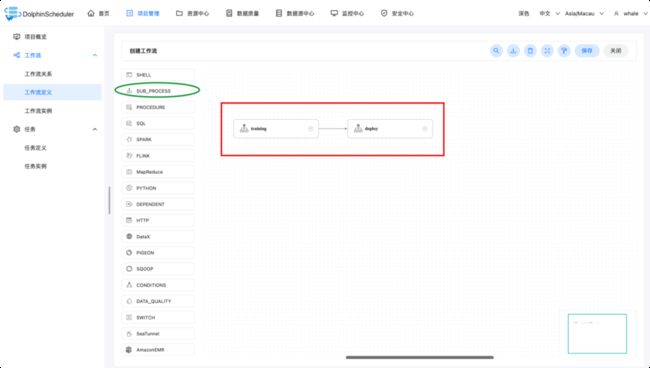
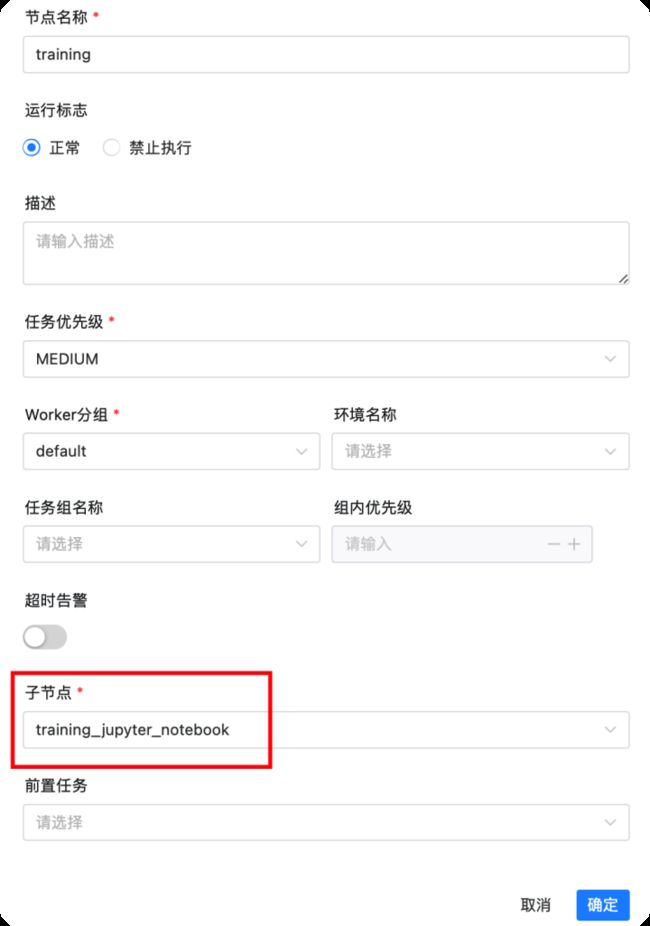
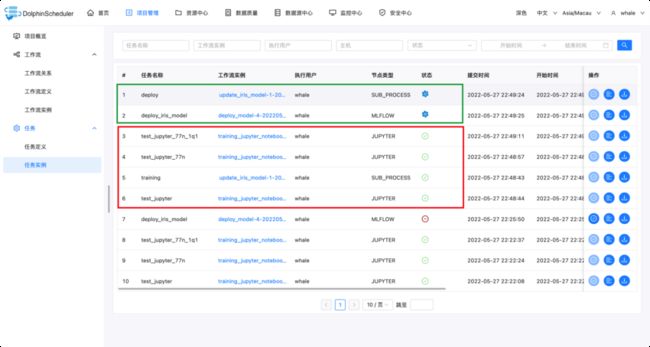
思考:Jupyter+MLflow还能做些什么?再加上OpenMLDB呢?
04
Apache DolphinScheduler 与 MLOps 结合的计划
MLOps Landscape
DS

上图为机器学习相关工具和平台的展示图,Apache DolphinScheduler 未来将有选择地支持其中一些使用范围较广,使用价值较高的工具和平台。
未来MLOps组件支持
DS

未来,Apache DolphinScheduler 将支持的MLOps组件主要分为三个模块,包括数据治理、模型和部署,涉及到的组件主要有 DVC(Data Version Control),集成Kubeflow建模,提供Seldon Core、BentoML、Kubeflow等部署工具,以适用不同场景使用需求。
如何集成更多工具,让Apache DolphinScheduler更好地服务用户,是我们长期的思考话题,欢迎更多对MLOps或开源感兴趣的小伙伴参与共建!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
![]()
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
更多精彩推荐
☞日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”
☞达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程【二】
☞Apache Dolphinscheduler 5月Meetup:6个月重构大数据平台,帮你避开调度升级改造/集群迁移踩过的坑
☞金融任务实例实时、离线跑批,Apache DolphinScheduler 在新网银行的三大应用场景与五大优化
☞中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问
☞又是一年开源之夏,八大课题项目奖金等你来拿!
我知道你在看哟
