Transformer(4)
1.什么是子层连接结构:
如图所示,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构.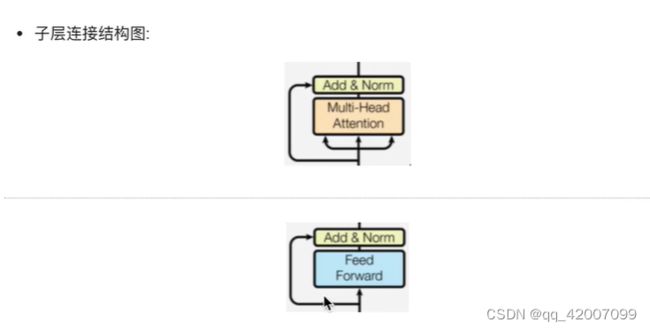
class SublayerConnection(nn.Module):
def __init__(self,size,dropout=0.1):
#size一般是都是词嵌入维度的大小,dropout本身是对模型结构中的节点数进行随机抑制的比率,
super(SublayerConnection,self).__init__()
#实例化规范化函数
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, sublayer):
#我们首先对输出进行规范化,然后将结果传给子层处理,之后再对子层进行dropout操作,
#随机停止一些网络中神经元的作用,来防止过拟合.最后还有一个add操作,
#因为存在跳跃连接,所以是将输入x与dropout后的子层输战结果相加作为最终的子层连接输出.
return x + self.dropout(sublayer(self.norm(x)))
size=512
dropout=0.2
head=8
d_model=512
x=pe_result
mask = Variable(torch.zeros(2,4,4))
#假设子层中装的是多头注意力层,实例化这个类
self_attn=MultiHeadAttention(head,d_model)
#使用lambda获得一个函数类型的子层
sublayer = lambda x :self_attn(x,x,x,mask)
sc = SublayerConnection(size,dropout)
sc_result = sc(x,sublayer)
print(sc_result)
print(sc_result.shape)
2.编码器层的作用:
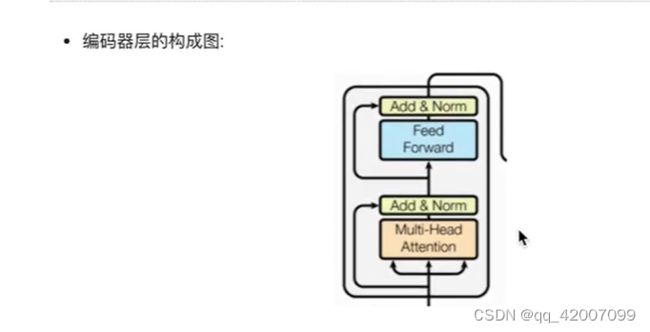
·作为编码器的组成单元,每个编码器层完成一次对输入的特征提取过程,即编码过程.
class Encoderlayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(Encoderlayer,self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
#编码器层中有两个子层连接结构,所以使用clones函数进行克隆
self.sublayer = clones(SublayerConnection(size, dropout),2)
self.size=size
def forward(self,x,mask):
#里面就是按照结构图左侧的流程.首先通过第一个子层连接结构,其中包含多头自注意力子层,
#然后通过第二个子层连接结构,其中包含前馈全连接子层.最后返回结果.
x = self.sublayer[0](x,lambda x: self.self_attn(x,x,x,mask))
return self.sublayer[1](x,self.feed_forward)
size = d_model = 512
head = 8
d_ff = 64
x=pe_result
dropout=0.2
self_attn=MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(2,4,4))
el = Encoderlayer(size, self_attn, ff, dropout)
el_result = el(x,mask)
print(sc_result)
print(sc_result.shape) 
3.编码器的实现
class Encoder(nn.Module):
def __init__(self, layer, N): #参数分别代表编码器层和编码器层的个数"
super(Encoder,self).__init__()
self.layers = clones(layer,N) #首先使用clones函数克隆N个编码器层放在self.layers中
#再初始化一个规范化层,它将用在编码器的最后面
self.norm = LayerNorm(layer.size)
def forward(self,x,mask):
for layer in self.layers:
x = layer(x,mask)
return self.norm(x)
size = d_model = 512
head = 8
d_ff = 64
c=copy.deepcopy
attn = MultiHeadAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
dropout=0.2
layer=Encoderlayer(size, c(attn), c(ff), dropout)
N=8
mask = Variable(torch.zeros(2,4,4))
x=pe_result
en = Encoder(layer, N)
en_result = en(x, mask)
print(en_result.shape)
>>>torch.Size([2,4,512])